

In this article, we are going to train the FasterViT model on the Pascal VOC segmentation dataset.
FasterViT is one of the faster alternatives to the original Vision Transformer models. Not only faster, but it is deemed more accurate as well across many image classification tasks. In some of the previous articles, we covered the image classification and binary semantic segmentation capabilities of the Faster ViT model. In this article, we will focus on the multi-label semantic segmentation capability using FasterViT.

As the original FasterViT project does not make a semantic segmentation model readily available, we will use a modified version of the FasterViT-0 model.
We will not go through the basics of the FasterViT and modified FasterViT-0 for segmentation here. I highly recommend the following two articles before moving further:
Here, we will solely focus on the dataset, the dataset preparation, training, and inference.
We will cover the following points in this article
- We will start with a discussion of the Pascal VOC segmentation dataset.
- This will follow the dataset augmentation techniques and how the augmentations modify the original images.
- Next, we will move to the training phase and analysis of the results.
- Finally, we will use the best trained model for image and video inference.
Libraries and Dependencies
Let’s check out the libraries and dependencies that we need for the code in the article to run.
- kaggle
- timm==0.9.16
- fastervit
- albumentations
- torch==2.1.2
- torchvision==0.16.2
We need the Kaggle API to download the dataset. The timm (Torch Image Models) library takes care of all the FasterViT related modules needed for pretrained weight and parameter loading. The fastervit library is necessary for loading the FasterViT model. We need Albumentations for image augmentation and our framework of choice is PyTorch.
Download Code
You need not install them manually. They all come in a requirements text file when downloading the zip file for the article. After downloading you can simply install them via the requirements.txt file.
pip install -r requirements.txt
Project Directory Structure
Let’s take a look at the directory structure.
├── inference_data │ ├── images │ └── videos ├── outputs │ ├── inference_results_image │ ├── inference_results_video │ ├── valid_preds │ ├── accuracy.png │ ├── best_model_iou.pth │ ├── best_model_loss.pth │ ├── loss.png │ ├── miou.png │ └── model.pth ├── voc_2012_segmentation_data │ ├── train_images │ ├── train_labels │ ├── valid_images │ └── valid_labels ├── weights │ └── faster_vit_0.pth.tar ├── config.py ├── datasets.py ├── engine.py ├── inference_image.py ├── inference_video.py ├── metrics.py ├── requirements.txt ├── segmentation_model.py ├── train.py └── utils.py
- The
inference_datadirectory contains the images and videos that we will use for inference after training the FasterViT model on the VOC dataset. - The
outputsdirectory contains all the outputs from training including the model weights and the inference results as well. voc_2012_segmentation_datacontains the Pascal VOC segmentation dataset. We will later see how to download the dataset.- The
weightsfolder contains the pretrained FasterViT-0 weights. I highly recommend going through the FasterViT binary segmentation article to know more about it. - Finally, directly in the parent directory we have all the Python files.
All the code files, inference data, and trained weights will be available to download via the download section. In case you intend to train the model yourself, you will need to download the dataset and put it in the above structure.
The Pascal VOC Semantic Segmentation Dataset
The Pascal VOC semantic segmentation dataset is one of the most well-known in computer vision. The best part about this dataset is that it is not too large. It contains roughly 1450 images both, in the training and the validation set. This makes the VOC segmentation dataset perfect for training the FasterViT model.
There are 20 object classes and 1 background class in the dataset.
- ‘background’,
- ‘aeroplane’,
- ‘bicycle’,
- ‘bird’,
- ‘boat’,
- ‘bottle’,
- ‘bus’,
- ‘car’,
- ‘cat’,
- ‘chair’,
- ‘cow’,
- ‘dining table’,
- ‘dog’,
- ‘horse’,
- ‘motorbike’,
- ‘person’,
- ‘potted plant’,
- ‘sheep’,
- ‘sofa’,
- ‘train’,
- ‘tv/monitor’
You can find the details and color mapping on the Kaggle page here. It is really easy to install the Kaggle API and download the dataset. Just execute the following commands in the terminal.
pip install kaggle
kaggle datasets download -d sovitrath/voc-2012-segmentation-data
Following are some of the ground truth training images and their respective segmentation maps from the dataset.

As we can see, the images contain enough variety to teach a model about segmenting different objects.
That’s all we need to discuss about the dataset.
Dataset Preparation and Augmentation
If you go through the previous article, you will find that our FasterViT segmentation model can only take in square images at the moment. We will resize all images and segmentation maps to 512×512 resolution. This is one of the constraints that we will alter in future articles.
Apart from the resizing, we also apply the following augmentations using Albumentations:
- Horizontal flipping
- Random brightness and contrast
- Rotation
Here are a few samples of how the images and masks look after the augmentation.

Augmenting the samples adds more variation to the images and helps prevent overfitting while training.
You can explore the datasets.py file to learn more details about the dataset preparation steps.
Training the FasterViT Model on the VOC Segmentation Dataset
The train.py is the executable training script. It does the following tasks:
- Initializes the datasets and data loaders.
- Loads the model, the optimizer, and the loss function. We are using the Adam optimizer for training.
- Then it trains the model for a certain number of epochs as provided in the command line argument.
The training experiment was carried out on an A10 24 GB GPU.
Let’s execute the script and start the training process.
python train.py --imgsz 512 512 --epochs 50 --lr 0.0001 --batch 8 --scheduler
We are training the model for 50 epochs, with a batch size of 8, an initial learning rate of 0.0001, and applying a learning rate scheduler as well. The learning rate scheduler reduces the learning rate by a factor of 10 after 30 epochs.
Here are the outputs from the terminal from the last few epochs.
EPOCH: 49 Training 100%|████████████████████| 183/183 [03:12<00:00, 1.05s/it] Validating 100%|████████████████████| 182/182 [01:17<00:00, 2.36it/s] Train Epoch Loss: 0.0718, Train Epoch PixAcc: 0.9661, Train Epoch mIOU: 0.349340 Valid Epoch Loss: 0.3007, Valid Epoch PixAcc: 0.9190 Valid Epoch mIOU: 0.283305 Adjusting learning rate of group 0 to 1.0000e-05. -------------------------------------------------- EPOCH: 50 Training 100%|████████████████████| 183/183 [03:12<00:00, 1.05s/it] Validating 100%|████████████████████| 182/182 [01:16<00:00, 2.38it/s] Best validation IoU: 0.285580612014345 Saving best model for epoch: 50 Train Epoch Loss: 0.0709, Train Epoch PixAcc: 0.9665, Train Epoch mIOU: 0.349338 Valid Epoch Loss: 0.2959, Valid Epoch PixAcc: 0.9194 Valid Epoch mIOU: 0.285581 Adjusting learning rate of group 0 to 1.0000e-05. -------------------------------------------------- TRAINING COMPLETE
The model reached a validation Mean IoU of 28.55% on the last epoch. Following are the loss, accuracy, and mean IoU graphs after training.
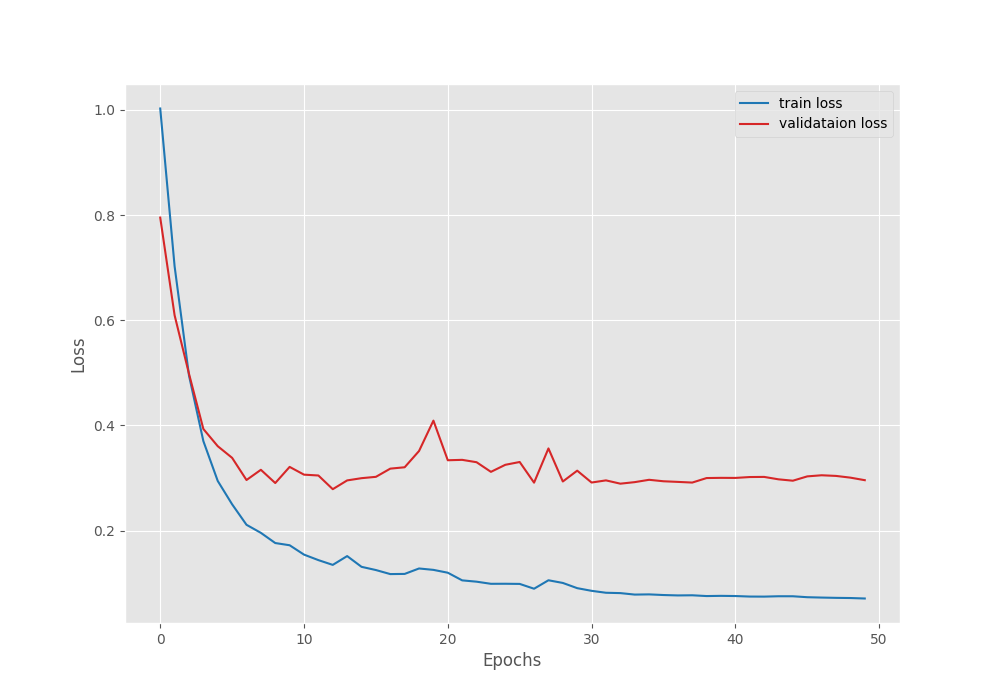
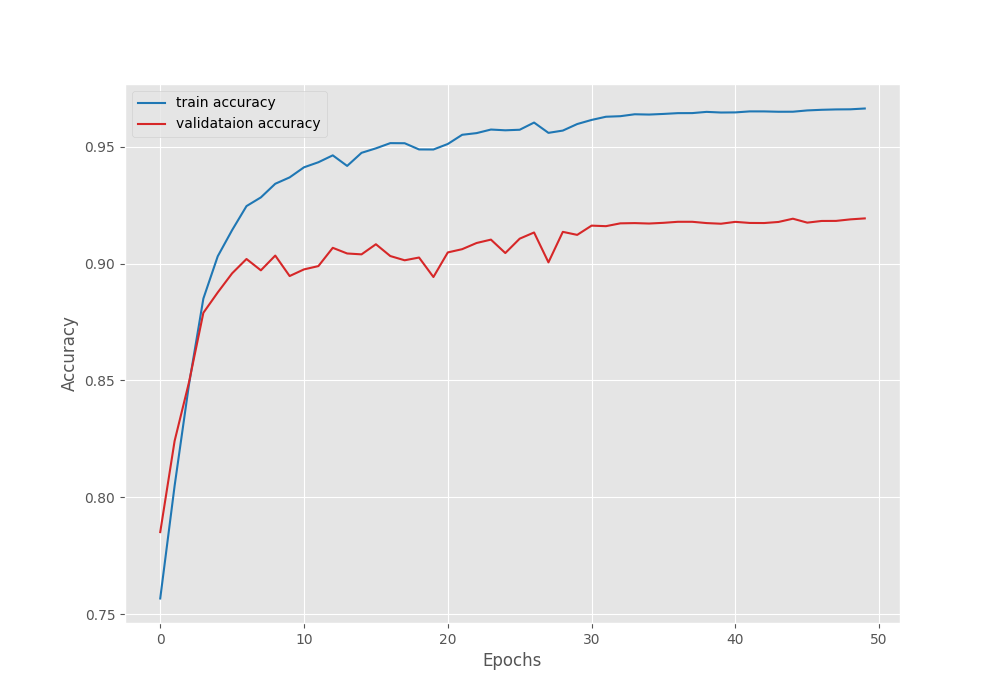
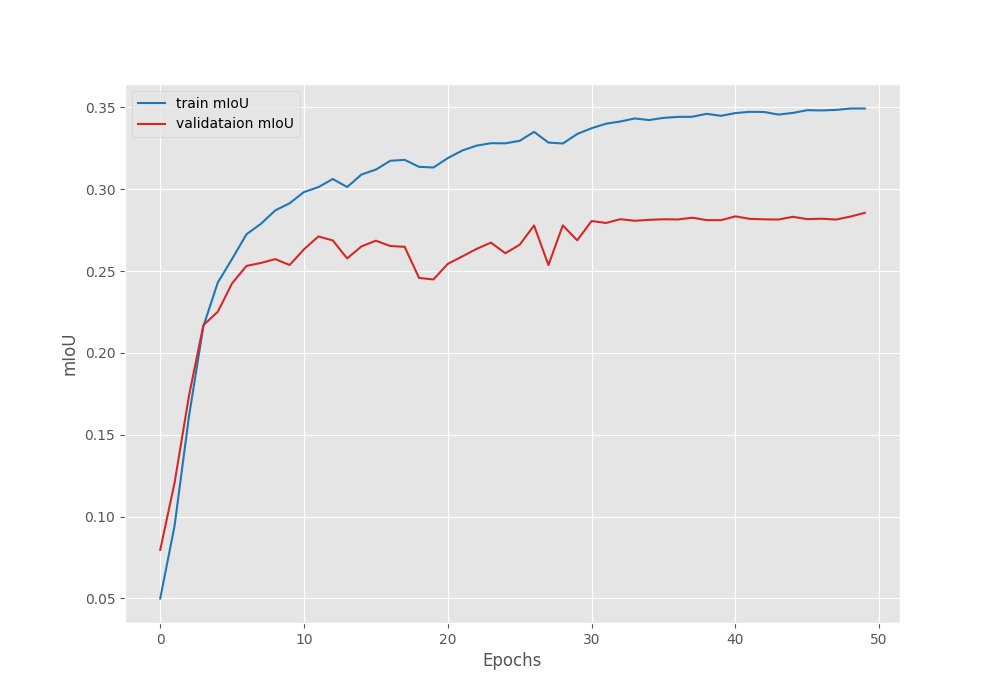
It looks like the IoU was still improving and we could have trained the model for a few more epochs. Still, let’s use the best mIoU model that we have for now and run inference.
Inference on Images
To run inference on images, we will use the inference_image.py script. There are a few considerations while running the inference:
- The model can only handle static images of 512×512 resolution. This means that we need to resize all the images before feeding them to the network.
- However, all images will not look proportionally good after resizing. The aspect ratio will be affected.
- For this reason, we will run inference on the 512×512 images, but resize the final segmentation map to the original image size and then overlap them.
- The results will not be perfect and in fact, maybe blurry in most cases. Still, the images will not be distorted.
You can get more details by going through the inference_image.py script.
We can run the following command to start the inference process.
python inference_image.py --model outputs/best_model_iou.pth --imgsz 512 512 --device cuda --input inference_data/images/
The script accepts the path to the pretrained model weights, the image size for resizing, the computation device, and the path to the images.
Here are the results.

Here, we only have images of persons. We can see that the model has learned to segment the persons but not that well. It needs more training and the resizing of the segmentation map is also affecting the results.
Inference on Videos using the VOC Trained FasterViT Model
Now, let’s run inference on videos. For this, we will use the inference_video.py script.
The following inference experiments were run on an RTX 3080 GPU.
python inference_video.py --model outputs/best_model_iou.pth --imgsz 512 512 --device cuda --input inference_data/videos/video_4.mp4
The command remains similar to the image inference one, except for providing the path to a video file.
The results are not that bad at all. It is able to segment the horse well in most cases apart from the legs where the segmentation needs to be finer. Furthermore, the FPS is not that high as well. We are only getting 14 FPS on a high-end GPU. So, the model needs more optimization which we will see in future posts.
Let’s try a more difficult scenario.
python inference_video.py --model outputs/best_model_iou.pth --imgsz 512 512 --device cuda --input inference_data/videos/video_5.mp4
Here we have various types of vehicles, however, the model can only segment the cars very well. In the case of buses, the segmentation maps are proper only when they are fully visible.
Want to know more about Transformer based semantic segmentation models?
Be sure to check the SegFormer and Mask2Former series of articles.
- SegFormer for Semantic Segmentation
- Training SegFormer for Person Segmentation
- Road Segmentation using SegFormer
- Fine-Tuning SegFormer for Multi-Class Segmentation
- Mask2Former: Semantic, Panoptic, and Instance Segmentation with One Architecture
- Fine Tuning Mask2Former
- Multi Class Segmentation using Mask2Former
Summary and Conclusion
In this article, we trained a FasterViT-0 based segmentation model. We took the ImageNet pretrained backbone and trained the FasterViT model on the Pascal VOC segmentation dataset. Although the results are not excellent, we know where the model needs improvements which we will try to tackle in future articles. I hope that this article was worth your time.
If you have any doubts, thoughts or suggestions, please leave them in the comment section. I will surely address them.
You can contact me using the Contact section. You can also find me on LinkedIn, and X.

3 thoughts on “Training FasterViT on VOC Segmentation Dataset”