
Transformer neural networks (or just Transformers) have taken over the world of deep learning by storm. Starting from impressive capability in NLP, and chatbot systems, to computer vision, they seem to be able to perform all tasks. Transformer neural networks are quite good at object detection also. DETR (Detection Transformer) by Facebook was one of the first transformer based object detection neural networks. In this article, we will start our journey with DETR for object detection.

In today’s scenario, DETR is not the object detection model with the highest mAP (Mean Average Precision). But they are capable of high quality detections with a good balance between speed and accuracy. As such, we will explore four different DETR models in this article. Along with a brief on the performance of each of the DETR models, we will also run inference using them. This will allow us to compare the FPS for each of them.
We will cover the following points in this article:
- We will start with a brief discussion of four different Detection Transformer models. These include:
- DETR ResNet50 and ResNet50 DC5
- DETR ResNet101 and ResNet101 DC5
- After a performance analysis as mentioned in the paper, we will start our own inference experiments. For this, we will use a library dedicated to vision transformers. More on this later.
- While running inference, we will check the FPS and detection quality for each of the models. This will provide us with a good analysis for the fastest as well the most accurate model.
Detection Transformer for Object Detection
The DETR model was introduced by Facebook AI in the End-to-End Object Detection with Transformers paper by Carion et al.
DETR was one of the first object detection models to use the transformer architecture and attention mechanism. It takes inspiration from the NLP world, where transformers show huge potential in language modeling.
Along with the transformer based approach, it has a few other interesting architectural decisions as well. Although we will not discuss the entire model in detail here, we will try to point out all the novel approaches in DETR.
It is important to mention that DETR can perform both object detection and panoptic segmentation. But we will focus just on object detection in this article.
DETR Architecture in Brief

DETR follows a very simple approach to object detection. It detects the final sets of bounding boxes by combining a CNN (Convolutional Neural Network) with a transformer architecture.
In object detection, we generally have the concept of anchors. The predicted bounding boxes are then passed through NMS to get the final predictions. But DETR always predicts 100 bounding boxes by default. This is configurable. We need some methods to match the ground truth boxes with the predictions. For this, DETR uses bipartite matching. This uniquely assigns predictions with ground truth boxes.
Let’s go a bit deeper into the architecture now.
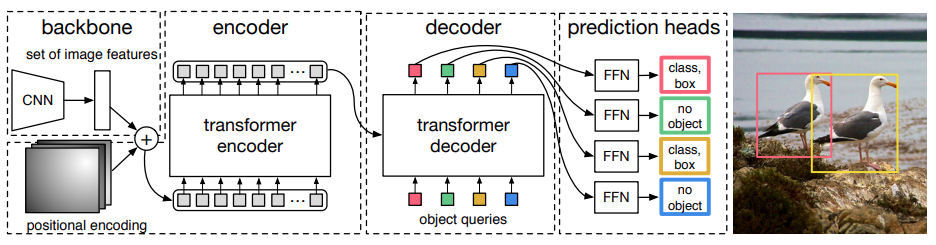
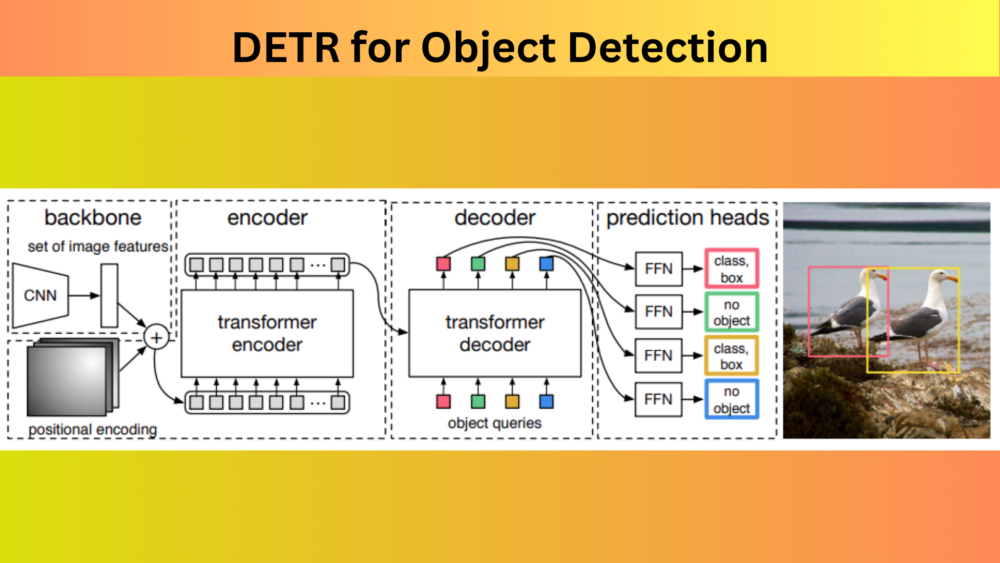
The main aim of the authors with DETR was to provide a simple pipeline for inference and training. For this, the model also needs to be simple, even when using the transformer architecture.
As we can see in the above figure, DETR uses a CNN model as the backbone. In the official code, it was the ResNet architecture.
The CNN backbone learns the 2D representations and flattens the output. This output goes into the positional encoding which then goes into the transformer encoder. Here, it learns the positional embeddings which are then passed on to the decoder. We then pass the output embeddings of the transformer decoder to an FFN (Feed Forward Network). The FFN either detects an object class or a 'no object' class.
Here is a detailed architecture of the DETR model.
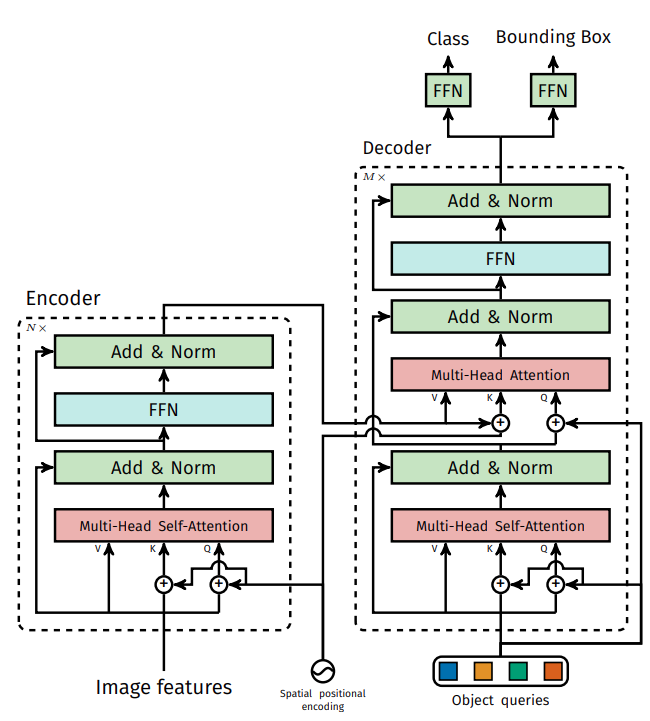
We skip quite a few details above, like bipartite matching, positional encodings, and the transformer encoder/decoder. We will cover all of these in future articles for sure.
For now, let’s move on to the performance of the DETR models.
DETR Performance Comparison and Experiments
At the time of release, the main aim of the authors was to beat the Faster RCNN baseline using DETR. But as of now, the updated Faster RCNN ResNet50 FPN V2 performs better than the DETR models. Still, let’s go through the performance comparison.
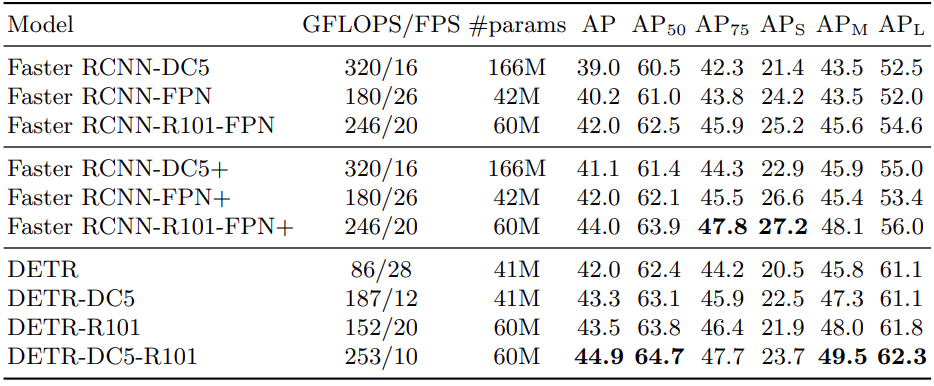
The above image shows the performance comparison of the various DETR models with Faster RCNN models. As we can see, there are 4 DETR models. Just DETR is the model with a ResNet50 backbone. We also have another one with the ResNet101 backbone. The DC5 indicates a better but slower model. It used dilated C5 stage which increases the resolution of the feature maps of the last stage of the CNN backbone. The upsample happens by a factor of 2 which leads to better detection of smaller objects.
Note: DC5 models do not lead to an increase in parameters.
As we can see, the DETR DC5 model with ResNet101 backbone having 44.9 mAP is the best performing model of all.
The Vision Transformers Library for Object Detection using DETR
For the past few months, I have been working on a library for Vision Transformer models. Currently, it supports fine tuning of transformer based classification models and the four DETR models.
We can also use the library to run inference using the pretrained DETR models. Because the setup of vision_transformers is easy, we will use this for running inference on images and videos using DETR.
Set Up the vision_transformers Library
Before installing the vision_transformers library, I recommend that you install PyTorch manually from the official site. This will ensure proper CUDA support according to your configuration. You can use any PyTorch version starting from 1.10. For example, the following installs PyTorch 2.0.0 using the conda package manager.
conda install pytorch torchvision torchaudio pytorch-cuda=11.7 -c pytorch -c nvidia
Then install vision_transformers.
pip install vision-transformers
Finally, clone the GitHub repository in the working directory of your choice and install the rest of the dependencies.
git clone https://github.com/sovit-123/vision_transformers.git
cd vision_transformers
pip install -r requirements.txt
That’s it, we are done with the setup of the vision_transformers library.
Project Directory Structure
Before moving into the inference part, let’s check the directory structure.
├── input
│ ├── video_1.mp4
│ └── video_2.mp4
└── vision_transformers
├── data
├── examples
├── example_test_data
├── readme_images
├── runs
├── tools
├── vision_transformers
├── README.md
├── requirements.txt
└── setup.py
- The
vision_transformersdirectory is the library that we just cloned above. It contains all the code that we need. We need not go into the technical details in this post. - We have a couple of videos in the
inputdirectory. For our purpose, we will run inference on one of the videos to check the performance.
The input files will be available while downloading the zip file for this post. To run inference, you will need to follow the above installation steps. Apart from that, all the models will download automatically when running inference for the first time.
Using DETR to Run Video Inference
In this section, we will use all four DETR models for inference on the same video. This will allow us to do a qualitative comparison between the detection quality.
We will use the inference_video.py script present inside the tools directory for the experiments.
Note: All the inference experiments were carried out on a system with 10 GB RTX 3080 GPU, i7 10th generation CPU, and 32 GB of RAM.
Download Code
Inference using DETR ResNet50
We will start with the DETR ResNet50 model. You can execute the following command in the terminal inside the vision_transformers directory to start the experiment.
python tools/inference_video_detect.py --input ../input/video_2.mp4 --model detr_resnet50 --show
We are using the following flags in the above command:
--input: To provide that path to the input video.--model: Name of the model. We can choose fromdetr_resnet50,detr_resnet50_dc5,detr_resnet101, anddetr_resnet101_dc5.--show: This is a boolean flag indicating that we want to visualize the outputs on the screen as the predictions are happening.
The inference script uses a default score threshold of 0.5.
On the RTX 3080 GPU, the DETR ResNet50 model was able to achieve an average of 53.6 FPS. This is not too bad.
Let’s take a look at the results.
The results are good to start with. The model is able to detect all the important objects including traffic lights. But we can that there is quite a lot of flickering. Also, it is detecting one of the partially occluded cars as a person. Let’s see if the issues go away with better models.
Inference using DETR ResNet50 DC5
Using the DETR ResNet50 DC5 model just needs changing the --model flag.
python tools/inference_video_detect.py --input ../input/video_2.mp4 --model detr_resnet50_dc5 --show
This runs slightly slower compared to the previous model, with an average FPS of 47.2.
Here are the results.
The detections are a bit better here. But we can still see the fluctuations and the wrong detection of the car as a person is still present.
Inference using DETR ResNet101
Now, we will use a bigger model, DETR with the ResNet101 backbone. This contains over 60 million parameters.
python tools/inference_video_detect.py --input ../input/video_2.mp4 --model detr_resnet101 --show
This time, the FPS drops even further to 42.1
These results are better than the previous ones. In a few of the frames, it is correctly detecting the car. But the predictions can be even better.
Inference using DETR ResNet101 DC5
Finally, we will use the best model among the four. The DETR ResNet101 DC5 model.
python tools/inference_video_detect.py --input ../input/video_2.mp4 --model detr_resnet101_dc5 --show
It is the slowest among the four models with an average of 39.3 FPS.
Let’s see if the FPS trade-off is worth it.
Some of the results are certainly better compared to the previous 3. For example, there is less fluctuation in traffic light detections. But the other issues still remain.
Feel free to run experiments on any video of your choice.
Most probably, fine tuning the models on custom datasets will yield the best use case results. But it is very important to keep in mind that vision transformer models require a huge amount of data to perform better than CNN based object detection models.
Summary and Conclusion
In this article, we started our journey with DETR, a transformer based object detection. After going through a brief discussion on the model architecture and results, we ran some inference experiments on a video. This helped us analyze the results of all four DETR models. In the next blog post, we will use the DETR model to fine tune it on a custom object detection dataset. I hope that this article was worth your time.
If you have any doubts, thoughts, or suggestions, please leave them in the comment section. I will surely address them.
You can contact me using the Contact section. You can also find me on LinkedIn, and X.
Object Detection Articles Not to Miss
- Getting Started with Single Shot Object Detection
- Train PyTorch RetinaNet on Custom Dataset
- Train SSD300 VGG16 Model from Torchvision on Custom Dataset
- Fine Tuning Faster RCNN ResNet50 FPN V2 using PyTorch
References

Excellent presentation .
Thank you.
Thanks for your updates and great work on the VIT repo. I have a problem for training my own custom datasets in XML format such as aquarium datasets. when changing the path in yaml files according to training and validation files, the training works but evaluation metrics give me zero. please help me
Hi, I have replied you on email. Please check.