
The field of natural language processing (NLP) has witnessed significant advancements in recent years, thanks to the emergence of innovative deep learning models. Among these models, the Transformer neural network is a game-changer, revolutionizing sequence transduction tasks such as machine translation, language modeling, and more. In this article, we will explore the key concepts and findings from the groundbreaking paper “Attention is All You Need” by Vaswani et al. (2017).

What are we going to cover in this article?
- We will start with a short introduction to the amazing Attention is All You Need paper and its authors.
- We will follow this with a discussion of neural attention.
- Then we will cover the original Transformer neural network as introduced in the paper. This includes the discussion of:
- Encoder and Decoder stacks
- Attention Mechanism
- Scaled dot product
- Positional encoding
- Next, we will discuss the various tasks that the Transformer model can perform along with the results from the paper.
Note: This is not a technical guide to the Transformer Neural Network. There are many great articles out there that cover that and I will post the links at the end of the article. This is more of a summary of what the Transformer neural network is, what it can do, and how it is shaping the NLP landscape.
Attention is All You Need
The Transformer neural network was introduced in the paper Attention Is All You Need. The authors of the paper are Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin.
In short, the paper introduced a whole new architecture for sequence transduction called the Transformer. Although it all started with NLP as it turns out, the Transformer model will go on to not only reshape the NLP landscape but also the Computer Vision landscape.
Let’s take a look at what made the Transformer architecture so unique, powerful, yet simple.
The Power of Neural Attention
Traditional sequence transduction models heavily rely on recurrent or convolutional neural networks, which involve complex architectures with encoders and decoders. However, these models often struggle with long-range dependencies and suffer from limited parallelization capabilities. The introduction of attention mechanisms has been a significant breakthrough in addressing these limitations by allowing models to focus on relevant information without considering the distance between input and output positions.
Neural attention, in particular, has proven to be highly beneficial in various sequence modeling and transduction tasks. By leveraging the power of attention, models can learn dependencies between input and output positions without recurrent connections. This not only improves the quality of the results but also enables higher parallelization and reduced training time.
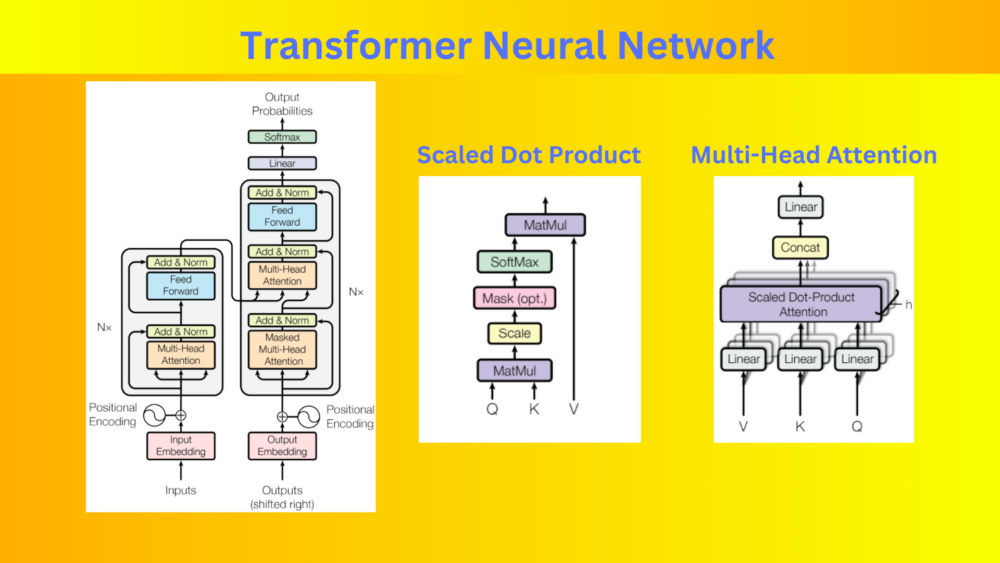
The Transformer Neural Network Model Architecture
The Transformer model proposed in the paper completely dispenses with recurrence and convolutions, instead relying solely on attention mechanisms. The architecture consists of stacked self-attention and point-wise, fully connected layers for the encoder and decoder.
Encoder and Decoder Stacks in Transformer
The encoder stack consists of N identical layers, each containing two sub-layers. The first sub-layer is a multi-head self-attention mechanism. The second one is a position-wise fully connected feed-forward network. Residual connections and layer normalization are present to facilitate information flow within and between the sub-layers.

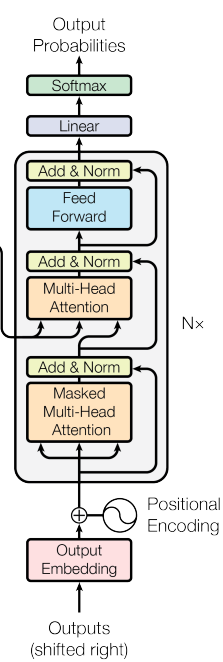
Similarly, the decoder stack comprises N identical layers, including the self-attention and feed-forward sub-layers. Additionally, the decoder inserts an extra sub-layer. This performs multi-head attention over the encoder stack’s output. It enables attention-based information transfer from the input sequence to the output sequence during decoding.
Attention Mechanisms in Transformer Neural Network
The Transformer model employs self-attention mechanisms in three different ways:
- Encoder-Decoder Attention: This attention layer allows each position in the decoder to attend to all positions in the encoder. This enables effective modeling of dependencies between input and output sequences.
- Encoder Self-Attention: Each position in the self-attention layers of the encoder can attend to all positions in the previous layer. It captures dependencies within the input sequence.
- Decoder Self-Attention: Similar to the encoder self-attention, the decoder self-attention allows each position in the decoder to attend to all positions up to and including itself. However, leftward information flow is prevented to maintain the auto-regressive property.

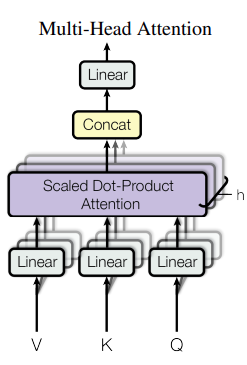
The attention function used in the Transformer model is the “Scaled Dot-Product Attention”. It involves computing the dot products of queries, keys, and values. This is followed by scaling and applying a softmax function to obtain weighted sums of the values. Multi-head attention is also employed. This in turn allows the model to jointly attend to different representation subspaces at different positions.
Positional Encoding
Since the Transformer model lacks recurrence and convolutions, it requires a mechanism to capture the order of tokens in a sequence. To address this, the model incorporates positional encodings into the input embeddings. These encodings provide information about the relative or absolute position of tokens. Such an encoding technique allows the model to make use of sequence order. The positional encodings are added to the input embeddings. This enables the model to learn attention-based dependencies based on position.
Pretraining Tasks and Results using the Transformer Neural Network
Pretraining plays a crucial role in the success of deep learning models. In the case of the Transformer, the authors explored various pretraining tasks, including language modeling, machine translation, and more. By leveraging large-scale datasets and pretraining on diverse tasks, the Transformer achieves impressive results in subsequent downstream tasks.
- When applied to machine translation tasks, the Transformer surpasses existing models in terms of translation quality. This results in the Transformer network even outperforming ensemble models. Notably, the Transformer achieved a BLEU score of 28.4 on the WMT 2014 English-to-German translation task, surpassing all previous results by a significant margin. The Transformer network even surpasses the previous model on the WMT 2014 English-to-French translation task. It achieves a BLEU score of 41.0 on this task.
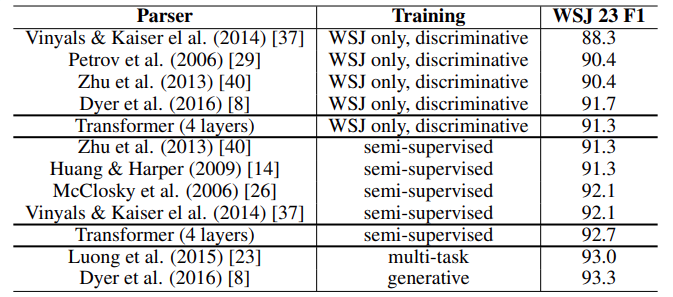
- The authors also trained the model for English Constituency Parsing. It is essentially the task of breaking down an English sentence into its sub-parts or phrases. The model was trained on the Wall Street Journal (WSJ) portion of the Penn Treebank dataset. It beats most of the previous models even without task specific tuning as it generalizes well to English constituency parsing
Transformer Model Variations
The authors varied the base Transformer model and trained it on the English-to-German translation task. Essentially, we can vary the model size by changing the:
- Number of transformer layers
- Number of attention heads
- The embedding dimension
Further, we can also control the overfitting of the larger versions of the model by changing the dropout rate.

We can see in the above table how changing various parameters of the Transformer model affects the BLEU scores and the number of parameters in the model.
Tasks Enabled by the Transformer Neural Network
The Transformer model’s versatility extends beyond machine translation and language modeling. Its self-attention mechanisms and parallelization capabilities make it suitable for various sequence-based tasks. These include:
- Text summarization
- Question answering
- Sentiment analysis, and more.
The Transformer neural network has shown promising results in the above domains. Moving ahead, the Transformer network will keep showing its potential for advancing the field of NLP.
Conclusion
The Transformer neural network has emerged as a revolutionary approach in sequence transduction tasks. By leveraging attention mechanisms and dispensing with recurrence and convolutions, the Transformer achieves state-of-the-art results in machine translation and other NLP tasks. Its ability to capture long-range dependencies and parallelize computations sets a new standard for sequence modeling. As researchers continue to explore and refine this model, the Transformer’s impact on the field of NLP is expected to grow exponentially.
The Transformer paper by Vaswani et al. represents a significant milestone in deep learning research, opening up new avenues for sequence transduction and inspiring further exploration in the field. As the Transformer continues to evolve and find applications in various domains, its transformative power will undoubtedly shape the future of NLP.
I hope this article was useful to you.
If you have any doubts, thoughts, or suggestions, please leave them in the comment section. I will surely address them.
You can contact me using the Contact section. You can also find me on LinkedIn, and X.
References
Further Reading

20 thoughts on “Transformer Neural Network: Revolutionizing Sequence Transduction”