

Large language models are pretrained on terabytes of language datasets. However, the pretraining dataset and strategy teach the model to generate the next token or word. In a real world sense, this is not much useful. Because in the end, we want to accomplish a task using the LLM, either through chat or instruction. We can do so through fine-tuning an LLM. Generally, we call this instruction tuning of the language model. To this end, in this article, we will use the OPT-125M model for instruction tuning.

Note: This is the very first article on tuning/using Language Models/Large Language Models. Here, we will not focus on the theory much, but rather on the dataset used, the code, and understanding the pipeline to get started right away. Specifically we will use a sample of the Open Assistant dataset along with the Hugging Face Supervised Fine-Tuning Trainer.
We will cover the following topics in this article
- We will start with a short discussion of the dataset that we will use for instruction tuning of the OPT-125 model.
- Next, we will discuss various ways to prepare the dataset for instruction tuning a language model.
- Then, we will move to the coding part. Here, we will cover:
- Dataset and training configurations.
- Dataset preparation.
- Training the OPT-125 model using Hugging Face SFT Trainer.
- Finally, we will carry out inference using the trained model and finish with some potential improvement points.
The Open Assistant Guanaco Dataset
In this article, we will use the Open Assistant Guanaco dataset by Tim Dettmers that is available on Hugging Face. It is a subset of the popular Open Assistant dataset to train LLMs for instruction following.
The dataset that we will use contains 10000 samples roughly. This comes to around 9800 training and 500 validation samples. Unlike the original dataset, it contains only the text field which makes it easier for us to experiment with the dataset.
For example, here is a sample from the dataset.

As we can see, these are conversations between a human and a language model (assistant). The ### Human: tag precedes each human instruction/chat. And the LLM’s answer is preceded by the ### Assistant: tag. These tags or separators are crucial to teach the model which part of the conversation it should contribute to.
There are hundreds of instruction following/assistant/chat datasets right now on Hugging Face. And the above is just one format. Throughout the next few articles, we will uncover more varied datasets.
Not just chat, we can also train LLMs for specific tasks like text classification, question answering, and even text summarization.
Want to know how to use a transformer encoder for text classification? The following articles will surely help you.
Ways to Prepare Dataset for Instruction Tuning a Model
There are several ways to prepare a dataset for instruction tuning of the OPT-125M model. However, as we will be using the Supervised Fine-Tuning Trainer (SFT) pipeline here, there are two primary methods.
One is per sample padding where we pad each row according to the maximum context length that we provided. This means that if the batch size is 8, then there will be 8 samples in a batch and each sample will be padded independently with the padding token used by the tokenizer. With the Hugging Face SFT pipeline, we can achieve this using packing=False when initializing the Trainer pipeline.
Here is an example of the same.

The next method is continuous random sampling from the dataset, just like it happens in pretraining of the LLMs. Here, we sample data from each row randomly and append the end of sequence (EOS) token after each row’s data, then continue adding another sample until the context length is reached. In this case, if the batch size is 8, then each sample in a batch can contain chats from two different rows separated by the EOS token. Here is an example to make the concept clearer.
In the above example, the is the EOS token. We can achieve this by using packing=True when initializing the SFT Trainer pipeline.
It is worthwhile to note that in each case, the model learns to predict the next token. However, in most cases, we will get better results with the latter method as the model always gets to predict a token from the real conversation rather than a pad token as may happen in the former case.
In this tutorial, we will cover the usage of the latter method.
Project Directory Structure
Let’s take a look at the directory structure of the project.
├── outputs │ ├── opt_openassistant_guanaco_packed │ │ ├── best_model │ │ │ ├── config.json │ │ │ ├── generation_config.json │ │ │ ├── merges.txt │ │ │ ├── model.safetensors │ │ │ ├── special_tokens_map.json │ │ │ ├── tokenizer_config.json │ │ │ └── vocab.json │ │ └── logs │ │ ├── checkpoint-1358 │ │ ├── checkpoint-3390 │ │ └── runs │ └── opt_openassistant_guanaco_per_sample_padding │ ├── best_model │ │ ├── config.json │ │ ├── generation_config.json │ │ ├── merges.txt │ │ ├── model.safetensors │ │ ├── special_tokens_map.json │ │ ├── tokenizer_config.json │ │ └── vocab.json │ └── logs │ ├── checkpoint-1231 │ ├── checkpoint-3070 │ └── runs ├── inference.ipynb ├── opt_openassistant_guanaco_packed_text.ipynb └── opt_openassistant_guanaco_per_sample_padding.ipynb
- In the root project directory, we have three notebooks. Two of them are training notebooks, one for packed sample training, one for per sample padded training, and another inference notebook. Although we will cover the packed sample training here, both of them are available to download for the readers.
- The
outputsdirectory contains the best model and logs.
All the notebooks and the packed sample training models are available for downloading via the download section.
Download Code
Libraries and Dependencies
We will use PyTorch as the base framework here. On top of that, there are several Hugging Face libraries that we need for running the notebooks successfully. They are:
acceleratetransformerstrldatasets
You can use the requirements.txt file that comes with the code base to install all of them in one go.
pip install -r requirements.txt
That’s all we need to set up and now we can focus on the coding section.
Instruction Tuning OPT-125M
As discussed earlier, we will use the OPT-125M model for instruction tuning. This model is from Meta AI, published in the paper OPT: Open Pre-trained Transformer Language Models. It is the smallest model in the family of OPT models and is perfect for starting and experimenting with instruction tuning.
If you wish to know to fine-tune a GPT2 model for text generation, check out the previous article where we fine-tune DistIlGPT2 to generate detective stories.
All the code in the following training sections are present in the opt_openassistant_guanaco_packed_text.ipynb notebook.
Import Statements
Let’s start with importing the necessary modules and libraries.
import os
import torch
from datasets import load_dataset
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
TrainingArguments,
pipeline,
logging,
)
from trl import SFTTrainer
The SFTTrainer class from the trl library is one of the important ones. This library is specifically meant for fine-tuning LLMs.
On a side note, if we can prepare the dataset carefully, then we can also use the default Trainer API to fine-tune language models in a supervised manner for chat and instruction following. We will cover that in a future post.
Training and Dataset Hyperparameters
The following are all the configurations that we are going to use for dataset preparation and training our OPT-125M model for instruction following.
epochs = 10 batch_size = 8 num_workers = os.cpu_count() bf16 = False fp16 = True gradient_accumulation_steps = 4 context_length = 512 learning_rate = 0.0001 model_name = 'facebook/opt-125m' out_dir = 'outputs/opt_openassistant_guanaco'
Most of them are self explanatory. Let’s go through some of the more important ones from above:
bf16andfp16: Instead of training in full precision (FP32), using either BF16 or FP16 consumes less GPU memory and is often faster to train. Newer NVIDIA GPUs (RTX series/Ampere architecture and later) allow the usage of BF16 which is computationally more stable compared to FP16 training. In case you training on GTX GPUs, or P100, or T4, consider using FP16. At a time, only one of them can beTrue.gradient_accumulation_steps: Although we mention a batch size, we can additionally store the gradients before a backpropagation step. Withgradient_accumulation_stepswe can tell the trainer API how many batches to wait before a backpropagation step. So, in this case, our total batch size becomes 8*4=32. This makes training more stable and in LLM training, higher batch size often results in a better training run.context_length: Each sample (along with the packing option that we use) can be several tokens long. The GPU may not be able to accomodate very long samples at a time. Mentioning a context length tells the tokenizer where to cut off samples and which samples to pad in case a sample is smaller than the context length.model_name: This is the tag of the OPT-125M model on the Hugging Face Hub.
Loading the Open Assistant Guanaco Dataset
Using the load_dataset function, it is extremely simple to load any dataset available on the Hugging Face hub.
dataset = load_dataset('timdettmers/openassistant-guanaco')
print(dataset)
Printing the dataset shows the number of samples and the splits that it contains.

Now, let’s check one sample from the training set.
print(dataset['train']['text'][0])
This is a truncated part of the larger human-assistant chat.
### Human: Can you write a short introduction about the relevance of the term "monopsony" in economics? Please use examples related to potential monopsonies in the labour market and cite relevant research.### Assistant: "Monopsony" refers to a market structure where there is only one buyer for a particular good or service. In economics, this term is particularly relevant in the labor market, where a monopsony employer has significant power over the wages and working conditions of their employees. The presence of a monopsony can result in lower wages and reduced employment opportunities for workers, as the employer has little incentive to increase wages or provide better working conditions.
As we can see, each sample starts with a ### Human: tag, and each assistant answer starts with a ### Assistant: tag. There may be several instances where one conversation continues in the following row. I highly recommend going through some of the samples in the dataset to get a clearer picture of the structure and flow.
Preparing the OPT-125M Model for Instruction Tuning
Next, we need to load the OPT-125M model.
if bf16:
model = AutoModelForCausalLM.from_pretrained(model_name).to(dtype=torch.bfloat16)
else:
model = AutoModelForCausalLM.from_pretrained(model_name)
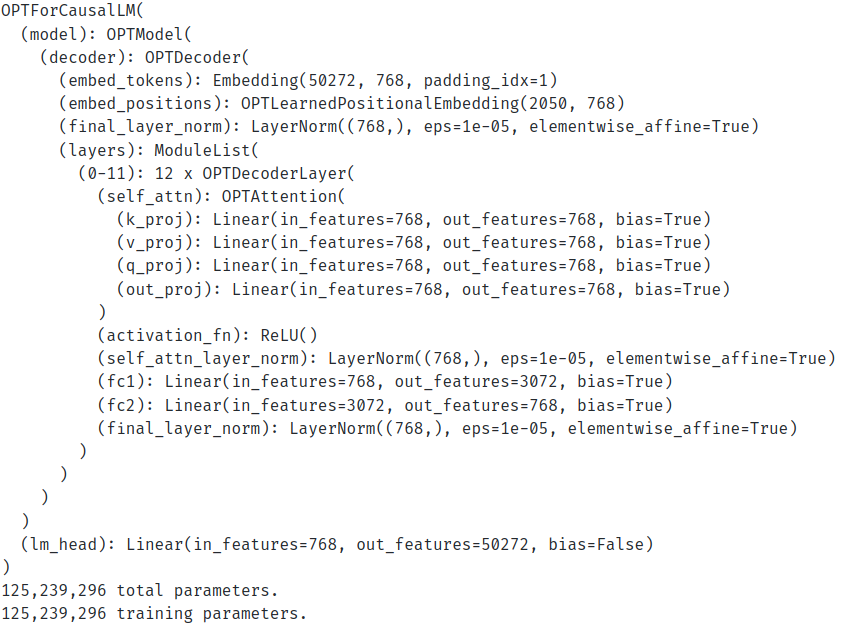
In the above code block, we load the model based on whether we choose FP16 or BF16 in the configurations. Further, the following is the architecture and the number of parameters in the model.
Loading the Tokenizer
When using the SFTTrainer API, we simply need to load the tokenizer and need not tokenize any samples ourselves. The trainer API will handle that on its own.
tokenizer = AutoTokenizer.from_pretrained(
model_name,
trust_remote_code=True,
use_fast=False
)
That’s all we need to do for the tokenization here.
Note that we are not covering the details of tokenizers here. However, the following articles can help you clear concepts of creating a simple tokenizer for the next character & next word generation using LSTM, and next word generation using Transformers.
- Character Level Text Generation using LSTM
- Word Level Text Generation using LSTM
- Text Generation with Transformers
Defining the Training Arguments, the Trainer API, and Training the Model
The final step is training the OPT-125M to follow instructions, But first, we need to define the training arguments and the trainer API.
The following code block initializes the TrainingArguments with all the desired configurations.
training_args = TrainingArguments(
output_dir=f"{out_dir}/logs",
evaluation_strategy='epoch',
weight_decay=0.01,
load_best_model_at_end=True,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
logging_strategy='epoch',
save_strategy='epoch',
save_total_limit=2,
bf16=bf16,
fp16=fp16,
report_to='tensorboard',
dataloader_num_workers=num_workers,
gradient_accumulation_steps=gradient_accumulation_steps,
learning_rate=learning_rate,
lr_scheduler_type='constant',
num_train_epochs=epochs
)
Next is initializing the SFTTrainer.
trainer = SFTTrainer(
model=model,
train_dataset=dataset['train'],
eval_dataset=dataset['test'],
dataset_text_field='text',
max_seq_length=context_length,
tokenizer=tokenizer,
args=training_args,
packing=True
)
This part is important when using the SFT Trainer API. Let’s go through the arguments.
train_datasetandeval_dataset: These are training and test attributes of the current dataset. However, they can also be different dataset instances, in case we prepare our custom dataset.dataset_text: If we look at the dataset instance, we can observe that each sample is within thetextfield/column. This is what the argument is expecting. It needs to know from which field to extract the data if there are multiple fields in a dataset.packing: As discussed at the beginning of the article, we are usingpacking=Truewhich will append several samples together until thecontext_lengthis reached. Mostly, it tries to tie together samples of similar lengths.
There is one important point here. We did not prepare the dataset manually and do not know how the sentences are structured before being fed to the tokenizer. However, we can check that using the get_train_dataloader method of the trainer instance.
dataloader = trainer.get_train_dataloader()
for i, sample in enumerate(dataloader):
print(tokenizer.decode(sample['input_ids'][0]))
print('#'*50)
if i == 5:
break
The code block prints the first sample from 5 batches of the prepared dataset.
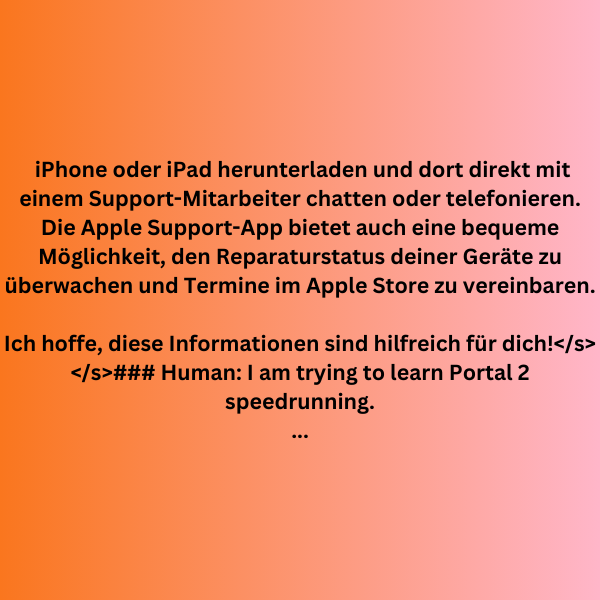
Here is a sample.
iPhone oder iPad herunterladen und dort direkt mit einem Support-Mitarbeiter chatten oder telefonieren. Die Apple Support-App bietet auch eine bequeme Möglichkeit, den Reparaturstatus deiner Geräte zu überwachen und Termine im Apple Store zu vereinbaren. Ich hoffe, diese Informationen sind hilfreich für dich!### Human: I am trying to learn Portal 2 speedrunning. Can you help me with some of the basics, such as bhopping?### Assistant: Sure, I can help you with that! Bhopping, or bunny hopping, is a technique in Portal 2 speedrunning where you jump repeatedly in order to maintain momentum and move faster. Here are some basic steps to follow: 1. Begin by moving forward and jumping. As you land, jump again immediately. 2. As you jump, strafe to one side using the A or D key on your keyboard. This will help you maintain your speed. 3. As soon as you land, jump again and strafe to the other side using the opposite key. 4. Repeat this pattern, jumping and strafing back and forth, to maintain your speed. It can take some practice to get the timing right, but once you master the technique, it can be very useful for quickly moving through levels in Portal 2. Here are a few additional tips for successful bhopping: - Try to time your jumps so that you land just as your previous jump ends. This will help you maintain your speed and avoid losing momentum. - Use your mouse to adjust your view as you jump, so that you can see where you're going and avoid obstacles. - Be careful not to jump too often or you may lose control of your character and slow down. - Practice on different surfaces, as some surfaces may be easier to bhop on than others. Good luck with your speedrunning!### Human: I cannot, sadly.### Human: Tại sao con đường thông thương cổ đại được gọi là “Con đường t
There are some important points to observe here.
- Several samples have been appended randomly.
- After each conversation ends, the end of sequence token (
) is appended by the tokenizer. This is important during the training phase, as it tells the model where a conversation ends.
Start the Training
Now, we simply need to call the train method to start the training.
history = trainer.train()
Here are the logs.
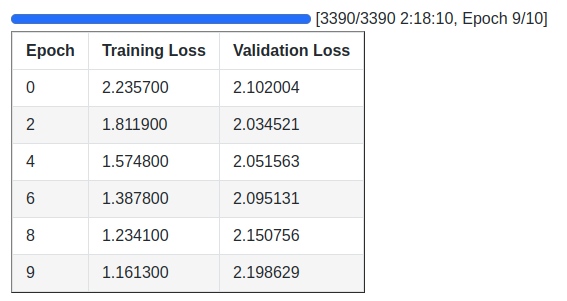
The model reached the lowest validation loss on the second epoch. The following is the validation loss graph from the training run.
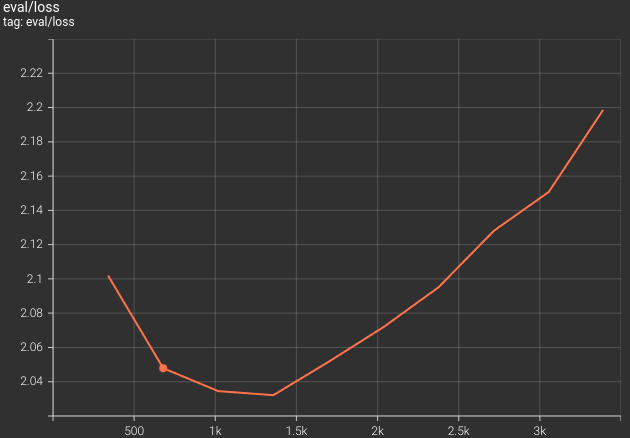
It looks like we can use a learning rate scheduler and a larger dataset to train an even better model. In case you run the experiments, use the comment section to let others know of your findings.
Finally, we save the best model and the tokenizer to disk.
model.save_pretrained(f"{out_dir}/best_model")
tokenizer.save_pretrained(f"{out_dir}/best_model")
We are done with the training. Right now, we can move to the inference section.
Inference using the Instruction Tuned OPT-125M
The inference code resides in the inference.ipynb notebook and it is extremely simple to load the model and run inference.
First, we import all the necessary modules, define the computation device, and load the trained model & and the tokenizer.
from transformers import (
AutoModelForCausalLM,
logging,
pipeline,
AutoTokenizer
)
import torch
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = AutoModelForCausalLM.from_pretrained('outputs/opt_openassistant_guanaco_packed/best_model/')
tokenizer = AutoTokenizer.from_pretrained('outputs/opt_openassistant_guanaco_packed/best_model/')
Second, we initialize the text generation pipeline. The Transformers library makes it seamless to generate text using any fine-tuned model.
pipe = pipeline(
task='text-generation',
model=model,
tokenizer=tokenizer,
max_length=300, # Prompt + new tokens to generate.
device_map=device
)
We pass the task, the model & tokenizer, and maximum length of the prompt along with the generated text and the computation device as arguments.
Third, we need to define a prompt template. Remember that our dataset had the coversation in a specific format. We need to replicate the same during inference to get proper response from the instruction tuned OPT-125 model.
template = '### Human: {}### Assistant:'
Later, we will format the text with the human prompt.
Finally, define a prompt, format the prompt template, and generate the text.
prompt = 'Write a few tips for staying healthy.'
prompt = template.format(prompt)
outputs = pipe(
prompt,
do_sample=True,
temperature=0.7,
top_k=50,
top_p=0.95,
repetition_penalty=1.1,
)
print(outputs[0]['generated_text'])
We also pass some additional argumets to the text generation pipeline.
do_sample: This argument enables different sampling methods during text generation. I would recommend going through the ducumentation to get a thorough overview as defining each sampling method is out of scope of this article.temperature: A higher temparature adds variation to the generated text.top_kandtop_p: Both of these are sampling methods and are closely connected with thedo_sampleargument.repetition_penalty: Sometimes, models will just keep on repeating the same text during generation. We can provide a repitition penalty (a value higher than the default 1.0) to avoid repititions in the generated content.
Here are the points generated by the model for the above prompt.

The model generates some really good points for staying healthy. The only issue is that the model does not finish the conversation properly. Perhaps using a larger model, or larger dataset, and training the current model for longer can rectify this as well. We can also add some manual post-processing to remove the unfinished sentences.
Further Steps
- For further experiments, we can add learning rate scheduling, use larger context lengths, and train for longer.
- We trained a smaller (OPT-125M) model for instruction tuning. We can also try larger models like the OPT-350M model and check its performance on performance tuning.
Summary and Conclusion
In this article, we trained the OPT-125M model for instruction tuning. Starting from the discussion of the dataset, format of the text, to training and inference, we covered each part in detail. We also discussed some further steps that can be taken to train a better model. I hope that this article was worth your time.
If you have any doubts, thoughts, or suggestions, please leave them in the comment section. I will surely address them.
You can contact me using the Contact section. You can also find me on LinkedIn, and X.
References:

7 thoughts on “Instruction Tuning OPT-125M”