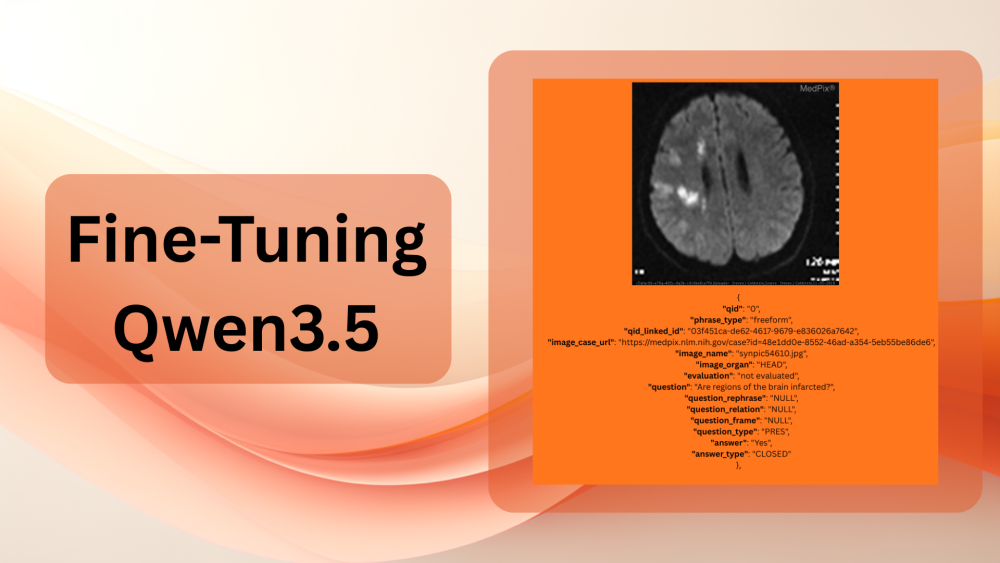
In this article, we fine-tune the Qwen3.5-0.8B model on the VQA-RAD dataset, which is a question-answering dataset based on radiology images. After training, we carry out inference using the fine-tuned model. ...
Fine-Tuning Qwen3.5

Machine Learning and Deep Learning
In this article, we fine-tune the Qwen3.5-0.8B model on the VQA-RAD dataset, which is a question-answering dataset based on radiology images. After training, we carry out inference using the fine-tuned model. ...

In this article, we explore creating a simple sketch to HTML application using Qwen3-VL where users can upload an image or screenshot for a potential website and the Qwen3-VL model will give back the HTML. ...

In this article, we explore the Qwen3-VL model, the latest iteration of the Qwen-VL series. We start with model architecture and benchmarks, and then move to hands-on inference for object detection, OCR, video understanding, and sketch-to-HTML using Qwen3-VL. ...

In this article we are fine-tuning the Phi-3.5 Vision Instruct model on a receipt OCR dataset. We are using Hugging Face libraries and training a LoRA. ...

In this article, we explore the DEIMv2 object detection model based on the DINOv3 and HGNetv2 backbones, along with carrying inference on images and videos. ...
Business WordPress Theme copyright 2025