

The world of open-source Large Language Models (LLMs) is rapidly closing the capability gap with proprietary systems. However, in the multimodal domain, open-source alternatives that can rival models like GPT-4o or Gemini have been slower to emerge. This is where BAGEL (Scalable Generative Cognitive Model) comes in, an open-source initiative aiming to democratize advanced multimodal AI.

Training unified multimodal models that can seamlessly understand, generate, and edit images is an immense challenge. It involves navigating complex architectural decisions, vast datasets, and intricate training regimes. BAGEL, developed by researchers from ByteDance and various academic institutions, tackles these challenges. This results in a powerful foundation model licensed under Apache 2.0.
We are going to cover the following topics to understand BAGEL
- What is BAGEL, and why do we need it?
- Why is BAGEL special?
- What kind of unification does BAGEL use, and how does it help?
- What is MoT (Mixture of Transformers) that BAGEL uses as part of its architecture?
- How do the thinking and non-thinking abilities help in such unified multimodal models?
- How to run inference for image generation, image understanding, and image editing using BAGEL?
What is BAGEL, and Why Do We Need It?
BAGEL is an open-source foundational model designed to natively support both multimodal understanding and generation. It’s a unified, decoder-only transformer pretrained on trillions of tokens. This vast dataset is not just text-based but comprises carefully curated, large-scale interleaved text, image, video, and web data.
It is a 14B parameter model with 7B active parameters during inference.
The need for models like BAGEL is now more than ever. While proprietary systems have demonstrated incredible multimodal capabilities, they limit broader research and application. The paper highlights a “substantial gap” between existing academic models and these closed systems. BAGEL aims to bridge this gap by:
- Providing an open-source alternative for researchers and developers.
- Sharing key findings, pretraining details, and data creation protocols.
- Releasing code and checkpoints to foster community-driven advancements.
By unifying understanding and generation within a single framework, BAGEL paves the way for a set of open-source multimodal models.
Why is BAGEL Special? Emerging Properties and Performance
BAGEL’s training on diverse interleaved data allows it to exhibit emerging capabilities in complex multimodal reasoning. These are abilities not explicitly programmed but surface as the model scales. As a result, BAGEL:
- Significantly outperforms prior open-source unified models on standard benchmarks for both multimodal generation and understanding.
- Demonstrates advanced reasoning abilities such as free-form image manipulation, future frame prediction, 3D manipulation, and even simulated world navigation.
The paper notes that as BAGEL scales with interleaved multimodal pre-training, a clear pattern emerges:
- Basic multimodal understanding and high-fidelity generation converge first.
- Complex editing and free-form visual manipulation abilities surface next.
- Finally, long-context reasoning benefits both understanding and generation, suggesting a synergy of atomic skills into compositional reasoning.
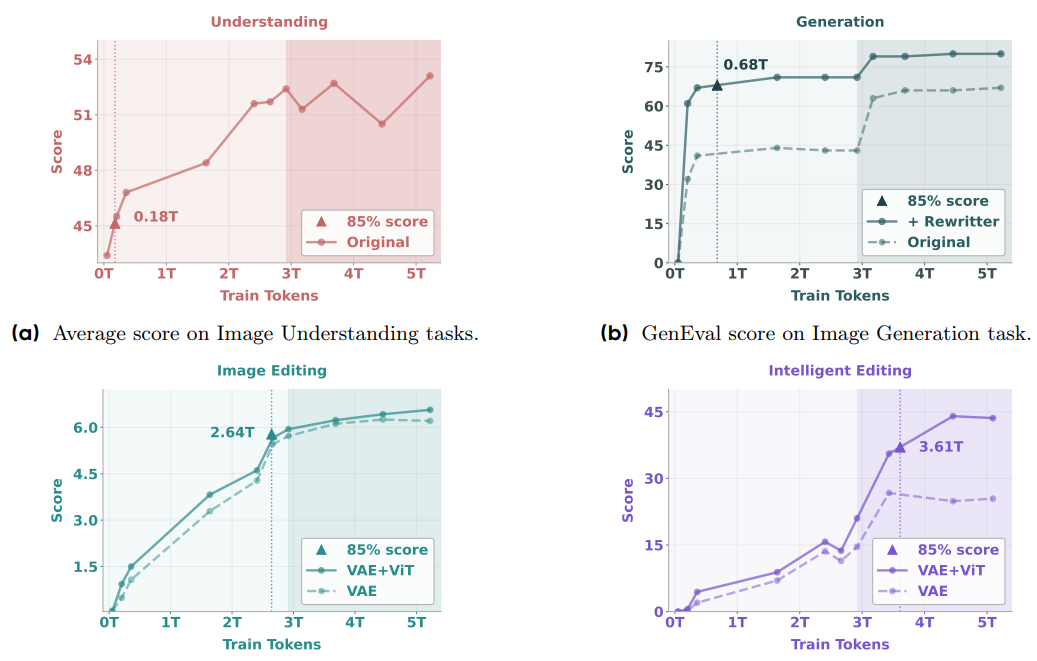

These advanced capabilities, often beyond the scope of traditional image editing models, make BAGEL a particularly exciting development.
Want to know more about fine-tuning VLMs? Here are some articles that are perfect for you.
- Fine-Tuning Llama 3.2 Vision
- Qwen2 VL – Inference and Fine-Tuning for Understanding Charts
- Fine-Tuning SmolVLM for Receipt OCR
Unifying Multimodal Understanding and Generation
A core design philosophy behind BAGEL is to maximize the model’s capacity without introducing “heuristic bottlenecks or task-specific constraints” often found in previous models. To achieve true unification, the BAGEL team explored several design choices:
- Quantized Autoregressive (AR) models: While straightforward, they often suffer from lower visual quality and high inference latency.
- External Diffuser models: These connect LLMs to diffusion models via adapters. While they can converge quickly, they introduce a bottleneck by compressing LLM context into a few latent tokens. This potentially results in the loss of information crucial for long-context reasoning.
BAGEL opts for an Integrated Transformer approach. This involves a unified integration of LLM principles (for understanding and reasoning) and diffusion model principles (for strong visual generation) within a single transformer architecture. This design:
- Maintains a bottleneck-free context throughout all transformer blocks.
- Enables lossless interaction between generation and understanding modules via shared self-attention operations.
- Is more amenable to scaling and better suited for long-context multimodal reasoning.

This unified architecture allows text, ViT (Vision Transformer for understanding), and VAE (Variational Autoencoder for generation) tokens to be interleaved and processed cohesively.
The MoT (Mixture-of-Transformers) Architecture
To implement its unified vision, BAGEL adopts a Mixture-of-Transformers (MoT) architecture. This distinguishes it from denser models or even Mixture-of-Experts (MoE) setups.
In BAGEL’s MoT:
- There are two distinct transformer experts: one specialized for multimodal understanding and the other for multimodal generation.
- Correspondingly, it uses two separate visual encoders: an understanding-oriented encoder (initialized from SigLIP2) and a generation-oriented VAE (from FLUX, frozen during training).
- Crucially, these two transformer experts operate on the same token sequence and utilize shared self-attention at every layer. This allows for deep interplay between the understanding and generation pathways.

The paper presents ablation studies comparing Dense, MoE (duplicating FFN layers), and MoT (duplicating all trainable LLM parameters for the generation expert). The MoT variant consistently outperformed the others, especially in multimodal generation (MSE loss), while maintaining strong performance in understanding (CE loss). This suggests that dedicating separate, full-capacity experts for understanding and generation, while allowing them to share context through attention, mitigates optimization challenges that arise from competing learning objectives.
Reasoning-Augmented Capabilities: Thinking and Non-Thinking Models
An important feature of BAGEL is its ability to engage in explicit reasoning, or “thinking,” before producing an output. This is facilitated by:
- Reasoning-Augmented Data: The pretraining data was added with reasoning-oriented content (inspired by DeepSeek-R1), including Chain-of-Thoughts (CoT) for multimodal understanding. The hypothesis is that a language-based reasoning step before image generation can clarify visual goals and improve planning.
- Explicit CoT Generation: For tasks like text-to-image generation or complex image editing, BAGEL can be prompted to first generate an intermediate “thinking” step (CoT). This refines the initial prompt or outlines the editing strategy. This refined understanding then guides the final output generation.
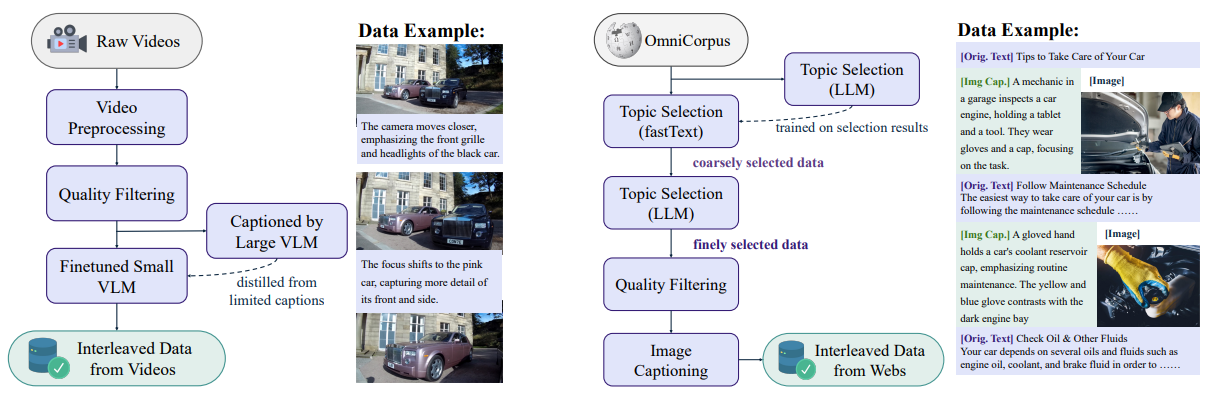
This “thinking” process significantly enhances performance.
- For text-to-image on the WISE benchmark, BAGEL with CoT achieved a score of 0.70, a substantial improvement over its non-CoT counterpart (0.52) and surpassing previous open-source SOTA.
- For intelligent image editing, CoT improved BAGEL’s IntelligentBench score from 44.9 to 55.3. This can be attributed to better leverage of world knowledge and detailed editing guidance.

This ability to “think” allows BAGEL to tackle more ambiguous prompts and complex, multi-step tasks.
Running Inference with BAGEL
With 14B total and 7B active parameters, BAGEL needs at least 12GB VRAM with flash-attention to run inference. To avoid this overhead, we use the official demo website launched by the authors.
You can also visit their GitHub repository and set up BAGEL locally if your hardware meets the requirements.
The demo website supports image understanding, image generation, and image editing – all with thinking and no-thinking options.
Image Understanding/Captioning Using BAGEL
We start with a simple prompt and ask it about an image of a cat without thinking mode enabled.
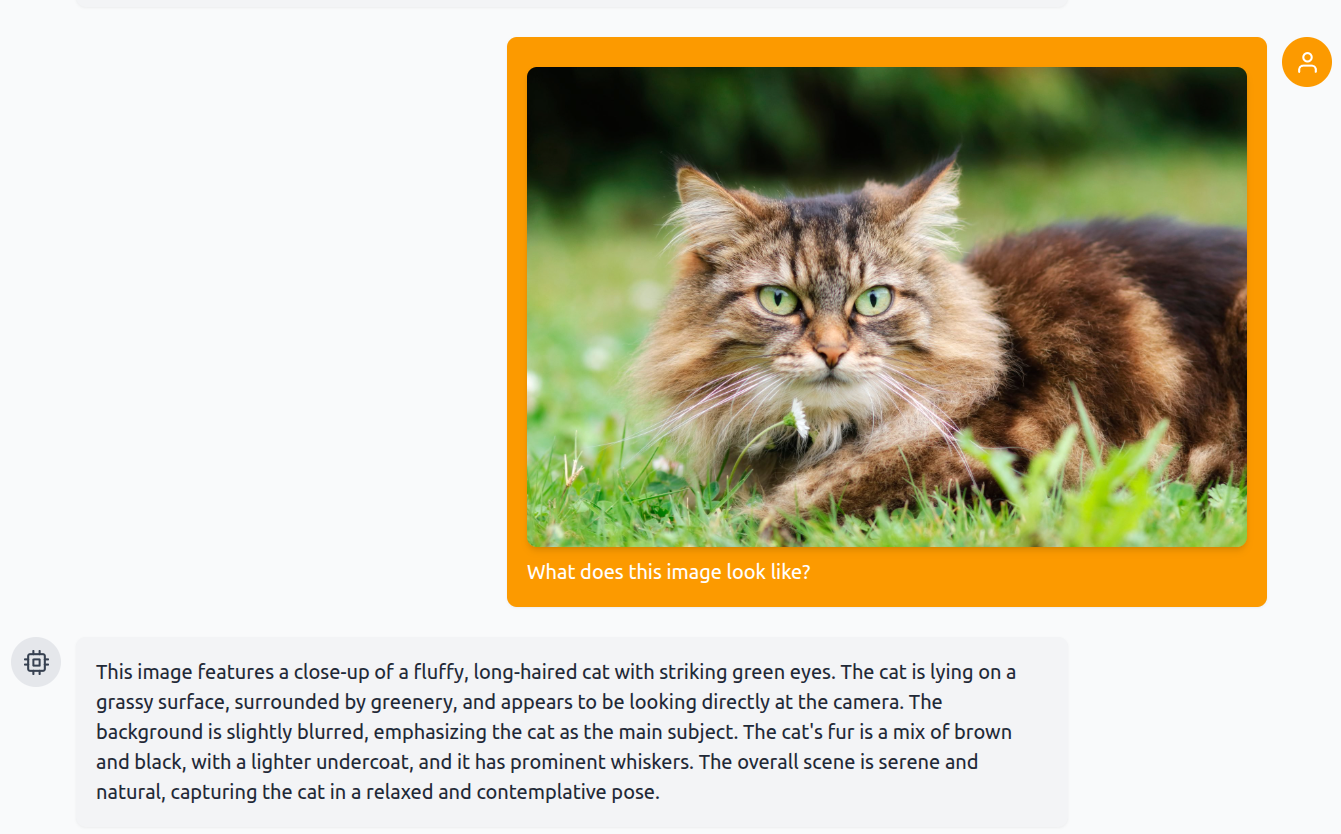
The caption is quite detailed, capturing every aspect, starting from the eyes of the cat to the blurry background.
Now, let’s ask about the same image, this time, however, with thinking mode enabled.
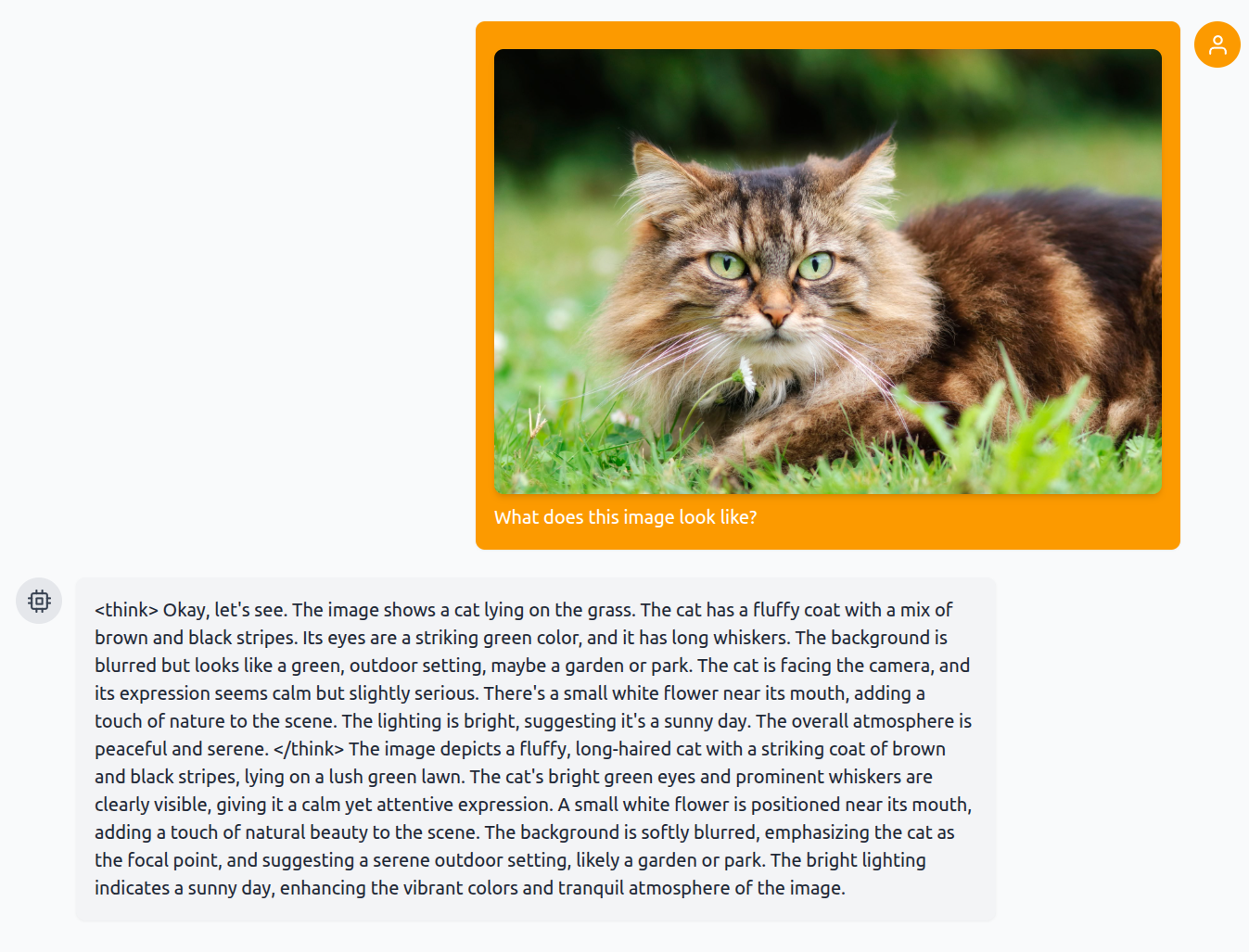
This time, the caption is even more detailed. It went on to understand that there is an image of a flower near the cat’s mouth.
Image Generation Using BAGEL
Let’s move to image generation. We simply ask the model to generate an image of a cat. Once with non-thinking mode and the other time with thinking mode enabled. We use the default time-steps to generate the image here, which is 50.


Clearly, the image with thinking mode enabled is superior. However, in both cases, the quality of the image is not as good as pure diffusion based image generation models. This might be one of the drawbacks of training a multimodal-multitask model. We can expect these results to get much better in the near future.
Image Editing Using BAGEL
For image editing, we use a simple image of a flamingo and ask BAGEL to cartoonize it. First, we let it generate the image in non-thinking mode with 50 time-steps. Second, the same time-steps but with thinking mode enabled. Third, with the thinking mode enabled and using 100 time steps.
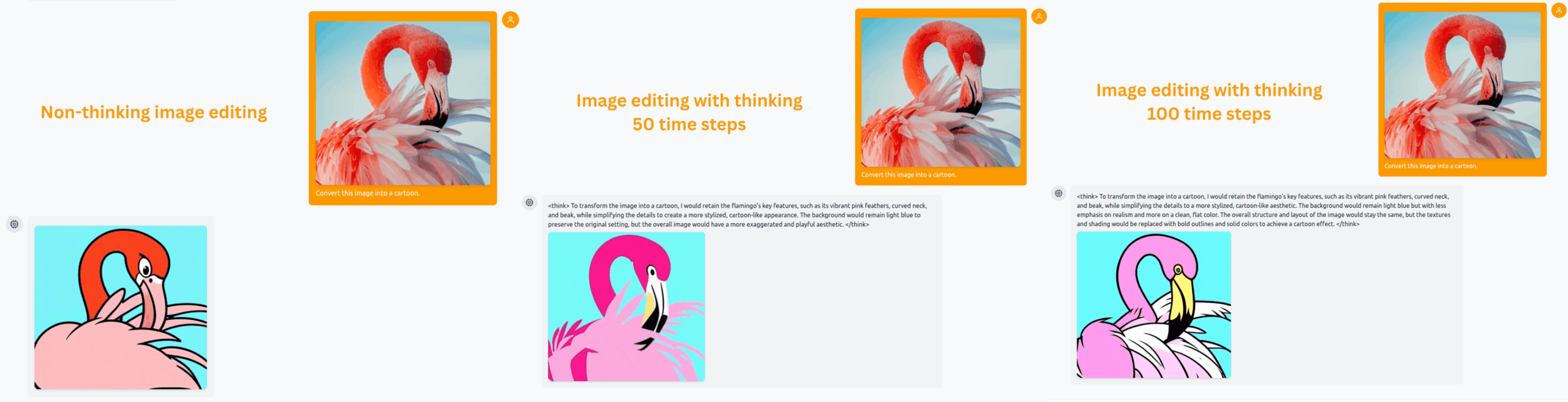
The first result is fine, we get what we ask, nothing fancy here. Interestingly, in the second case with 50 time-steps and thinking mode enabled, the result looks worse and blurrier. However, it gets much better with 100 time steps. Of course, experimenting with more such tasks will give a clearer picture. So, try to play around and analyze what kind of results you are getting.
Summary and Conclusion
In this article, we covered a short introduction to BAGEL. By successfully unifying understanding and generation within a scalable MoT architecture and training it on trillions of tokens of diverse, interleaved data, it not only achieves state-of-the-art performance on many benchmarks but also exhibits remarkable emerging properties. We will try to cover more on BAGEL in future articles.
If you have any questions, thoughts, or suggestions, please leave them in the comment section. I will surely address them.
You can contact me using the Contact section. You can also find me on LinkedIn, and X.
References
