

In last week’s article, we covered fine tuning Mask2Former on a binary segmentation dataset. However, a lot of real-life problems and datasets will contain multiple classes to segment. For this, we extend the concept to train the Mask2Former model on a multi class semantic segmentation dataset. For multi class segmentation using Mask2Former, we will use a lane segmentation dataset.

While covering the the concept for training Mask2Former on this multi class segmentation dataset, we will also take a peek at the model’s limitations.
We will cover the following topics in this article
- First, we will have a small discussion on the road lane segmentation dataset that we will use to train the Mask2Former model.
- Second, we will briefly discuss the pretrained Mask2Former model that will use to train on the dataset.
- Third, we will move to the practical section of training the Mask2Former model on the road segmentation dataset.
- Finally, after training we will carry out inference on images and videos and also discuss the drawbacks for the same.
Most of the code and concepts remain the same as in the previous post where we fine tuned Mask2Former. We will only go through the parts which change according to the dataset. Most importantly, we will focus on the result and a few issues with using Mask2Former in a practical application. Please go through the previous post if you wish to get a detailed explanation of the code that we use here.
The Road and Lane Segmentation Dataset
We will use the road and lane segmentation dataset available on Kaggle here. The dataset contains four classes including background. They are:
- Background
- Roads
- Lane mark solid
- Lane mark dashed
The dataset has already been divided into a training and a validation split. There are 299 training and 74 validation samples with the masks in RGB format.
Downloading and extracting the dataset reveals the following directory structure.
road_seg
├── train
│ ├── images [299 entries exceeds filelimit, not opening dir]
│ └── masks [299 entries exceeds filelimit, not opening dir]
└── valid
├── images [74 entries exceeds filelimit, not opening dir]
└── masks [74 entries exceeds filelimit, not opening dir]
The dataset is extracted into the road_seg directory with the splits in their respective subdirectories.
Here are a few samples from the dataset.

The above figure shows the ground truth mask overlaid on the ground truth image from the training set.
The Project Directory Structure
The following block shows the entire project’s directory structure.
├── input │ ├── inference_data │ └── road_seg ├── outputs │ ├── final_model │ ├── inference_results_image │ ├── model_iou │ ├── model_loss │ ├── valid_preds │ ├── loss.png │ └── miou.png ├── config.py ├── custom_datasets.py ├── engine.py ├── infer_image.py ├── infer_video.py ├── model.py ├── train.py └── utils.py
- The
inputdirectory contains the dataset that we discussed in the previous section. - All the outputs from training and inference will reside in the
outputsdirectory. - The Python code files are present in the parent project directory.
All the Python code files, inference data, and trained models are available via the download section. If you want to carry out training, you need to download the dataset that we discussed earlier and arrange it in the above structure.
Library Dependencies
We will use the transformers library along with the PyTorch framework. We also need to install evaluate library for IoU calculation
PyTorch Installation
conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidia
Transformers Installation
pip install transformers
Evaluate Installation
pip install evaluate
With this, all the setup is complete.
Training Mask2Former for Multi Class Segmentation
Let’s get into the practical discussion revolving around the model and the code.
Download Code
The Mask2Former Swin Tiny Model Trained on the ADE20K Dataset
We will use the Huggin Face transformers library to load the pretrained Mask2Former model. Specifically, we will use the Mask2Former model with Swin Transformer Tiny backbone, pretrained on the ADE20K semantic segmentation dataset. It is the facebook/mask2former-swin-tiny-ade-semantic in the transformers repository.
You can see the pretrained models in full action in the Mask2Former article. In the article, we discuss Mask2Former models for semantic, panoptic, and instance segmentation models.
The Mask2Former Swin Tiny model is the smallest pretrained semantic segmentation model in the family. Still, this model contains around 47 million parameters. Let’s see further on whether this model scale reflects in the performance or not.
Dataset Augmentations
Before moving into the training section, let’s discuss the image augmentations that we apply. For the training dataset, we use the following augmentations:
- Horizontal flipping
- Random brightness contrast
- Random rotation
We use the Albumentations library to apply the augmentations. Here are a few samples that show how the images and masks look after applying the augmentations.

Executing the Training Script
Let’s execute the training script and check how the model performs.
The training experiment was carried out on a machine with RTX 3080 10 GB GPU, 10th generation i7 CPU, and 32 GB of RAM.
python train.py --batch 8 --imgsz 320 320 --lr 0.0001 --epochs 30
We are training the model for 30 epochs, with a batch size of 8, image size of 320×320, and initial learning rate of 0.0001.
Here are the results from the last few epochs.
EPOCH: 27 Training 100%|████████████████████| 38/38 [02:29<00:00, 3.93s/it] Validating 100%|████████████████████| 10/10 [00:18<00:00, 1.87s/it] Best validation loss: 9.363416194915771 Saving best model for epoch: 27 Best validation IoU: 0.8369587704717141 Saving best model for epoch: 27 Train Epoch Loss: 8.7562, Train Epoch mIOU: 0.830626 Valid Epoch Loss: 9.3634, Valid Epoch mIOU: 0.836959 -------------------------------------------------- EPOCH: 28 Training 100%|████████████████████| 38/38 [02:31<00:00, 3.98s/it] Validating 100%|████████████████████| 10/10 [00:19<00:00, 1.96s/it] Train Epoch Loss: 8.6000, Train Epoch mIOU: 0.832037 Valid Epoch Loss: 9.3810, Valid Epoch mIOU: 0.834177 -------------------------------------------------- EPOCH: 29 Training 100%|████████████████████| 38/38 [02:34<00:00, 4.07s/it] Validating 100%|████████████████████| 10/10 [00:19<00:00, 1.93s/it] Train Epoch Loss: 8.5514, Train Epoch mIOU: 0.835474 Valid Epoch Loss: 9.3738, Valid Epoch mIOU: 0.836914 -------------------------------------------------- EPOCH: 30 Training 100%|████████████████████| 38/38 [02:34<00:00, 4.07s/it] Validating 100%|████████████████████| 10/10 [00:19<00:00, 1.96s/it] Train Epoch Loss: 8.4919, Train Epoch mIOU: 0.835521 Valid Epoch Loss: 9.4749, Valid Epoch mIOU: 0.833047 -------------------------------------------------- TRAINING COMPLETE
The model with the best validation IoU of 83.1% and best validation loss of 9.36 was obtained on epoch 27. Following this, here are the IoU and loss graphs that we obtained from the training run.
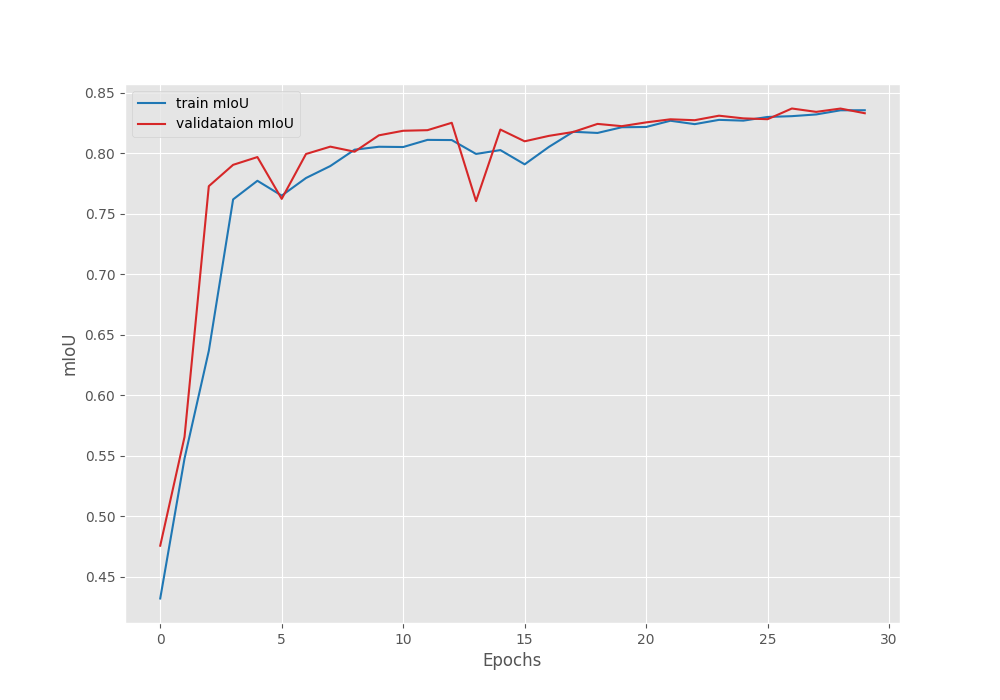
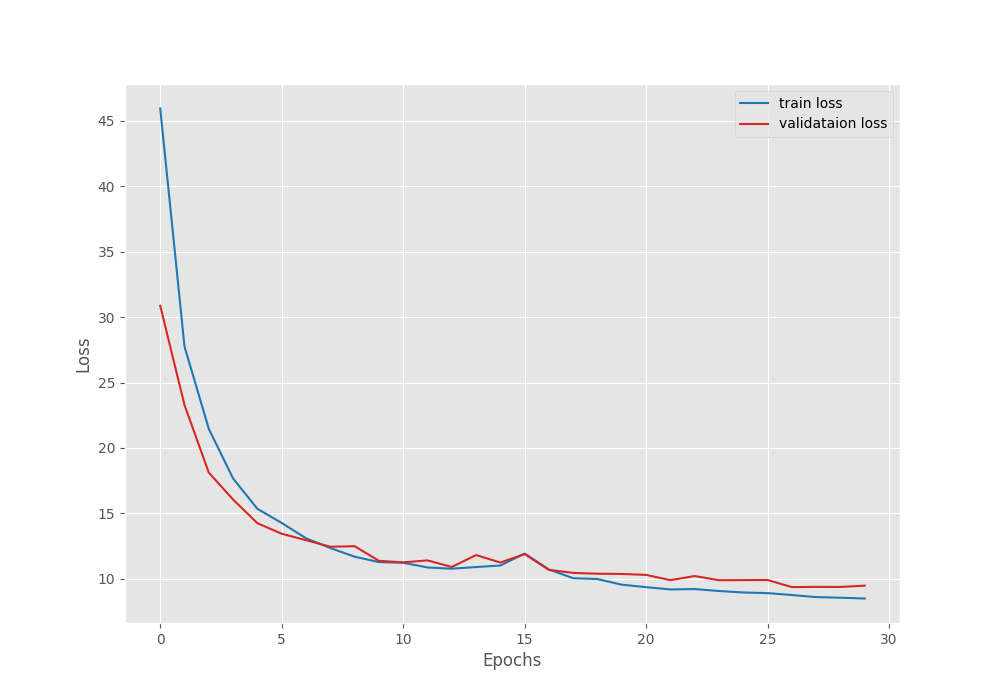
It is very clear that we can train the model for even longer with the same settings. We are not yet able to overfit the graphs, so, there is a lot of potential for improvement.
As we have the best model with us right now, let’s move on to the inference phase.
Inference on Validation Images
We can use the infer_image.py script to carry out inference on the validation images.
python infer_image.py --model outputs/model_iou/ --input input/road_seg/valid/images/ --imgsz 512 512
We provide the path to the model folder with the best IoU, the path to the validation images directory, and an image size of 512×512. Although we trained with lower resolution images, the model gives excellent output even with slightly higher square inputs. This also gives us a chance to analyze how the model performs on resolutions other than what it has been trained on.
The following figure shows a few samples from the inference results.

The results are excellent apart from a few cases.
- Whenever the dashed lane lines are too close to the car, the model is not able to segment it.
- It is having difficulty in segmenting the road when there is any reflection on the windshield of the car.
Other than the above two cases, the segmentation maps look very clear and well bordered. Most probably, training the model for a few more epochs will solve these issues as well.
Inference on Videos
Now, let’s get to one of the most important points. When we train a model on a road segmentation dataset, we expect it to perform well on videos as well. So, let’s run inference on an unseen video and analyze the performance.
We will use the infer_video.py script in this case.
The following video inference was run on a laptop RTX 3070 Ti GPU.
python infer_video.py --model outputs/model_iou/ --input input/inference_data/videos/video_2.mov --imgsz 512 512
The segmentation maps look clear and crisp at least on the lane where the car is driving. In fact, the model can segment the dashed lane lines almost perfectly. This shows the ability of the model to perform well on real-world data even with few training samples.
However, there is a bigger issue here, the FPS (Frames per Second). We are averaging at only 2 FPS even on a good GPU. This shows the lack of usability of Mask2Former for lane and road segmentation on edge devices where it may be most intended.
Such experiments and insights teach us which model to use for which use case. Other models, like SegFormer, may need longer training or give slightly inferior segmentation maps. However, they are fast and can be deployed on edge devices with proper optimization. Training SegFormer on the same road segmentation data gives more than decent results and higher FPS as well.
Summary and Conclusion
In this article, we trained the Mask2Former model on a multi class road and lane segmentation dataset. We went over the model, the dataset augmentation strategy, training, and inference results. Analyzing the results gave us more insights into the Mask2Former model and what other alternatives we have for real time semantic segmentation. I hope that this article was worth your time.
If you have any doubts, thoughts, or suggestions, please leave them in the comment section. I will surely address them.
You can contact me using the Contact section. You can also find me on LinkedIn, and X.

I want to train this model for binary classification. What are the changes I would need to do?
Hello Shubh. In that case, please take a look at this article => https://debuggercafe.com/fine-tuning-mask2former/
sorry the error happened when I executed python train.py –batch 8 –imgsz 320 320 –lr 0.0001 –epochs 30
error message:
—-> 8 A.Normalize(mean=ADE_MEAN, std=ADE_STD)
ValidationError: 4 validation errors for InitSchema
mean.float
Input should be a valid number [type=float_type, input_value=array([0.485, 0.456, 0.406]), input_type=ndarray]
Hello. It is difficult to say right away what might be the issue. I will check the code and let you know. It may so happen that something has been updated in the API. I will check it.
Hello. It was an error with the mean and standard deviation that was defined for the preprocessing. It seems with an update of the API, it no longer accepts Numpy arrays. I have modified them to lists now. You can download the latest code and it will run without errors.
Hi, Sovit,
It’s been solved from your latest update, thank you very much! One more question, suppose I’d like to keep some but not all existing classes in the pre-trained weight and add a new class. After I change config and prepare images and masks, how should I modify this line in model.py or it doesn’t need to be modified at all?
This line:
image_processor = Mask2FormerImageProcessor(ignore_index=255, reduce_labels=True)
Hello. Once you modify the config file, the train.py will take care of loading the model properly with the correct number of classes. You need not do anything manually.
I hope this helps.
Since Mask2Former ignores pixels with a value of 255, I’m wondering about potential issues with my current mask setup. My masks have pixel values of 0 for the background and 255 for the foreground (representing the “crack” class). I’m working with just two classes: background and crack. Unlike your setup where only the Red channel contains mask information and the other channels are zeroed out, all three RGB channels in my masks will either contain mask data (255) or be empty (0). Will this configuration cause any issues with Mask2Former, considering its handling of 255-valued pixels?