
Grammar Correction is one of the major problems in NLP (Natural Language Processing). Tools like Grammarly that help with automated grammar correction are invaluable in modern online writing. A lot of online tools like Grammarly pop up almost every few months. And guess what? They are all powered by AI, or NLP to be precise. But how do they work? Although it is difficult to pinpoint how grammar correction tools work, we can take some safe guesses. Most probably, they have a Transformer model under the hood. Grammarly has an official blog post on how Transformers help in GEC (Grammatical Error Correction). In this article, although we will not be building any state-of-the-art grammar correction model, we will train a very simple model using T5.

We covered spelling correction using T5 in one of the previous articles. It was a minimal example to show how we can use Transformers for spelling correction. Similarly, in this article, we will touch upon every point briefly. This includes the dataset, the dataset preparation process, and the training. Our main focus is on creating a working solution with a code-first approach to grammar correction using Transformers. This will lead the way to future articles where we will dive deeper into this topic.
We will cover the following points for grammar correction using Hugging Face Transformers
- We will start with the dataset discussion. To be precise, we will use the First Certificate in English (FCE) dataset in this article.
- Next is the dataset preparation part. We need to prepare the dataset in such a way that we can feed it to the T5 model easily for training.
- Then comes the training of the T5 Transformer model for grammar correction.
- Finally, we will run inference using the trained model.
The FCE Dataset
The FCE (First Certificate in English) dataset is a subset of the Cambridge Learner Corpus (CLC). It is a part of the Building Educational Applications 2019 Shared Task: Grammatical Error Correction competition. The website hosts other datasets as well but we are interested in the FCE v2.1 under the Data section.
Downloading and extracting the dataset will reveal the following format.
fce_v2.1.bea19
└── fce
├── json
│ ├── fce.dev.json
│ ├── fce.test.json
│ └── fce.train.json
├── json_to_m2.py
├── licence.txt
├── m2
│ ├── fce.dev.gold.bea19.m2
│ ├── fce.test.gold.bea19.m2
│ └── fce.train.gold.bea19.m2
└── readme.txt
All the data files will be extracted into fce_v2.1.bea19/fce directory. There is a json and an m2 subdirectory. However, we will deal with the JSON format of the dataset in the json subdirectory.
It contains a training, a dev, and a test set. Now, let’s look at an example from the training set.
{"text": "Dear Sir or Madam,\n\nI am writing in order to express my
disappointment about your musical show \"Over the Rainbow\".\n\nI
saws the show's advertisement hanging up of a wall in London where
I was spending my holiday with some friends. I convinced them to go
there with me because I had heard good references about your
Company and, above all, about the main star, Danny Brook.\n\nThe
problems started in the box office, where we asked for the discounts
you announced in the advertisement, and the man who was selling
the tickets said that they didn't exist.\n\nMoreover, the show was
delayed forty-five minutes and the worst of all was that Danny Brook
had been replaced by another actor.\n\nOn the other hand, the
theatre restaurant was closed because unknown reasons.\n\nYou
promised a perfect evening but it became a big disastrous!\n\nI
would like some kind of explanation and receive my money back. If
you don't agree, I will act consequently.\n\nI look forward to
hearing from you.\n\nYours faithfully,", "age": "21-25", "q": "1",
"script-s": "31", "edits": [[0, [[71, 76, "with", "RT"],
[118, 122, "saw", "IV"], [159, 161, "on", "RT"], [292, 302,
"reviews", "RN"], [303, 308, "of", "RT"], [338, 343,
"because of", "RT"], [394, 396, "at", "RT"], [681, 698,
"In addition", "ID"], [734, 741, "for", "R"],
[811, 821, "disaster", "DN"], [866, 873, "to get", "FV"],
[920, 932, "", "UY"]]]], "l1": "ca", "id": "TR1*0102*2000*01",
"answer-s": "4.3"}
Each sample is in a dictionary format with several key-value pairs. Among them, we are interested in the "text" and "edits" key-value pairs.
The "text" key contains the essay as it was originally written by the author with a few grammatical errors. The "edits" key contains the correction edits in the following format:
[[annotator_id, [[char_start_offset, char_end_offset, correction], …]], …]
We are most interested in the char_start_offset, char_end_offset, and correction values. The former two values indicate the character indices where the word is wrong excluding the newline symbols ('\n'). For example, in the first case, the characters from 71 to 76 correspond to the word about which should be replaced with with.
As such, there are 2116 samples in the training set, 159 samples in the dev set, and 194 samples in the test set.
In the current format, it isn’t easy to write the dataset preparation code to be fed to the T5 model. For this reason, we will preprocess the dataset into an easier format which we will deal with while preparing the dataset for the model. We will do this in the coding section of the article.
For now, you can go ahead and download the dataset.
Project Directory Structure
Let’s take a look at the complete directory structure.
├── final_model_t5_small │ ├── added_tokens.json │ ├── config.json │ ├── generation_config.json │ ├── pytorch_model.bin │ ├── special_tokens_map.json │ ├── spiece.model │ └── tokenizer_config.json ├── input │ ├── fce_v2.1.bea19 │ └── final │ ├── test.json │ ├── train.json │ └── valid.json ├── results_t5_small │ ├── checkpoint-5500 │ ├── checkpoint-6500 │ └── events.out.tfevents.1703464284.sovitdl.18962.0 ├── preprocess_fce.py └── t5_small.ipynb
- The
final_model_t5_smallandresults_t5_smallcontain the trained model and tokenizer after the training is done. - The
inputdirectory contains the FCE dataset that we explored in the previous section. Along with that, it contains a final directory with three JSON files. We will obtain these after executing the preprocessing script. - Directly inside the project directory, we have two files:
t5_small.ipynbwhich contains the code to train the T5 model for grammar correction and run inference.preprocess_fce.pyscript that we will use to obtain the JSON files in theinput/finaldirectory.
You can download the Jupyter Notebook for training & inference along with the best weights via the “Download Code” section.
Dependencies
Before we move forward, we need to ensure that the environment is properly set up. We need the PyTorch framework for running the code in this article. Please go ahead and install it according to your configuration from the official site.
Along with that, we need to install Hugging Face transformers and datasets libraries.
pip install transformers
pip install datasets
That’s it. We are done with all the major dependencies that we need.
Download Code
Grammar Correction using Hugging Face Transformers and the T5 Model
Let’s get into the coding part of the article. The first step, as we discussed earlier to bring the FCE dataset into a simpler format.
Preprocessing the FCE Dataset
For that, we have a simple preprocessing script in the preprocess_fce.py file. Here is the entire content of the file.
import json
import os
ROOTS = [
'input/fce_v2.1.bea19/fce/json/fce.train.json',
'input/fce_v2.1.bea19/fce/json/fce.dev.json',
'input/fce_v2.1.bea19/fce/json/fce.test.json'
]
SPLITS = [
'train',
'valid',
'test'
]
save_dir = 'input/final'
os.makedirs(save_dir, exist_ok=True)
def replace_multiple_substrings(original_string, replacements):
# replacements is expected to be a list of tuples, each containing:
# (start_index, end_index, new_substring)
# Sort replacements by start_index to handle replacements in order
replacements.sort(key=lambda x: x[0])
result = original_string
offset = 0 # This offset is necessary because the string length may change
for start_index, end_index, new_substring in replacements:
# Adjust indices based on the current offset
adjusted_start = start_index + offset
adjusted_end = end_index + offset
# Check for invalid indices
if adjusted_start < 0 or adjusted_end > len(result) or adjusted_start > adjusted_end:
print(f"Error: Invalid indices for replacement '{new_substring}'. Skipping.")
continue
# Replace the specified part of the string
result = result[:adjusted_start] + str(new_substring) + result[adjusted_end:]
# Update the offset based on how the length of the string has changed
offset += len(str(new_substring)) - (end_index - start_index)
return result
for root, split in zip(ROOTS, SPLITS):
data = []
data_points = []
with open(root, 'r') as f:
for line in f:
data.append(json.loads(line))
for i in range(len(data)):
str_data = data[i]['text']
re_data = data[i]['edits'][0][1]
# print('STR: ', str_data)
# print('RE: ', re_data)
modified_string = replace_multiple_substrings(str_data, [data[:3] for data in re_data])
# print(modified_string)
data_point = {
'original': str_data,
'corrected': modified_string
}
data_points.append(data_point)
with open(os.path.join(save_dir, split+'.json'), 'w') as f:
json.dump(data_points, f, indent=4)
This is a simple script that converts the original FCE dataset into a much simpler format. A simpler dataset format will later reduce the code that we need to write while training the model.
In short, the above script:
- Takes the original train, dev, and test files of the FCE dataset.
- Reads the original text and the edits from the JSON files.
- According to the edits, it creates a new text with the corrected words in place.
After executing the above script, you will find train.json, valid.json, and test.json files inside input/final directory.
Following is a sample from the training split.
{
"original": "Dear Sir or Madam,\n\nI am writing in order to express my
disappointment about your musical show \"Over the Rainbow\".\n\nI saws the
show's advertisement hanging up of a wall in London where I was spending my
holiday with some friends. I convinced them to go there with me because I had
heard good references about your Company and, above all, about the main star,
Danny Brook.\n\nThe problems started in the box office, where we asked for the
discounts you announced in the advertisement, and the man who was selling the
tickets said that they didn't exist.\n\nMoreover, the show was delayed forty-five
minutes and the worst of all was that Danny Brook had been replaced by another
actor.\n\nOn the other hand, the theatre restaurant was closed because unknown
reasons.\n\nYou promised a perfect evening but it became a big disastrous!\n\nI
would like some kind of explanation and receive my money back. If you don't agree,
I will act consequently.\n\nI look forward to hearing from you.\n\nYours faithfully,",
"corrected": "Dear Sir or Madam,\n\nI am writing in order to express my
disappointment with your musical show \"Over the Rainbow\".\n\nI saw the show's
advertisement hanging up on a wall in London where I was spending my holiday with
some friends. I convinced them to go there with me because I had heard good reviews
of your Company and, above all, because of the main star, Danny Brook.\n\nThe
problems started at the box office, where we asked for the discounts you announced
in the advertisement, and the man who was selling the tickets said that they didn't
exist.\n\nMoreover, the show was delayed forty-five minutes and the worst of all
was that Danny Brook had been replaced by another actor.\n\nIn addition, the theatre
restaurant was closed for unknown reasons.\n\nYou promised a perfect evening but it
became a big disaster!\n\nI would like some kind of explanation and to get my money
back. If you don't agree, I will act .\n\nI look forward to hearing from you.\n\nYours
faithfully,"
}
So, for each sample, we now have a dictionary-like format with an "original" key and a "corrected" key.
T5 for Grammar Correction
Now, let’s jump into the actual training notebook. The code here follows the content in the t5_small.ipynb Jupyter Notebook.
In case you want a brief about the T5 Transformer model, please take a look at the spelling correction article. In that article, we used the T5 model for single-word spelling correction, and it may be a good starting point if you are new to this topic.
Let’s start with the import statements.
import torch
from transformers import (
T5Tokenizer,
T5ForConditionalGeneration,
TrainingArguments,
Trainer
)
from datasets import load_dataset
From the transformers library, we import:
T5Tokenizer: To tokenize the dataset which consists of grammatically incorrect and correct sentences.T5ForConditionalGeneration: This is for the loading of the T5 model.TrainingArguments: This class initializes all the training arguments before starting the training.Trainer: To initialize theTrainerobject so that we can train the T5 model.
We also import the load_dataset function from the datasets library to load the prepared JSON files in a format that is directly compatible with the rest of the transformers pipeline.
Loading the Dataset
Next, we load the preprocessed training, validation, and test datasets.
dataset_train = load_dataset(
'json',
data_files='input/final/train.json',
split='train'
)
dataset_valid = load_dataset(
'json',
data_files='input/final/valid.json',
split='train'
)
dataset_test = load_dataset(
'json',
data_files='input/final/test.json',
split='train'
)
When using the load_dataset function, the first argument is always the type of dataset that we are loading. As our dataset is in JSON format, so, we pass 'json'.
One other point to note here is the split argument. When loading external datasets, it becomes mandatory to give the split as 'train'. However, that does not change any attribute of the dataset, so, we can use each split as originally intended.
Defining Dataset and Training Configurations
The following code block contains a few dataset and training related configurations.
MODEL = 't5-small' BATCH_SIZE = 16 MAX_LENGTH = 256 EPOCHS = 50 NUM_WORKERS = 8 OUT_DIR = 'results_t5_small'
MODEL: This is the model name that we will pass while loading the tokenizer and the model weights. For our grammar correction use case, we are using the T5 Small model.BATCH_SIZE: We are using a batch size of 16 for the data loaders.MAX_LENGTH: This is the maximum context length to consider for each sample in the JSON files. Beyond this length, the text samples will be truncated and smaller samples will be padded.EPOCHS: The number of epochs to train the model for.NUM_WORKERS: The number of parallel workers for the data loaders.OUT_DIR: This is the output directory to save intermediate results.
Tokenizing the FCE Dataset
Tokenization is assigning an integer value to each word and breaking down a word into simpler ones if necessary. This is a much simpler explanation of what goes on inside. However, explaining the entire process of tokenization is out of the scope of this article.
Let’s see how we can tokenize the dataset that we have just loaded above.
tokenizer = T5Tokenizer.from_pretrained(MODEL)
# Function to convert text data into model inputs and targets
def preprocess_function(examples):
inputs = [f"rectify: {inc}" for inc in examples['original']]
model_inputs = tokenizer(
inputs,
max_length=MAX_LENGTH,
truncation=True,
padding='max_length'
)
# Set up the tokenizer for targets
with tokenizer.as_target_tokenizer():
labels = tokenizer(
examples['corrected'],
max_length=MAX_LENGTH,
truncation=True,
padding='max_length'
)
model_inputs["labels"] = labels["input_ids"]
return model_inputs
# Apply the function to the whole dataset
tokenized_train = dataset_train.map(
preprocess_function,
batched=True,
num_proc=8
)
tokenized_valid = dataset_valid.map(
preprocess_function,
batched=True,
num_proc=8
)
tokenized_test = dataset_test.map(
preprocess_function,
batched=True,
num_proc=8
)
The first step is loading the tokenizer. We load the T5Tokenizer on the first line of the above code cell while passing the model name that we defined earlier.
In the second step, we have a preprocess_function. This accepts samples from the loaded dataset. Each sample consists of the original grammatically incorrect and the modified grammatically correct text. Note that we are appending the rectify text to each of the original incorrect text. T5 models work best when assigning a starting token based on the task. As we are correcting grammatical errors here, we have passed the above text.
Theoretically, it is possible to pass any string as a starting token. However, using something that aligns with the task is much better.
The inputs to the T5 model are going to be the incorrect sentences and the targets (labels) will be the correct sentences. Finally, we return a dictionary that contains both, the tokenized input and the tokenized targets.
The third step involves mapping all three splits to the preprocessing function. The num_proc argument defines how many parallel processes are being used for tokenization.
If you are new to NLP, then you can start with the following text classification articles which will help you better understand the pipeline of tokenization.
- Getting Started with Text Classification using Pytorch, NLP, and Deep Learning
- Disaster Tweet Classification using PyTorch
Loading the T5 Model
Now, let’s load the T5 model and check the number of trainable parameters.
# Load the pre-trained BART model
model = T5ForConditionalGeneration.from_pretrained(MODEL)
# Specify the device
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
# Total parameters and trainable parameters.
total_params = sum(p.numel() for p in model.parameters())
print(f"{total_params:,} total parameters.")
total_trainable_params = sum(
p.numel() for p in model.parameters() if p.requires_grad)
print(f"{total_trainable_params:,} training parameters.")
We are using the from_pretrained method of the T5ForConditionalGeneration class to load the pretrained T5 Small model. It contains around 60.5 million parameters which is enough for getting started with our journey of GEC (Grammatical Error Correction).
Defining the Training Arguments
We will use the TrainingArguments class to initialize all the training arguments.
# Define the training arguments
training_args = TrainingArguments(
output_dir=OUT_DIR,
num_train_epochs=EPOCHS,
per_device_train_batch_size=BATCH_SIZE,
per_device_eval_batch_size=BATCH_SIZE*2,
warmup_steps=500,
weight_decay=0.01,
logging_dir=OUT_DIR,
evaluation_strategy='steps',
save_steps=500,
eval_steps=500,
load_best_model_at_end=True,
save_total_limit=2,
report_to='tensorboard',
dataloader_num_workers=NUM_WORKERS
)
It accepts several arguments (more than 100 to be precise). However, in the above code block, we only pass the ones necessary for our usage.
According to the arguments:
- The model will be evaluated and saved every 500 steps. But only two saved models will be preserved and others will be overwritten.
- The best model will be loaded at the end so that we can save it one final time before proceeding to the inference section.
Starting the Training for Grammar Correction using T5
Before starting the training, we need to initialize the Trainer API as well. The next code cell does that and starts the training.
# Create the Trainer instance
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_train,
eval_dataset=tokenized_valid,
)
# Start training
history = trainer.train()
The Trainer class accepts the model, the above defined training arguments, and training & validation datasets.
We invoke the train method of the instance to start the training.
Here are the training logs after 50 epochs.
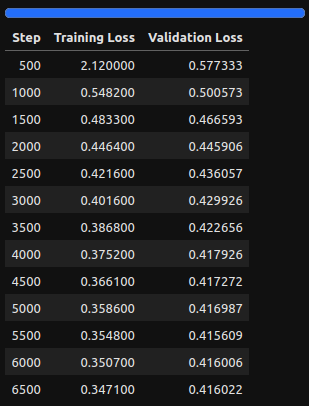
The model was able to reach the best loss at 5500 steps after which it began to deteriorate. But as we are loading the best model after training, we can again save the best final model and tokenizer to disk to use at inference time. Let’s do that.
tokenizer.save_pretrained('final_model_t5_small')
model.save_pretrained('final_model_t5_small')
Next, we can evaluate the model on the test set as well.
trainer.evaluate(tokenized_test)
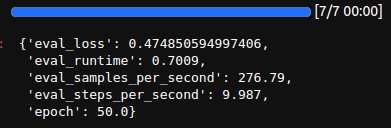
The evaluation loss on the test set is 0.47. One important point to keep note of here is that we are evaluating the grammar correction model based on the validation loss which is not entirely correct. In future posts, we will explore more accurate metrics for grammar correction models.
Following is the evaluation loss graph from the above training.
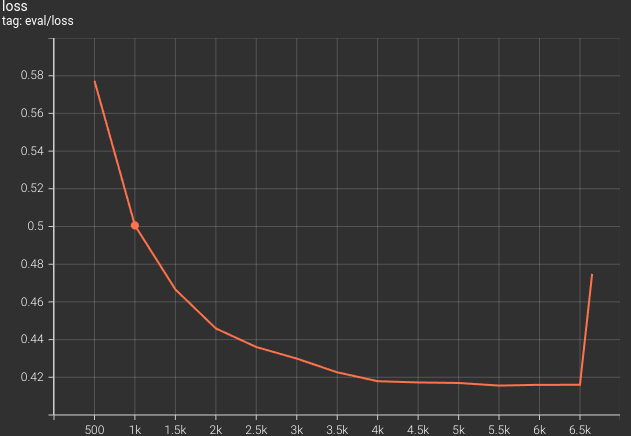
As we can see, the loss was mostly reducing till the end of the training. To continue training further, most probably, we will have to apply a learning rate scheduling technique.
Grammar Correction Inference using the Trained T5 Model
Let’s move on to the inference phase now. Following are the steps to carry out for grammar correction inference:
- First, we will load the best model weights and tokenizer from the disk.
- Second, we will write a helper function for grammar correction inference.
- Third, we will pass a list of sentences to the helper function to get the corrected sentences.
from transformers import T5ForConditionalGeneration, T5Tokenizer
model_path = 'final_model_t5_small' # the path where you saved your model
model = T5ForConditionalGeneration.from_pretrained(model_path)
tokenizer = T5Tokenizer.from_pretrained(model_path)
We load the final model and tokenizer from the disk in the above code block.
Now, let’s write a simple helper function called do_correction.
def do_correction(text, model, tokenizer):
input_text = f"rectify: {text}"
inputs = tokenizer.encode(
input_text,
return_tensors='pt',
max_length=256,
padding='max_length',
truncation=True
)
# Get correct sentence ids.
corrected_ids = model.generate(
inputs,
max_length=384,
num_beams=5,
early_stopping=True
)
# Decode.
corrected_sentence = tokenizer.decode(
corrected_ids[0],
skip_special_tokens=True
)
return corrected_sentence
It simply processes the input text, generates the text IDs by forward passing through the model, and decodes the IDs to return the final text.
Please note that we are adding the same rectify text here as well before each sentence.
Finally, define a few sentences in a list and pass through the model.
sentences = [
"He don't like to eat vegetables.",
"They was going to the store yesterday.",
"She don't sings very well.",
"Between you and I, the decision not well received.",
"The book I borrowed from the library, it was really interesting.",
"Despite of the rain, they went for a picnic."
]
for sentence in sentences:
corrected_sentence = do_correction(sentence, model, tokenizer)
print(f"ORIG: {sentence}\nCORRECT: {corrected_sentence}")
Here are the outputs.
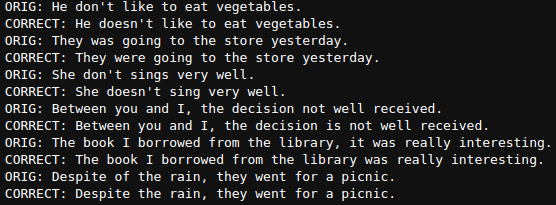
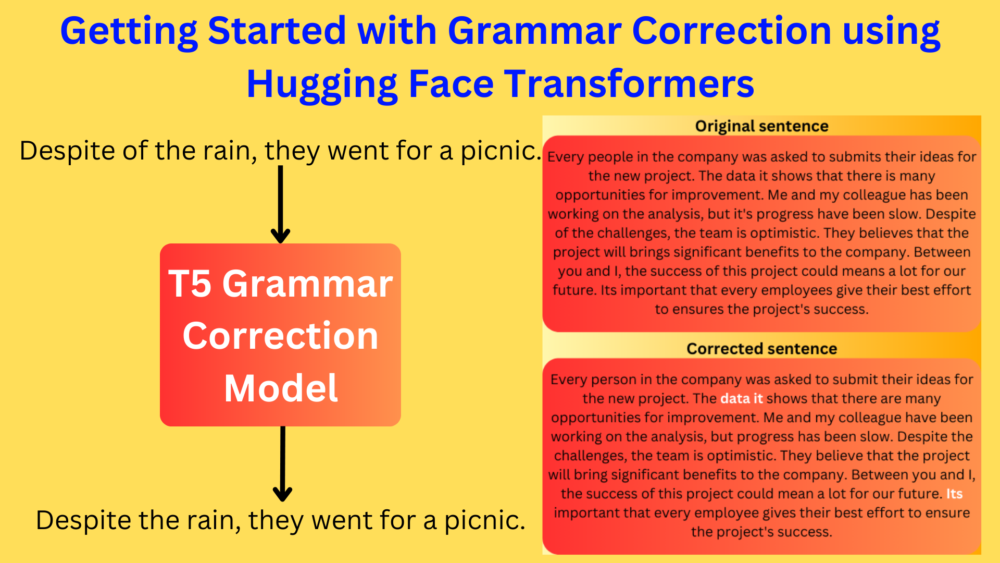
The results are really good. The model can correct all the grammatical mistakes in the sentences. However, the T5 Small model does not do very well on long sentences with multiple errors. Here is an example.

There are two errors in the corrected sentence. The model failed to rectify “data it” and in the final sentence “Its” should have been either “It is” or “It’s“.
In future articles, we will see how larger models with better training strategies can handle such cases.
Summary and Conclusion
In this article, we went through a code-first approach for grammar correction using Hugging Face Transformers. We trained the T5 Small model on the FCE dataset and ran inference on some unseen sentences. In the end, we also checked whether the model lacks, that is, long text with multiple errors. We will tackle these issues in future articles. I hope this article was worth your time.
If you have any doubts, thoughts, or suggestions, please leave them in the comment section. I will surely address them.
You can contact me using the Contact section. You can also find me on LinkedIn, and X.
Further Reading

1 thought on “Getting Started with Grammar Correction using Hugging Face Transformers”