

In the last tutorial, we covered a short introduction to HybridNets. We also carried out a few simple inference experiments to get to know the HybridNets network capability a bit better. But we did not go much deeper into the network architecture, experiments, and results. This is what we will do in this post. We will discuss the HybridNets paper thoroughly.
We will cover the following topics in this post:
- First, we will start with what are HybridNets and why we need such neural networks.
- Second, we will cover the contributions of the HybridNets paper.
- Then we will move on to the HybridNets network architecture.
- Finally, we will discuss the experiments, results, and comparisons with other models.
HybridNets Neural Networks
The HybridNets neural network was introduced by VT Dat et al. in the paper HybridNets: End-to-End Perception Network. This is a multi-task neural network that can carry out end-to-end visual perception. In other words, this neural network can do both, detection, and segmentation.
Why Are Multi-Task Neural Networks Important?
The big question here is “why do we need such a neural network?”. In autonomous driving, the visual perception neural network does multiple tasks. It has a complex structure for detecting humans, other vehicles, and the drivable area, and does a myriad of other challenging yet safety-critical tasks.
Such tasks cannot be achieved by a simple linear neural network that does just classification, detection, or segmentation. We need neural networks that can multitask. Hence, the term end-to-end multi-task visual perception.
On that front, the HybridNets introduced in the paper is an example of such an end-to-end network.
As per the authors, the HybridNets neural network has a major significance in autonomous driving where end-to-end visual perception is critical and speed of computation is also paramount.

The HybridNets neural network does traffic object detection, drivable area segmentation, and lane detection (segmentation) as well.
Contributions of the HybridNets Paper
The following are the novel contributions of the paper:
- HybridNets, an end-to-end perception network, achieves outstanding results in real-time on the BDD100K dataset.
- Automatically customized anchor for each level in the weighted bidirectional feature network, on any dataset.
- An efficient training loss function and training strategy to balance and optimize multi-task networks.
The paper also mentions how working on top of previous publications and research gave the advantage to achieve good results.
Other than the above, we can also mention one major contribution to the coding or the practical side of the paper:
- The paper proposes efficient segmentation head and box/class prediction networks based on weighted bidirectional feature network.
We will get into the details of these in later parts of the post.
The authors have also made the code for the publication open-source on GitHub.
The HybridNets Network Architecture
The HybridNet neural network consists of an encoder and two different heads (decoders) for multitasking.
The encoder consists of the backbone and neck. And one decoder is for detection, and the other for segmentation.
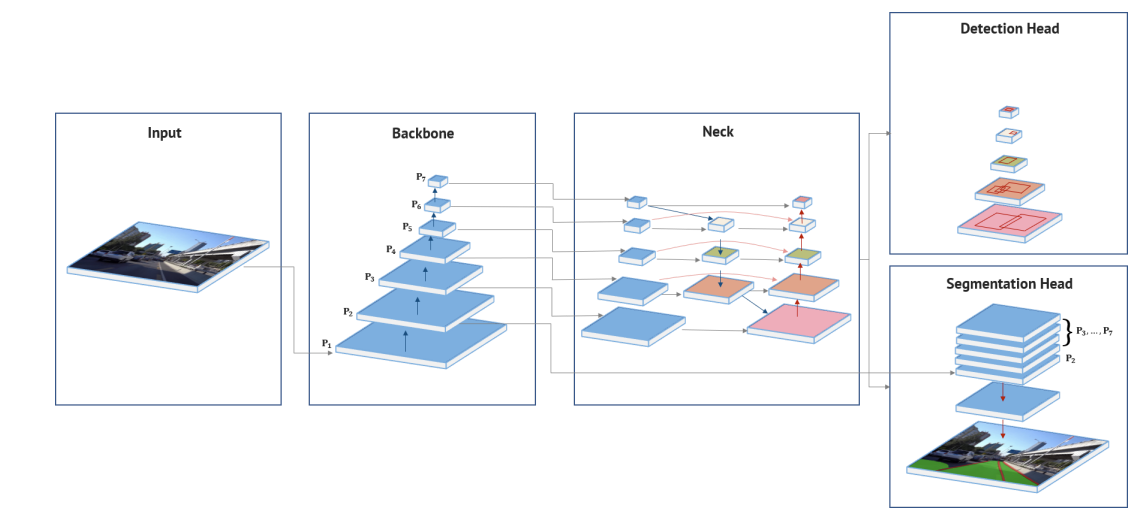
The above figure shows the complete architecture of the network. Let’s get into each of the components of the neural network.
The HybridNets Encoder
As we already know, both, the detection head and the segmentation head are reliant upon the features of the encoder. This means that the encoder will have to be accurate and fast.
Pretrained ImageNet models already provide good accuracy in transfer learning and extracting features. And the recent EfficientNet neural network models have shown the capability for both, accuracy and speed.
For that reason, the authors choose the EfficientNet-B3 model. This solves three potential problems for them. The EfficientNet-B3 model is already optimized according to the depth, width, and resolution parameters. They already get the advantage of obtaining vital features from the backbone at a lower computational cost.
But that’s not all. They also need to optimize the neck of the encoder for better performance. For that, the authors use the concept of BiFPN based on EfficientDet.
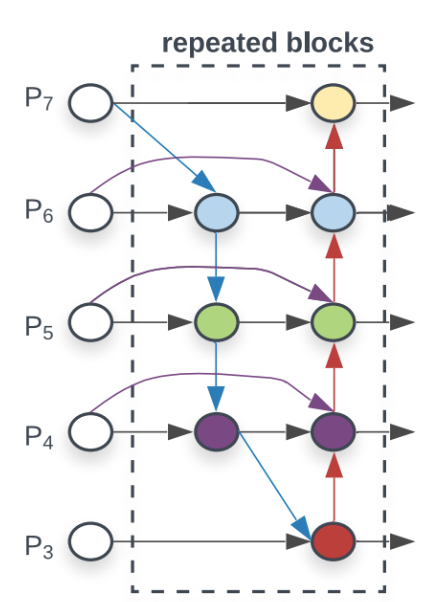
In simple words, BiFPN helps to fuse features at different resolutions. This enables information to flow in both top-down and bottom-up directions.
The HybridNets Decoder
The decoder of the hybridNets neural network consists of the detection and segmentation head.
For the detection, the authors use the concept of anchor boxes. Here, each feature map from the neck is assigned nine anchor boxes with different aspect ratios. It also borrows the K-means anchor clustering from YOLOv4. They choose 9 clusters with 3 different scales for each grid scale.
The detection head predicts the offsets of the bounding boxes, the probability of each class, and also the confidence of the prediction boxes.
Now, coming to the segmentation head, it outputs three classes. They are the background, the drivable area, and the lane lines.
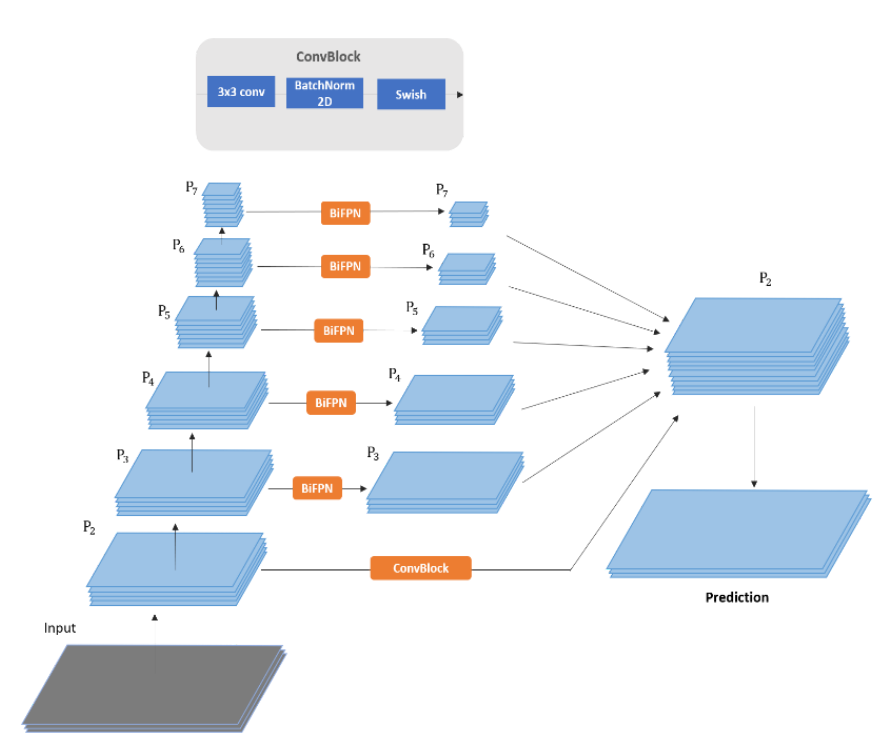
5 feature levels from the neck (\(P_3\) to \(P_7\)) go into the segmentation branch. The segmentation happens in four steps:
- First, the network up-samples all feature maps to the same size.
- Next, the \(P_2\) feature maps are passed through a convolutional layer to have the same feature map channels as others.
- Then, the network combines them to obtain a better feature fusion.
- In the last step, the network restores the final feature maps to the original input image size.
Feature fusion is important here as it helps the network improve the output precision.
The Loss Function
The proposed neural network uses a multi-task loss for training. The multi-task loss is critical to the training of the end-to-end network.
Without going into too many details, the final loss is a combination of the detection and segmentation loss.
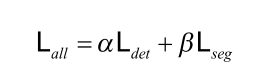
In the above formula, \(\alpha\) and \(\beta\) are the tuning parameters to balance the total loss.
You can find the details of the detection and segmentation in section 2.4 of the paper.
Experiments and Results
In this section, we will discuss the experiments and results from the paper.
Data Preparation
The neural network has been trained on the Berkeley DeepDrive Dataset (BDD100K) dataset. As the authors had to compare the results of the HybridNets neural network with previous works, so they prepared the dataset for the three tasks according to the existing networks which have already been trained on the BDDK100 dataset. For that, the authors had to use only four (car, truck, bus, train) classes out of the 10 detection classes from the dataset. Moreover, they also combined these four classes into a single vehicle class.
Also, the authors merge the direct and alternative segmentation classes into a single drivable class.
Training Details
The authors resize all images to 640×384 resolution before feeding them to the neural network. This resolution maintains the aspect ratio, has a good trade-off between performance and accuracy, and the dimensions are also divisible by 128 for the BiFPN.
For the augmentations, first, the basic augmentations are used. These include rotating, scaling, translation, horizontal flipping, and HSV shifting. Also, the authors use mosaic augmentation for training the detection head.
And for the EfficientNet-B3 model as the backbone, the authors use the pre-trained ImageNet weights to gain an advantage.
There are a few other parameters and hypermeter details for training which you can find in section 3.1 of the paper.
HybridNets Results
The authors measure the mAP for detection at 0.5 IoU threshold. As such, the model achieves 77.3 mAP on the BDD100k dataset for detection. For lane detection, it achieves 31.6 mean IoU. The network consists of 12.83 million parameters and 15.6 billion floating-point operations.
As per the paper, the HybridNets model is 1.4 times faster during inference compared to other similar models (like YOLOP) on the V100 GPU.
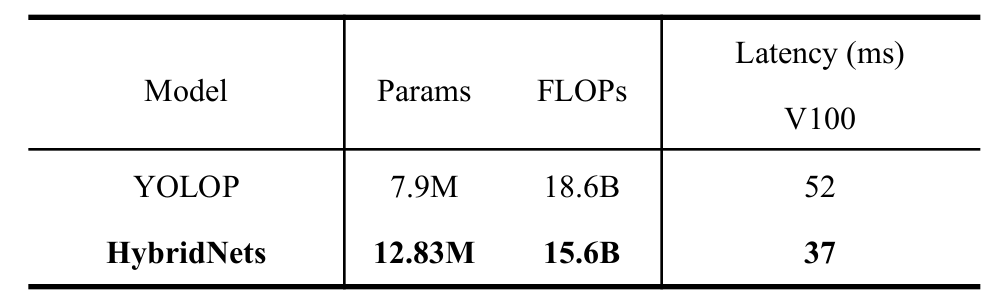
We can see from the above table that, though HybridNets contains more parameters compared to YOLOP, still it is faster during inference. Although it is worthwhile to note that the above inference latency is while excluding the image preprocessing and NMS post-processing. Still, it is around 27 FPS during the forward pass on the V100 GPU which is almost real-time.
Multi-Task Performance Results
HybridNets is not the only or the first multi-task neural network. There are a few others and drawing comparisons with them is pretty important. Because of that, the authors compare their HybridNets model with 5 other models which have also been trained on the BDD100K dataset. These models were trained for traffic object detection. The following figure (table 2 from the paper) shows the results.

It is pretty clear that at 0.50 IoU, the HybridNets is ahead of others with 77.3 mAP. Not only that, the HybridNets model can detect incredibly small objects between 3 to 10 pixels. The following are some of the results from the paper, that too in challenging night-time conditions.


Drivable Area Segmentation Performance
Now coming to the drivable area segmentation performance.
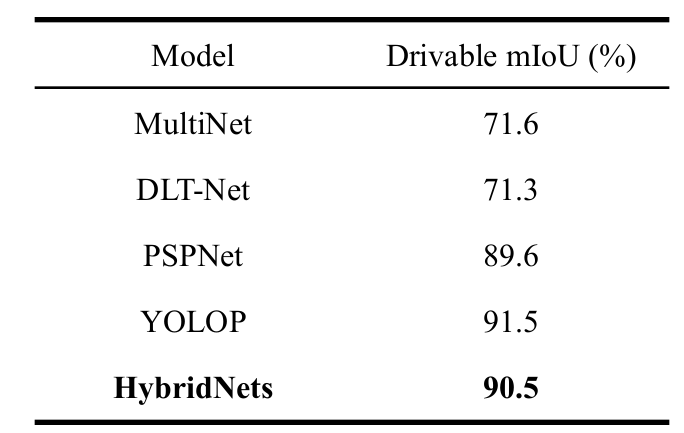
The above figure shows the results from table 3 from the paper. As we can see, the HybridNets model has 1% less mIoU compared to YOLOP. But the authors also argue that YOLOP employs two different decoders for specific segmentation tasks. So, even though YOLOP has slightly higher mIoU, HybridNets is more flexible and accurate when testing. This is shown in the following figure.

For YOLOP results in the above figure, the red regions are false positives and the yellow regions are false negatives.
Results for Lane Detection (Segmentation)
For lane detection, the authors use both accuracy and IoU.
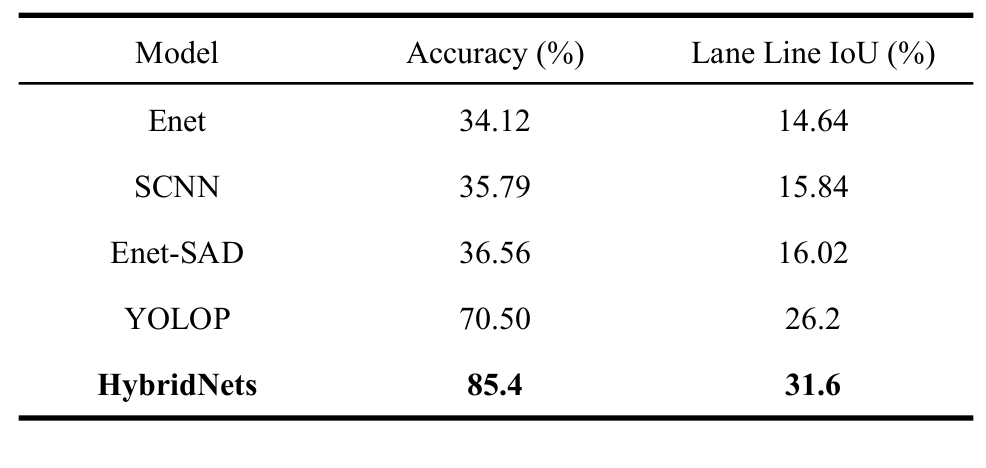
With an accuracy of 85.4% and IoU of 31.6%, the HybridNets model outperforms all other models on the same task.

From the above figure, it is clear that even for lane detection, the HybridNets model is performing well during both day and night time.
Summary and Conclusion
In this post, we discussed the HybridNets paper which is a multi-task network for object detection and segmentation. We started with a general introduction, moved to the model architecture, and finally discussed the training procedure and results. We saw where the HybridNets is performing better than others and where it is lacking. I hope that this post was helpful for you.
If you have any doubts, thoughts, or suggestions, please leave them in the comment section. I will surely address them.
You can contact me using the Contact section. You can also find me on LinkedIn, and X.

good and informative article
Thank you.