

A lot of times, the pretrained models out there may not serve our purpose for the problem that we have at hand. In deep learning, one may face this issue with pretrained object detection models quite a lot. For instance, Torchvision has two SSD models pretrained on the COCO dataset. One with VGG16 backbone, and a lite version with MobileNetV3 backbone. But what if we want to change the backbone with a more efficient one? Like ResNet or maybe ShuffleNet. In this tutorial, we will learn how to use a Torchvision ImageNet pretrained custom backbone for PyTorch SSD.

One question that may arise is “Why do we need a custom backbone for an object detection model when we have so so many out there”?
A lot of times, the pretrained models may not suffice our needs. Sometimes, while solving a problem we may not want to use another object detection library apart from PyTorch. Or maybe we do not want to use SSD with VGG16 backbone. Or if nothing else, for learning purposes, so that we can solve any type of object detection problem in the future.
The above reasons are not exhaustive but they are enough to explore how to use a custom backbone for PyTorch SSD models.
Let’s take a look at the points that we will cover in this post.
- We will start with a discussion of the dataset.
- Then in the coding section, we will primarily focus on the model preparation part. That is, how to load an ImageNet pretrained backbone and attach an SSD object detection head to it.
- We will go through the rest of the code as and when required.
- After training, we will also run inference on unseen data.
The Person Detection Dataset to Train PyTorch SSD with Custom Backbone
In this tutorial, we will use a fairly simple object detection dataset to train the custom Single Shot Detector. We will train it on a person detection dataset which is easy, to begin with. The model will use a pretrained backbone but it has not learned to detect any objects. So, giving it a simple class to learn will be a good idea.
The dataset that we will use here is a modification of the Pedestrian Detection dataset from Kaggle. The original dataset has some labeling issues.
I have corrected all the labels and you can find the new Person Detection dataset on Kaggle. The annotations are in XML format. All the persons in the images are labeled with person class. The dataset contains 944 training, 160 validation, and 235 test samples.
Here are some of the ground truth images from the dataset.

We can see that the images are present in varied environments. The model, of course, will get to see different people in different scenarios. Hopefully, after training, it will detect a person well on unseen images.
For now, please go ahead and download the dataset if you wish to run the training on your own. After downloading and extracting the dataset, you should see the following structure.
├── Test
│ └── Test
│ └── JPEGImages [470 entries exceeds filelimit, not opening dir]
├── Train
│ └── Train
│ └── JPEGImages [1888 entries exceeds filelimit, not opening dir]
└── Val
└── Val
└── JPEGImages [320 entries exceeds filelimit, not opening dir]
After extracting the dataset, we have three directories/subdirectories.
The Train, Val, and Test directories contain the training, validation, and test splits respectively. The images and their corresponding XML annotation files are present inside the JPEGImages directories. You may explore the dataset a bit on your own before moving forward.
The Project Directory Structure
Let’s take a look at the entire directory structure before moving forward with training the Single Shot Detection model with a custom backbone.
├── data │ ├── inference_data │ │ ├── image_1.jpg │ │ ... │ │ ├── image_4.jpg │ │ └── video_1.mp4 │ ├── Test │ │ └── Test │ │ └── JPEGImages [470 entries exceeds filelimit, not opening dir] │ ├── Train │ │ └── Train │ │ └── JPEGImages [1888 entries exceeds filelimit, not opening dir] │ └── Val │ └── Val │ └── JPEGImages [320 entries exceeds filelimit, not opening dir] ├── inference_outputs │ ├── images [239 entries exceeds filelimit, not opening dir] │ └── videos │ └── video_1.mp4 ├── notebooks │ └── visualizations_data.ipynb ├── outputs │ ├── best_model.pth │ ├── last_model.pth │ ├── map.png │ └── train_loss.png ├── config.py ├── custom_utils.py ├── datasets.py ├── eval.py ├── inference.py ├── inference_video.py ├── model.py └── train.py
- First, we have the
datadirectory. This contains the person dataset in theTrain,Val, andTestfolders as discussed earlier. Along with that, we also have aninference_datadirectory containing some images and videos. We will use these for inference after training the model. - Second, we have the
inference_outputsandoutputsdirectories. These contain the outputs from the inference and training experiments respectively. The training experiment will output the mAP and loss plots along with the trained SSD model. - Third, we have a
notebooksdirectory which we can use for data exploration and visualization. - Finally, directly inside the parent project directory, we have all the Python files. We will mostly focus on the
model.pyscript.
The best trained weights and the inference data will be available via the downloadable zip file that comes with this post. You can directly use them for inference. If you wish to run the training experiments as well, please download the dataset from Kaggle.
Training PyTorch SSD Model with Custom Backbone
In the following coding and training sections, we will mostly focus on the model preparation and dataset preparation part. For other coding sections, we will only have an overview of the most important parts. The downloaded file contains all the scripts. Feel free to take your time and explore the code before your move forward.
Download Code
The Configuration File
We will go through the configuration file first. This defines all the essential components that we need for training and dataset preparation. Going through it will make the exploration of the other parts easier. All the training and dataset configuration goes into the config.py file.
import torch
BATCH_SIZE = 16 # Increase / decrease according to GPU memeory.
RESIZE_TO = 640 # Resize the image for training and transforms.
NUM_EPOCHS = 75 # Number of epochs to train for.
NUM_WORKERS = 4 # Number of parallel workers for data loading.
DEVICE = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
# Training images and XML files directory.
TRAIN_DIR = 'data/Train/Train/JPEGImages'
# Validation images and XML files directory.
VALID_DIR = 'data/Val/Val/JPEGImages'
# Classes: 0 index is reserved for background.
CLASSES = [
'__background__', 'person'
]
NUM_CLASSES = len(CLASSES)
# Whether to visualize images after crearing the data loaders.
VISUALIZE_TRANSFORMED_IMAGES = False
# Location to save model and plots.
OUT_DIR = 'outputs'
We start with defining the batch size for the data loaders, the image resolution to resize to, the number of epochs to train for, and the number of workers.
Although, we are using an SSD300 model, still, we will resize all images to 640×640 resolution for better performance.
Then we provide the paths to the training and validation directories where the images and annotations reside.
CLASSES contains two classes. One is __background__ and the other is person (the object class from the dataset).
We also have a VISUALIZE_TRANSFORMED_IMAGES attribute. If True, a few transformed images (from the dataloader) will show up on the screen when executing the training script. This helps in debugging and checking if all the augmentations and annotations are correct or not.
PyTorch SSD with ResNet Backbone
We will customize the PyTorch Single Shot Detection model with an ImageNet pretrained backbone. As a starting point, we will use the ResNet34 ImageNet pretrained model. That will help the model to start with some already learned features. The architecture is going to change a bit on top of that when we add the classification and regression heads to the model.
Let’s take a look at the code and then getting into the details will make the custom PyTorch SSD explanation a bit easier. The code for the PyTorch SSD model with the custom backbone resides in the model.py file.
import torchvision
import torch.nn as nn
from torchvision.models.detection.ssd import (
SSD,
DefaultBoxGenerator,
SSDHead
)
def create_model(num_classes=91, size=300, nms=0.45):
model_backbone = torchvision.models.resnet34(
weights=torchvision.models.ResNet34_Weights.DEFAULT
)
conv1 = model_backbone.conv1
bn1 = model_backbone.bn1
relu = model_backbone.relu
max_pool = model_backbone.maxpool
layer1 = model_backbone.layer1
layer2 = model_backbone.layer2
layer3 = model_backbone.layer3
layer4 = model_backbone.layer4
backbone = nn.Sequential(
conv1, bn1, relu, max_pool,
layer1, layer2, layer3, layer4
)
out_channels = [512, 512, 512, 512, 512, 512]
anchor_generator = DefaultBoxGenerator(
[[2], [2, 3], [2, 3], [2, 3], [2], [2]],
)
num_anchors = anchor_generator.num_anchors_per_location()
head = SSDHead(out_channels, num_anchors, num_classes)
model = SSD(
backbone=backbone,
num_classes=num_classes,
anchor_generator=anchor_generator,
size=(size, size),
head=head,
nms_thresh=nms
)
return model
Code Explanation for PyTorch SSD with ResNet34 Backbone
First, we import all the necessary classes from torchvision.models.detection.ssd (line 4). After that, all the logic takes place in the create_model function.
On line 11, we create an instance of the ResNet34 model with ImageNet pretrained weights. From lines 14 to 21 we extract all the necessary layers that we need to create the entire backbone before the classification head. Then on line 22, we create the final backbone wrapped within a Sequential module.
After the backbone, we also need to add new convolutional layers for the classification and regression head. The number of layers in both heads has to match. For this, we create an out_channels list on line 26. This defines the input channels of six new 2D convolutional layers. The first input channel in this list has to match the output channel of the last layer from the backbone. This is 512 for ResNet34. For the rest five 2D convolutional layers, we use 512 input channels as well.
Then we define the aspect ratios of anchor boxes using DefaultBoxGenerator. We keep this the same as in the official code that is used for pretraining the model on the COCO dataset. These may not be the best numbers for person detection, but they should work optimally well.
Line 30 defines the number of anchors based on the aspect ratios.
Next, we create the detection and classification head based on out_channels list, num_anchors, and the num_classes.
Note: The number of classes is 2 for this dataset. 0 for the background class, and 1 for the person class.
Finally, we combine all and create the SSD model. We also pass the size argument. According to this, all the images will be resized internally.
The following is the output for the detection and the classification head.
(head): SSDHead(
(classification_head): SSDClassificationHead(
(module_list): ModuleList(
(0): Conv2d(512, 8, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): Conv2d(512, 12, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(2): Conv2d(512, 12, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): Conv2d(512, 12, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): Conv2d(512, 8, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(5): Conv2d(512, 8, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
)
(regression_head): SSDRegressionHead(
(module_list): ModuleList(
(0): Conv2d(512, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): Conv2d(512, 24, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(2): Conv2d(512, 24, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): Conv2d(512, 24, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): Conv2d(512, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(5): Conv2d(512, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
)
)
As we can see, there are 6 convolutional layers in each SSD head.
Custom Utilities and Dataset Preparation
The custom_utils.py script contains a lot of helper functions and classes.
Apart from functions for saving the best model weights and plots, it also contains the augmentations that we apply to the images. We define the augmentations under the get_train_transform() function. These are directly used in the datasets.py script when preparing the dataset.
To prevent overfitting, we apply quite a number of augmentations. Here is a complete list of them.
- HorizontalFlip
- Blur
- MotionBlur
- MedianBlur
- ToGray
- RandomBrightnessContrast
- ColorJitter
- RandomGamma
We can execute the datasets.py script which shows a few images after decoding them from the data loaders. This way we can verify whether the augmentation and resizing operations are properly applied or not. The following are a few images after executing datasets.py.

We can see that the images are resized. Also, the first image appears blurry and pixelated because of the augmentations.
The Training Script
The train.py file is the driver script and contains all the code for training. These include the training & validation functions, creating the data loaders, and initializing the model.
We will be using the SGD optimizer with a starting learning rate of 0.0005 and a momentum of 0.9. A learning rate scheduler will be applied after 45 epochs to reduce it by a factor of 10.
If you wish, you can go over the training script before executing the training.
In the parent project directory, execute the following command to start the training.
python train.py
Here is the truncated output from the terminal.
Number of training samples: 944 Number of validation samples: 160 . . . EPOCH 1 of 75 Training Loss: 9.3790: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 59/59 [00:16<00:00, 3.48it/s] Validating 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 10/10 [00:01<00:00, 5.18it/s] Epoch #1 train loss: 12.464 Epoch #1 [email protected]:0.95: 0.036912836134433746 Epoch #1 [email protected]: 0.16292478144168854 Took 0.472 minutes for epoch 0 BEST VALIDATION mAP: 0.036912836134433746 SAVING BEST MODEL FOR EPOCH: 1 SAVING PLOTS COMPLETE... Adjusting learning rate of group 0 to 5.0000e-04. . . . EPOCH 37 of 75 Training Loss: 1.5863: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 59/59 [00:14<00:00, 4.03it/s] Validating 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 10/10 [00:02<00:00, 4.99it/s] Epoch #37 train loss: 1.992 Epoch #37 [email protected]:0.95: 0.24836641550064087 Epoch #37 [email protected]: 0.652535080909729 Took 0.360 minutes for epoch 36 BEST VALIDATION mAP: 0.24836641550064087 SAVING BEST MODEL FOR EPOCH: 37 SAVING PLOTS COMPLETE... Adjusting learning rate of group 0 to 5.0000e-04. . . . EPOCH 75 of 75 Training Loss: 0.6868: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 59/59 [00:14<00:00, 3.96it/s] Validating 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 10/10 [00:01<00:00, 5.12it/s] Epoch #75 train loss: 0.778 Epoch #75 [email protected]:0.95: 0.22010944783687592 Epoch #75 [email protected]: 0.6166431903839111 Took 0.308 minutes for epoch 74 SAVING PLOTS COMPLETE... Adjusting learning rate of group 0 to 5.0000e-05.
We use mAP as the object detection evaluation metric here. The model reaches the best mAP of 24.83% at 0.50 IoU on epoch 37. At IoU 0.50:095, the mAP is 65.35%. It is not too bad considering we do not even have 1000 images.
Let’s take a look at the plots.
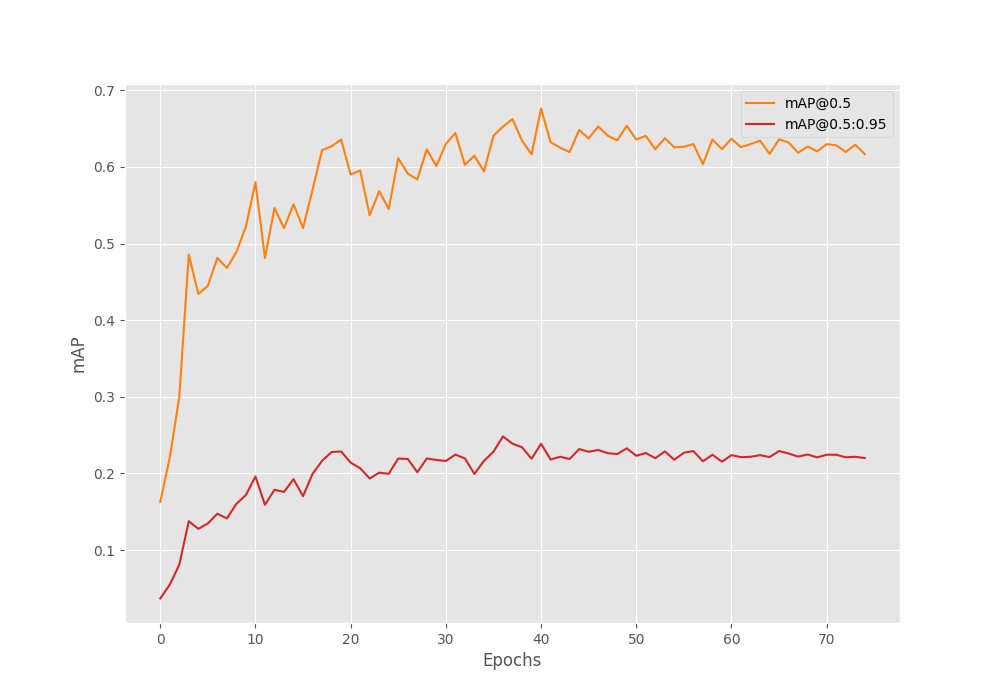
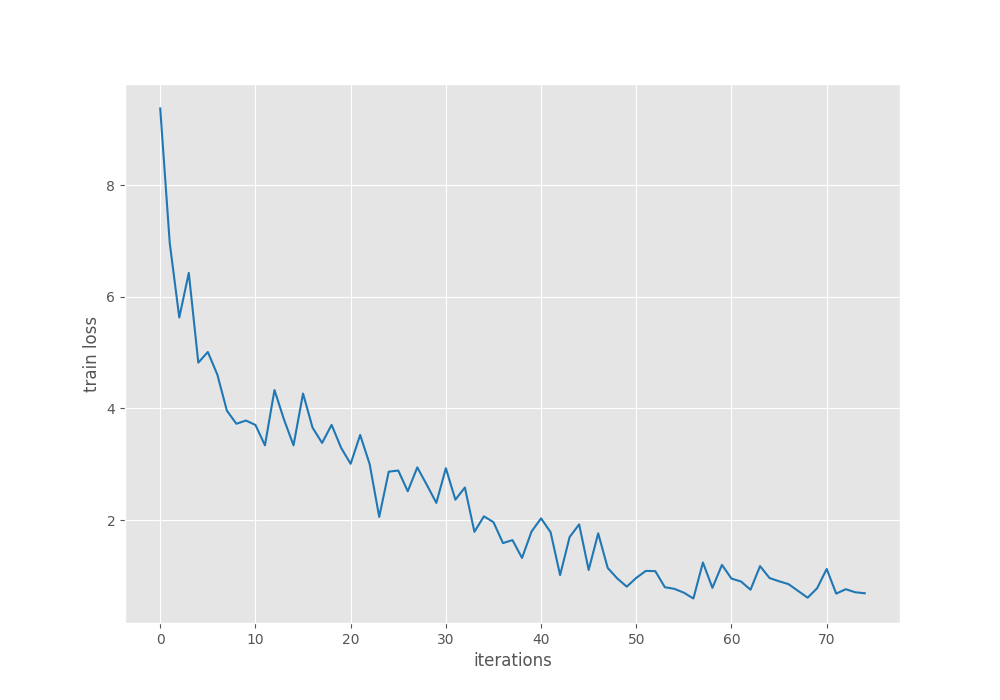
Although the training loss is decreasing till the end of the training, the mAP seems to reduce after around 50 epochs. The mAP does not improve after epoch 37 even after applying the learning rate scheduler.
Evaluation on the Test Dataset
We have the best trained model now. There is also a test set that contains the ground truth annotations. Let’s run evaluation on it using the eval.py script. The directory path has been hardcoded into the script for now.
python eval.py
The following are the results.
100%|████████████████████████████████████████████████████| 15/15 [00:03<00:00, 5.00it/s] mAP_50: 58.024 mAP_50_95: 19.222
We have an mAP of 58% at 0.50 IoU and 19.22 % at 0.50:0.95 IoU. This is slightly lower compared to the validation set.
Inference on Images and Videos
First, we will run inference on the test images, and then inference on some videos that are not part of the dataset.
To run inference on the test images, we can run the following command:
python inference.py --input data/Test/Test/JPEGImages/
We run inference on all the images from the test set.
Here are some of the good results.

And here are some images where the model did not perform very well.

To run inference on videos, we need to run the inference_video.py script while providing the path to the video file. We use the default score threshold of 0.25 in the following experiments.
Let’s start with a slightly crowded scene.
python inference_video.py --input data/inference_data/video_1.mp4 --imgsz 640
The model ran at 150 FPS on average on an RTX 3080 GPU.
The results are very mixed here. In some of the frames, the model is performing really well, while in others there is a lot of flickering. Also, it is unable to detect persons at a distance.
Here is another result.
Interestingly, although the persons are closer to the camera, the flickering does not go away.
Making Improvements to the PyTorch SSD Model with Custom Backbone
There are a few ways to make the model even better.
- We can start by training it on more data.
- We can also try a larger backbone like ResNet50 which may prove to be a better feature extractor.
- Also, we can add FPN (Feature Pyramid Network) which can help the backbone a lot when dealing with small objects.
Posts Not to Miss
- Object Detection using SSD300 ResNet50 and PyTorch
- Fine SSD with VGG16 backbone
- Getting Started with Single Shot Object Detection
Summary and Conclusion
In this tutorial, we learned how to add a custom backbone to a PyTorch SSD head. Using such methods we can create our custom object detection models. We also trained the custom SSD model on a person detection dataset and analyzed the results. Although the results were not very good, they were still decent. We also discussed how to improve the performance of the model further.
If you have any doubts, thoughts, or suggestion, please leave them in the comment section. I will surely address them
You can contact me using the Contact section. You can also find me on LinkedIn, and Twitter.
References

Thank you very much for a great tutorial and providing a code, but I would like to ask a question. I have one issue that I can train a model only for 640×640 resolution. As a dataset I took COCO dataset and chose one class – cars. So when I start training on 1920×1080 for example, after 25 epochs my loss become inf. I tried to reduce learning rate down to 1e-7, changed SGD to Adam, change batch size, tried gradient clipping, but nothing helped. Did you have this issue, how did you resolve it?
Thanks in advance,
Ilia
Hello Ilia.
I have not tried with 1920×1080 images. Can you let me know where you are defining the image size?
According to the config file shown in this post, the images are resized to a square shape. So, did you modify the code to run the training on 1920×1080 images?
Also, you mention that the loss becomes infinity after 25 epochs. Are the models saved before that epoch able to give proper inference results?
Hello Sovit, could you please contact me I need your help regarding my project.?
Hello Sovit, thank you for your reply.
Indeed, in the code there is only one parameter responsible for size, but in model.py in a function “create_model” you can rewrite a line “model=SSD(…, size=(size, size), …)” with “model=SSD(…, size=(1920, 1080), …)”. With batch_size=1 loss become inf after 10 epochs.
And after that I tried image size = 300 (so now image size is a square and in this test I modified config.py only) and again at 11th epoch a loss bacame inf. Here there is a log:
********************************************************************
EPOCH 11 of 75
Training
Loss: 7.0678: 1%|█▎ | 6/766 [00:00<01:30, 8.43it/s]/home/user/.pyenv/versions/3.11.4/lib/python3.11/site-packages/albumentations/augmentations/functional.py:825: RuntimeWarning: invalid value encountered in power
img = np.power(img, gamma)
Loss: inf: 100%|█████████████████████████████████████████████████████████| 766/766 [00:32<00:00, 23.69it/s]
Validating
100%|██████████████████████████████████████████████████████████████████████| 34/34 [00:01<00:00, 18.21it/s]
Epoch #11 train loss: inf
Epoch #11 [email protected]:0.95: 0.0
Epoch #11 [email protected]: 0.0
Took 0.614 minutes for epoch 10
SAVING PLOTS COMPLETE…
Adjusting learning rate of group 0 to 5.0000e-05.
********************************************************************
And whatever I tried, it always failed on 11th epoch for image resolution = 300. And of course on inference the result is very poor because after 10 epochs mAP is about 0.001.
Can you try with 300, 300 but with higher batch size? Maybe batch size 1 is causing issues.
Thank you, I will try to vary this and other parameters.
umber of training samples: 6236
Number of validation samples: 1557
SSD(
(backbone): Sequential(
(0): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(4): Sequential(
(0): Bottleneck(
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(5): Sequential(
(0): Bottleneck(
(conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(6): Sequential(
(0): Bottleneck(
(conv1): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(512, 1024, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(4): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(5): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(6): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(7): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(8): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(9): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(10): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(11): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(12): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(13): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(14): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(15): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(16): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(17): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(18): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(19): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(20): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(21): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(22): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(7): Sequential(
(0): Bottleneck(
(conv1): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(1024, 2048, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
)
(anchor_generator): DefaultBoxGenerator(aspect_ratios=[[2], [2, 3], [2, 3], [2, 3], [2], [2]], clip=True, scales=[0.15, 0.3, 0.44999999999999996, 0.6, 0.75, 0.9, 1.0], steps=None)
(head): SSDHead(
(classification_head): SSDClassificationHead(
(module_list): ModuleList(
(0): Conv2d(512, 4, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1-3): 3 x Conv2d(512, 6, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4-5): 2 x Conv2d(512, 4, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
)
(regression_head): SSDRegressionHead(
(module_list): ModuleList(
(0): Conv2d(512, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1-3): 3 x Conv2d(512, 24, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4-5): 2 x Conv2d(512, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
)
)
(transform): GeneralizedRCNNTransform(
Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
Resize(min_size=(640,), max_size=640, mode=’bilinear’)
)
)
43,191,510 total parameters.
43,191,510 training parameters.
Adjusting learning rate of group 0 to 5.0000e-04.
EPOCH 1 of 75
Training
0% 0/390 [00:00<?, ?it/s]^C
Whats happening why is it exiting after first epoch please respong to this
Hello. It looks like the training has not started. I hope you are using a GPU for training. Can you please try reducing the batch size and training again?
Hello sovit. please could you contact me I really need your help please…..
Hello Annie. You can reach out to me on [email protected]
What if I want to replace the backbone using vgg16?
Hello. You will need to modify the model.py file. Instead of loading the ResNet34 model, you need to load the VGG16 model. However, even after that minor tweaks to the layer loading will be needed.
If you need a pretrained model inference with VGG16 SSD model, you can check this article => https://debuggercafe.com/ssd300-vgg16-backbone-object-detection-with-pytorch-and-torchvision/
I’ve contacted you via email, and I’ve sent you the model.py code that I’m using, can you check it?
I have replied to you by email. Thanks.
Hello, I need to train with 100 epochs but Google colab’s GPU has a time limit. I have trained for 50 epochs and the results are saved in the outputs folder (last_model.pth). Can I use the last_model.pth model to continue training for another 50 epochs next time?
Hello. Yes, you can continue training by loading the last_model.pth state dictionary.
hello sovit
i got this error while training :
ValueError Traceback (most recent call last)
in ()
111 train_dataset = create_train_dataset(TRAIN_DIR)
112 valid_dataset = create_valid_dataset(VALID_DIR)
–> 113 train_loader = create_train_loader(train_dataset, num_workers=NUM_WORKERS)
114 valid_loader = create_valid_loader(valid_dataset, NUM_WORKERS)
115 print(f”Number of training samples: {len(train_dataset)}”)
2 frames
/content/datasets.py in create_train_loader(train_dataset, num_workers)
129 return valid_dataset
130 def create_train_loader(train_dataset, num_workers=0):
–> 131 train_loader = DataLoader(
132 train_dataset,
133 batch_size=BATCH_SIZE,
/usr/local/lib/python3.10/dist-packages/torch/utils/data/dataloader.py in __init__(self, dataset, batch_size, shuffle, sampler, batch_sampler, num_workers, collate_fn, pin_memory, drop_last, timeout, worker_init_fn, multiprocessing_context, generator, prefetch_factor, persistent_workers, pin_memory_device)
348 suggested_max_worker_msg)
349 return warn_msg
–> 350
351 if not self.num_workers or self.num_workers == 0:
352 return
/usr/local/lib/python3.10/dist-packages/torch/utils/data/sampler.py in __init__(self, data_source, replacement, num_samples, generator)
141
142 if not isinstance(self.num_samples, int) or self.num_samples 143 raise ValueError(f”num_samples should be a positive integer value, but got num_samples={self.num_samples}”)
144
145 @property
ValueError: num_samples should be a positive integer value, but got num_samples=0
Hi. I think you gave the wrong dataset path in the configuration file. Can you please recheck that?
Dear Sovit Ranjan. I have run the SSD code given in this tutorial. I am working on CPU and doing object detection. Can you please provide code for inference on videos using CPU. I an unable to run the video inference code. (I am using CPU. I have trained SSD model on CPU). Also i am working on Windows 11.
Moreover the objects in my videos are very small. The objects are small birds flying. So should i keep the image size as 640 or increase the size. The actual image size is around 1500 x 960. (I am using frames of video as input image for training). So for good inference results should i increase the 640 size?
Hello Salman. To run the inference scripts on CPU, please change the DEVICE to ‘cpu’ in the config.py file.
I have changed device to cpu while training aswell and training ran properly. But during inference i got issue as torch.transform is using cuda aswell. Moreover cv2.imshow also giving error.
Also for my second question, what max size i can use for input image. My training data images are of 1500×960 size. And objects are very small. So when i use 640 size as image input, the training results are very poor
Hello. Can you please let me know what CUDA and OpenCV error you are facing? Also, you can try the 1024 pixel resizing. For small objects that will probably give much better results.
Thanks for the help. The cuda issue resolved but still my inference is very poor despite using image size 1024.
Moreover what changes are required to set image size as 1024? Should i set Image size to 1024 in config.py file or i have to do changes in model.py aswell or in some other files
Hi Salman. You just need to make changes to the config.py file. If the results are poor, I think you should give it a try with RetinaNet, I am sure you will get better results.
https://debuggercafe.com/train-pytorch-retinanet-on-custom-dataset/
I want to modify eval.py to also compute Precision and Recall, but it didn’t work. can you guide on this?
Hello. Can you please tell the issue? Although I won’t be able to provide the entire code, I may be able to guide you.
i used this library for that:
from torchmetrics.classification import MulticlassPrecision, MulticlassRecall
i got this error:
raise ValueError( ValueError: (‘The `preds` and `target` should have the same shape,’, ‘ got `preds` with shape=torch.Size([5]) and `target` with shape=torch.Size([4]).’)
Hello. Is the code from the blog post or is it different?
I have just added the lines for computing Precision and Recall using this library:
from torchmetrics.classification import MulticlassPrecision, MulticlassRecall
From the imports, it looks that they are meant for classification and not detection. I need to check the documentation.
Hi Sovit,
Thank you for your code. I am adding code into train.py and eval.py to calculate precision and recall, but I’m failing. Can you help me or do you have another version that can calculate precision and recall? I hope you reply soon.
Thank you very much
Hello. I think, the best way is to use Torchmetrics for calculating those metrics. Please take a look at this docs:
https://lightning.ai/docs/torchmetrics/stable/detection/mean_average_precision.html
Hello,
Thank you for your reply. Thank you for your reply. I read the torchmetrics docs and I see that precision and recall can only be used for task classification. So, I converted the preds and target of mAP to preds and target for Precision and Recall. And I did it. This is convert function:
def convert_detection2classification(preds, target, iou_threshold=0.7):
preds_labels = []
target_labels = []
# loop through each image
for pred, tgt in zip(preds, target):
pred_boxes = pred[‘boxes’] # pred bounding boxes
pred_labels = pred[‘labels’] # pred label
pred_scores = pred[‘scores’] # pred score
target_boxes = tgt[‘boxes’] # Ground truth bounding boxes
target_labels_actual = tgt[‘labels’] # Ground truth label
# Calculate IoU between all pred and ground truth label pairs
if len(pred_boxes) > 0 and len(target_boxes) > 0:
iou_matrix = box_iou(pred_boxes, target_boxes)
# loop through ground truth label
for i, tgt_label in enumerate(target_labels_actual):
# find bounding box pred have max IoU for this ground truth label
iou_max, idx = iou_matrix[:, i].max(0)
if iou_max >= iou_threshold:
# if IoU >= threshold –> True Positive
preds_labels.append(pred_labels[idx].item()) # get value pred label
target_labels.append(tgt_label.item()) # get value ground truth label
else:
# if all IoU False Negative
target_labels.append(tgt_label.item())
preds_labels.append(-1) # No pred true
else:
# if there is no pred or ground truth label, it’s all False Negative
for tgt_label in target_labels_actual:
target_labels.append(tgt_label.item())
preds_labels.append(-1)
return torch.tensor(preds_labels), torch.tensor(target_labels)
Hello. Thanks for the update here. I hope your code is working.
Hello Sovit, I am new in object detection learning, and tested your code and it worked fine. Thanks for making this tutorial. I have a question regarding the SSD, any idea why people don’t use SSD anymore compared to other methods like yolo. In addition, after SSDlite 320 there was no new model for SSD. Does this mean that SSD is not suitable for the industry or research? Interestingly on a custom dataset I can see SSDlite works as good as yolov8 or yolov11. I also noticed that the performance of yolo is good for speed but for detection I would say SSD or Faster RCNN are still better.
Lastly, I want to use a commercial-friendly model for a project. Any recommendations?
Thank you
Hello Rohit. You have made some good observations. I would say people go with YOLO only because of ease of use. However, the AGPL license of Ultralytics is a big hindrance which does not allow free usage for commercial applications.
If you have a good dataset and a good pipeline with proper hyperparameters for training, I would recommend going with SSD320 or even RetinaNet from Torchvision. You can stay worry free as all Torchvision detection models are either MIT or Apache and do not require a commercial license.
Hello Sovit, Thank you for your response. Yes, I agree with you. I asked ultralytics for the license and they annually charge $10,000 USD which is huge. Surprisingly, Ultralytics even use SAM2 or RT-DETR which are already Apache, but they claim it to be AGPL as well. I think for commercial projects, it’s waste of time to focus on ultralytics. The best solution as you have mentioned is using Tochvision-based algorithms.
Thanks
Yes, Rohit. Whatever model gets added to Ultralytics gets converted to AGPL license. Frankly, there needs to a vision only library that has MIT/Apache models for classification, detection, and segmentation, and as easy to use as Ultralytics.
Hello, I want to practice training the SSD300 VGG16 model from Torchvision on a custom dataset in Colab, but I can’t find any GitHub links or sources to download it. Could you please help me? Thank you!
Hello. I have replied in the SSD VGG16 post. I hope that helps.
Hello Sovit, I got some error while running the train.py. Can you help me?
I’ve contacted you via email, and I’ve sent you the link of google colab that I’m using, can you check it?
Hello Zahra. I have sent a reply to the email. Can you please check and try that?
I have checked and tried it. It works, thanks for your help.
Welcome.
After puting email in ‘Download the Source Code for this Tutorial’ and afer checking mail it redirecting me to website ‘https://appsumo.com/’
Can you give me direct link to download the Code.
Hello Gaurav. I have not updated the above link and replied with the link in the email as well. I hope this solves the issue.
KeyError: tensor(1) During Training
Could you help me to solve this error
Hi Gaurav. Can you try installing albumentations==1.1.0
That should solve the issue.
Thanks that’s worked
But i got problem in colab while running ” !python inference.py –input data/Test/Test/JPEGImages/”
/content/20230605_Using_Custom_Backbone_for_PyTorch_SSD_for_Object_Detection/inference.py:43: FutureWarning: You are using `torch.load` with `weights_only=False` (the current default value), which uses the default pickle module implicitly. It is possible to construct malicious pickle data which will execute arbitrary code during unpickling (See https://github.com/pytorch/pytorch/blob/main/SECURITY.md#untrusted-models for more details). In a future release, the default value for `weights_only` will be flipped to `True`. This limits the functions that could be executed during unpickling. Arbitrary objects will no longer be allowed to be loaded via this mode unless they are explicitly allowlisted by the user via `torch.serialization.add_safe_globals`. We recommend you start setting `weights_only=True` for any use case where you don’t have full control of the loaded file. Please open an issue on GitHub for any issues related to this experimental feature.
checkpoint = torch.load(‘outputs/best_model.pth’, map_location=DEVICE)
Test instances: 235
(629, 500, 3)
qt.qpa.xcb: could not connect to display
qt.qpa.plugin: Could not load the Qt platform plugin “xcb” in “/usr/local/lib/python3.11/dist-packages/cv2/qt/plugins” even though it was found.
This application failed to start because no Qt platform plugin could be initialized. Reinstalling the application may fix this problem.
Available platform plugins are: xcb.
Hi Gaurav. The inference script uses OpenCV for visualization. So, you will need to execute that locally.
Hi Sovit,
I wanted to share an idea with you, which could be useful for the object detection community. We have SSDlitemobilenetv3 in the past, and with the last year release of mobilenetv4, I think it would be great if someone creates SSDlite Mobilenetv4. I haven’t seen anyone has done it yet, although I provided this idea to the main authors as well. I guess if you are interested and have time then you can make an SSDlite Mobilenetv4. I have a strong impression that it will be better than previous SSD models in terms of FPS. Unfortunately, I don’t have much computing resources but I guess you could be the perfect person for it to model.
Hello Subhan. Thanks for taking an interest in this. One issue is that torchvision does not have a pretrained MobileNetv4. Although Hugging Face Transformers has, it is usually difficult to modify and add detection heads. I will surely try though.
Hi Sovit,
Thank you for the response. I got the following response from the author when I asked him about it integrating it from hugging face transformers:
It’d work fine, there is an API for extracting the needed features it just needs to be wired up w/ an object dection code base and trained….
Not sure which API he was talking about, but if I get any response from him then I will let you know.
That’s great. If you get any further response, please keep me updated.