

With every new update, PyTorch brings something new. Most of the time, PyTorch modules get a performance update. Like, faster training on existing hardware, and better support on newer hardware. Of course, there are other major updates and bug fixing also. But with PyTorch 1.12, some pretty major updates happened for the pretrained models also. This is mainly for Torchvision (Torchvision 0.13 in this case), but other library models also got some nice updates. In this blog post, we will mainly discuss the major updates that took place for the Torchvision model library with PyTorch 1.12.
This blog post is like a PyTorch library walkthrough. Although mostly focused on Torchvision 0.13 model library updates that we got with PyTorch 1.12, we will also discuss other updates for a small part as well.
All the points that we will discuss here are fundamental to how we load pretrained models and use them for inference and fine-tuning. I hope this will help many developers get familiar with the updates much faster. Especially, I hope that this post helps beginners in PyTorch navigate the pretrained models’ landscape better than before.

Before diving into the details, let’s check out the topics that we will cover in this post:
- Multi-weight support with Torchvision 0.13.
- New image classification architectures:
- EfficientNetv2.
- Swin Transformer.
- New object detection model weights.
- Image classification model-refresh with updated training recipe for ImageNet pretraining.
- New data augmentation techniques.
Multi-Weight Support with ImageNetV2 Weights
With PyTorch 1.12 also comes Torchvision 0.13. And with Torchvision 0.13 comes newly updated ImageNet weights for a lot of the pretrained models. This is perhaps one of the major updates in the model library of PyTorch 1.12. In short, these new ImageNet pretrained weights give around 3% more accuracy on average. This was obtained using updated training recipes which we will check out in one of the later sections.
Does that mean the older arguments and weights are useless? Well no, at least not at the moment. But they will slowly be deprecated. Right now, we can still use older arguments and keywords to load the ImageNet pretrained weights. Along with that, we have the option (newer method and syntax) to load either the older ImageNet weights or the updated ImageNet weights. In the future also, we will be able to load the older ImageNet weights but only by using the newer syntax (we will get to that shortly).
The following GIF from the official documentation shows in a very concise manner the difference between the older and newer syntax.

As you can see, we will no longer be using the pretrained argument. Rather we have the new weights argument now to choose either between the ImageNetV1 weights or the updated ImageNetV2 weights.
Using the New Syntax To Load Weights
Now, let’s check out the new syntax to load either the ImageNetV1 or ImageNetV2 weights. As discussed above, the pretrained argument to load the pretrained weights will slowly deprecate with upcoming versions. With Torchvision version 0.13, we have a few different ways that we can use to load the ImageNet weights.
Let’s take the case of loading the MobileNetV3 Large model here and different cases of using the weights argument either to load the pretrained weights or not.
Not loading the pretrained weights.
import torchvision.models as models model = models.mobilenet_v3_large(weights=None)
If we want to train the model from scratch, we can provide None to the weights argument.
Loading the new ImageNetV2 weights.
Ideally, we should choose the ImageNetV2 weights as they possibly will give the best results while fine-tuning. We can do that using either of the three following ways.
import torchvision.models as models model = models.mobilenet_v3_large(weights=models.MobileNet_V3_Large_Weights.IMAGENET1K_V2)
OR
import torchvision.models as models model = models.mobilenet_v3_large(weights="IMAGENET1K_V2")
OR
import torchvision.models as models model = models.mobilenet_v3_large(weights=models.MobileNet_V3_Large_Weights.DEFAULT)
Using the DEFAULT case will load the best available weights for that model. And most probably, it is going to be the ImageNetV2 weights as they are providing better accuracy compared to the ImageNetV1 weights.
Loading New Transforms and Prediction Labels
The new pretrained weights need newer transforms for inference and fine-tuning. But we do not need to worry much about mentioning the new transforms manually as we can use the new API syntax to do that.
import torchvision.models as models # Initialize the Weight model and Transforms. weights = models.MobileNet_V3_Large_Weights.DEFAULT model = models.mobilenet_v3_large(weights=weights) preprocess = weights.transforms() # Apply it to the input image. image_transformed = preprocess(imgage)
On a similar note, it is now much easier to obtain the final category name (label name) for image classification using the new API.
# Source => https://pytorch.org/vision/0.13/models.html#classification
prediction = model(batch).squeeze(0).softmax(0)
class_id = prediction.argmax().item()
score = prediction[class_id].item()
category_name = weights.meta["categories"][class_id]
print(f"{category_name}: {100 * score:.1f}%")
As we can see, the new meta attribute holds the category data which we can easily load.
You can get full details of all the API updates in the official docs here.
New ImageNet Classification Architectures
The new Torchvision update also brings two very important classification architectures into the library. Those are:
- Swin Transformer
- EfficientNetV2
This brings 6 new pretrained models in total (3 each) into the library. It seems from the library that the newly added models and weights for the two architectures are still with the ImageNet1k_V1 weights (at least as of writing this, which may change in the future). Nonetheless, the EfficientNetV2 weights seem to be some of the highest performing weights in the entire library with more than 85% top-1 accuracy for the Large and Medium models.

Currently, there are only a few of the RegNet and ViT models which seem to outperform the above two EfficientNetV2 models. Three RegNet models actually outperform all the other models in the library right now with more than 86% top-1 accuracy. Although, it is worthwhile to note that one of those RegNet models has a whopping 644.8M parameters.
New Object Detection Model Weights
With the new version of Torchvision, two of the object detection architecture weights have also been updated. They are:
- FasterRCNN ResNet50 FPN v2
- RetinaNet ResNet50 FPN v2
The FasterRCNN model gets a massive 9.7% increase in box mAP while the RetinaNet model gets a 5.1% increase in mAP.
These were achieved using new training recipes and post-paper architectural optimizations as mentioned here. These include some pretty good stuff from different papers. We may go into the details of all the optimizations in another post.
If you visit the listing of all the available object detection weights here, you may notice something interesting.
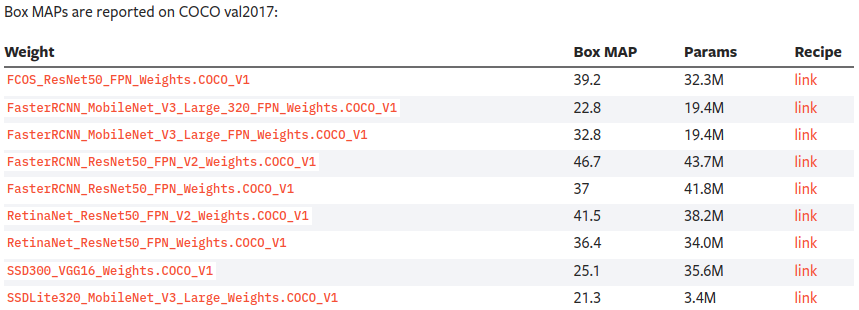
All of the weights mentioned are COCO_V1 weights. This means that, in the next versions of model library updates with PyTorch, we may also get V2 weights for COCO just as we got for ImageNet in the current version. That will be really interesting to check out.
Moreover, as we have new weights for these two object detection models now, it will also be interesting to compare their performances in transfer learning on custom datasets.
Image Classification Model Refresh with Updated Training Recipe for ImageNet Pretraining
In one of the previous sections, we discussed that now ImageNet1k_V2 weights are available for some of the models. Hopefully, other models will also get weight updates in future versions.
If you want to get the details of the new training recipe, you can visit this link. These include new training recipes for the following among others as well:
- Regularization technique.
- Augmentations.
- Model Quantization
Along with that, we also have new RegNet and ViT trained models and some of the RegNet models surpass all the other pretrained models in terms of accuracy.
And the following link contains all the models that got a refresh with ImageNet1k_V2 weights.
Among others, this contains different ResNet, MobileNet, ResNext, and Wide ResNet models.
New Data Augmentation Techniques
With PyTorch 1.12, now we have more data augmentation techniques. One of the more prominent ones is the AugMix augmentation.
This augmentation technique was introduced in the paper AUGMIX: A SIMPLE DATA PROCESSING METHOD TO IMPROVE ROBUSTNESS AND UNCERTAINTY by Dan Hendrycks et al.
Other augmentation techniques which are made available with the new release are:
- Large Scale Jitter
- Fixed Size Crop
- Random Shortest Side
- Simple CopyPaste
New Layers
We also have new layers with PyTorch 1.12. These include:
- DropBlock introduced in the DropBlock: A regularization method for convolutional networks paper.
- Conv3DNormActivation.
- A generic MLP block for Torchvision.
These should open up simpler and better ways to create models and advance research as well.
New Losses
And finally, we have a few important loss functions that are now added to PyTorch.
- We have the GeneralizedIOULoss. It is from the paper Generalized Intersection over Union: A Metric and A Loss for Bounding Box Regression by Rezatofighi et al.
- We also have DIoU and Complete IoU loss functions from Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression.
It seems that with PyTorch 1.12, PyTorch did not only get a model library update but a lot of other useful updates as well. If you really want to dive even deeper into all these, be sure to check their official blog post. Here, they not only post about the updates of Torchvision, but also the updates of other libraries like TorchAudio, TorchText, and TorchRec.
Summary and Conclusion
In this blog post, we explore the new model library updates that we got with the release of PyTorch 1.12. We have new features including updated classification and detection weights, new model architectures, new augmentation techniques, layers, and losses as well. With all these, PyTorch seems to be moving in a very interesting direction which possibly not only makes things easier for researchers but also for developers as well. I hope that this post was helpful to you, especially if you are just getting started with PyTorch.
If you have any doubts, thoughts, or suggestions, please leave them in the comment section. I will surely address them.
You can contact me using the Contact section. You can also find me on LinkedIn, and X.

2 thoughts on “Model Library Updates with PyTorch 1.12”