
The world of Natural Language Processing is ever-evolving. The quest to generate coherent and contextually relevant text has led to the development of various techniques and models. One such technique is “Word Level Text Generation”. Although Transformers perform best in this domain, we will learn the basics using LSTM. We will build upon the foundations in our previous blog post, “Character Level Text Generation using LSTM”. Continuing from there, we explore generating text at the word level.
While character-level text generation models have their merits, they fall short when producing text that reads fluently and maintains meaningful context, especially in longer sequences. In this follow-up post, we delve into the reasons why word level text generation models are essential for overcoming these limitations.
We will cover the following points in this blog post
- We will start with the shortcomings of character level text generation.
- This will be followed by some of the advantages of word level text generation models.
- Then, we will dive into the coding part.
- Here, first, we will prepare the dataset along with the word level vocabulary.
- The next step is to create the LSTM model that can be trained on the dataset.
- After training, we will run inference to check whether our model has learned the words in our dataset or not.
Note: This is a minimal implementation of an autoregressive LSTM. We do not cover all the caveats needed for a full-fledged text generation pipeline. Our primary aim here is to get up and running with the most important steps needed for training a text generation model from scratch.
The Shortcomings of Character-Level Text Generation
Character-level text generation models are indeed remarkable. However, they are capable of generating only one character at a time. They fall short in real-world complex tasks, because of the following reasons.
- Lack of Context: Character-level models operate at a very granular level, treating each character in isolation. While this allows them to capture the fine details of language, it makes it challenging to maintain the broader context required for coherent text generation. As a result, generating meaningful sentences, paragraphs, or even entire documents can be a daunting task.
- Prone to Random Output: In longer sequences, character-level models are more susceptible to generating gibberish or nonsensical text. The absence of word-level semantics means that characters may combine in ways that defy linguistic rules. This leads to text that lacks coherence and readability.
The Promise of Word Level Text Generation
Word level text generation, on the other hand, addresses these shortcomings by operating at a higher linguistic level. By treating words as the basic building blocks of text, these models can capture meaningful context, structure, and semantics. This makes them better suited for tasks that require longer sequences of coherent text. Here’s why word level text generation is the next logical step in the evolution of text generation models:
- Improved Contextual Understanding: Word-level models can grasp the relationships between words, phrases, and sentences. This leads to text that flows more naturally and maintains a coherent narrative. Furthermore, this makes them ideal for applications like story generation, content creation, and language generation tasks where context is crucial.
- Enhanced Readability: Text generated at the word level is inherently more readable and human-like. Words are the fundamental units of language. Word-level models excel at producing text that adheres to linguistic conventions, resulting in more engaging and comprehensible content.
Word Level Text Generation using LSTM with the PyTorch Framework
We will use PyTorch for coding our way through understanding word level text generation using LSTM. You can install PyTorch from the official page.
The steps for word level text generation training will be somewhat different compared to character level text generation.
Steps for Word Level Text Generation using LSTM
- First, we will prepare the dataset. This includes the preparation of vocabulary, a dictionary for mapping words to integers, and a reverse dictionary as well.
- Second, we need to prepare the data loaders where the input will be sentences to a certain length and the targets will be the same sentences but shifted one place to the right.
- Third, we need to prepare the LSTM model.
- Finally, we will carry out the training and inference using the trained model.
Just getting started with NLP? The following two blog posts will help you get started.
- Getting Started with Text Classification using Pytorch, NLP, and Deep Learning
- Disaster Tweet Classification using PyTorch
Download Code
Import Statements
Let’s import all the necessary modules and packages first.
import torch import torch.nn as nn import torch.optim as optim from torch.utils.data import Dataset, DataLoader from collections import Counter
Other than Pytorch, we only need the collections module from Python.
Word Level Vocabulary and Dataset Preparation
The next step is creating the vocabulary and dataset.
# Dataset Preparation
with open('data/alice_1.txt', 'r', encoding='utf-8') as file:
text = file.read()
# Tokenize the text into words
words = text.split()
word_counts = Counter(words)
vocab = list(word_counts.keys())
vocab_size = len(vocab)
word_to_int = {word: i for i, word in enumerate(vocab)}
int_to_word = {i: word for word, i in word_to_int.items()}
SEQUENCE_LENGTH = 64
samples = [words[i:i+SEQUENCE_LENGTH+1] for i in range(len(words)-SEQUENCE_LENGTH)]
print(vocab)
print(word_to_int)
print(int_to_word)
The goal here is to convert a raw text file into a format suitable for training a machine learning model. If you have gone through the previous post, then you will find the approach very similar. The only difference here is that we treat each unique word as a token (unique integer).
We read the text from a text file that contains a short fictional story.
Then we split the text based on the whitespace character. We then pass this to Counter to count how many times each word is present.
From the Counter, we extract a vocabulary list vocab, which contains all unique words from the text. The vocab_size is determined by counting the number of unique words. Two dictionaries are created: word_to_int and int_to_word. The former maps each word to a unique integer, and the latter is the reverse, mapping each unique integer back to its corresponding word. These mappings are essential for converting between human-readable text and a numerical representation that deep learning models can process.
Next, we define a hyperparameter, SEQUENCE_LENGTH. This defines how many words will be used to predict the next word. In general, longer sequences result in a better model. Furthermore, larger models are more capable of handling larger vocabulary and longer sequences.
Here is the truncated output from printing the vocabulary.

Creating Data Loaders
We need to define a simple custom PyTorch dataset class to create the data loaders.
class TextDataset(Dataset):
def __init__(self, samples, word_to_int):
self.samples = samples
self.word_to_int = word_to_int
def __len__(self):
return len(self.samples)
def __getitem__(self, idx):
sample = self.samples[idx]
input_seq = torch.LongTensor([self.word_to_int[word] for word in sample[:-1]])
target_seq = torch.LongTensor([self.word_to_int[word] for word in sample[1:]])
return input_seq, target_seq
The class accepts the samples which is a list of lists containing sequences of 64 words each. Along with that, it also accepts the word_to_int dictionary for mapping.
In the __getitem__ method, we extract one sample based on the index. input_seq is a sequence of integers that corresponds to the words of the sample excluding the last word. This will be used as the input to the LSTM. target_seq is a sequence of integers that corresponds to the words of the sample excluding the first word. This is the target sequence that the model will try to predict. Each element in the target_seq is the next word following the corresponding element in the input_seq.
BATCH_SIZE = 32
dataset = TextDataset(samples, word_to_int)
dataloader = DataLoader(
dataset,
batch_size=BATCH_SIZE,
shuffle=True,
)
print(dataset[1])
We create a data loader of batch size 32. Now, you may note that we do not use a collation function like the previous blog post. In this case, we assume that we will never have sequence lengths longer than the number of words in the document. Although a naive approach, this is easier to handle for learning.
Printing the first sample reveals the following output.

As we can see the target sample is shifted to the right by one word.
The LSTM Model
The model will remain almost the same as the character level model. It does not matter whether the model deals with characters or words, in the end, it has to process the numbers instead of raw text.
class TextGenerationLSTM(nn.Module):
def __init__(
self,
vocab_size,
embedding_dim,
hidden_size,
num_layers
):
super(TextGenerationLSTM, self).__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim)
self.lstm = nn.LSTM(
input_size=embedding_dim,
hidden_size=hidden_size,
num_layers=num_layers,
batch_first=True
)
self.fc = nn.Linear(hidden_size, vocab_size)
self.hidden_size = hidden_size
self.num_layers = num_layers
def forward(self, x, hidden=None):
if hidden == None:
hidden = self.init_hidden(x.shape[0])
x = self.embedding(x)
out, (h_n, c_n) = self.lstm(x, hidden)
out = out.contiguous().view(-1, self.hidden_size)
out = self.fc(out)
return out, (h_n, c_n)
def init_hidden(self, batch_size):
h0 = torch.zeros(self.num_layers, batch_size, self.hidden_size).to(device)
c0 = torch.zeros(self.num_layers, batch_size, self.hidden_size).to(device)
return h0, c0
I highly recommend going through the previous post once to get a detailed explanation of the model preparation.
Training Hyperpameters
Now, let’s define some additional training hyperparameters.
# Training Setup embedding_dim = 16 hidden_size = 32 num_layers = 1 learning_rate = 0.01 epochs = 50
For preparing the LSTM model, we have:
embedding_dim = 16: This sets the size of the embedding vector for each word. This converts each word in the vocabulary into a 16-dimensional vector.hidden_size = 32: This is the size of the hidden layers within the LSTM. Each LSTM unit will output a vector of size 32.num_layers = 1: This determines the number of LSTM layers to be stacked in the model. Here it is set to 1, meaning we will have a single-layer LSTM.
Additionally, we define the learning rate and the number of epochs that we want to train the model for.
Training the LSTM Model
Before we can begin the training, we need to set the computation device, initialize the model, the optimizer, and the loss function.
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = TextGenerationLSTM(
vocab_size,
embedding_dim,
hidden_size,
num_layers
).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
The final model contains roughly 27000 parameters.
The next code block defines the training loop.
# Training
def train(model, epochs, dataloader, criterion):
model.train()
for epoch in range(epochs):
running_loss = 0
for input_seq, target_seq in dataloader:
input_seq, target_seq = input_seq.to(device), target_seq.to(device)
outputs, _ = model(input_seq)
loss = criterion(outputs, target_seq.view(-1))
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss += loss.detach().cpu().numpy()
epoch_loss = running_loss / len(dataloader)
print(f"Epoch {epoch} loss: {epoch_loss:.3f}")
train(model, epochs, dataloader, criterion)
After each training epoch, we print the average loss for that particular epoch.
By the end of training, we have a loss of 0.027. As the training loss is so low, hopefully, the model was able to learn the features of the dataset. We need the model to overfit on this small sample to ensure that each component of our pipeline is working. The best way to know this is by running inference.
Inference using the Trained Word Level LSTM Model
Let’s write the inference function first.
# Inference
def generate_text(model, start_string, num_words):
model.eval()
words = start_string.split()
for _ in range(num_words):
input_seq = torch.LongTensor([word_to_int[word] for word in words[-SEQUENCE_LENGTH:]]).unsqueeze(0).to(device)
h, c = model.init_hidden(1)
output, (h, c) = model(input_seq, (h, c))
next_token = output.argmax(1)[-1].item()
words.append(int_to_word[next_token])
return " ".join(words)
# Example usage:
print("Generated Text:", generate_text(model, start_string="Alice was a", num_words=100))
The generate_text function accepts the trained model, a starting string, and the number of words that we want to generate as parameters.
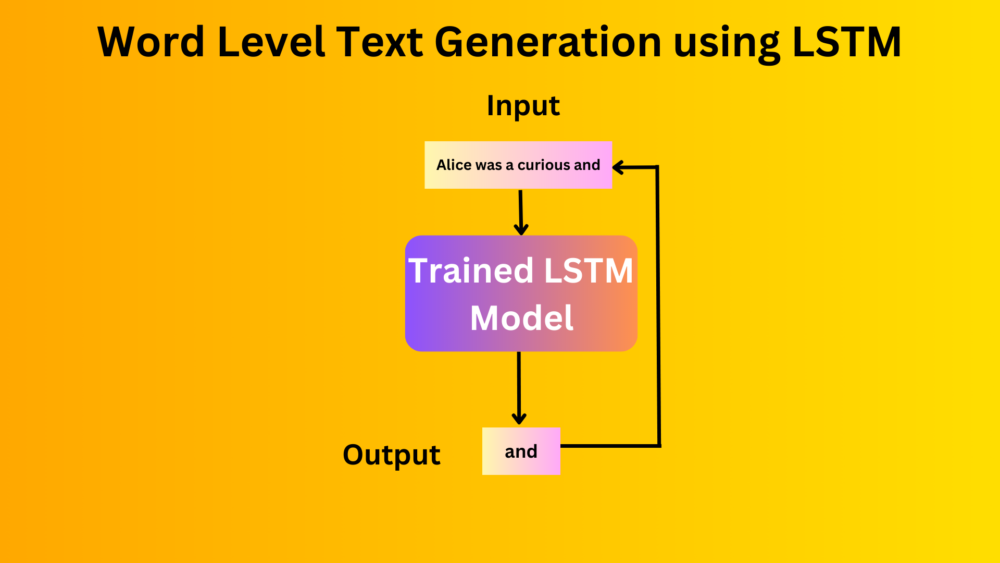
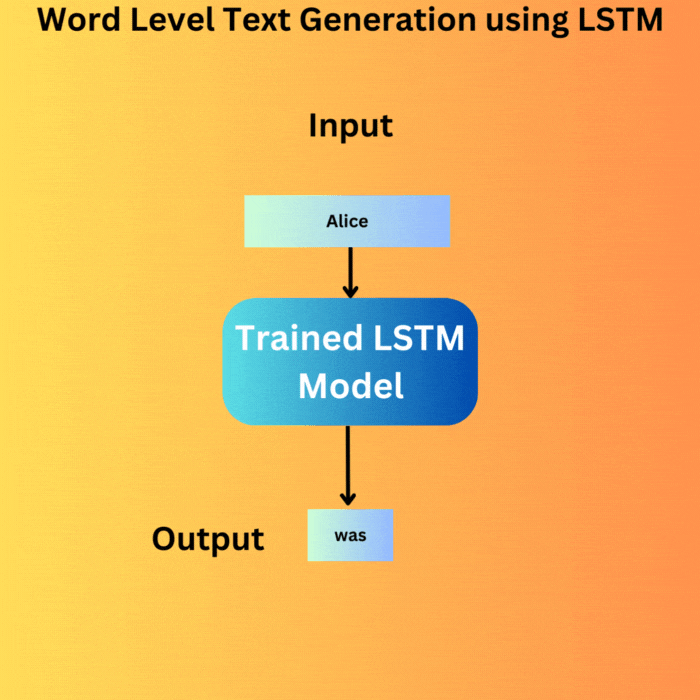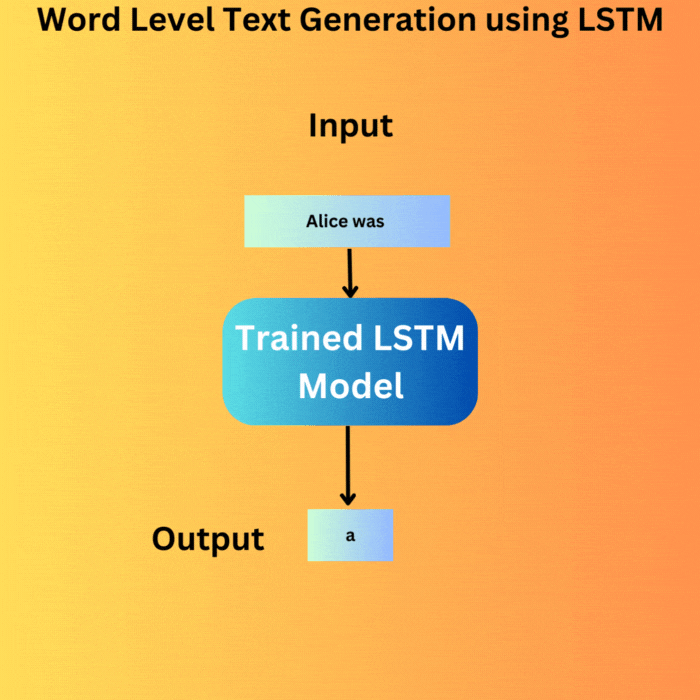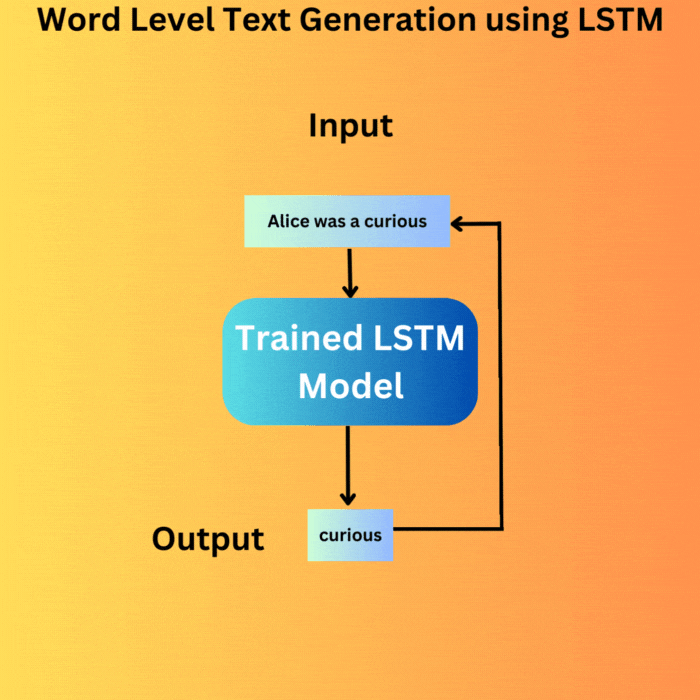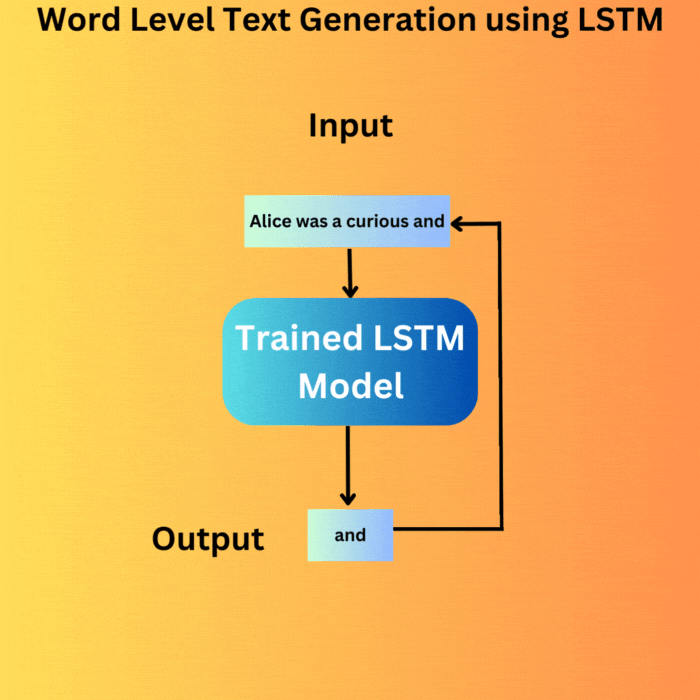
We keep on generating the text until we reach the desired number of words. On each loop, the output from the previous loop is appended to the input and is fed to the model. This is the essence of autoregressive text generation and primarily what drives today’s GPT and Llama models.
We start with the same string as in the training document, “Alice was a” and generate the next 100 words. This is the output that we get.

This is nice. Our model was able to remember the entire dataset. Although this is not something we desire when training models for real-world deployment, for us, this is a good sign as this signifies that each component of the pipeline is correct.
What is Missing and Where to Go From Here?
This is just a starting point for training autoregressive text generation models. To keep things simple, we have left out a lot of things. Here are some questions and pointers that you can further research.
- What happens when we provide the sequence length longer than the number of words in a text file?
- How to add padding and collation function for more robust training?
- How to handle more text files in a single directory and create a larger vocabulary?
- What will happen if we create a larger model?
We will try to answer all of these questions in the next blog post where will train a Transformer based text generation model from scratch.
Summary and Conclusion
In this blog post, we covered word level text generation using LSTM. We started with the dataset and vocabulary preparation for the word level text tokens. Next, we created a simple LSTM model. After training, we also ran inference and checked that the model was able to overfit on the dataset. This was a very simple implementation of autoregressive text generation. In the next blog post, we will cover Transformer models that we can use for text generation. I hope this blog post was worth your time.
If you have any doubts, thoughts, or suggestions, please leave them in the comment section. I will surely address them.
You can contact me using the Contact section. You can also find me on LinkedIn, and X.

4 thoughts on “Word Level Text Generation using LSTM”