

Many beginners in the field of computer vision and deep learning start with image classification. After exploring much deep learning image classification techniques, datasets, and architectures, they want to try something more exciting and challenging. And most of them move towards deep learning for object detection. But soon they realise that there are numerous techniques in deep learning based object detection. And moreover, the techniques used are not that simple. A beginner can easily get lost in hundreds of research papers and come out really frustrated.
In this article, we will not go into any hands-on coding for deep learning for object detection. But we will take a look at some of the best and SotA (State of the Art) techniques covering various aspects of object detection. Although this article will be theoretical, still you will get a clear picture of where you should start your journey for object detection.
What will you learn after reading this article?
- What is object detection? A basic introduction.
- Research papers that we will discuss in this article.
- The RCNN family of object detectors.
- The SSD (Single Shot Detection) object detector.
- The YOLO (You Only Look Once) family of object detectors.
- Finally, some new techniques that are worth reading and knowing about.
Deep Learning and Object Detection
Even though most will be familiar with it already, still let’s start with the most basic question. What is object detection?
In simple words, in object detection, the algorithm classifies the objects in an image and also locates (localization) the objects by drawing a bounding box around them.
Basically, classification + localization means that there is only a single object in an image and we draw a bounding box around that only. And object detection is classifying and drawing bounding boxes around multiple objects in an image. Although they are really the same (in my opinion, at least) because localization is still detection but only on a single object.
But adhering to the common norm, let’s take a quick look at three images to clarify all our doubts about classification, localization, and detection.
Deep Learning for Image Classification
Take a look at the following image.

When we show the above image to a deep learning algorithm, and it outputs that the image is that of a dog then we call it as classification.
Classification is a very approachable problem in the field of deep learning. We have come a long way. With datasets like ImageNet and challenges like ILSVRC, we have solved image classification to a great extent. But of course, we still have a long way to go.
Deep Learning for Object Localization
Things start to get a bit tricky when we want to solve object localization with deep learning. It is no more as simple as classification. Now we have to classify what the object is and determine its location as well.

In the above image (figure 3), suppose that the algorithm classifies the image as a dog and draws a bounding box around it as well. This is formally called localization.
Deep Learning for Object Detection
Now, this is where we combine the above two concepts. In object detection, we will classify all the objects that are present in the image and also detect their positions as well.
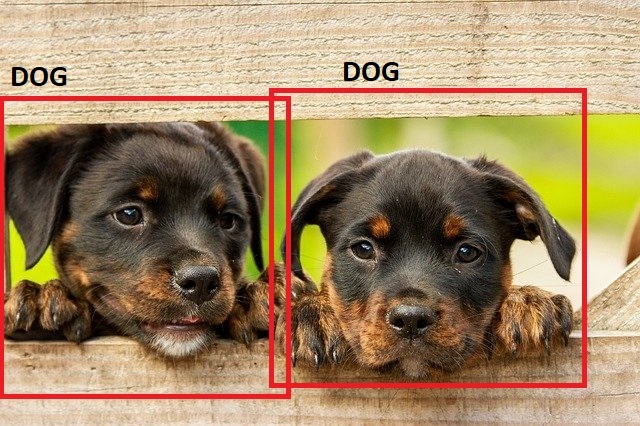
In figure 4, the deep learning algorithm recognizes all the dogs as well as draws the bounding boxes around them. This is know as object detection.
Figure 4 is a very simple example of object detection. Things can get really tricky when we have maybe 20 or 30 objects in an image. The following image will give you an idea of how difficult this can be.

What you see in figure 5 is achieved using the YOLO deep learning object detector. Frankly, when I started with object detection and saw some of the state of the art results, I could not believe that we can get such results (Obviously, now I do).
It is true that deep learning based object detectors are giving us some really amazing results. Starting from real-time traffic monitoring to self-driving cars, the results are just amazing. But in my opinion, we still have a long way to go in terms of wide-spread applicability of state of the art object detectors in real-time on edge devices.
Hopefully, the above figures and concepts clear some of your doubts about object detection.
Now, let’s move on to discuss some of the best papers in the field of deep learning based object detectors that paved the way for most of the future algorithms.
The RCNN Family of Object Detectors
In this section, we will discuss the RCNN deep learning object detectors. The RCNN detectors (or, Region Proposal CNN) are a total of three papers which include RCNN, Fast RCNN, and Faster RCNN.
RCNN
The RCNN object detector (Rich feature hierarchies for accurate object detection and semantic segmentation) was first published in 2013. This paper by Ross Girshick, Jeff Donahue, Trevor Darrell, and Jitendra Malik paved the way for many future deep learning object detector models.
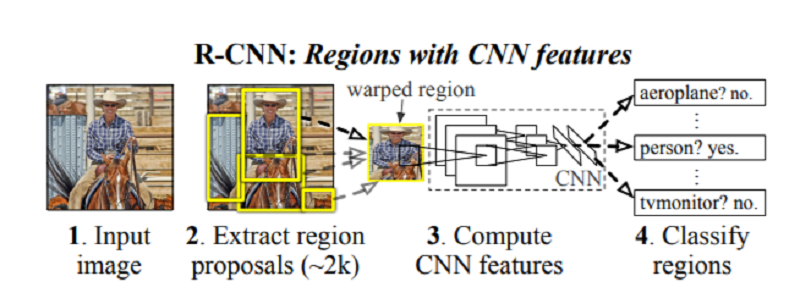
At that time it outperformed all other models and became the new state of the art in deep learning based object detectors. The architecture is benchmarked on the VOC 2010 and ILSVRC2013 datasets.
Not only the result was good but also the method used was simple and efficient.
The Approach of RCNN
The RCNN arhitecture’s first step is to take an input image and propose around 2000 region in the image. These are called region proposals and this is done using a computer vision technique.
After the region proposal step completes, then a convolutional neural network extracts the useful features from those 2000 proposals. According to the paper, the authors used the CNN model by Krizhevsky et al. for extracting a 4096-dimensional feature vector. They did this for each of the 2000 proposals in an image.
In the next step, a linear SVM classifier classifies each of the features into one of the image classes.
At that time, the RCNN model achieved an mAP (mean average precision) of 53.7% on PASCAL VOC 2010 and an mAP of 31.4% on the ILSVRC2013 detection dataset.
The RCNN architecture was the State-of-the-Art at that time but it was also very slow. It is difficult to use RCNN for real-time detection as it is.
You can find the original Caffe implementation here.
Fast RCNN
Fast Region-based Convolutional Network method (Fast R-CNN) by Ross Girshick was the follow up paper to RCNN.
The Fast RCNN architecture has several advantages over the RCNN architecture.
- Higher detection quality (mAP) than R-CNN, SPPnet.
- Training is single-stage, using a multi-task loss.
- Training can update all network layers.
- No disk storage is required for feature caching.
According the paper, the training is 9 times faster and at testing time Fast RCNN is 213 times faster as compared to RCNN.
The Approach of Fast RCNN
The Fast RCNN architecture is a 3 stage detector model.
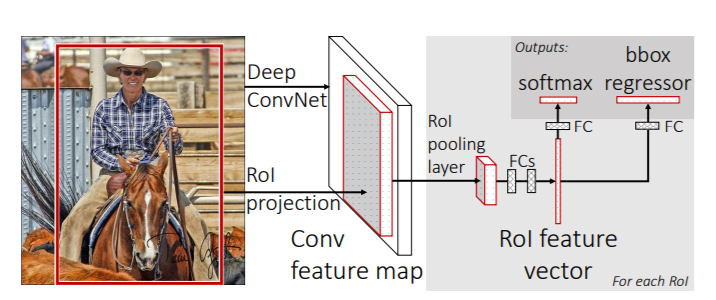
- First, we give the model an image and several Regions of Interest (RoIs) as input. These go into a convolutional neural network.
- Then the RoI pooling layers use max-pooling to convert the features inside regions of interest into small feature maps of a particular height and width. These are then mapped to a feature vector by fully connected (FC) layers.
- Finally, the network outputs two vectors per RoI. One is the softmax probabilities from which we can obtain the image classes. The other one is per-class bounding box regression offsets.
The Fast RCNN model again performed better than all the other models. It achieved state-of-the-art mAP on VOC07, 2010, and 2012. On the VOC 2012 dataset, Fast RCNN achieved mAP of 65.7%. On the VOC 2010 dataset, it achieved an mAP of 66.1%. And Fast RCNN achieved an mAP of 66.9% on the VOC 2007 dataset.
Faster RCNN
The paper Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks is the last proposal in the RCNN group of architectures. With this paper the authors Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun aimed to achieve real-time object detection.
Very simply, the Faster RCNN is a better version of the Fast RCNN where every step includes the use of neural networks (CNNs) mainly. The authors introduce a Region Proposal Network (RPN) that shares full-image convolutional features with the detection network. This helps to get nearly cost-free region proposals.
The Approach of Faster RCNN
The Faster RCNN comprises of two modules.
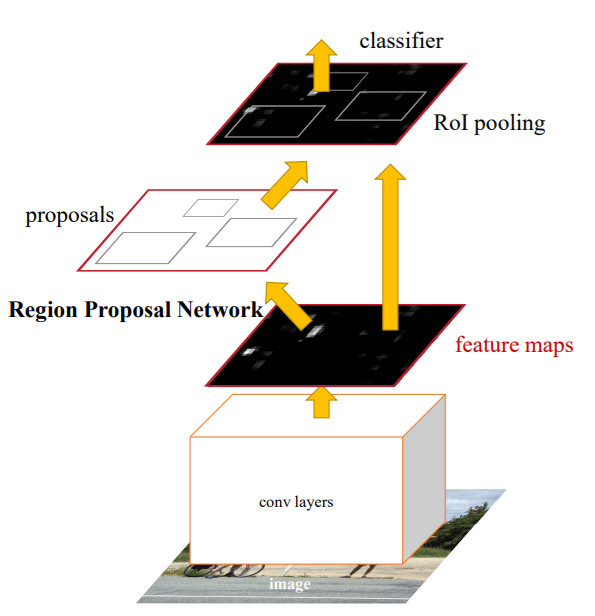
The first module is a fully convolutional neural network that proposes the regions. In fact, in figure 8, the first covnolutional block and the Region Proposal Network block make up the fast module that give use the rectangular proposals.
The second module is the Fast RCNN model that uses the proposed regions by applying RoI pooling and classifying the rectangular regions.
This makes the Faster RCNN architecture an end-to-end model
The authors used the VGG-16 model as the base CNN. They achieved a frame rate of 5FPS when using a GPU. The Faster RCNN model also gave state-of-the-art detection results on the PASCAL VOC 2007, 2012, and MS COCO datasets.
SSD: Single Shot MultiBox Detector
Next, we will move on to the very famous SSD (Single Shot Detector) by Liu et al.
The authors proposed a method to detect objects using a single neural network. It does not use any region proposal methods which makes it extremely fast and hence, a single shot detector (like YOLO, which we will discuss in the next section).
The Approach of SSD
The SSD architecture comprises of a VGG-16 base network and several other feature layers after that.
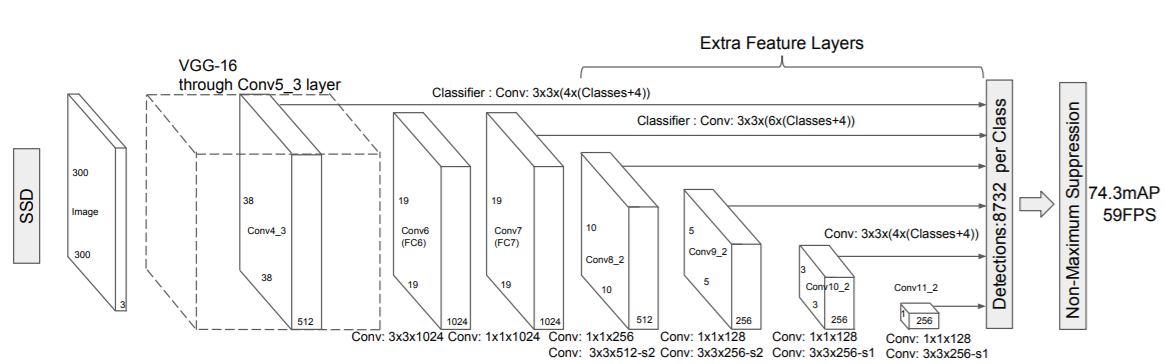
In figure 9, we can clearly see that there are extra convolutional feature extractor layers after the VGG-16 model. These help to predict the offsets to default bounding boxes at different scales as they downsize the feature maps at each layer.
The following image shows an example of bounding boxes with different aspect ratios.
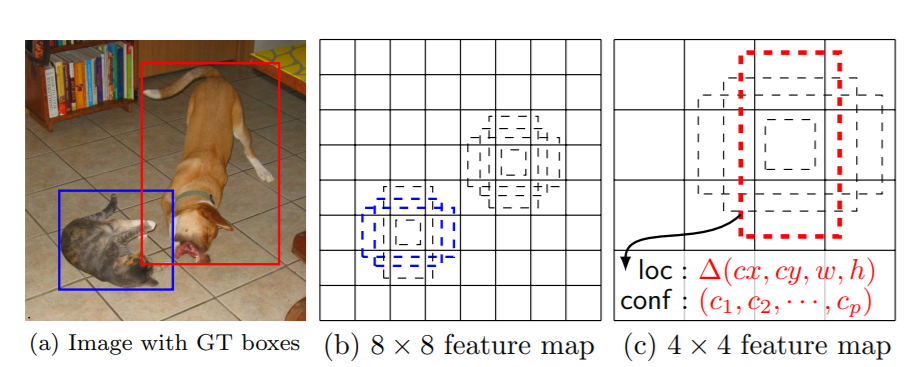
In figure 10, (a) shows the original image with the ground truth boxes which act as input to the network. Now, (b) and (c) show the default bounding boxes with different aspect ratios. At training time, these default bounding boxes are evaluated by matching them with the ground truth boxes. If the default bounding boxes match with the ground truth boxes, then they are treated as positives. You will find all of this in much detail in the paper. You should give the paper a read to gain an even better insight.
At the time of the release of the paper, SSD showed real competency in real-time detection and mAP as well. SSD300 (input image size 300×300) achieved 74.3% mAP on the VOC2007 test data with 59 FPS when using an NVIDIA Titan X GPU. And SSD512(input image size 512×512) achieved 76.9% mAP outperforming Faster RCNN at that time. In fact, SSD512 even outperformed YOLO version 1 on the PASCAL VOC2012 test dataset.
The YOLO Detectors
Now, we will discuss the YOLO object detectors, which are also single-shot detectors. Here, we will discuss three papers as well, that are YOLO, YOLO9000, and YOLOv3.
YOLO
The very first YOLO paper was released in June 2015 which was before the release of SSD.
The authors of the paper Joseph Redmon, Santosh Divvala, Ross Girshick, Ali Farhadi, proposed YOLO as a single shot detector which was fast even at that time and now. They framed object detection as a regression problem to detect the bounding boxes and the class probabilities. The architecture consists of a single neural network which sees the input image just once to output the boxes and probabilities.
The YOLO Network
Although the YOLO architecture is quite simple, yet understanding the paper the first time may be a bit difficult.
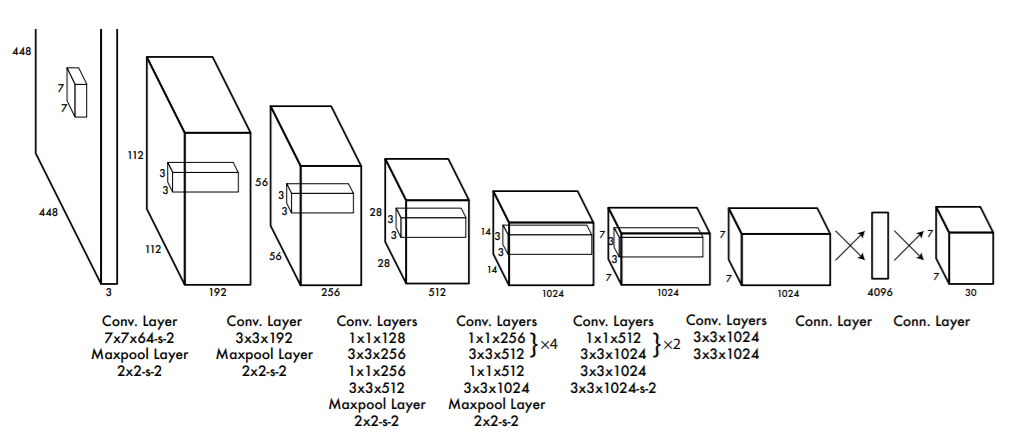
Figure 11 shows the neural network architecture of YOLO. This network is inspired by GoogLeNet but is different in some aspects. The network consists of 24 convolutional layers and 2 fully connected layers. It uses 1×1 convolutions to reduce the feature map space. These 1×1 convolutions replace the inception modules from the GoogLeNet.
The Working of YOLO Model
Here, we will briefly discuss the working of the YOLO model.
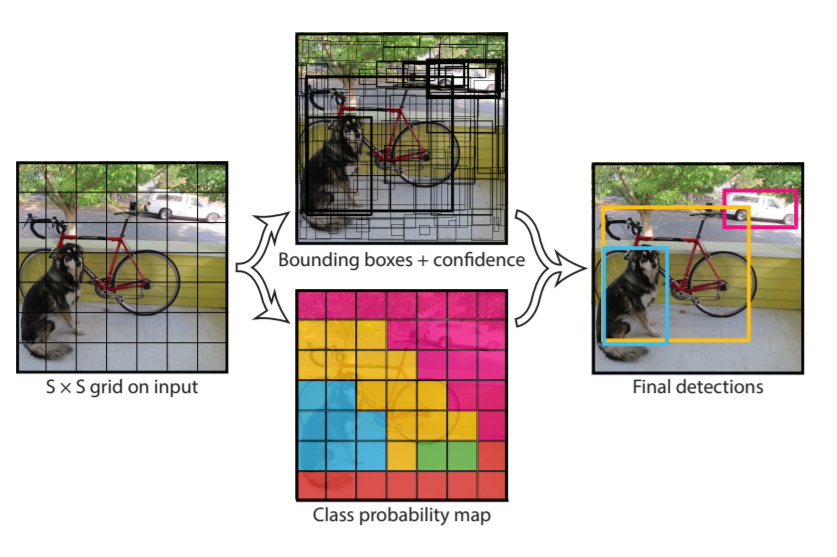
First, the YOLO model divides the input image into an S x S grid. In figure 12, S is 7 for the PASCAL VOC dataset. Each grid cell in an image helps in detecting the object. If the center of an object falls into a grid cell, then that grid cell is responsible for detecting that object.
If you look at figure 11, then you will see that the last layer has an output of 7x7x30. Let’s see how we reach there. First of all, the 7×7 corresponds to the grid cells. Each grid cell predicts B bounding boxes and the confidence scores of those boxes as well. There are also C class probabilities. The predictions are in the forms of S x S x (B * 5 + C). If we consider B = 2, and PASCAL VOC has 20 classes, then we reach at 7 x 7 x 30.
Going into more details of the architecture and model of YOLO will require its own article. Try and give the paper a read on your own and see what you can infer from the paper.
The Results from YOLO
The normal YOLO model got a frame rate of 45 FPS using a NVIDIA Titan X GPU. There is a also a fast version of YOLO called as Fast YOLO which achieved an astounding 155 FPS at that time. It used a smaller neural network architecture, 9 convolutional layers instead of 24.
But there was a trade-off for such high FPS. YOLO was not able to achieve very high mAP when compared to other detectors. It mainly suffered when trying to detect smaller objects in images or videos.
In the coming years, two more versions of YOLO came up, which addressed the low mAP problems.
YOLO9000: Better, Faster, Stronger
The above is literally the name of the second YOLO version by Joseph Redmon and Ali Farhadi released in 2016.
This version was much more improved than the first version and was able to detect 9000 object categories. To know how the authors did that, you will have to read the paper. You will find all the details and enjoy it as well.
The Approach of YOLO9000
The core approach of YOLO9000 remained the same as YOLOv1. The authors changed the neural network approach a bit. They named the neural network model as Darknet-19 as it contains 19 convolutional layers and 5 max-pooling layers.
Also, the method for choosing the bounding boxes changed a bit. To give you an idea, I am showing the following figure along with the caption from the paper itself.
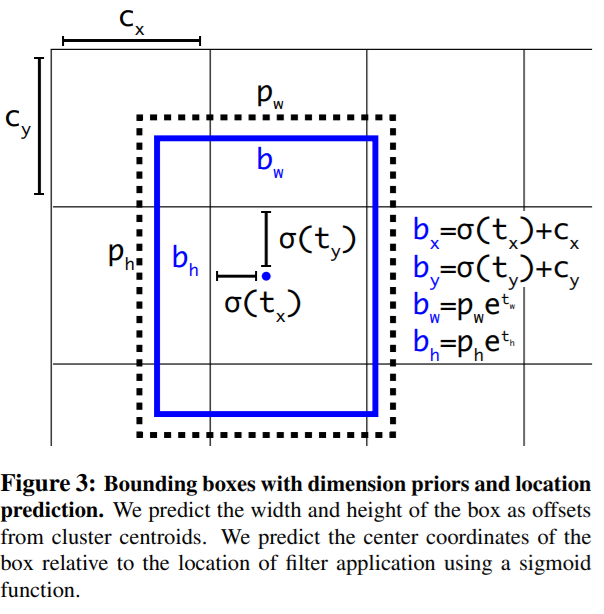
Again, I highly recommend reading the paper as we cannot go into all the details of the paper here.
YOLO9000 Results
For an input size of 416×416 (YOLOv2 416×416), YOLOv2 achieved 76.8 mAP with 67 FPS. When the input image size was increased to 544×544 (YOLOv2 544×544), then it achieved 78.6 mAP at 40 FPS. This surpassed all other deep learning object detectors like Faster RCNN with the ResNet architecture.
YOLOv3: An Incremental Improvement
We will not go into much detail of YOLOv3. This approach was again by Joseph Redmon and Ali Farhadi
Actually, YOLOv3 did not have the highest mAP when it was released, that is 2018. There were other networks like RetinNet-101 which performed better.
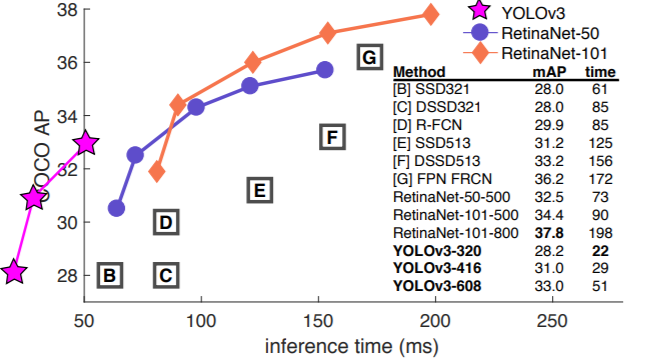
But it achieved the highest FPS with very good mAP when compared to other deep learning based object detectors.
The authors also updated the neural network architecture, now with 53 convolutional layers. Do give the paper a read. You will enjoy it and get to know many more details about the YOLOv3 model.
Some New Methods
Let’s talk about some new methods that are pretty recent and achieved really good results. We will not go into many details but this should give you a good idea of what new papers to read and apply.
EfficientDet: Scalable and Efficient Object Detection
EfficientDet is one of the best deep learning based object detector out there now. It has recently been updated as well to EfficientDet-D7 (July 2020).
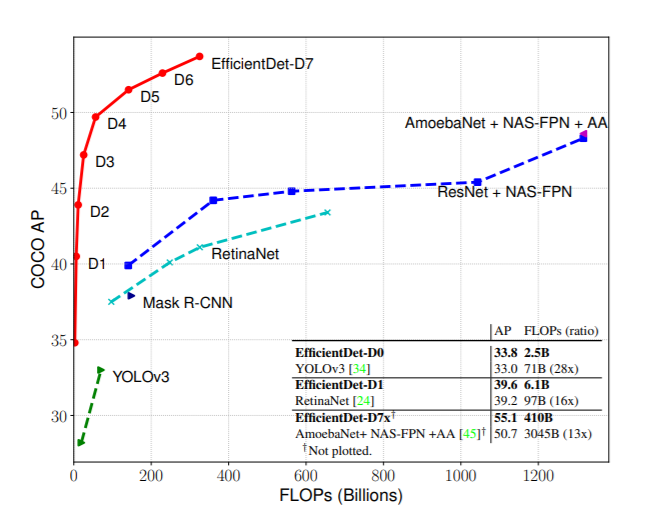
The method by Mingxing Tan, Ruoming Pang, and Quoc V. Le achieves state of the art AP (55.1) on the COCO dataset.
You can find the code here.
YOLOv4: Optimal Speed and Accuracy of Object Detection
Yes, we have a new version of YOLO, that is YOLOv4. This method has recently been released (April 2020).
But this time we have a new set of authors for the paper. YOLOv4 by Alexey Bochkovskiy, Chien-Yao Wang, and Hong-Yuan Mark Liao again beats all the previous frame rate benchmarks for real-time object detection including YOLOv3.
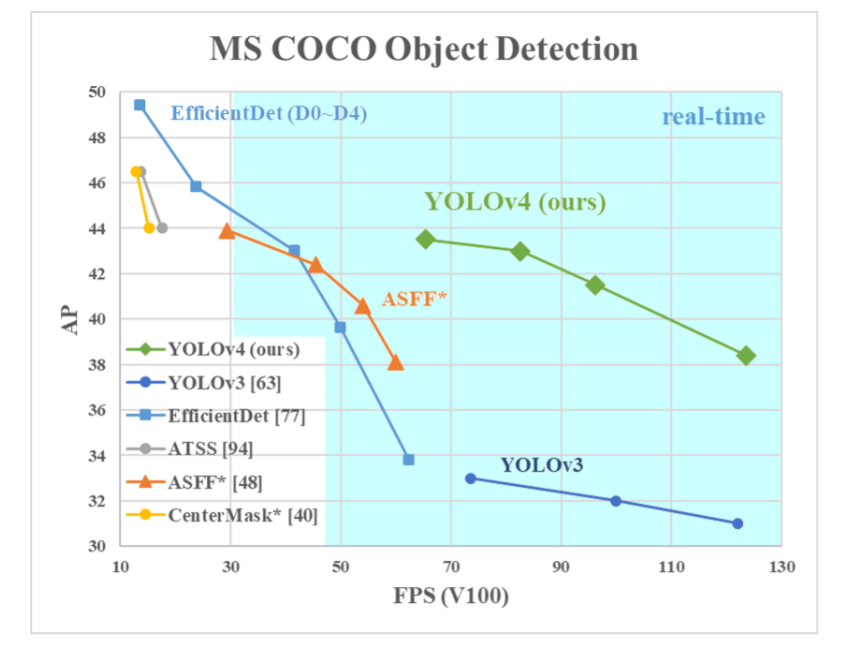
YOLOv4 does not have the highest AP (Average Precision) but it does have the highest FPS on the NVIDIA V100 GPU.
Links to Papers to Read
Here, I am providing the links to all the papers that we discussed in this article.
- Rich feature hierarchies for accurate object detection and semantic segmentation.
- Fast R-CNN.
- Faster R-CNN: Towards Real-Time ObjectDetection with Region Proposal Networks.
- SSD: Single Shot MultiBox Detector.
- You Only Look Once: Unified, Real-Time Object Detection.
- YOLO9000: Better, Faster, Stronger.
- YOLOv3: An Incremental Improvement.
- EfficientDet: Scalable and Efficient Object Detection.
- YOLOv4: Optimal Speed and Accuracy of Object Detection.
Summary and Conclusion
In this article, you learned about some state-of-the-art deep learning object detection techniques and also real-time object detectors. If you are getting into object detection, then I hope that this article helps to get started smoothly.
If you have any doubts, thoughts, or suggestions, then please leave them in the comment section. I will surely address them.
You can contact me using the Contact section. You can also find me on LinkedIn, and X.

Who is the best for small object detection?
Hello Fkih. In my experience, Faster RCNN object detector works really well even with small objects out of the box. But if you want real-time detection and that too on small objects, then with a bit of tweaking YOLO can lead to great results. You may look at one of my deep learning projects on GitHub, Traffic Light Detection using YOLOv3. Hope that you will find it useful. https://github.com/sovit-123/Traffic-Light-Detection-Using-YOLOv3
To imprime the detection of small object. I will develop an SRGAN (before or after) the detector!
Could you please clarify your question a bit more? What do you mean by “imprime”? And the reason for applying Super Resolution to object detection?
Thanks for the wonderful article.
Which would you consider to be better for training object detection on medical images? Speed (FPS) here might not be that important (useful but not very important), something that would have high positive as well as negative predictive value.
I am glad that you liked it. I understand the FPS part that you are saying about. For medical images, FPS is not important. Try getting a high mAP with a high recall value.