In this article, we explore the Web-DINO models trained via Web-SSL 2.0 methodology on the MC-2B (MetaCLIP-2B) dataset. ...
Web-SSL: Scaling Language Free Visual Representation


Machine Learning and Deep Learning
In this article, we explore the Web-DINO models trained via Web-SSL 2.0 methodology on the MC-2B (MetaCLIP-2B) dataset. ...

In this article, we cover the architecture of ViTPose and ViTPose++ and run inference on images & videos using ViTPose. ...
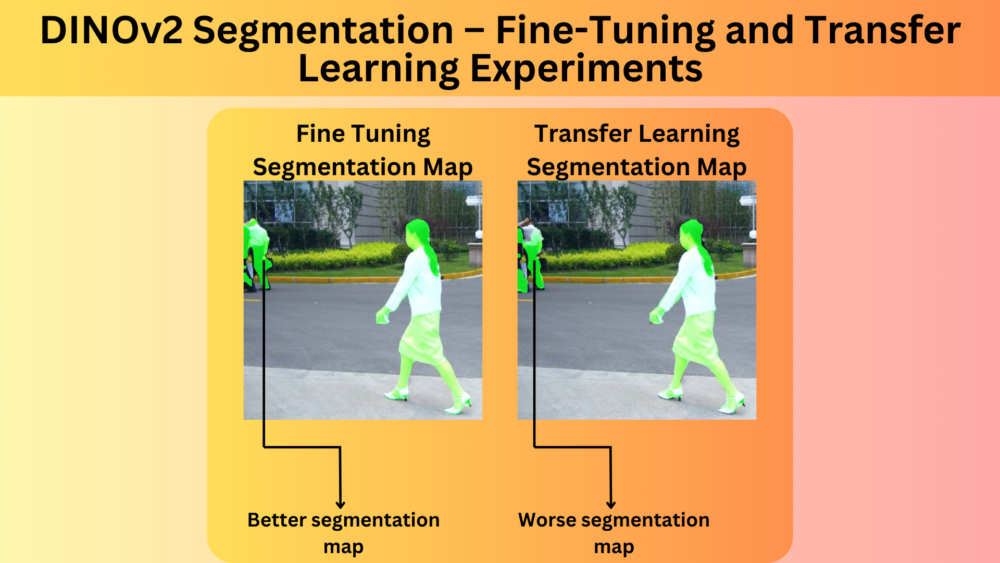
In this article, we simply the semantic segmentation (pixel classification) head of the DINOv2 model and carry out experiments comparing fine-tuning and transfer learning. ...

In this article, we modify the DINOv2 model for semantic segmentation, freeze the backbone, and train the model on the Penn-Fudan Pedestrian segmentation dataset. ...

In this article, we create a custom Vision Transformer based object detection model using NVIDIA's FasterViT backbone and the Single Shot Detection head. ...
Business WordPress Theme copyright 2025