

Panoptic driving perception is an important requirement for autonomous driving. Getting an overall picture of the surrounding helps a computer vision based neural network on making the appropriate decisions. But it is a complex problem to solve as well, especially in real-time. The new YOLOPv2 is a neural network model made just for this. It solves the driving perception problem for autonomous driving in real-time. All the while achieving state-of-the-art performance. In this article, we will discuss the YOLOPv2 paper which claims to be better, faster, and stronger than the previous panoptic driving perception models.

We will cover the following points in detail while discussing the YOLOPv2 paper:
- Why achieving real-time panoptic driving perception is a challenge?
- Some of the previous state-of-the-art models for panoptic driving perception.
- What does YOLOPv2 do differently?
- What makes YOLOPv2 better, faster, and stronger?
- YOLOPv2 architecture and methodology.
- Loss functions for training YOLOPv2.
- YOLOPv2 training experiments and results.
To know how YOLOPv2 beats the other panoptic driving perception models, keep reading.
Why is Panoptic Driving Perception Hard?
Panoptic driving perception is all about scene understanding and then outputting the correct predictions. It always involves more than one task.
Traffic vehicle detection, drivable area segmentation, and lane segmentation are three of the most common tasks. But achieving good results on these three tasks in real time is difficult.
Moreover, it is impractical to use three different neural networks for the three tasks. Using three different neural networks for the three tasks, it is hard to get real-time predictions. Also, panoptic driving perception is meant for autonomous driving. And autonomous driving systems have computational constraints.
Using a single good neural network backbone and branching off three heads is a common practice. This ensures the reusability of the features from the same scene (image/frame) and reduces network complexity as well.
Further, panoptic driving perception for autonomous driving is one of the most practical uses cases of deep learning and computer vision. In the real world, conditions are not always ideal. The neural network has to learn to detect vehicles, and segment roads & lanes in different weather, lighting, and traffic conditions as well.
Panoptic driving perception is not as simple as training a single network for a single task. Researchers/practitioners have to take care that the neural network performs almost equally well on all three tasks.
Further in the article, let’s see how YOLOPv2 tackles all of the above problems.
Previous State-of-the-Art Panoptic Driving Perception Models
There are panoptic driving perception neural networks other than YOLOPv2. These were considered state-of-the-art when they were released.
In fact, YOLOPv2 has been inspired by YOLOP. At the time of publication, YOLOP was able to beat the previous models for panoptic driving perception. YOLOP runs in real-time for traffic object detection and segmentation. One can even achieve real-time FPS with YOLOP ONNX CPU by reducing the image resolution. Although in the latter case, the detection and segmentation performance deteriorates.
Another such neural network model is HybridNets. Although slower than YOLOP, HybridNets performs better in detection and segmentation tasks compared to YOLOP.
For the rest of the article, let’s focus our attention on YOLOPv2.
What Does YOLOPv2 Do Differently?
YOLOPV2 by Han et al. is an efficient multi-task learning network to perform traffic object detection, drivable road segmentation, and lane detection in real-time. The authors also claim that the inference time reduces by half when compared with previous models.
They use the YOLOP network performance as the baseline. Then to improve the performance, they add the following components to the entire architecture and pipeline:
- An improved backbone for better feature extraction.
- Augmentation techniques like Mosaic and Mixup.
- Transposed convolutional layer for segmentation branches.
- Focal loss and Dice loss to the training pipeline.
All of the above help YOLOPv2 become better than the previous panoptic driving perception models.
We will discuss all of the above points in detail in further sections.
What makes YOLOPv2 Better, Faster, and Stronger?
YOLOPv2 terms itself to be better, faster, and stronger than the previous neural networks. It is clear that the name takes inspiration from the YOLOv2 paper by Joseph Redmon and Ali Farhadi.
YOLOPv2 is capable of running at 91 FPS on an NVIDIA Tesla V100 GPU. Under the same settings, YOLOP ran at 49 FPS. YOLOPv2 is more accurate at traffic object detection, drivable area segmentation, and lane detection as well.
So, how do the authors manage to do it?
- Better: Using a better model architecture along with bag-of-freebies for training. These include Mosaic and Mixup augmentation along with a combination of a hybrid loss function.
- Faster: A newer backbone neural network and better memory allocation help to achieve this.
- Stronger: YOLOPv2 adapts to various scenes under different conditions pretty well.
Now, as it is clear why the authors call it better, faster, and stronger, let’s jump into the model architecture of YOLOPv2.
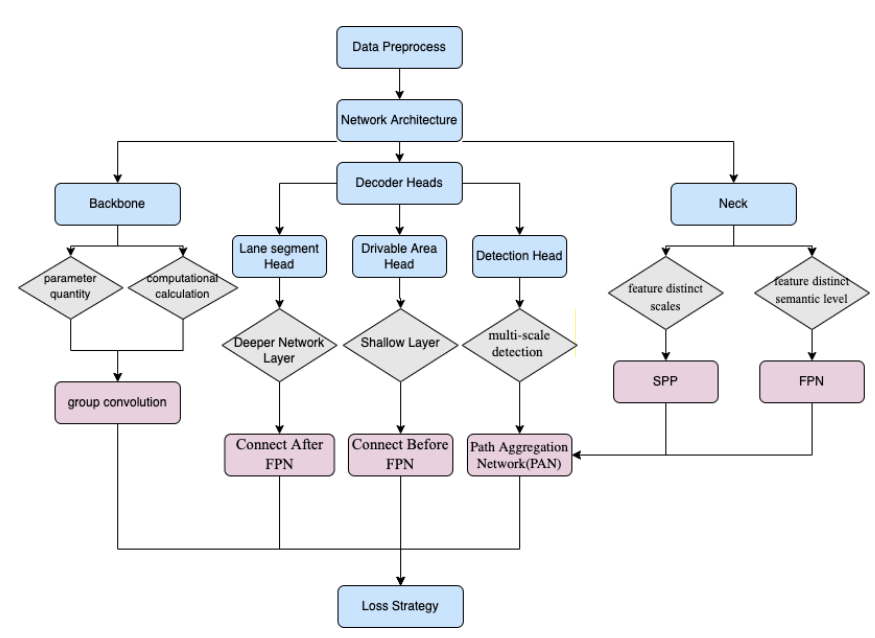
YOLOPv2 Architecture and Methodology
The YOLOPv2 network architecture follows a multi-task learning strategy.
YOLOPv2 builds by taking inspiration from YOLOP and HybridNets . But it uses a more efficient backbone for feature extraction. Also, YOLOPv2 does not share the same head for drivable area segmentation and lane detection. Instead, it has three different heads for each of the three tasks.
The Backbone of YOLOPv2 (Shared Encoder)
YOLOPv2 uses E-ELAN (Extended ELAN) as the feature extractor which uses group convolution. Then, the neck part after the backbone uses concatenation for fusing the features. Further, Spatial Pyramid Pooling (SPP) is used for fusing features at different scales.
Similarly, Feature Pyramid Network (FPN) is used to fuse features at different semantic levels.
YOLOPv2 Decoders (Task Heads)
As discussed earlier, YOLOPv2 contains three task heads. One for traffic object detection, another for drivable area segmentation, and a final one for lane detection (segmentation).
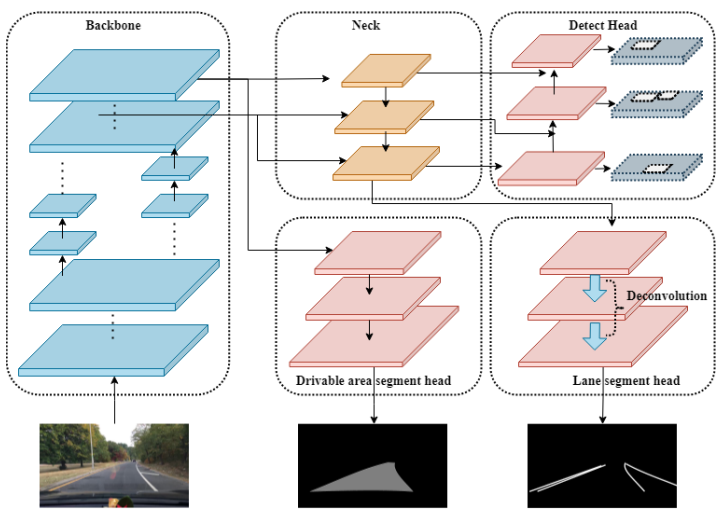
The detection happens according to an anchor-based multi-scale scheme. This network combines features from FPN and PAN (Path Aggregation Network) and runs detection on the multi-scale feature maps to obtain bounding boxes at different scales.
Then, the detection heads detect the offsets of the position (x, y coordinates) and the scaled width and height. This is similar to most of the YOLO architectures which carry out detection in a similar manner. Also, the detection head outputs the probability and the confidence for each class.
YOLOP (v1) uses the same features from the last layer of the neck for both, drivable area segmentation and lane segmentation. But YOLOPv2 uses different heads and features from different semantic levels as well. The head of the drivable area segmentation branches out prior to the FPN module. It helps to get features from less deeper layers of the network. Due to this the drivable area segmentation feature maps also require upsampling layers to accommodate for this loss.
The lane segmentation head branches out from the FPN layer. This helps it extract features from the deeper level. Further, it is aided by deconvolution in the decoder stage for improved performance.
Loss Functions to Train YOLOPv2
YOLOPv2 uses three different losses for the three tasks.
Detection Loss
The detection loss is a weighted sum of classification loss, object loss, and bounding box loss.
$$
L_{det} = \alpha_1L_{class} + \alpha_2L_{obj} + \alpha_3L_{box}
$$
For the calculation of the classification loss and object loss, the focal loss is used. This addresses the issue of the class imbalance problem.
In the above formula, \(\alpha_1\), \(\alpha_2\), and \(\alpha_3\) are the three weight values assigned to each of the loss components.
Drivable Area Segmentation Loss
For drivable area segmentation, the authors use cross-entropy loss.
This aims to minimize the classification error between the predicted values and the ground-truth pixels.
Lane Segmentation Loss
Lane segmentation is a difficult task. Because the lines are thin, there will be a lot of background pixels. This is a hard problem where the model has to focus on the pixels containing the lane lines only. This leads the authors of YOLOPv2 to use the Focal loss for lane segmentation.
As both, drivable area segmentation, and lane segmentation are difficult tasks, the authors try to combine the two. They call it a hybrid loss function.
One is Focal loss which can focus on the hard examples to improve lane detection accuracy. Another is a hybrid loss which is a combination of Focal loss and Dice loss.
Dice loss helps to alleviate the class imbalance problem and Focal loss helps to focus on the hard examples.
The final loss function looks like the following.

In the above figure, Dice loss is used for drivable area segmentation, and Focal loss is used for lane segmentation.
\(\gamma\) is the trade-off between Dice and Focal loss. \(C\) implies the number of categories, which is 2 in this case, the drivable area class, and the lane segmentation class. \(TP_{p(c)}\), \(FN_{p(c)}\), \(FP_{p(c)}\) are the True Positive, False Negative, and the False Positive respectively.
YOLOPv2 Training Experiments and Results
All the training experiments were run on an NVIDIA TESLA V100 GPU with the PyTorch deep learning framework.
The authors use the BDD100K dataset for training. It is one of the largest open-source datasets for benchmarking models dealing with autonomous driving.
The dataset was divided into 70000 training images, 10000 validation images, and 20000 test images.
Training Parameters and Hyperparameters
The following table shows all the configurations used for training the YOLOPv2 model.
| Dataset | BDD100K |
| Initial learning rate | 0.01 |
| Learning rate policy | Cosine Annealing |
| Warm restart | First 3 epochs |
| Momentum | 0.937 |
| Weight Decay | 0.005 |
| Epochs | 300 |
| Training image size | 640x640x3 |
| Test image size | 640x384x3 |
While training, Mosaic and Mixup augmentations are also used.
Results
Here, we will discuss the results for FPS, traffic object detection, drivable area segmentation, and lane segmentation. We will also compare the results with other similar models.
FPS Results
The following table from the paper shows the FPS comparison with other models.

It is clear that even with more parameters, YOLOPv2 is faster than both, HybridNets, and YOLOP. This is possible due to the efficient E-ELAN backbone network.
Traffic Object Detection Results
For evaluation, the authors use the mAP50 object detection metric, which is the same as was in the case of YOLOP.
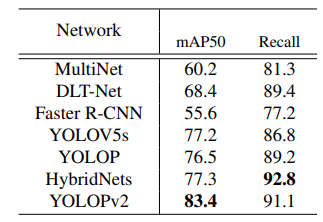
The above table from the paper shows that YOLOPv2 achieves 83.4 mAP50 which is higher than the other models. Although it has a slightly low recall compared to HybridNets.
Drivable Area Segmentation Results
The authors use the MIoU (Mean Intersection over Union) for drivable area segmentation.
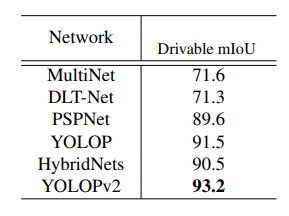
Here, the YOLOPv2 model is 2 points ahead compared to the previous best model, which is YOLOP. For drivable area segmentation, YOLOPv2 is able to achieve 93.5 MIoU which is quite impressive.
Lane Segmentation Results
There are many deep learning models focused on just lane segmentation. Let’s see how YOLOPv2 stacks up against them.
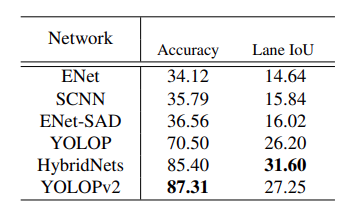
It seems like, although HybridNets has higher Lane IoU, YOLOPv2 has higher accuracy for lane detection.
The above numerical results show that YOLOPv2 is better than other models in most areas. Let’s check out some visual results as well.
Visual Results
The following image from the paper shows the visual results of YOLOPV2 and compares them against YOLOP and HybridNets.
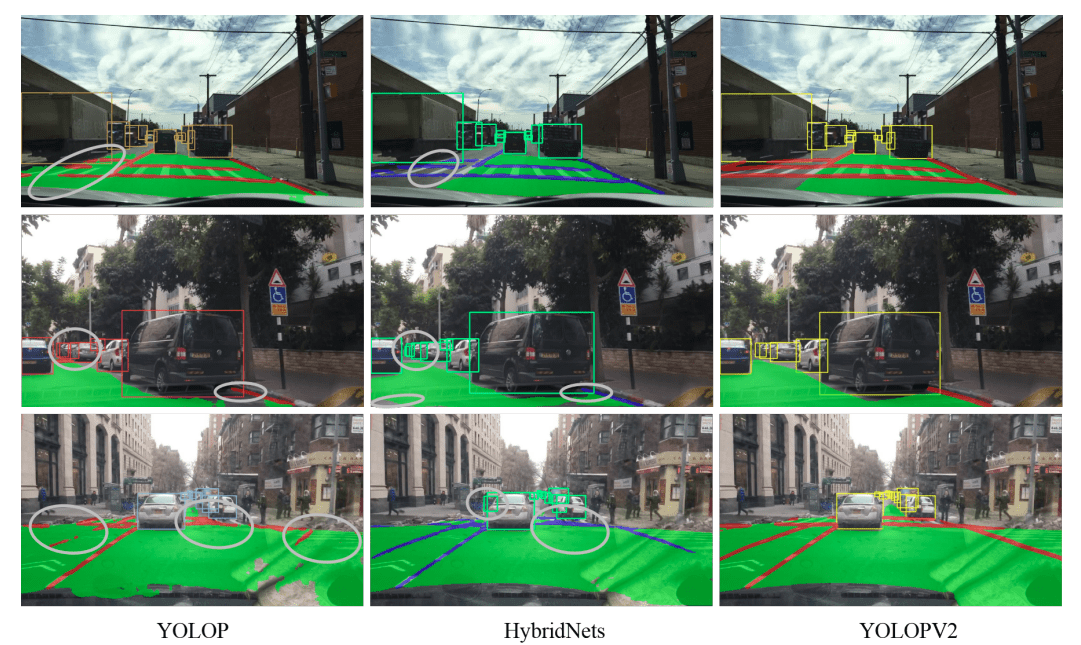
For drivable area segmentation, and lane detection, both, YOLOP, and HybridNets are making mistakes in the difficult scenes. Whereas, the YOLOPv2 predictions are almost perfect.
For traffic object detection, both, YOLOP and HybridNets are detecting extra objects. But there are no such cases in the YOLOPv2 detections.
Now, let’s take a look at some night-time results.

Here, YOLOP and HybridNets are missing out on the truck in the first row but YOLOPv2 (third column) is able to detect that.
In the second and third rows, we can see mistakes by YOLOP and HybridNets in the drivable area segmentation and lane detection. But YOLOPv2 is able to segment everything pretty accurately.
Seems like YOLOPv2 is able to perform much better in real-world scenarios compared to the previous state-of-the-art models.
Summary and Conclusion
In this article, we discussed the YOLOPv2 paper. We started with why panoptic driving perception is difficult and what models are currently available. Then we discussed the YOLOPv2 model architecture, training criteria, and the results. We also saw how YOLOPv2 performs better in certain areas compared to the previous models. I hope that this article was helpful to you.
If you have any doubts, thoughts, or suggestions, please leave them in the comment section. I will surely address them.
You can contact me using the Contact section. You can also find me on LinkedIn, and X.
References
- YOLOPv2: Better, Faster, Stronger for Panoptic Driving Perception
- YOLOP: You Only Look Once for Panoptic Driving Perception
- HybridNets: End-to-End Perception Network
- BDD100k Dataset

1 thought on “YOLOPv2 for Better, Faster, Stronger Panoptic Driving Perception – Paper Explanation”