

Training deep learning models to solve a particular problem takes time. Be it image classification, object detection, image segmentation, or any task involving NLP. Many a time, we deal with large models and large datasets. And training a really good model is difficult. It requires computational resources and time. And the fact that we have to deal with a number of hyperparameters that need proper tuning to get the best model does not make the work easier. Choosing the right hyperparameter is key to training the best neural network we can for a specific task.
For that reason, hyperparameter tuning in deep learning is an active area for both researchers and developers. The developers try their best to bring to life and validate the ideas pitched by researchers to tune the hyperparameters while training a deep learning model. In this post, we will be going through an Introduction to Hyperparameter Tuning in Deep Learning.
We will be covering the following topics in this post.
- What are the different hyperparameters we deal with that need tuning while training a deep learning model?
- What are the hyperparameters related to the neural network model?
- Different hyperparameters related to the data.
- Different hyperparameters for the learning algorithm that needs tuning.
- What can be some of the hyperparameters that we need to tune and deal with while dealing with computer vision problems in deep learning?
- Different methods of hyperparameter tuning: manual, grid search, and random search.
- And finally, what are some of tools and libraries that we have to deal with the practical coding side of hyperparameter tuning in deep learning. Along with that what are some of the issues that we need to deal with while carrying out hyperparameter tuning?
A Note Before Moving Further…
Note that this post will be completely theoretical. This is the first post in many that will be published in the future regarding hyperparameter tuning in deep learning. In future posts, we will cover many practical concepts which will include coding and trying out different hyperparameter tuning techniques in deep learning.
You will be able to find a huge number of libraries and tools both for PyTorch and TensorFlow that make the task of hyperparameter tuning a lot easier nowadays. Still, there is a catch to this that we will discuss at the end of this post.
In future posts, we will try to cover as many different hyperparameter tuning techniques across different libraries and frameworks. The posts may not be published serially as the number of posts related to the topic can be high. Still, we will try to cover a few posts after this that directly deal with the practical aspect of hyperparameter tuning.
Now, let’s jump into the post.
Hyperparameters that We Can Tune While Training a Deep Learning Model
There are numerous hyperparameters that we can tune while training a deep learning model. In no particular order, the following are some of them:
- The number of training iterations or training epochs.
- The learning rate.
- Parameters of learning algorithms in themselves.
- The number of layers in a neural network along with the neural units in each layer.
- The batch size.
- The image size when dealing with computer vision tasks like image classification and object detection.
To be frank, there are a whole lot of other things that can be considered as hyperparameters and affect training. The above are only some of them. And in the following sections, we will explore as many as we can under the following categories:
- Hyperparameters to tune in a neural network model.
- Hyperparameters involving the dataset.
- Different hyperparameters involving the learning algorithm.
Let’s start off with the first point, that is, hyperparameters to tune in a neural network model.
Hyperparameters to Tune in a Neural Network Model
When dealing with any problem that we solve using a deep learning technique, the neural network model becomes an integral part of it. The model might be large or small, it affects the final results to a great extent. And it has knobs that need tuning.
Number of Hidden Layers
When a deep learning model does not seem to be performing well in the beginning, the first thing any practitioner will add is more hidden layers. In the case of a convolutional neural network, adding tens of convolutional layers and a few wide linear layers are not uncommon.
In fact, that’s what drove the VGG models to be some of the best when they came out.

But just stacking of layers stops helping at a certain point and we need something more to the architecture. That’s what ResNets proved when they came out.
But we will not go into the details of ResNet in this post as we need to confine ourselves to the hyperparameter part of a neural network. For, now keeping in mind that the number of layers affects the performance should suffice.
Number of Units in the Hidden Layers
The number of hidden neural units go almost hand in hand along with the number of hidden layers. Sometimes, increasing the units in the linear layers can improve the performance of a model drastically.
Still, we need to be very careful here as just a high random number will completely diverge the training or might result in overfitting too soon.
Hyperparameters Related to Layers in Particular
We can also adjust the hyperparameters for the layer building part of the model. A few things that we can choose to handle here are:
- Whether to add Dropout or not? As adding dropout is often a regularization technique and helps to prevent overfitting in larger models. Mostly helps when we try to use a large pre-trained model for transfer learning on a relatively smaller dataset.

- Which activation function to use for hidden layers? The most common options are sigmoid, tanh, and ReLU. But nowadays it seems that ReLU always seems like a good starting point and even performs better than others in almost all cases. Still, sigmoid and tanh have their uses when training GANs. In fact, for GANs even LeakyReLU is an option.
- The initialization of the weights for the layers can also impact training. We have the option between zero initialization and random initialization. For biases, initializing them to 0 is good option. But for convolutional layers, 0 or 1 inititialization is not a very good idea as the weights might not update properly while training. Most of the popular frameworks like PyTorch and TensorFlow, follow the uniform initialization of the weights for the convolutional layers.
Hyperparameters to Tune Involving the Dataset
There are quite a few hyperparameters related to the dataset that we can tune. Let’s go over them.
Batch Size
Batch size almost always seems to affect training. Using a very small batch size can lead to slower convergence of the model. This is mostly because of how many samples the model gets to train on each iteration which directly affects the weight updates.
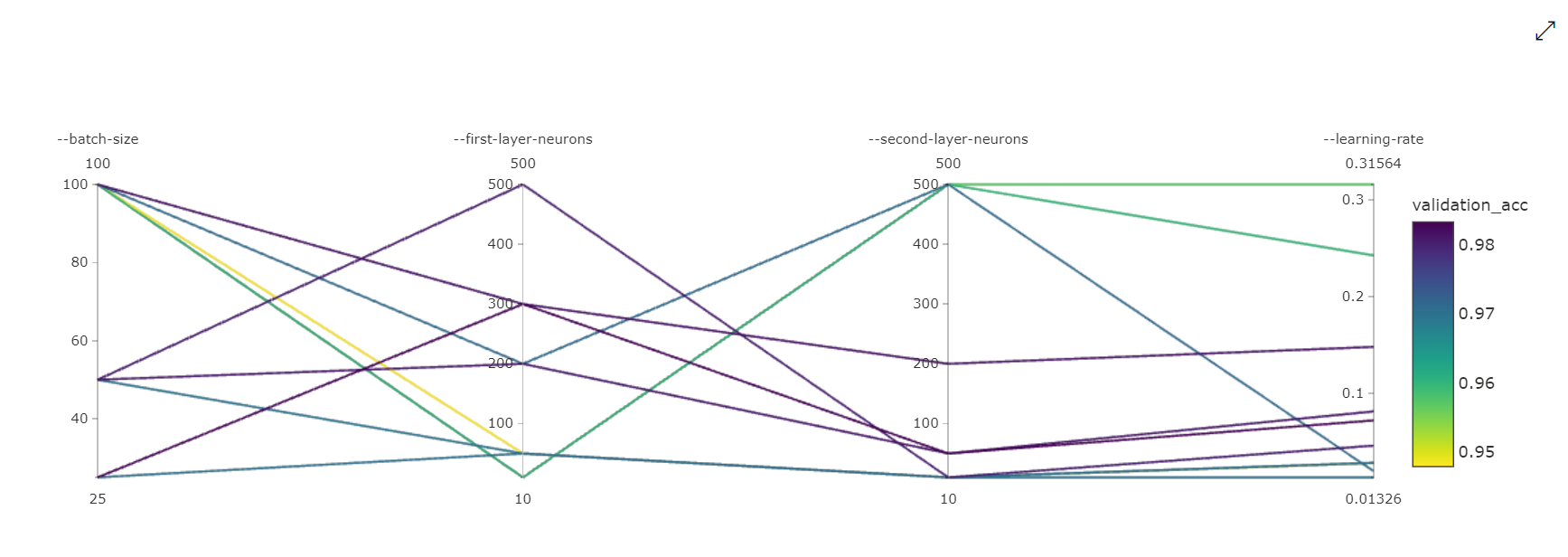
Too small or a too large batch size can both affect training badly if we do not take care of the other things. That being said, a batch size of 32 or 64 almost always seems like a good option for computer vision and mainly image classification tasks.

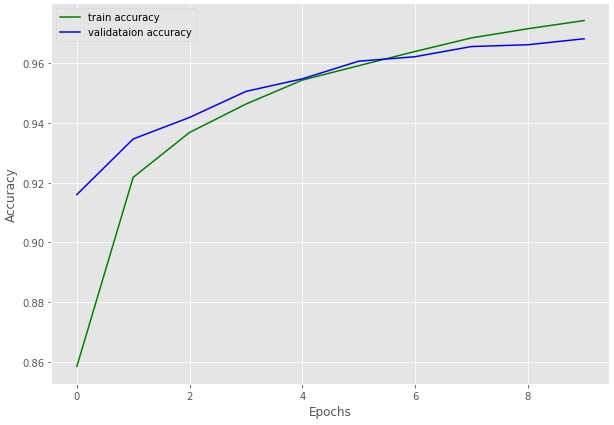
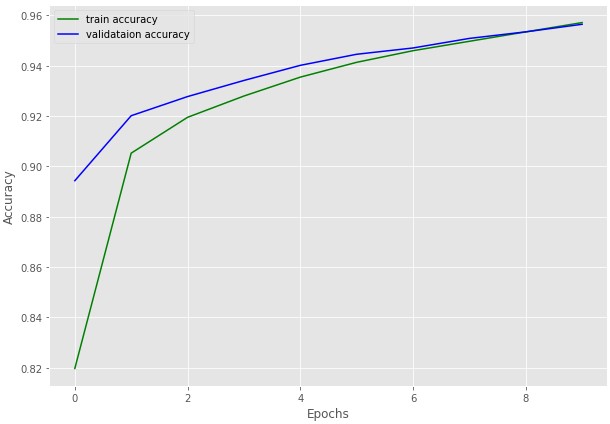
There is one thing to note here though. Sometimes it’s just not possible to use a very large batch size due to GPU memory constraints. Does that mean that we will not be able to train our model at all? Not likey so. A smaller batch size mostly will affect the convergence time. It might double or even triple the number of iterations required to reach the loss that a batch size of 32 or 64 gives. But mostly, the model will reach that loss, slowly.
This mostly happens because in one iteration the model is able to see very few examples. So, to correctly orient its weights in the right direction it will need more training examples which can only happen by more number of iterations or epochs.
Number of Training Iterations or Epochs
The last sentence in the above paragraph brings us directly to the next controlling hyperparameter. That is the number of iterations (also known as the number of batches) or the number of epochs (number of times trained on the entire dataset).
By now we have seen that other hyperparameters like batch size also affect how many iterations we need to train the model for to reach an optimal solution. Then again, even with proper batch size, the number of epochs affects the training to a good extent.
We cannot train for a very less number of epochs, as there is a chance that the model might reach an even lower loss if further training takes place. Also, we cannot train for a random high number of epochs as it may cause overfitting resulting in the increase of validation loss.
Early stopping is a good way to control the number of epochs we need to train for. When the metric we want to monitor does not improve for a few epochs, we stop the training. This usually, is a good practice and often helps to get an optimal model as well.
Number of Training Samples
There is no denying that training deep learning models require a lot of training data, well, most of the time at least.
If training from scratch, then we surely need a lot of data. To give a perspective, any new CNN that comes out is trained on 1 million images from the ImageNet dataset so that its pre-trained features can be used for transfer learning and fine-tuning. So, the number of samples does matter a lot. If we are carrying out fine-tuning using a pre-trained model, then having somewhat fewer training samples will be fine.
Still, even during transfer learning and fine-tuning, we might have hundreds of thousands of training images. We can easily sample a set out of them as per our requirement and carry out the training. If the performance is not good enough, we sample more images. This means that number of training samples can have a direct impact on the training of the model.
If It is a Computer Vision Problem…
Now, this particular point is only valid for convolutional neural networks and scenarios where we deal with images.
For image classification and object detection, the resolution (dimension) of images matter a lot. Often, feeding larger images to the neural network leads to better accuracy. This is because the model gets to see more features in a single image. As an image that is 512×512 in dimension will have more features and information than an image that is 224×224 in dimension. Although, we need to keep in mind that using high-resolution images also leads to slower training iterations and needs more GPU memory. So, we might need to decrease the batch size, which again can have an adverse impact on the training time of the model.
Hyperparameters to Tune in the Optimization Algorithm
Choosing the right optimizer is one of the most critical tasks for the success of any deep learning problem. There are a few very important hyperparameters that we need to tune according to the optimizers we choose. And let’s keep things completely practical here, and choose the things we deal with while coding deep neural nets on a day-to-day basis.
The Learning Rate
Enough emphasis cannot be put on how much important the learning rate is for an optimizer to work properly. In simple words:
- Too high learning rate => training might diverge => the model might not reach an optimal solution at all.
- Too low learning rate => the convergence will be slow => or the model might not reach an optimal solution at all.
We need the right learning rate which will lead to proper training.
And even if we start with the perfect learning rate, as the model starts to learn, we most probably have to schedule it properly so that the model keeps on learning in the right direction.
Parameters of Optimizers
Moreover, not to mention that optimizers have their own parameters which we may need to tune at times.
- In SGD (Stochastic Gradient Descent), we have the momentum and weight decay parameters. Although both of them already have some optimal values which work well. For examples, the value of 0.9 for momentum is often a good choice. The weight decay parameter, which introduces an L2 penalty while learning, works well with a value of 0.0005.
- In Adam optimizer, we have the beta coefficients used for computing running averages of gradient and its square. The optimal and default values for (beta1 and beta2) both PyTorch and TensorFlow are 0.9, and 0.999 respectively. However, things change when dealing with Generative Advesarial Networks, where it is advised to use a value of 0.5 for beta1.
By now, we know that hyperparameter tunning can be a big task in deep learning. But before we can tune them, we still have to decide one more thing. How do we approach tuning the hyperparameters?
Different Approaches to Hyperparameter Tuning in Deep Learning
In the above sections, we saw that we have a bunch of hyperparameters to tune while training a neural network.
But how do we move on to change the values? Do we:
- Train once, check the results and change one or more hyperparmeters at a time manually (manual hyperparameter tuning)?
- Do we go on serially changing a few values after each training till we find the hyperparameters that give us the best results (grid hyperparameter search)?
- Do we change a few hyperparameters randomly after each training experiment till we find the best set of hyperparameters (random hyperparameter search)?
To keep this section short, let’s jump on the best approach that was found by James Bergstra and Yoshua Bengio and was published by them in the paper Random Search for Hyper-Parameter Optimization (the name gives it away).
The best approach is random hyperparameter search. And the following image from the paper explains that reason in a few simple words.

We will not go any deeper into what was covered in the paper. But I would recommend that you go through the paper at least once. It has a lot of insights that will surely help you in training better neural network models.
Different Libraries and Frameworks Available for Hyperparameter Tuning in Deep Learning
We have covered a lot of theoretical concepts by now. Let’s try to get into the practical side a bit.
From the above, it is pretty clear that writing code from scratch for hyperparameter tuning is not an easy task. Thankfully, there are many libraries and frameworks that are available that can help us in this. Here are a few:
Ray Tune is a Python library for fast hyperparameter tuning at scale…Tune is a Python library for experiment execution and hyperparameter tuning at any scale…Supports any machine learning framework, including PyTorch, XGBoost, MXNet, and Keras.
https://www.ray.io/ray-tune
KerasTuner is an easy-to-use, scalable hyperparameter optimization framework that solves the pain points of hyperparameter search… comes with Bayesian Optimization, Hyperband, and Random Search algorithms built-in…
https://keras.io/keras_tuner/
An open source hyperparameter optimization framework to automate hyperparameter search…Optuna is framework agnostic. You can use it with any machine learning or deep learning framework.
https://optuna.org/
The above three are some of the biggest players in hyperparameter optimization and tuning in the deep learning field. There are a few more, which may not be as widely used as the above, but are surely useful.
- Scikit-Learn: As surprising as it may sound, we can use Scikit-Learn’s Grid Search and Random Search methods to directly tune hyperparameters of models built with TensorFlow/Keras.
- Skorch: We can combine the methods that Skorch provides along with the techniques of Scikit-Learn to optimize hyperparameteres of models in PyTorch.
Hopefully, in future articles, we will be able to tackle a lof examples which include hyperparameter tuning for deep learning models along with the usage of the above libraries.
A Bit More About Hyperparameter Tuning for Deep Learning…
Deep Learning models take time to train. Not always, may not be when someone is starting out with deep learning and trying out MNIST classification. But eventually, everyone reaches a stage where they start to train big enough models which takes a lot of time to train.
When your model is taking a day or a week to complete one set of experimentation, hyperparameter tuning, which will run the same experiment multiple times, does not seem like a very good idea. Still, we will explore all of the possible scenarios while getting hands-on with the different libraries and will see for ourselves how to tackle such situations.
Summary and Conclusion
In this post, we covered the theoretical aspects of hyperparameter tuning in deep learning. We went over the different hyperparameters that we can tune for optimizers, models, and datasets. We also covered a few of the libraries that support hyperparameter optimization. I hope that this article was useful to you.
If you have any doubts, thoughts, or suggestions, please leave them in the comment section. I will surely address them.
You can contact me using the Contact section. You can also find me on LinkedIn, and X.

4 thoughts on “An Introduction to Hyperparameter Tuning in Deep Learning”