

In my previous article, Challenges in Machine Learning Project, I just touched upon the points of overfitting and underfitting. In this post, I am going to give a bit more in-depth view of the two. And if you are interested in Machine Learning, then you will surely enjoy this article about overfitting and underfitting.
Overfitting and underfitting are the two problems that are related to the training data. Although the two are primarily concepts of statistics, I am going to tackle the situation while trying a machine learning perspective.
Overfitting
Starting with a simple example. Consider that you have gone to the supermarket to buy some food. You see a particular variety of apple and bought it. When checking out at the counter you got to know that they are too costly, being of superior quality. On the way back home your mind starts wondering how costly apples have become.
The problem with the above situation is that you generalized the whole ‘Cost of Apple’ scenario with only a single variety of apple, whereas this is not the case. This is called overgeneralizing. And when the same thing happens in machine learning it is called overfitting.
Overfitting is the situation when the learning model performs really well on the training data, capturing almost every feature. But when it comes to generalizing some future data, it does very poorly.
The image below can be considered a simple yet exact example of overfitting.
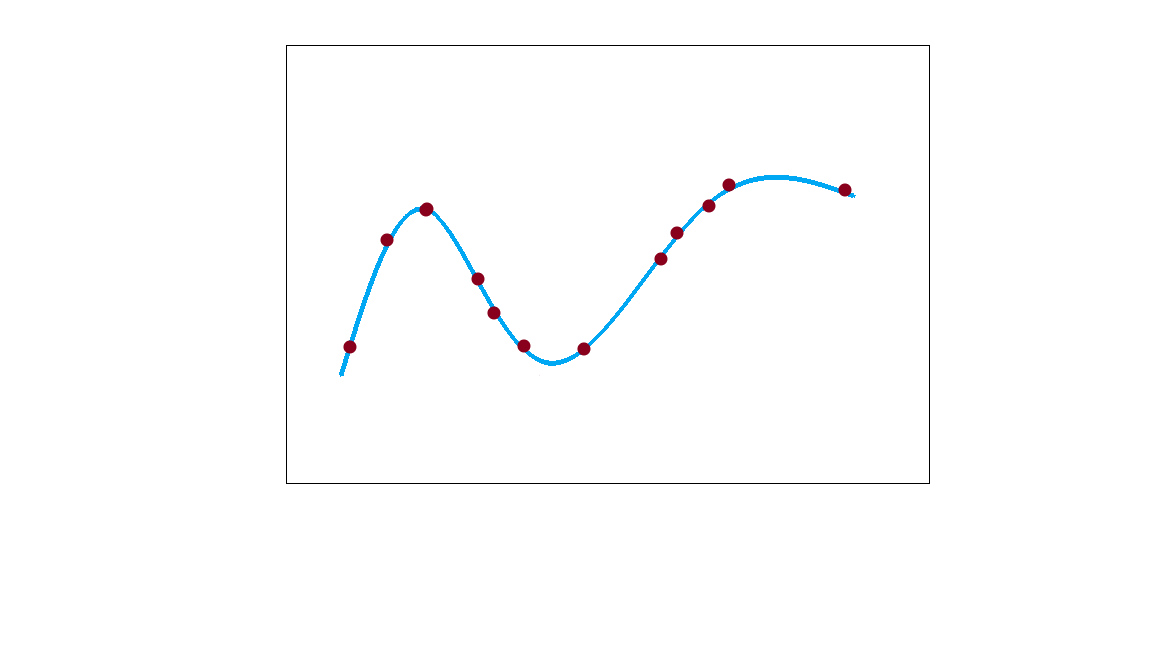
Why does Overfitting Occur?
The main reason for overfitting can be attribute to the fact that a very complex model is used for a dataset which can be learned with a simpler model. In that case, the model tries to capture the noise and outliers and begins to find relationships among them as well.
Solution to Overfitting
The two most common solutions to overfitting:
- You can try to reduce the noise and outliers in the data. This can be done in the pre-processing stage which is a common stage in any machine learning project.
- You can also try to gather more data. In that way the model will find it hard to find relation among the noise and try to generalize the data that is actually relevant.
But the above two steps are only the beginning. You can try setting hyperparameters and extracting new features as well. In some cases, they tend to work really well.
Underfitting
Underfitting is just the opposite of overfitting. The model finds it difficult to even find relation among the relevant underlying structure.
Linear models in machine learning are most prone to underfitting, though this is not always the case. But when this occurs, then the model is not accurate even on the training set. The image below will make it even clear.
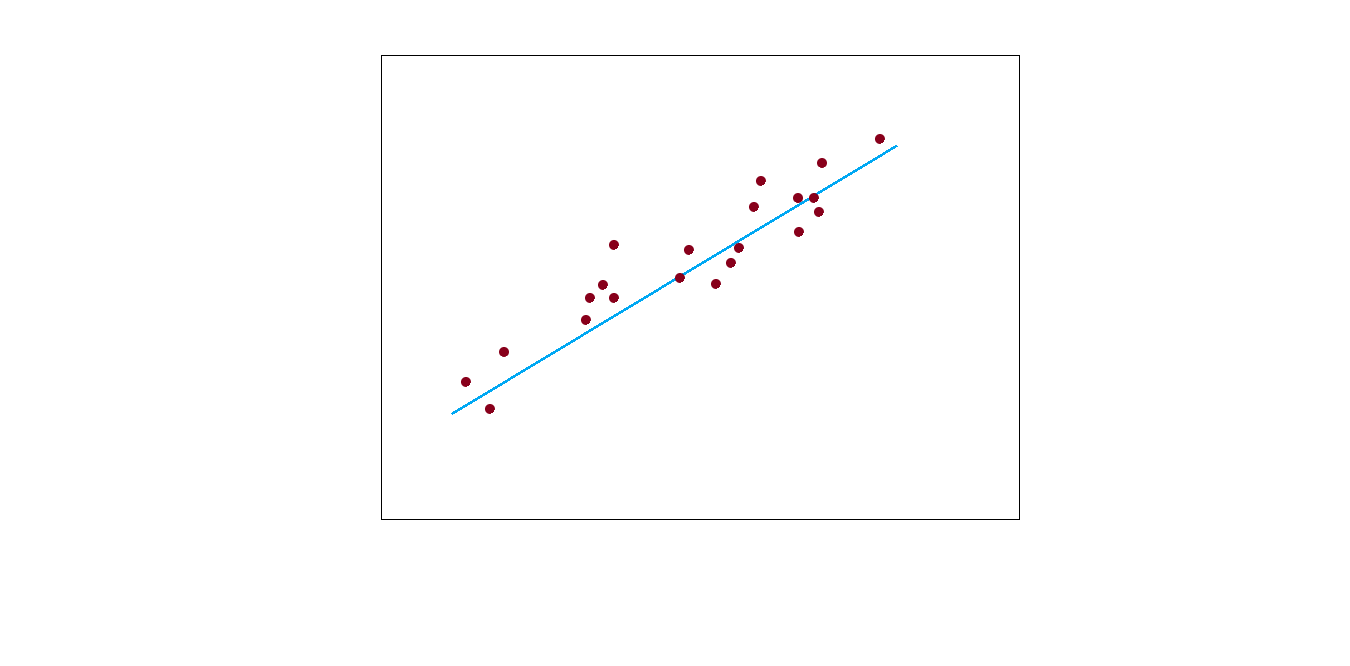
Solution
The most common solution to underfitting is choosing a more complex model than the used linear model. It can help to capture the features better and find the patterns. You can also play with the features and try to extract more relevant features from the data.
Conclusion
This is a short overview of the concepts but I hope that you liked it. Share it and give a thumbs up. Follow me Twitter to get regular updates of my articles.

3 thoughts on “A Theory of Overfitting and Underfitting in Machine Learning”