
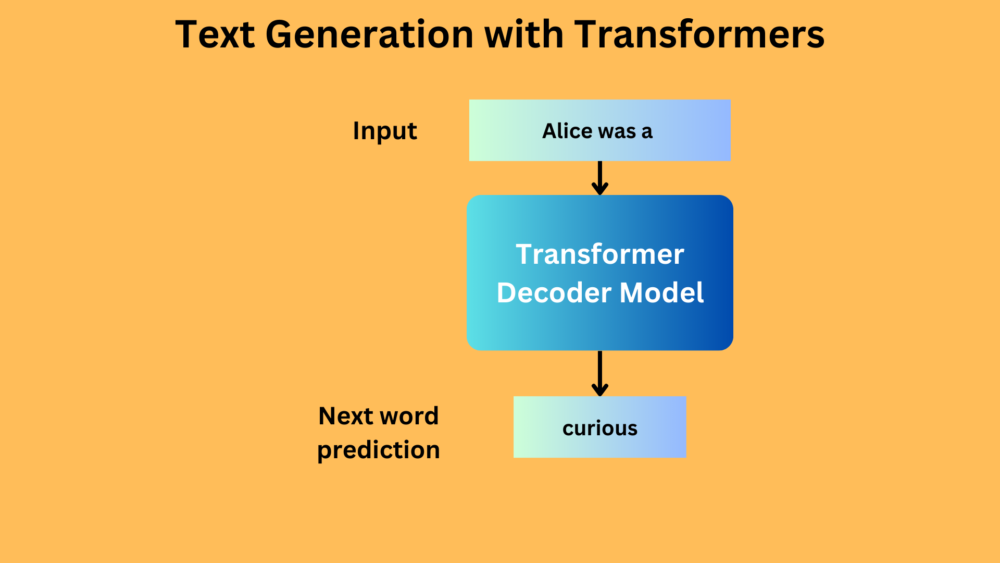
In this blog post, we will create the simplest possible pipeline for text generation with Transformers.
This is the third blog post in the series. In the last two blog posts, we covered text generation using LSTM.
Here, we will create the pipeline to train an autoregressive Transformer model for text generation using PyTorch. This is the perfect post for you if you want to train your own Transformer model from scratch for text generation (without all the bells and whistles).
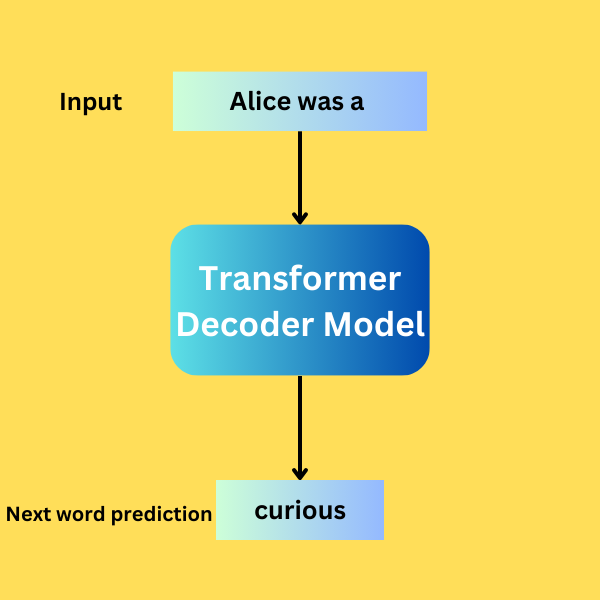
We will cover the following topics here
- We will start with the dataset preparation. The data is present in a single text file from which we will create the vocabulary, dataset, and data loader.
- Next, we will use the torch.nn module to create the text generation Transformer model. PyTorch provides the individual components to build Transformers. We will combine them to create our autoregressive decoder only model.
- Then comes the training part. Here our objective will be to overfit the model on the training data.
- Finally, we will run inference using the trained model. If we are successful in training the Transformer model, we should be able to prompt the model into generating the same text as the training data.
Note: This is a beginner friendly post that covers the essential components of getting started with text generation from scratch. While doing so, we will create the most minimalistic data loading pipeline along with a simple decoder-only Transformer model. During inference, we will use a greedy approach to text generation.
Training Text Generation Transformers
We will go through all the details of training a text generation transformer model with a code-first approach. So, let’s directly jump into writing the code.
Download Code
Let’s start with importing all the libraries and modules.
import torch import torch.nn as nn import torch.optim as optim import math import torch.nn.functional as F from torch.utils.data import Dataset, DataLoader from collections import Counter
PyTorch is the only main dependency that we have for this blog post. We do not need any other external libraries.
Dataset Preparation
We will be creating a word level vocabulary from the text file that we have. This is going to be very similar to the process we had in the word level LSTM dataset preparation process in the previous post.
# Dataset Preparation
with open('data/alice_1.txt', 'r', encoding='utf-8') as file:
text = file.read()
# Tokenize the text into words
words = text.split()
word_counts = Counter(words)
vocab = list(word_counts.keys())
vocab_size = len(vocab)
word_to_int = {word: i for i, word in enumerate(vocab)}
int_to_word = {i: word for word, i in word_to_int.items()}
SEQUENCE_LENGTH = 64
samples = [words[i:i+SEQUENCE_LENGTH+1] for i in range(len(words)-SEQUENCE_LENGTH)]
print(vocab)
print(word_to_int)
print(int_to_word)
Firstly, we read the text file from the disk and split all the words based on the whitespace character. Secondly, we use the Counter class to count the instances of all the words in the words list. Next, we create a vocabulary of all the unique words and store them in the vocab list. Following that, we create a word to integer mapping and store it in the word_to_int dictionary. Similarly, we create a reverse mapping and store it in the int_to_word dictionary. These two will be used while preparing the data loaders and during inference respectively.
Here is a sample of the word_to_int mapping that we created above.

As we can see, each word maps to a corresponding integer value.
In the next step, we create a 2D list and call it samples. Each list in this contains 64 words because we provide the SEQUENCE_LENGTH to be 64. Each list is shifted to the right by one word after the first one. To create a clearer picture, here is an image.

In the above image, the first sample starts from Alice and stops at called. As we shift each sample to the right by one word, the second sample starts from was.
Creating the Dataset Class and the Data Loader
Next, we need to create the custom dataset class.
class TextDataset(Dataset):
def __init__(self, samples, word_to_int):
self.samples = samples
self.word_to_int = word_to_int
def __len__(self):
return len(self.samples)
def __getitem__(self, idx):
sample = self.samples[idx]
input_seq = torch.LongTensor([self.word_to_int[word] for word in sample[:-1]])
target_seq = torch.LongTensor([self.word_to_int[word] for word in sample[1:]])
return input_seq, target_seq
The class accepts the samples which is the 2D list containing the sequences. Along with that, it also accepts the word_to_int dictionary for mapping.
In the __getitem__ method, input_seq represents the input to the model from a sample excluding the last word. The model has to predict the next word as the target_seq is the output sequence shifted one position to the right. This is the basis of language modeling using Transformers where the model has to predict the next word given a set of sequences.
Finally, we create the dataset instance and the data loader.
BATCH_SIZE = 32
dataset = TextDataset(samples, word_to_int)
dataloader = DataLoader(
dataset,
batch_size=BATCH_SIZE,
shuffle=True,
)
print(dataset[1])
The dataloader has a batch size of 32 and the following image shows an example.

From the above image, it is clear that the input sequence starts from 1 while the target sequence starts from 2 and stops at 56.
This is all we need to prepare the dataset for training Transformers for text generation.
The Decoder Only Text Generation Transformer Model
Now, let’s get to the most important part of the blog post, the Transformer model.
The original Transformer neural network by Vaswani et al. was meant for sequence transduction.
It contained both, an encoder and a decoder which could perform tasks like language translation.
However, for text generation, we only need the decoder part of the model. Let’s create the model using the torch.nn module and then get into the explanation as we do so.
def generate_square_subsequent_mask(sz):
"""
Generate a square mask for the sequence. The masked positions are filled with float('-inf').
Unmasked positions are filled with float(0.0).
"""
mask = (torch.triu(torch.ones(sz, sz)) == 1).transpose(0, 1)
mask = mask.float().masked_fill(mask == 0, float('-inf')).masked_fill(mask == 1, float(0.0))
return mask
The above function is a utility function that creates a mask that is used in the attention mechanism of the Transformer model. It ensures that while predicting the next word, the model sees the context only till the previous words. This is a key concept in decoder-only autoregressive text generation models.
class PositionalEncoding(nn.Module):
def __init__(self, max_len, d_model, dropout=0.1):
"""
:param max_len: Input length sequence.
:param d_model: Embedding dimension.
:param dropout: Dropout value (default=0.1)
"""
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
"""
Inputs of forward function
:param x: the sequence fed to the positional encoder model (required).
Shape:
x: [sequence length, batch size, embed dim]
output: [sequence length, batch size, embed dim]
"""
x = x + self.pe[:, :x.size(1)]
return self.dropout(x)
The above class defines the Positional Encoding for the tokens.
But why is Positional Encoding important?
Transformer models do not have a recurrence mechanism like RNNs and LSTMs. So, inherently, they do not have any concept about the sequence of the tokens. This is where Positional Encoding comes in. The pe variable stores the positions of all the possible positions in a sequence.
There is one thing to note though. In the forward method the positional encodings are sliced to match the input size and added to the input embeddings, which adds information about the position of each token in the sequence to its embedding.
The Final Text Generation Transformers Model
class TextGen(nn.Module):
def __init__(self, vocab_size, embed_dim, num_layers, num_heads):
super(TextGen, self).__init__()
self.pos_encoder = PositionalEncoding(max_len=SEQUENCE_LENGTH, d_model=embed_dim)
self.emb = nn.Embedding(vocab_size, embed_dim)
self.decoder_layer = nn.TransformerDecoderLayer(
d_model=embed_dim,
nhead=num_heads,
batch_first=True
)
self.decoder = nn.TransformerDecoder(
decoder_layer=self.decoder_layer,
num_layers=num_layers,
)
self.linear = nn.Linear(embed_dim, vocab_size)
self.dropout = nn.Dropout(0.2)
# Positional encoding is required. Else the model does not learn.
def forward(self, x):
emb = self.emb(x)
# Generate input sequence mask with shape (SEQUENCE_LENGTH, SEQUENCE_LENGTH)
input_mask = generate_square_subsequent_mask(x.size(1)).to(x.device)
x = self.pos_encoder(emb)
x = self.decoder(x, memory=x, tgt_mask=input_mask, memory_mask=input_mask)
x = self.dropout(x)
out = self.linear(x)
return out
The TextGen class creates the final text generation Transformer model by combining the above components and adding the missing ones as well.
Firstly, we define the mandatory embedding layer that will create a vector embedding for each token. Secondly, the positional encoding step kicks in. We pass all the embeddings through the pos_encoder instance to obtain the positions of all the token embeddings. Then, we invoke the decoder part of the model that we have defined using nn.TransformerDecoderLayer and nn.TransformerDecoder. As we do not have an encoder, the memory and memory_mask are the same as the decoder positional embeddings and the decoder input mask. Otherwise, they would have been the corresponding components from the encoder.
Finally, we pass the model through a linear layer where the number of output features is the same as the vocabulary size of the dataset.
Training the Model
Before we train the model, let’s define some hyperparameters and initialize the Transformer model as well.
epochs = 100
learning_rate = 0.001
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = TextGen(
vocab_size=vocab_size,
embed_dim=100,
num_layers=2,
num_heads=2,
).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
print(model)
# Total parameters and trainable parameters.
total_params = sum(p.numel() for p in model.parameters())
print(f"{total_params:,} total parameters.")
total_trainable_params = sum(
p.numel() for p in model.parameters() if p.requires_grad)
print(f"{total_trainable_params:,} training parameters.\n")
We will be training the model for 100 epochs and the optimizer learning rate is going to be 0.001. The final Transformer model contains an embedding size of 100, two decoder layers, and 2 attention heads. This builds a model with approximately 1.56 million parameters.
Now, we just need to define a simple training loop and start the training.
# Training
def train(model, epochs, dataloader, criterion):
model.train()
for epoch in range(epochs):
running_loss = 0
for input_seq, target_seq in dataloader:
input_seq, target_seq = input_seq.to(device), target_seq.to(device)
outputs = model(input_seq)
target_seq = target_seq.contiguous().view(-1)
outputs = outputs.view(-1, vocab_size)
loss = criterion(outputs, target_seq.view(-1))
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss += loss.detach().cpu().numpy()
epoch_loss = running_loss / len(dataloader)
print(f"Epoch {epoch} loss: {epoch_loss:.3f}")
train(model, epochs, dataloader, criterion)
One thing to note in the training loop is the shape of the targets and the outputs before calculating the loss. We need to ensure that the shape of the targets is [batch_size x sequence_length] in flattened format and the shape of the outputs is [batch_size x sequence_length, vocab_size].
By the end of training, the loss is 0.027.
Inference using Text Generation Transformers
As we have trained our model, we can run inference. We did not train on a big dataset. Furthermore, our aim here is to check whether all of the training procedures went fine or not. So, we will try to generate the same text as in the training data.
Let’s start with defining a few helper functions.
def return_int_vector(text):
words = text.split()
input_seq = torch.LongTensor([word_to_int[word] for word in words[-SEQUENCE_LENGTH:]]).unsqueeze(0)
return input_seq
def sample_next(predictions):
"""
Greedy sampling.
"""
# Greedy approach.
probabilities = F.softmax(predictions[:, -1, :], dim=-1).cpu()
next_token = torch.argmax(probabilities)
return int(next_token.cpu())
def text_generator(sentence, generate_length):
model.eval()
sample = sentence
for i in range(generate_length):
int_vector = return_int_vector(sample)
if len(int_vector) >= SEQUENCE_LENGTH - 1:
break
input_tensor = int_vector.to(device)
with torch.no_grad():
predictions = model(input_tensor)
next_token = sample_next(predictions)
sample += ' ' + int_to_word[next_token]
print(sample)
print('\n')
We have defined three helper functions in the above code block.
return_int_vectorsimply returns the tensor format of a sentence by first breaking the sentence into words and then mapping each word to its integer format in theword_to_intdictionary.sample_nextapplies a greedy decoding approach to the model’s output. After obtaining the output, we apply the Softmax function and just extract the integer with the highest confidence score and map it to the corresponding word.- The
text_generatorfunction drives the entire inference pipeline. It calls thereturn_int_vectorfunction, forward passes the tensor through the model, and samples the next token based on the output token from thesample_nextfunction. After we extract each word in a loop, we add it to the original sentence and then again feed it to the model.
Finally, let’s define a sample sentence and carry out the inference.
sentences = [
"Alice was a"
]
generate_length = 100
for sentence in sentences:
print(f"PROMPT: {sentence}")
text_generator(sentence, generate_length)
Our model will generate 100 words based on the generate_length variable.
Here is the output.

We can see that the model generates the training data almost perfectly. This implies that our entire model creation and training pipeline is correct.
However, we can do much more here. We can:
- Modularize the code to handle larger datasets.
- Add a better tokenization method instead of the naive word to integer mapping.
- And have a better text generation technique (decoding) during inference.
We will try to explore all of these in future posts.
Summary and Conclusion
In this blog post, we created a simple pipeline for text generation with Transformer models. Starting from the creation of the dataset, training of the model, to the inference, we covered all, though in a simplified manner. We will try to explore advanced techniques and frameworks like Hugging Face in the future. I hope this blog post was useful to you.
If you have any doubts, thoughts, or suggestions, please leave them in the comment section. I will surely address them.
You can contact me using the Contact section. You can also find me on LinkedIn, and X.

Thank you, great nice and clean tutorial. Though you call view(-1) one times too often, it doesnt matter because the shapes still match but it is confusing. It occurs in line loss = criterion(outputs, target_seq.view(-1))
Thanks for the review Lukas. I will check it out.
Thank you for this powerful blog.
I’m learning Deep Learning and found this helpful.
I am glad that is helping you.