

In the world of machine learning, there are numerous algorithms to choose from. Each algorithm has its own benefits and drawbacks and we should choose one that will work best for the data we have in hand. Random Forests are perhaps one of the best-known algorithms. In this article, we will learn about Random Forests in machine learning. We will try to answer how they work and why they work so well.
What are Random Forests?
Random forest is a supervised learning algorithm.
Random Forests are typically an ensemble of Decision Trees. In machine learning, decision trees are really versatile algorithms. They can perform both classification and regression. They can handle large and complex datasets as well.
So, when we combine decision trees, we end up with a random forest. Random Forests are one of the most powerful machine learning algorithms available today. Like decision trees, they can perform both classification and regression. Obviously, there a lot of things going on behind the scenes while using random forest on a machine learning problem. And we will look into those shortly.
To know the exact workings of random forests, we first need to know about Ensembling and Bagging in Machine Learning.
Ensemble in Machine Learning
In ensembling, we choose several base predictors and train each predictor on a different subset of the same training set.
In other words, we choose different learning algorithms. Then we train each algorithm on a random subset of the training dataset. This is one of the most important features in the ensembling method. Because we train each algorithm on different subsets of the training data, therefore, each algorithm will learn a different important feature. That’s why ensembling is such a powerful method.
Finally, we combine all the trained algorithms to obtain one final predictive model. This final model will perform better than each of the individual models.
Ensemble learning is a very powerful method in practice and often works out very well for large and complex datasets. In machine learning competitions, most of the time it is an ensemble model that takes the higher place on the leaderboard.
Bagging in Random Forests
Random forests are trained by using the concept of bagging which is another very important feature of ensemble learning.
Bagging is short for Bootstrap Aggregating. Bagging is mainly helpful when we choose to use an ensemble technique in machine learning.
In bagging, instead of different algorithms, we use the same algorithm for every predictor. Each of the predictors of the algorithm is trained on different subsets of the training data.
The following image will help you better understand the concept of bagging.
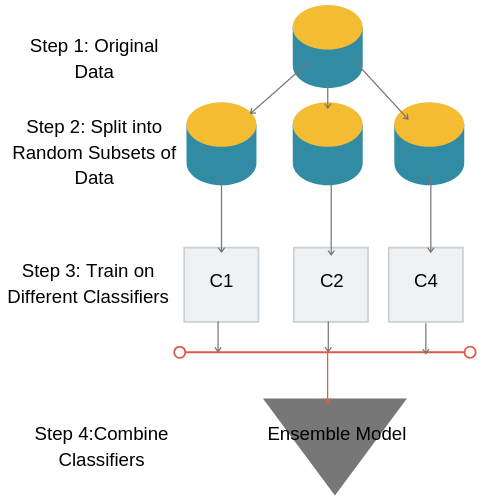
Now coming back to random forests, they are trained by the method of bagging. That means, we have different decision trees which will train on the random subsets of the data. And we know that decision trees are very efficient algorithms.
Why are Random Forests so Efficient?
In the previous section, we saw that random forests are a combination of optimized decision trees where each decision tree will learn from a different subset of the original data.
When combined with the concept of bagging, each decision tree will learn a different feature of the dataset. Due to this, there is a high probability that both, the bias and variance will reduce. This will ultimately reduce the chances of either overfitting or underfitting. Because of this, the model will work very well on the unseen test data. This is one of the main reasons for the efficiency of random forests.
Now, we know that each of the decision trees in a random forest is trained on different subsets of data which leads to better accuracy. But that is not the only reason.
At each node split, all the features are not considered for evaluation. Only a random set of features are considered to decide the best split. This is one more reason for the high efficiency of random forests.
Implementing a Simple Random Forest Classifier
Scikit-Learn makes it really easy to implement Random Forest. There are a number of hyperparameters to tune while using Random Forest Classifier from Scikit-Learn. You can take a look at all these hyperparameters here.
We will try to implement a very simple example to see the working of random forest classifier. We will use make_classification module from sklearn.datasets to create a random dataset for classification. The following example is just for making you comfortable with Random Forest Classifier. It is a very simple approach for using the classifier with Scikit-Learn library.
First, let’s import all the packages that we will need.
from sklearn.ensemble import RandomForestClassifier from sklearn.datasets import make_classification from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score
We are also importing train_test_split module to split the data between training and testing set. Also, we will use accuracy_score to evaluate our classifier.
Now, let’s load the data and build the classifier
X, y = make_classification(n_samples=10000, n_features=5,
n_redundant=0, random_state=0, shuffle=False)
clf = RandomForestClassifier(n_estimators=100)
In the above code snippet, we are loading 10000 samples. The number of features is 5. There is one more parameter, that is n_redundant. This specifies the number of redundant features which we have set to 0.
For the classifier, we are using n_estimators=100. This tells that there are 100 different decision trees ensembled to build the classifier.
Now, let’s split the data into 80% training set and 20% test set.
x_train, x_test, y_train, y_test = train_test_split(X, y, train_size=0.8)
Next, we can train the classifier, predict on the test set, and print the accuracy score as well.
# train the classifier clf.fit(x_train, y_train) # predict on the test set y_preds = clf.predict(x_test) # print the accuracy print(accuracy_score(y_test, y_preds))
0.8905
We are getting around 89% accuracy. You can always do better. Start by changing the number of estimators of the random forest. There are a lot of other hyperparameters to tune as well. Play with those a bit and you will feel even more comfortable.
Summary and Conclusion
In this article, you learned about the working of the Random Forest Algorithm and how the ensemble method is used. You also got to know how to use the Scikit-Learn library to implement Random Forest Classifier.
If you gained something from this article, then subscribe to the website and turn on the notifications as well to get timely updates. You can follow me on LinkedIn and Twitter to get updates about new articles.

1 thought on “An Introduction to Random Forests in Machine Learning”