

In this article, we will build the FasterViT Detection model. The primary aim is to create a single stage object detection model from a Vision Transformer backbone. We will use the pretrained FasterViT backbone from NVIDIA, add an SSD head from Torchvision, and train the model on the Pascal VOC object detection dataset.

Primarily, the article covers the following topics
- A brief background on Vision Transformer object detection models.
- Modifications that we need to make to the FasterViT backbone to create a Transformer based object detection model.
- Data loading and augmentation pipeline.
- Training the FasterViT Detection model, running evaluation, and inference on unseen data.
Background on Vision Transformer Based Object Detection Models
Since the advent of Vision Transformer models, we have seen their applications in several tasks. Image classification, semantic segmentation, object detection, and many industrial applications as well. Often, libraries like MMDetection and Detectron2 provide Transformer based object detection models.
Detectron2 has the famous ViTDet model and MMDetection has Transformer based detection models as well. But most of these are based on MaskRCNN heads (instance segmentation) and are not real time on commodity hardware.
Although libraries like Ultralytics have RTDETR integration, it is not easy to explore the codebase.
What if we want to create a real-time object detection model with a Single Stage Object Detection head? That’s where pretrained Vision Transformer backbones and Torchvision detection utilities come into the picture.
We will modify the pretrained FasterViT backbone along with the Torchvision SSD head to create a real-time Vision Transformer object detection model.
The codebase will be easy to explore and modify. Although we are not building everything from scratch, being able to see and work with creating such an object detection model, training, and evaluation will lead to a lot of learning.
It is worthwhile to note that although we get decent results, they are not state-of-the-art. We will primarily aim to create a Vision Transformer object detection model partially from scratch and work with the code.
Before moving further, I highly recommend reviewing the FasterViT image classification article. In the article, we cover the FasterViT model from NVIDIA, its variants, the results, and carry out image classification.
The Pascal VOC Object Detection Dataset
We will train the FasterViT detection model on the Pascal VOC dataset. The dataset contains 16551 images for training and 4952 images for validation across 20 object classes.
[ 'background', "aeroplane", "bicycle", "bird", "boat", "bottle", "bus", "car", "cat", "chair", "cow", "diningtable", "dog", "horse", "motorbike", "person", "pottedplant", "sheep", "sofa", "train", "tvmonitor" ]
You can download the dataset from Kaggle. After extracting, you will find the following directory structure.
voc_07_12/
└── final_xml_dataset
├── train
│ ├── images [16551 entries exceeds filelimit, not opening dir]
│ └── labels [16551 entries exceeds filelimit, not opening dir]
├── valid
│ ├── images [4952 entries exceeds filelimit, not opening dir]
│ └── labels [4952 entries exceeds filelimit, not opening dir]
└── README.txt
We have a train and a valid directory with respective subdirectories for images and labels in XML format.
Here are some samples from the dataset.

Project Directory Structure
Let’s take a look at the entire project’s directory structure.
├── data │ ├── inference_data │ └── voc_07_12 ├── inference_outputs │ ├── images │ └── videos ├── outputs │ ├── best_model.pth │ ├── last_model.pth │ ├── map.png │ └── train_loss.png ├── weights │ └── faster_vit_0.pth.tar ├── config.py ├── custom_utils.py ├── datasets.py ├── eval.py ├── inference.py ├── inference_video.py ├── model.py ├── README.md ├── requirements.txt └── train.py
- The
datadirectory contains the Pascal VOC dataset that we downloaded earlier and also inference data. - The
inference_outputsdirectory contains the results from carrying out inference after training the model. - In the
outputsdirectory, we have the trained model weights and the plots for Mean Average Precision and loss. - The
weightsdirectory contains the ImageNet pretrained weights from FasterViT-0 that we downloaded from the official repository. - The parent project directory contains all the code files, along with a README, and requirements file.
The download section allows you to download the Python code files, FasterViT-0 pretrained weights, inference, data, and the best weights for Pascal VOC training. In case you follow along with the training, please download the Pascal VOC and arrange it in the directory structure as shown above.
Download Code
Installing Dependencies
We are using PyTorch as the deep learning framework here. You can install all the requirements using the requirements.txt file.
pip install -r requirements.txt
Although it installs PyTorch 2.1.2 and Torchvision 0.16.2, if you choose to work with the latest versions, it should work.
Faster ViT Detection for Custom Transformer Based Object Detection Model
We will explore some of the important components of the codebase here. We will start with the most crucial component, the FasterViT detection model.
FasterViT Detection Model
Here, we will explore the changes and additions that we need to make to the base FasterViT-0 model to make it object detection compatible.
In one of our previous articles, we created a FasterViT semantic segmentation model. Further, we have also explored training the FasterViT on Pascal VOC segmentation dataset. I am sure that both of these previous articles will help get a better understanding of the backbone.
The code for the detection model resides in the model.py file. It is almost entirely borrowed from the official repository so that we can make any changes that we want. The file is more than 1000 lines of code, so, we will cover the most important components only.
We start with some minor changes to the __init__ method of the FasterViT class.
class FasterViT(nn.Module):
"""
FasterViT based on: "Hatamizadeh et al.,
FasterViT: Fast Vision Transformers with Hierarchical Attention
"""
def __init__(self,
dim,
in_dim,
depths,
window_size,
ct_size,
mlp_ratio,
num_heads,
resolution=[224, 224],
drop_path_rate=0.2,
in_chans=3,
num_classes=1000,
qkv_bias=True,
qk_scale=None,
drop_rate=0.,
attn_drop_rate=0.,
layer_scale=None,
layer_scale_conv=None,
layer_norm_last=False,
hat=[False, False, True, False],
do_propagation=False,
**kwargs):
"""
Args:
dim: feature size dimension.
in_dim: inner-plane feature size dimension.
depths: layer depth.
window_size: window size.
ct_size: spatial dimension of carrier token local window.
mlp_ratio: MLP ratio.
num_heads: number of attention head.
resolution: image resolution.
drop_path_rate: drop path rate.
in_chans: input channel dimension.
num_classes: number of classes.
qkv_bias: bool argument for query, key, value learnable bias.
qk_scale: bool argument to scaling query, key.
drop_rate: dropout rate.
attn_drop_rate: attention dropout rate.
layer_scale: layer scale coefficient.
layer_scale_conv: conv layer scale coefficient.
layer_norm_last: last stage layer norm flag.
hat: hierarchical attention flag.
do_propagation: enable carrier token propagation.
"""
super().__init__()
if type(resolution)!=tuple and type(resolution)!=list:
resolution = [resolution, resolution]
num_features = int(dim * 2 ** (len(depths) - 1))
self.num_classes = num_classes
self.patch_embed = PatchEmbed(in_chans=in_chans, in_dim=in_dim, dim=dim)
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))]
self.levels = nn.ModuleList()
if hat is None: hat = [True, ]*len(depths)
for i in range(len(depths)):
conv = True if (i == 0 or i == 1) else False
level = FasterViTLayer(dim=int(dim * 2 ** i),
depth=depths[i],
num_heads=num_heads[i],
window_size=window_size[i],
ct_size=ct_size,
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias,
qk_scale=qk_scale,
conv=conv,
drop=drop_rate,
attn_drop=attn_drop_rate,
drop_path=dpr[sum(depths[:i]):sum(depths[:i + 1])],
downsample=(i < 3),
layer_scale=layer_scale,
layer_scale_conv=layer_scale_conv,
input_resolution=[int(2 ** (-2 - i) * resolution[0]),
int(2 ** (-2 - i) * resolution[1])],
only_local=not hat[i],
do_propagation=do_propagation)
self.levels.append(level)
self.norm = LayerNorm2d(num_features) if layer_norm_last else nn.BatchNorm2d(num_features)
self.avgpool = nn.AdaptiveAvgPool2d(1)
self.head = nn.Linear(num_features, num_classes) if num_classes > 0 else nn.Identity()
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
elif isinstance(m, LayerNorm2d):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
elif isinstance(m, nn.BatchNorm2d):
nn.init.ones_(m.weight)
nn.init.zeros_(m.bias)
@torch.jit.ignore
def no_weight_decay_keywords(self):
return {'rpb'}
def forward_features(self, x):
x = self.patch_embed(x)
for level in self.levels:
x = level(x)
x = self.norm(x)
# Return both, the final output, and the convolution feature.
return x
def forward_head(self, x):
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.head(x)
return x
def forward(self, x):
# Need only the forwarded features and not from the head part
# that is meant for classification.
x = self.forward_features(x)
# return final_features
return x
def _load_state_dict(self,
pretrained,
strict: bool = False):
_load_checkpoint(self,
pretrained,
strict=strict)
The FasterViT class remains almost the same as the original model. Of course, all the layers that create the FasterViT backbone are defined before this in the file. It is highly recommended to take a thorough look through the code at least once. All in all, initializing the above class provides us with the backbone features.
That brings us to the next custom function.
def faster_vit_0_any_res(pretrained=False, **kwargs):
depths = kwargs.pop("depths", [2, 3, 6, 5])
num_heads = kwargs.pop("num_heads", [2, 4, 8, 16])
window_size = kwargs.pop("window_size", [7, 7, 7, 7])
ct_size = kwargs.pop("ct_size", 2)
dim = kwargs.pop("dim", 64)
in_dim = kwargs.pop("in_dim", 64)
mlp_ratio = kwargs.pop("mlp_ratio", 4)
resolution = kwargs.pop("resolution", [512, 512])
drop_path_rate = kwargs.pop("drop_path_rate", 0.2)
model_path = kwargs.pop("model_path", "weights/faster_vit_0.pth.tar")
hat = kwargs.pop("hat", [False, False, True, False])
num_classes = kwargs.pop('num_classes', 2)
nms = kwargs.pop('nms', 0.45)
pretrained_cfg = resolve_pretrained_cfg('faster_vit_0_any_res').to_dict()
_update_default_model_kwargs(pretrained_cfg, kwargs, kwargs_filter=None)
backbone_model = FasterViT(depths=depths,
num_heads=num_heads,
window_size=window_size,
ct_size=ct_size,
dim=dim,
in_dim=in_dim,
mlp_ratio=mlp_ratio,
resolution=resolution,
drop_path_rate=drop_path_rate,
hat=hat,
**kwargs)
backbone_model.pretrained_cfg = pretrained_cfg
backbone_model.default_cfg = backbone_model.pretrained_cfg
if pretrained:
if not Path(model_path).is_file():
url = backbone_model.default_cfg['url']
torch.hub.download_url_to_file(url=url, dst=model_path)
backbone_model._load_state_dict(model_path)
backbone = nn.Sequential(backbone_model)
out_channels = [512, 512, 512, 512, 512, 512]
anchor_generator = DefaultBoxGenerator(
[[2], [2, 3], [2, 3], [2, 3], [2], [2]],
)
num_anchors = anchor_generator.num_anchors_per_location()
head = SSDHead(out_channels, num_anchors, num_classes=num_classes)
model = SSD(
backbone=backbone,
num_classes=num_classes,
anchor_generator=anchor_generator,
size=resolution,
head=head,
nms_thresh=nms
)
return model
We combine everything in the faster_vit_0_any_res function.
It accepts a pretrained parameter and several keyword parameters. The keyword parameters define the model hyperparameters such as the model depth, number of heads, window size, head dimension, expansion ratio, and model resolution among others.
We build the backbone_model by initializing the FasterViT class to extract the pretrained configuration and load the pretrained state dictionary from the weights directory.
Next, we create a Sequential model from the backbone.
As we are building an SSD model, we need to define the output channels for each of the SSD heads. This is followed by the anchor generator, and initializing SSDHead itself. We use the outputs from the final batch normalization layer of the backbone with 512 dimensional output and feed it to the SSD head.
This completes the process of creating the final model.
Sanity Check for Our FasterViT Detection Model
Let’s create a main block, initialize our model, and do a dummy forward pass through the model.
if __name__ == '__main__':
resolution = [512, 512]
model = faster_vit_0_any_res(
pretrained=True,
num_classes=8,
resolution=resolution,
nms=0.45
)
torchinfo.summary(
model,
device='cpu',
input_size=[1, 3, resolution[0], resolution[1]],
row_settings=["var_names"],
col_names=("input_size", "output_size", "num_params")
)
# Total parameters and trainable parameters.
total_params = sum(p.numel() for p in model.parameters())
print(f"{total_params:,} total parameters.")
total_trainable_params = sum(
p.numel() for p in model.parameters() if p.requires_grad)
print(f"{total_trainable_params:,} training parameters.")
random_input = torch.randn((2, 3, *resolution))
model.eval()
with torch.no_grad():
outputs = model(random_input)
print(outputs[0]['boxes'].shape)
We can execute the model file using:
python model.py
This is the output that we get on the terminal.
size mismatch for levels.2.blocks.0.hat_attn.pos_emb_funct.relative_coords_table: copying a param with shape torch.Size([1, 7, 7, 2]) from checkpoint, the shape in current model is torch.Size([1, 19, 19, 2]). size mismatch for levels.2.blocks.0.hat_attn.pos_emb_funct.relative_position_index: copying a param with shape torch.Size([16, 16]) from checkpoint, the shape in current model is torch.Size([100, 100]). size mismatch for levels.2.blocks.0.hat_attn.pos_emb_funct.relative_bias: copying a param with shape torch.Size([1, 8, 16, 16]) from checkpoint, the shape in current model is torch.Size([1, 8, 100, 100]). size mismatch for levels.2.blocks.0.hat_pos_embed.relative_bias: copying a param with shape torch.Size([1, 16, 256]) from checkpoint, the shape in current model is torch.Size([1, 100, 256]). size mismatch for levels.2.blocks.1.hat_attn.pos_emb_funct.relative_coords_table: copying a param with shape torch.Size([1, 7, 7, 2]) from checkpoint, the shape in current model is torch.Size([1, 19, 19, 2]). size mismatch for levels.2.blocks.1.hat_attn.pos_emb_funct.relative_position_index: copying a param with shape torch.Size([16, 16]) from checkpoint, the shape in current model is torch.Size([100, 100]). size mismatch for levels.2.blocks.1.hat_attn.pos_emb_funct.relative_bias: copying a param with shape torch.Size([1, 8, 16, 16]) from checkpoint, the shape in current model is torch.Size([1, 8, 100, 100]). size mismatch for levels.2.blocks.1.hat_pos_embed.relative_bias: copying a param with shape torch.Size([1, 16, 256]) from checkpoint, the shape in current model is torch.Size([1, 100, 256]). size mismatch for levels.2.blocks.2.hat_attn.pos_emb_funct.relative_coords_table: copying a param with shape torch.Size([1, 7, 7, 2]) from checkpoint, the shape in current model is torch.Size([1, 19, 19, 2]). size mismatch for levels.2.blocks.2.hat_attn.pos_emb_funct.relative_position_index: copying a param with shape torch.Size([16, 16]) from checkpoint, the shape in current model is torch.Size([100, 100]). size mismatch for levels.2.blocks.2.hat_attn.pos_emb_funct.relative_bias: copying a param with shape torch.Size([1, 8, 16, 16]) from checkpoint, the shape in current model is torch.Size([1, 8, 100, 100]). size mismatch for levels.2.blocks.2.hat_pos_embed.relative_bias: copying a param with shape torch.Size([1, 16, 256]) from checkpoint, the shape in current model is torch.Size([1, 100, 256]). size mismatch for levels.2.blocks.3.hat_attn.pos_emb_funct.relative_coords_table: copying a param with shape torch.Size([1, 7, 7, 2]) from checkpoint, the shape in current model is torch.Size([1, 19, 19, 2]). size mismatch for levels.2.blocks.3.hat_attn.pos_emb_funct.relative_position_index: copying a param with shape torch.Size([16, 16]) from checkpoint, the shape in current model is torch.Size([100, 100]). size mismatch for levels.2.blocks.3.hat_attn.pos_emb_funct.relative_bias: copying a param with shape torch.Size([1, 8, 16, 16]) from checkpoint, the shape in current model is torch.Size([1, 8, 100, 100]). size mismatch for levels.2.blocks.3.hat_pos_embed.relative_bias: copying a param with shape torch.Size([1, 16, 256]) from checkpoint, the shape in current model is torch.Size([1, 100, 256]). size mismatch for levels.2.blocks.4.hat_attn.pos_emb_funct.relative_coords_table: copying a param with shape torch.Size([1, 7, 7, 2]) from checkpoint, the shape in current model is torch.Size([1, 19, 19, 2]). size mismatch for levels.2.blocks.4.hat_attn.pos_emb_funct.relative_position_index: copying a param with shape torch.Size([16, 16]) from checkpoint, the shape in current model is torch.Size([100, 100]). size mismatch for levels.2.blocks.4.hat_attn.pos_emb_funct.relative_bias: copying a param with shape torch.Size([1, 8, 16, 16]) from checkpoint, the shape in current model is torch.Size([1, 8, 100, 100]). size mismatch for levels.2.blocks.4.hat_pos_embed.relative_bias: copying a param with shape torch.Size([1, 16, 256]) from checkpoint, the shape in current model is torch.Size([1, 100, 256]). size mismatch for levels.2.blocks.5.hat_attn.pos_emb_funct.relative_coords_table: copying a param with shape torch.Size([1, 7, 7, 2]) from checkpoint, the shape in current model is torch.Size([1, 19, 19, 2]). size mismatch for levels.2.blocks.5.hat_attn.pos_emb_funct.relative_position_index: copying a param with shape torch.Size([16, 16]) from checkpoint, the shape in current model is torch.Size([100, 100]). size mismatch for levels.2.blocks.5.hat_attn.pos_emb_funct.relative_bias: copying a param with shape torch.Size([1, 8, 16, 16]) from checkpoint, the shape in current model is torch.Size([1, 8, 100, 100]). size mismatch for levels.2.blocks.5.hat_pos_embed.relative_bias: copying a param with shape torch.Size([1, 16, 256]) from checkpoint, the shape in current model is torch.Size([1, 100, 256]). ====================================================================================================================================================== Layer (type (var_name)) Input Shape Output Shape Param # ====================================================================================================================================================== SSD (SSD) [1, 3, 512, 512] [200, 4] -- ├─GeneralizedRCNNTransform (transform) [1, 3, 512, 512] [1, 3, 512, 512] -- ├─Sequential (backbone) [1, 3, 512, 512] [1, 512, 16, 16] -- │ └─FasterViT (0) [1, 3, 512, 512] [1, 512, 16, 16] 513,000 │ │ └─PatchEmbed (patch_embed) [1, 3, 512, 512] [1, 64, 128, 128] 38,848 │ │ └─ModuleList (levels) -- -- 30,851,968 │ │ └─BatchNorm2d (norm) [1, 512, 16, 16] [1, 512, 16, 16] 1,024 ├─SSDHead (head) [1, 512, 16, 16] [1, 1024, 21] -- │ └─SSDRegressionHead (regression_head) [1, 512, 16, 16] [1, 1024, 4] -- │ │ └─ModuleList (module_list) -- -- 553,080 │ └─SSDClassificationHead (classification_head) [1, 512, 16, 16] [1, 1024, 21] -- │ │ └─ModuleList (module_list) -- -- 2,903,670 ├─DefaultBoxGenerator (anchor_generator) [1, 3, 512, 512] [1024, 4] -- ====================================================================================================================================================== Total params: 34,861,590 Trainable params: 34,861,590 Non-trainable params: 0 Total mult-adds (G): 17.01 ====================================================================================================================================================== Input size (MB): 3.15 Forward/backward pass size (MB): 543.37 Params size (MB): 125.41 Estimated Total Size (MB): 671.93 ====================================================================================================================================================== 34,861,590 total parameters. 34,861,590 training parameters. torch.Size([200, 4])
The size mismatch for all the embedding layers happens because of the difference in input resolution. The model was pretrained with 224×224 images and our input for the forward pass has 512×512 tensors. However, the pretrained weights for the rest of the matching layers have been loaded.
The final FasterViT detection model contains 34.8 million parameters for 21 classes (similar to Pascal VOC).
The Data Augmentation Pipeline
The data augmentation and image transformation code is present in the custom_utils.py file. As we are pretraining here, we employ several augmentation techniques for the training data using Albumentations. Here are all the training transforms:
def get_train_transform():
return A.Compose([
A.HorizontalFlip(p=0.5),
A.Blur(blur_limit=3, p=0.1),
A.MotionBlur(blur_limit=3, p=0.1),
A.MedianBlur(blur_limit=3, p=0.1),
A.ToGray(p=0.3),
A.RandomBrightnessContrast(p=0.3),
A.ColorJitter(p=0.3),
A.RandomGamma(p=0.3),
ToTensorV2(p=1.0),
], bbox_params={
'format': 'pascal_voc',
'label_fields': ['labels']
})
Training Configuration
We define all the training configurations in the config.py file.
import torch
BATCH_SIZE = 16 # Increase / decrease according to GPU memeory.
RESIZE_TO = 640 # Resize the image for training and transforms.
NUM_EPOCHS = 75 # Number of epochs to train for.
NUM_WORKERS = 8 # Number of parallel workers for data loading.
DEVICE = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
# Training images and XML files directory.
TRAIN_IMG = 'data/voc_07_12/final_xml_dataset/train/images'
TRAIN_ANNOT = 'data/voc_07_12/final_xml_dataset/train/labels'
# Validation images and XML files directory.
VALID_IMG = 'data/voc_07_12/final_xml_dataset/valid/images'
VALID_ANNOT = 'data/voc_07_12/final_xml_dataset/valid/labels'
# Classes: 0 index is reserved for background.
CLASSES = [
'__background__',
"aeroplane", "bicycle", "bird", "boat", "bottle", "bus", "car", "cat",
"chair", "cow", "diningtable", "dog", "horse", "motorbike", "person",
"pottedplant", "sheep", "sofa", "train", "tvmonitor"
]
NUM_CLASSES = len(CLASSES)
# Whether to visualize images after crearing the data loaders.
VISUALIZE_TRANSFORMED_IMAGES = False
# Location to save model and plots.
OUT_DIR = 'outputs'
You can adjust the batch size and number of workers based on the hardware that you are training on.
This brings us to the end of the coding part and we can begin training now.
Training the FasterViT Detection Model
The results for the training run shown here were carried out on a machine with a 10GB virtualized A100 GPU. It took around 9 hours to train for 75 epochs.
We can begin the training by simply executing the following command:
python train.py
Following are the loss and Mean Average Precision metrics graphs after training.
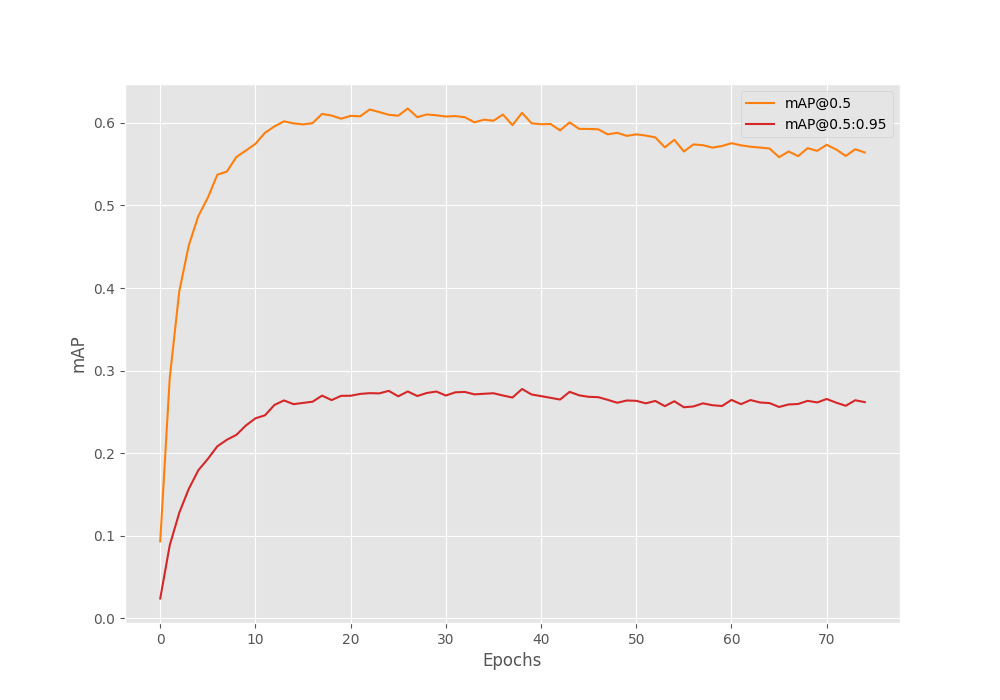
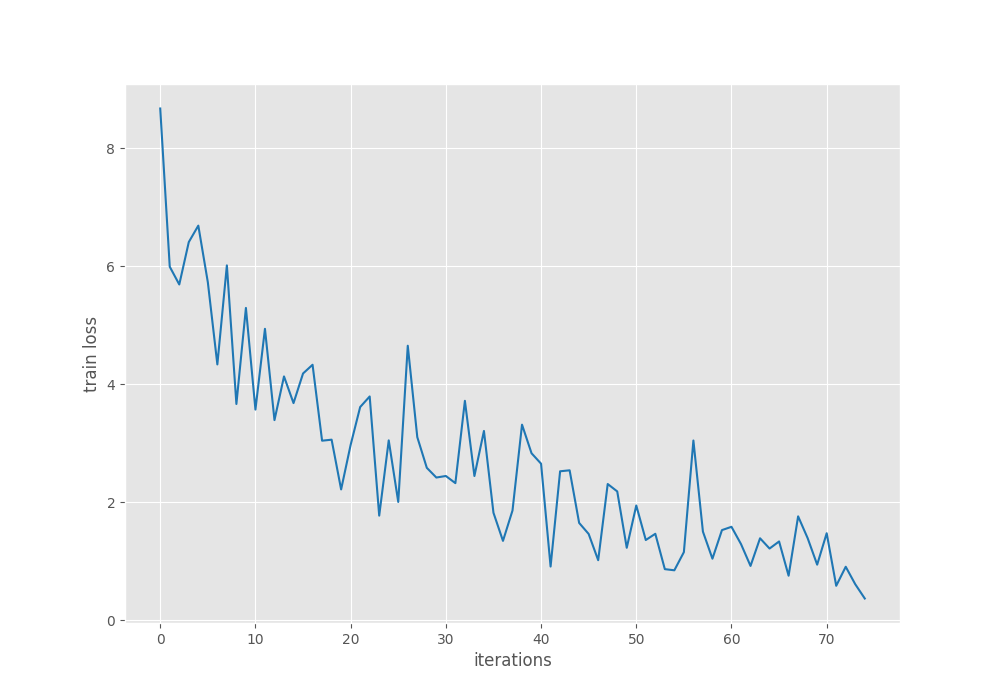
We can clearly see that the mAP starts deteriorating after around 25 epochs. We are already employing a good amount of augmentation techniques. So, in the next phase of training, learning rate scheduler will surely help.
The primary mAP is above 27% in our case. And the mAP at 50% IoU is above 60%.
To get the exact numbers, we can run the evaluation script using the best model weights.
python eval.py
Following are the results.
mAP_50: 61.226 mAP_50_95: 27.771
We achieve a primary mAP of 27.7% using the best model. This is not extremely good but a decent starting point.
Running Inference on Unseen Data
We can use the best model weights to run inference on videos with the inference_video.py script. It accepts an input video, a confidence threshold, and an optional image size.
The following inference experiments were run on a 10GB RTX 3080 GPU.
Let’s start with a simple experiment to detect humans.
python inference_video.py --input data/inference_data/videos/video_3.mp4 --threshold 0.7
Following is the result stored in the inference_outputs directory.
The results are good enough here with a bit of flickering. We are getting an average of 46 FPS.
Now, let’s try on a slightly complex scene.
python inference_video.py --input data/inference_data/videos/video_1.mp4 --threshold 0.7
The results are decent, however, there is a lot of flickering and the model fails to detect faraway objects as well.
Let’s run another experiment on a much more difficult scene.
python inference_video.py --input data/inference_data/videos/video_2.mp4 --threshold 0.5
No doubt the model fails here. The training dataset does not contain such crowded scenes and the lighting is challenging as well.
The above results show that there is room for extreme improvement.
Summary and Conclusion
In this article, we created a custom FasterViT Detection model using the FasterViT-0 backbone. We went through the code for preparing the backbone and attaching an SSD head. The results are decent at most and not compelling enough for a 34 million parameter model. However, we can improve the architecture and training pipeline which we may explore in one of the future articles. I hope this article was worth your time.
If you have any doubts, thoughts, or suggestions, please leave them in the comment section. I will surely address them.
You can contact me using the Contact section. You can also find me on LinkedIn, and X.
References
