

Variational autoencoders (VAEs) are a group of generative models in the field of deep learning and neural networks. I say group because there are many types of VAEs. We will know about some of them shortly.
If you are new to autoencoders, then I recommend that you learn a bit about autoencoders before moving further. You can visit this link where you will find the basic and some advanced concepts about autoencoders. You will also get hands-on coding experience by going through these articles.
What will you learn in this tutorial?
- A brief recap about standard autoencoders and their limitations.
- About variational autoencoders and a short theory about their mathematics.
- Implementing a simple linear autoencoder on the MNIST digit dataset using PyTorch.
Note: This tutorial uses PyTorch. So it will be easier for you to grasp the coding concepts if you are familiar with PyTorch.
A Short Recap of Standard (Classical) Autoencoders
A standard autoencoder consists of an encoder and a decoder. Let the input data be X. The encoder produces the latent space vector z from X. Then the decoder tries to reconstruct the input data X from the latent vector z.
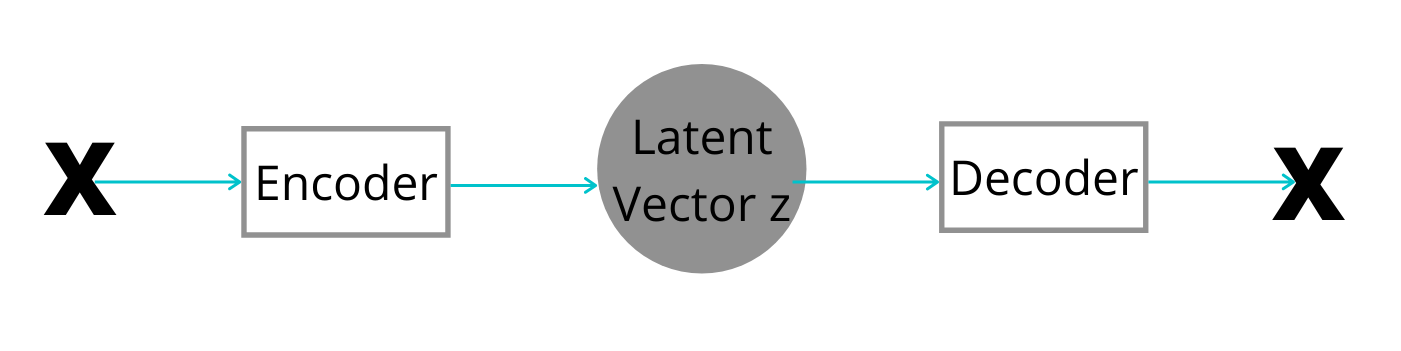
For example, let’s take the case of the MNIST digit dataset. Here, the input data X are all the digits in the dataset. The latent vector z consists of all the properties of the dataset that are not part of the original input data. Using these hidden (latent) vector properties, the decoder tries to reconstruct the original images again.
All of this sounds good, yet there are a few limitations to using standard autoencoders.
The Limitations of Standard Autoencoders
We now know that autoencoders are able to reconstruct the input data from the latent vectors. But the problem is that they can only reconstruct those types of images on which they are trained. In other words, they compress the data while producing the latent vector and try to replicate the output to the input.
Due to this, there are two major applications of standard autoencoder:
- Denoising of data, e.g. denoising images.
- Sparse reconstructions for dimensionality reduction.
Another limitation is that the latent space vectors are not continuous. This means that we can only replicate the output images to input images. But we cannot generate new images from the latent space vector. This is where variational autoencoders work much better than standard autoencoders.
Variational Autoencoders
The concept of variational autoencoders was introduced by Diederik P Kingma and Max Welling in their paper Auto-Encoding Variational Bayes.
Variational autoencoders or VAEs are really good at generating new images from the latent vector. Although, they also reconstruct images similar to the data they are trained on, but they can generate many variations of the images.
Moreover, the latent vector space of variational autoencoders is continous which helps them in generating new images.
In architecture, VAEs resemble a standard autoencoder. VAEs also consist of an encoder and a decoder. The major difference – the latent vector generated by VAEs is continuous which makes them a part of the generative neural network model family.
Types of Variational Autoencoders
VAEs also allow us to control or condition the outputs of the decoder to some extent. This conditioning of the decoder’s actions leads to the concept of Conditional Variational Autoencoders (CVAEs).
We can also have variational autoencoders that learn from latent vectors which have more disentanglement. As such, disentanglement can lead to learning a broader set of features from the input data to the latent vectors. This, we can control through a parameter called beta (\(\beta\)). Such VAEs are called \(\beta\)-VAEs.
However, in this tutorial, we will take a look at the simple VAE only. We will tackle other types of VAEs in future articles.
The Working of Variational Autoencoders
In this section we will go over the working of variational autoencoders. This section is going to be a bit technical. Our main focus is on the implementation of VAEs using coding. So, we will try to keep this section as short as possible.
I will highly recommend that you go through the original paper to get the most details about the mathematics behind VAEs.
The Problem
In the case of an autoencoder, we have \(z\) as the latent vector. We sample \(p_{\theta}(z)\) from \(z\). Then we sample the reconstruction given \(z\) as \(p_{\theta}(x|z)\). Here \(\theta\) are the learned parameters.
We want to maximize the log-likelihood of the data. The marginal likelihood is composed of a sum over the marginal likelihoods of individual datapoints. That is,
$$
logp_\theta(x^{(1)}, …, x^{(N)}) = \sum_{i=1}^{N}logp_\theta(x^{(i)})
$$
We can write this as:
$$
logp_\theta(x^{(i)}) = D_{KL}(q_{\phi}(z|x^{(i)}) || p_{\theta}(z|x^{(i)})) + \mathcal{L}(\theta, \phi;x^{(i)})
$$
In RHS, first, we have a KL divergence. This is the KL divergence between the approximated latent vector and the try latent vector of the encoder. Here, \(\phi\) are the approximated learned parameters. The second term is the variational lower bound.
The Variational Lower Bound
The variational lower bound is an important term. We can again write it as:
$$
\mathcal{L}(\theta, \phi;x^{(i)}) = -D_{KL}(q_{\phi}(z|x^{(i)}) || p_{\theta}(z)) + \mathbb{E}_{z{\tilde{}}q}[logp_{\theta}(x|z)]
$$
We need to maximize the variational lower bound by optimizing the parameters \(\phi\) and \(\theta\) of the neural network.
In simple words, on the RHS:
- We need to minimize the divergence between the estimated latent vector and the true latent vector.
- And we need to maximize the expectation of the reconstruction of data points from the latent vector.
Do not panic if the above formulae and concepts do not make much sense. You may have to go over the equations and the paper a few times to understand these. But it will be most helpful if you have a good grasp over the simple autoencoder concepts and the latent vector generation. Also, a bit of KL-Divergence knowledge will help. I highly recommend that you go through this article to get a better grasp of KL-Divergence.
There is just a bit more theory before we can move into the coding part. In fact, the last part of theory is one of the basic building blocks of implementation. It will also make the most sense in terms of understandability.
The Optimization Procedure
We need to maximize the \(\mathbb{E}{z{\tilde{}}q}[logp{\theta}(x|z)]\). Maximizing this means that the decoder is getting better at reconstruction. This means that we need to minimize reconstruction loss, which is \(\mathcal{L}_R\). This loss can be the Binary Cross-Entropy Loss (BCELoss).
Now, coming to minimizing \(D_{KL}(q_{\phi}(z|x^{(i)}) || p_{\theta}(z))\). This means, we need to maximize \(-D_{KL}(q_{\phi}(z|x^{(i)}) || p_{\theta}(z))\).
Rewriting it as:
$$
D_{KL}(q_{\phi}(z|x^{(i)}) || p_{\theta}(z)) = \frac{1}{2}\sum_{j=1}^{J}{(1+log(\sigma_j)^2-(\mu_j)^2-(\sigma_j)^2)}
$$
Here, \(\sigma_j\) is the standard deviation and \(\mu_j\) is the mean. For maximizing \(-D_{KL}\), we need \(\sigma_j\rightarrow1\) and \(\mu_j\rightarrow1\). Let’s call this loss as \(\mathcal{L}_{KL}\). And we sample \(\sigma\) and \(\mu\) from the encoder’s ouput.
So, the final VAE loss that we need to optimize is:
$$
\mathcal{L}_{VAE} = \mathcal{L}_R + \mathcal{L}_{KL}
$$
Finally, we need to sample from the input space using the following formula.
$$
Sample = \mu + \epsilon\sigma
$$
Here, \(\epsilon\sigma\) is element-wise multiplication. And the above formula is called the reparameterization trick in VAE. This perhaps is the most important part of a variational autoencoder. This makes it look like as if the sampling is coming from the input space instead of the latent vector space.
This marks the end of the mathematical details.
All of this will make more sense when we implement these in coding. And I again recommend going through the paper and my previous autoencoder blog posts.
The Directory Structure
We will use a very simple directory structure for this project.
├───input
│ └───data
├───outputs
└───src
│ model.py
│ train.py
The following are the descriptions of the different folders.
inputfolder has adatasubfolder where the MNIST dataset will get downloaded.outputswill contain the image reconstructions while training and validating the variational autoencoder model.- The
srcfolder contains two python scripts. One ismodel.pythat contains the variational autoencoder model architecture. The other one istrain.pythat contains the code to train and validate the VAE on the MNIST dataset.
Implementing a Simple Variational Autoencder using PyTorch
Beginning from this section, we will focus on the coding part of this tutorial. I will be telling which python code will go into which file. We will start with building the VAE model.
Building our Linear VAE Model using PyTorch
The VAE model that we will build will consist of linear layers only. We will call our model LinearVAE(). All the code in this section will go into the model.py file.
Let’s import the following modules first.
import torch import torch.nn as nn import torch.nn.functional as F
The LinearVAE() Module
We will define the LinearVAE() module in a single block of code so as to maintain the continuity. After that we will get into the description part.
The following block of code defines the LinearVAE() model.
features = 16
# define a simple linear VAE
class LinearVAE(nn.Module):
def __init__(self):
super(LinearVAE, self).__init__()
# encoder
self.enc1 = nn.Linear(in_features=784, out_features=512)
self.enc2 = nn.Linear(in_features=512, out_features=features*2)
# decoder
self.dec1 = nn.Linear(in_features=features, out_features=512)
self.dec2 = nn.Linear(in_features=512, out_features=784)
def reparameterize(self, mu, log_var):
"""
:param mu: mean from the encoder's latent space
:param log_var: log variance from the encoder's latent space
"""
std = torch.exp(0.5*log_var) # standard deviation
eps = torch.randn_like(std) # `randn_like` as we need the same size
sample = mu + (eps * std) # sampling as if coming from the input space
return sample
def forward(self, x):
# encoding
x = F.relu(self.enc1(x))
x = self.enc2(x).view(-1, 2, features)
# get `mu` and `log_var`
mu = x[:, 0, :] # the first feature values as mean
log_var = x[:, 1, :] # the other feature values as variance
# get the latent vector through reparameterization
z = self.reparameterize(mu, log_var)
# decoding
x = F.relu(self.dec1(z))
reconstruction = torch.sigmoid(self.dec2(x))
return reconstruction, mu, log_var
I know that this a bit different from a standard PyTorch model that contains only an __init__() and forward() function. But things will become very clear when we get into the description of the above code.
Description of the LinearVAE() Model
The features=16 is used in the output features for the encoder and the input features of the decoder.
First we have the __init__() function starting from line 4.
- We have a total of 4 linear layers here.
- The first two are the encoder layers. The
self.enc1has 784in_features. This corresponds to the total number of pixels for image in the MNIST dataset (28x28x1). Theout_featuresis 512. - Simlarly, we have another encoder layer with 32 output features.
- The deocoder layers go in reverse order as that of the encoder layers. By this, finally we end up with 784 outputs features in
self.dec2.
Then from line 15, we have the reparameterize() function.
- It has two parameters
muandlog_var. muis the mean that is coming from encoder’s latent space encoding.- And
log_varis the log variance that is coming from the encoder’s latent space. - These are the same terms that we use in the
Sampleformula in one of the previous sections. - At line 20, first, we calculate the standard deviation (
std) using thelog_var. - Then at line 21, we calculate epsilon (
eps) that we will use in thesampleformula. We usetorch.rand_like()so that dimensions will be same asstd. - At line 22, we calculate the
sampleusingmu,eps,std. Then we return its value. Take a moment to go through the above equations and steps.
Starting from line 25, we have the forward() function.
- First, lines 27 and 28 pass the input through the VAE’s encoder layers. But note that line 28 does not give us the latent vector.
- Then we get
muandlog_varat lines 31 and 32. These two have the same value as the encoder’s last layer output. - At line 35, we get the latent vector
zthrough the reparameterization trick usingmuandlog_var. - From line 38 we have the decoding part. We pass the latent vector
zthrough the first decoder layer. Then we get thereconstructionof the inputs by giving that output as input to the second decoder layer. - Finally, at line 40 we return the
reconstruction,mu, andlog_varvalues.
This ends the model building part of our VAE implementation. Next, we will move into writing the training code.
Writing the Training Code for the VAE Implementation
In this section, we will write the code to train and validate the VAE model. The code in this section will go into the train.py file.
We will start with importing all the modules and libraries that we will need.
import torch
import torchvision
import torch.optim as optim
import argparse
import matplotlib
import torch.nn as nn
import matplotlib.pyplot as plt
import torchvision.transforms as transforms
import model
from tqdm import tqdm
from torchvision import datasets
from torch.utils.data import DataLoader
from torchvision.utils import save_image
matplotlib.style.use('ggplot')
- At line 9, we are importing
modelwhich contains ourLinearVAE()model. - Also, we are importing the
save_imagefunction fromtorchvisionso that we able to save batches of images directly.
Construct the Argument Parser and Define the Learning Parameters
Now, we will define the argument parser to parse the command line arguments. We will provide the number of epochs to train for as the argument while executing the file from the command line. The following block of code constructs the argument parser.
# construct the argument parser and parser the arguments
parser = argparse.ArgumentParser()
parser.add_argument('-e', '--epochs', default=10, type=int,
help='number of epochs to train the VAE for')
args = vars(parser.parse_args())
Next, we will define the learning parameters for training our model.
# leanring parameters
epochs = args['epochs']
batch_size = 64
lr = 0.0001
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
- At line 2, we get the number of epochs from the argument parser.
- Then we define a batch size of 64 at line 3.
- We will use a learning rate of 0.0001.
- Finally, at line 5, we define the computation device, which is either the CPU or the GPU.
Preparing the MNIST Dataset
We will start with defining the transforms. For the transforms, we will only convert the data into torch tensors. We will not augment or rotate the data in any way. Either rotating or horizontally flipping the digit images can compromise the orientation information of the data.
# transforms
transform = transforms.Compose([
transforms.ToTensor(),
])
Now, we will get the test data and validation data using the datasets module from torchvision. If the data is not already present, then it will be downloaded to the respective folder.
# train and validation data
train_data = datasets.MNIST(
root='../input/data',
train=True,
download=True,
transform=transform
)
val_data = datasets.MNIST(
root='../input/data',
train=False,
download=True,
transform=transform
)
After this, we have to define the train and validation data loaders. We can easily do that using the DataLoader module from PyTorch.
# training and validation data loaders
train_loader = DataLoader(
train_data,
batch_size=batch_size,
shuffle=True
)
val_loader = DataLoader(
val_data,
batch_size=batch_size,
shuffle=False
)
This is all the data preparation that we need.
Initializing the Model, the Optimizer, and the Loss Function
We will start initialing the model and loading it onto the computation device. Then we will define the optimizer and the loss function.
model = model.LinearVAE().to(device) optimizer = optim.Adam(model.parameters(), lr=lr) criterion = nn.BCELoss(reduction='sum')
We are using the Adam optimizer for training. The loss function here is the Binary Cross Entropy loss. We will use it to calculate the reconstruction loss. Basically, it will calculate the loss between the actual input data points and the reconstructed data points. This is only part of the total loss. We will also have to calculate the KL divergence as well.
Note that we are using reduction='sum' for the BCELoss(). If you read the PyTorch documentations, then this is specifically for the case of autoencoders only.
The Final Loss Function
Here, we will write the function to calculate the total loss while training the autoencoder model. Remember that it is going to be the addition of the KL Divergence loss and the reconstruction loss.
def final_loss(bce_loss, mu, logvar):
"""
This function will add the reconstruction loss (BCELoss) and the
KL-Divergence.
KL-Divergence = 0.5 * sum(1 + log(sigma^2) - mu^2 - sigma^2)
:param bce_loss: recontruction loss
:param mu: the mean from the latent vector
:param logvar: log variance from the latent vector
"""
BCE = bce_loss
KLD = -0.5 * torch.sum(1 + logvar - mu.pow(2) - logvar.exp())
return BCE + KLD
final_loss() function has three parameters. The bce_loss is the Binary Cross Entropy reconstruction loss. The mu and log_var are the values that we get from the autoencoder model.
- First, we initialize the Binary Cross Entropy loss at line 11.
- At line 12, we calculate the KL divergence using the
muandlog_varvalues. - Finally, we return the total loss at line 14.
The Training Function
We will define the training function here. We will call it as fit().
def fit(model, dataloader):
model.train()
running_loss = 0.0
for i, data in tqdm(enumerate(dataloader), total=int(len(train_data)/dataloader.batch_size)):
data, _ = data
data = data.to(device)
data = data.view(data.size(0), -1)
optimizer.zero_grad()
reconstruction, mu, logvar = model(data)
bce_loss = criterion(reconstruction, data)
loss = final_loss(bce_loss, mu, logvar)
running_loss += loss.item()
loss.backward()
optimizer.step()
train_loss = running_loss/len(dataloader.dataset)
return train_loss
The fit() function accepts two parameters, the model and the train_loader as dataloader. At line 2, first, we get into training mode.
- At line 3, we initialize
running_lossto keep track of the batch-wise loss values. - Line 7, flattens the input data as we are going to feed it into a linear layer.
- At line 9, we get the
reconstruction,mu, andlog_var. - Line 10 calculates the reconstruction loss using the reconstructed data and the original input data.
- At line 11, we calculate the total loss using the
total_lossfunction. - We calculate the batch loss at line 12. Then we backpropagate the gradients and update the parameters at lines 13 and 14 respectively.
- Finally, we calculate the total loss for the epoch (
train_loss) and return its value.
The Validation Function
The validation function will be very similar to the training function with a few minor changes. We will call the function as validate().
def validate(model, dataloader):
model.eval()
running_loss = 0.0
with torch.no_grad():
for i, data in tqdm(enumerate(dataloader), total=int(len(val_data)/dataloader.batch_size)):
data, _ = data
data = data.to(device)
data = data.view(data.size(0), -1)
reconstruction, mu, logvar = model(data)
bce_loss = criterion(reconstruction, data)
loss = final_loss(bce_loss, mu, logvar)
running_loss += loss.item()
# save the last batch input and output of every epoch
if i == int(len(val_data)/dataloader.batch_size) - 1:
num_rows = 8
both = torch.cat((data.view(batch_size, 1, 28, 28)[:8],
reconstruction.view(batch_size, 1, 28, 28)[:8]))
save_image(both.cpu(), f"../outputs/output{epoch}.png", nrow=num_rows)
val_loss = running_loss/len(dataloader.dataset)
return val_loss
First, we get the model into evaluation mode using model.eval(). And everything takes place within the with torch.no_grad() block as we do not need the gradients during validation.
- Just like the training function, we calculate the losses at lines 11 and 12.
- At line 15, we check if we are at the last batch of every epoch. If we are at the last batch, then we concatenate the first eight images of the input data and the first eight images of the reconstructed data. Then we save the image batch using the
save_imagefunction. This will help us easily compare the real data to the reconstructed data. - Then at line 21, we calculate the total validation loss and return the value.
Executing the fit() and validate() Functions
This is the last part of this training script. We need to train and validate our VAE model for the specified number of epochs.
train_loss = []
val_loss = []
for epoch in range(epochs):
print(f"Epoch {epoch+1} of {epochs}")
train_epoch_loss = fit(model, train_loader)
val_epoch_loss = validate(model, val_loader)
train_loss.append(train_epoch_loss)
val_loss.append(val_epoch_loss)
print(f"Train Loss: {train_epoch_loss:.4f}")
print(f"Val Loss: {val_epoch_loss:.4f}")
- We will use the
train_lossandval_loss(lines 1 and 2) lists to store the train and validation losses respectively. - Then we use a
forloop to train the model for the number of epochs as specified in the command line argument.
This all that we need for the training script. Next, we will execute the code and analyze the outputs.
Executing the train.py Script
We have all the code ready to train our VAE on the MNIST dataset. Now, we just need to execute the train.py script.
You will need to open up the terminal and head over to the src folder in the terminal. From there you can execute the train.py script for 20 epochs.
python train.py --epochs 20
Your training will take less time if you run it on a GPU. The following is the truncated output from the command line.
Epoch 1 of 20 938it [00:12, 72.58it/s] 157it [00:01, 103.02it/s] Train Loss: 213.8055 Val Loss: 163.1456 Epoch 2 of 20 938it [00:12, 73.58it/s] 157it [00:01, 103.98it/s] Train Loss: 151.8054 Val Loss: 139.9007 ... Epoch 19 of 20 938it [00:12, 73.90it/s] 157it [00:01, 98.42it/s] Train Loss: 109.0154 Val Loss: 108.3255 Epoch 20 of 20 938it [00:12, 73.25it/s] 157it [00:01, 97.43it/s] Train Loss: 108.7223 Val Loss: 107.8552
After each validation epoch, we are saving the original input data and the reconstructed images to the disk. We will analyze those in the next section.
Analyzing the Image Reconstructions
Let’s start with very first output. That is, the output from the first validation epoch.

The reconstructions from the first epoch are a bit blurry. Moreover, the VAE model has reconstructed the digit 8 as 9 in all cases. And it has reconstructed the digit 4 as 0. This is expected as VAE tries to reconstruct the original images from a continuous vector space. So, most probably it will generate an image closer to something else when it is not very sure.
Now, let’s see the reconstructions after 10 epochs.
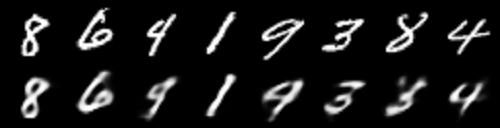
In figure 4, we can see that the reconstructions are much better and clearer. But still, the digit 4 (third from the left) is being reconstructed as a 9. And the digit 9 (fifth from the left) is being reconstructed as a 0.
Let’s hope that the outputs are even better in the last epoch (epoch 20).
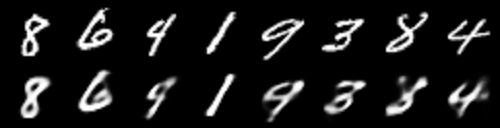
All the images except the 3 (third from right) are properly reconstructed. This digit 3 is being reconstructed as an eight. It is very clear that training for more epochs will yield even better results.
Summary and Conclusion
In this tutorial, you learned about the concept of variational autoencoders in deep learning. You also had hands-on experience and implemented a simple linear variational autoencoder model to reconstruct the digit MNIST images. I hope that you learned a lot from this tutorial.
If you have any thoughts, suggestions, or doubts, then please leave them in the comment section. I will surely address them.
You can contact me using the Contact section. You can also find me on LinkedIn, and Twitter.

Why are mu and logvar assigned the same value (the encoder’s last layer output)? This doesn’t make much sense to me.
Hello Luis, mu and log_var both are sampled from the encoder’s latent space output. The difference is in terms of calculation of std and sample. Now, coming to the question, why assign them different names, when a single name can satisfy? Actually, I myself tried to find the answer and read a lot of books to find out. But when it came down to the coding part, both were always sampled from the same latent space. It seems that it comes down to design choice and for easy understanding when calculating std, eps, and sample.
If you have any better answers, then please post in the comment section. If I find the answer, then I will surely update this post.
I think we can model the mu and var with two more nets. Specifically, first, we use a neural network f to map the input x to its latent correspondent z, then we design two independent nets g and h, and let mu = g(z) and var = h(z). The input and output size of g and h should be identical. This will allow more flexibility in the model.
A modified forward function:
def forward(self, x):
x = self.encoder(x)
mu = self.encode_to_mu(x)
log_var = self.encode_to_var(x)
z = self.reparameterize(mu, log_var)
x_hat = self.decoder(z)
return x_hat, mu, log_var
where self.encoder, self.encode_to_mu, self.encode_to_var and self.decoder are four neural networks.
Hello Jack, that sounds like an interesting approach. I have not tried such an approach till now. Will surely try it out. By the way, do you have any public colab notebooks or GitHub repo with the implementation? Giving the link here will help more readers to try out the approach easily.
Thank you yet again for such crisp insights. However in short..why at all to use VAE? What is the purpose of such a concept? Only reconstruction?
Without MNSIT datasets..can we apply it to say Images…with a practical example..? Sorry i had so many queries. Thank you again for educating us.
Thank you for your positive feedback.
First of all, using VAEs we can condition and control the outputs. As discussed in the tutorial, there is a class of VAE called Conditional VAE using which we can produce outputs with some conditioning. This we cannot do with standard autoencoders. I will be writing a detailed post on Conditional VAEs as well.
Coming to the second question, why MNIST? Because I wanted to start with something simple to introduce the mathematical concepts of VAEs. And yes, we can use VAEs on other image datasets. In fact, the next blog post is going to be about face image generation using VAEs. Although very simple and greyscale images, the face image dataset will introduce a fresh insight into using VAEs for real-life datasets.
And don’t worry, I will be posting many more articles on Generative models using Neural Networks. A lot more of different autoencoders and GANs as well.
Stay tuned.
Thank you sir for the absolutely wonderful insights. Thank you once again. I seriously wait for your tutorials. Just a small suggestion, in case if your programs are in colab..it will do immense help. Also try using weights and biases..logging info and displaying the results.
In case you see downloading datasets from PyTorch `datasets` module in any of the posts, you can easily use Colab. I will try to make a post for effectively using Colab for deep learning with .py scripts. But this may take some time as I already have some other posts lined up.
Again, thank you for the feedback.
Hello Sovit,
This article helps me build a concrete understanding of the VAE. Thank you!
Usually we distinguish a discriminative model from a generative model by whether they learn a conditional probability p(y|x) directly or first learn the joint probability p(x, y) and then resort to the Bayesian rule to derive p(y|x). Moreover this is usually discussed in the context of classification problems.
In the VAE neural network, we can sample from the latent space p(z), passing through the decoder, to get the output p(x|z). How would you interpret the “generative” term in both cases? Are they the same in both contexts?
Hello Guangye, I am happy that you found the article helpful.
Your intuition about VAE is perfectly right. We can generate the data given the latent space p(z) and can improve with each iteration while backpropagating the loss on those generated images.
But when we talk about “generator” and “discriminator”, then we mainly mean the concept of the GANs. And if you want to know about “generative-discriminative” modeling in detail, then you can check out these GAN posts of mine. They are quite detailed and will help you a lot. If you still, face doubts, then you can ask them in the comment section. I will happily answer them.
1. https://debuggercafe.com/introduction-to-generative-adversarial-networks-gans/
2. https://debuggercafe.com/generating-mnist-digit-images-using-vanilla-gan-with-pytorch/
3. https://debuggercafe.com/implementing-deep-convolutional-gan-with-pytorch/
Thank you Sovit, I will go through your blogs you listed.
Your implementation of VAE has a bug, you need two different Linears for each one and you shouldn’t use a non-linearity on top of them
I mean for each on of mu, logvar.
Hello Stathi. Thanks for reaching out. By a bug do you mean that it is showing any error or bug as in coding concept?
Hello Stathi. I have updated the code now for mu and logvar. I did not notice at first but now it is clear what you are saying. Thanks again for pointing this out.
Hello,
Great job on putting this article up! Really appreciate it. One doubt I have been having is on Line number 31 and 32 in LinearVAE class. What exactly is happening in the slicing operation.
mu = x[:, 0, :] # the first feature values as mean
log_var = x[:, 1, :] # the other feature values as variance
I am failing to follow the shapes of the vectors and how you are able to establish that the first feature to be the mean and the next to be variance. Really appreciate your reply.
Hello SidMaram, so your doubt is why I have taken the first dimension as mean and the second dimension as variance? Actually, in VAEs that’s how we consider the positions of the mean and variance to be. I know that at first, it can get a bit confusing. We extract both, mean and variance from the autoencoder’s latent space. This part is a bit theoretical and you may have to go into a bit in-depth. It would be best if you can give a read at the original VAE paper. I am providing the link here => https://arxiv.org/pdf/1312.6114.pdf
I hope this helps.
Awesome! I loved it. Really well explained. Thanks for that!
Some nitpicking. You wrote:
“Here, 𝜎𝑗 is the standard deviation and 𝜇𝑗 is the mean. For maximizing −𝐷𝐾𝐿, we need 𝜎𝑗→1 and 𝜇𝑗→1”
You meant that in order to maximize the -KL we need a mean of 0, right? 🙂
Hello Mahuani. Yes, we need the mean to be close to 0.
Thank you so much for your article, it helps a lot.
I have one question that I can’t really find an answer to it. What is your motivation to choose the Binary Cross-Entropy Loss as the reconstruction loss ? How one can choose a reconstruction loss ( MAE ou MSE for example) and be sure that it would be suitable for training the model ( the loss terms won’t be too big compared to the KL Div Loss or too small to have some balance between the two terms composing our overall loss function) ? Thank you
Hello Reda. Yours is actually a good question. We are using BCE over MSE here. See, we do not need the predicted and real values to exactly match or the loss to be exactly zero. Our main aim is to minimize the loss over time and as long as we are getting our predicted and real values almost the same then we are all okay. Another reason, frankly, is this is what I have read in most papers, books, and have seen experts like Yann Lecun use in the field as well. Coming to whether we can use MSE or not, it is no harm in trying to use MSE but in that case, the predicted and real pixel values will have to be really close or the same to each other to get good results. You can try and analyze though. I hope this helps.
I would like to contribute my answer,
Minimizing MSE is equalent to minimizing BCE ( Maximizing Likelihood).
I shall may use BCE preferably when having multi nominal distributions in latent space other MSE may work just fine
Thank you for the information, Ali.
I am not an expert but I suggest to reduce the latent space dimensions in order to generate the sample from prior normal noise/distribution.
In terms if you want to use it as generator.
The latent space you are using may result in distinct the data points in its latent space
Hi Ali. Thank you for your suggestions. I am very open to improving my autoencoder posts. They can be tricky to tackle sometimes and I will listen happily to any improvements that I can make. May I ask what latent space dimension you are suggesting?
I opted for 4 to 8 for MNIST and It resulted in fine generated samples from random noise (Prior) as input to te decoder.
Thanks for your reply. Will surely try that out as well.
Can I save the model after training
Yes you can Amit. You can use this command => torch.save(model.state_dict(), PATH)
can you please tell how and why did you took “logvar” instead of variance or std dev.And can you tell how exactly does we bring out mean and logvar(like why did we took the two parts as mean and variance
Hi. We are actually calculating the std dev using `logvar`. You will find it at line 20 of the model code block. As far as taking two parts are concerned, from the latent space encoding of the encoder, we calculate the mean `mu` from the first part and the `logvar` from the second part. And using these two, we get the latent vector `z`. I hope this answers your question.
But, log var means log sigma^2 but std dev means sigma right?….And another small doubt is like…how exactly the half part of matrix becomes mean and half as standard dev
std dev is the square root of the variance. So, to get std, we are doing torch.exp(0.5*log_var). And to answer your second question, that is, “how exactly the half part of matrix becomes mean and half as standard dev”, honestly, I will have to read up on that again a bit. I don’t want to give a wrong answer. In the mean time, may I provide you with this resource => https://atcold.github.io/pytorch-Deep-Learning/en/week08/08-3/
This material and the course is by Yann LeCun & Alfredo Canziani, so, it is pretty reliable. I also learned a lot from here. Good luck. Please get back if you have further queries.
Hi,
I found your tutorial very interesting. However, are you sure we need to import model? My system is unable to import model. pip is unable to find it.
Hello Paramita. Thank you for the appreciation.
The model.py is in the same directory as the train.py file. It is not a pip installable module. In this post, first, we write the model code in model.py and import that in train.py.
I hope this helps.
Hello, Sovit
Thank you for this great article. However, I have two questions:
1) why do we multiply by 0.5 in ‘reparametrize’ and ‘final_loss’?
2) during training I encounter my loss going below 0 and it becomes more and more negative each epoch (however, the model still trains and I get better results each epoch). Did you face the same problem?
Hello Ilya.
1. The 0.5 indicates 1/2 that we have in the KL divergence formula.
2. And for the negative loss, that you are getting, I am not sure of it right now. I did not face such an issue. However, it might be because of some changes in the PyTorch version. In that case, I will have to recheck the code with the latest version. And I will post an update here if any changes are made.
I hope this helps.
Hi,
In line 20 of the VAE class, std = torch.exp(0.5*log_var) should be changed to std = 0.5*torch.exp(log_var). As standard deviation is the square root of variance.
Hi Reza. Actually, to get square it should have been torch.exp(log_var*0.5) which is the same as log_var^(1/2). Thanks for bringing it up. It seems, right now, my implementation is still wrong but the correct answer is std = torch.exp(log_var*0.5)
Hi,
There is a mistake in the formula for the KLD Loss: the term with the log(var) ** 2 should have the power two inside the log: log(var ** 2). Code looks correct.
Hello Nicolas. Thanks for pointing it out. Will check it out.
Hi, I have a question of this model. Can we train the encoder and decoder respecitvely? What I mean is that can I first train the encoder with the KL loss function to output latent vectors, then train the decoder with BCE with the latent vectors? Many thanks for your reply!
Hello Hengjia. You can surely try that. But I am not sure how that will work out. But yes, trying it out will give more insights. All the best.
Hi, thank you for this post.
I had a question regarding your loss function, where you add the reconstruction loss with the negative KL divergence loss. Don’t you think the formula for the negative KL divergence should actually be the opposite? Same thing for every time you write the KL divergence through the article. I am saying that because it seems like this is what the original VAE article says: https://arxiv.org/pdf/1312.6114.pdf (see Part 3: Variational Auto-Encoder).
Thanks in advance for your feedback
I think you’re actually right, and that the original paper shows a gain function rather than a loss function, hence the opposite sign
Cheers