
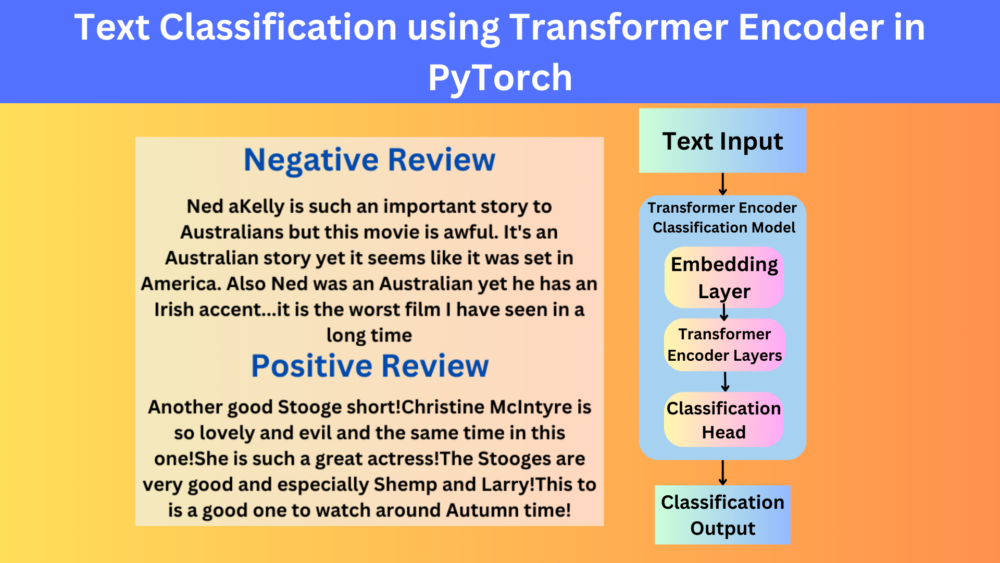
In this blog post, we will use the Transformer encoder model for text classification.
The original transformer model by Vaswani et al. was an encoder-decoder model. Such models are excellent for language translation tasks. However, in some cases, only the encoder or the decoder part of the transformer works better. One such task is text classification. For text classification, although we can use the entire transformer model, an encoder-only network with a classifier head works much better.
That is what we will accomplish in this blog post. We will build an encoder-only network that is true to the original transformer language model and use it for text classification. We will use PyTorch nn.TransformeEncoderLayer and nn.TransformerEncoder to build the neural network.

We will cover the following points in this blog post
- To carry out the text classification using the transformer encoder, we will use the IMDb movie review dataset. So, we will start with a discussion of the dataset.
- Next, we will move on to the Jupyter Notebook that contains the code. Here, we will mostly focus on the encoder-only transformer model preparation part.
- After training the model, we will also run testing and inference. The testing will happen on a held-out set of the IMDb dataset. For inference, we will pick out some real movie reviews from the internet.
The IMDb Movie Review Dataset
The IMDb movie review dataset contains several thousand real-life movie reviews. Each movie review may be positive or negative.
You can find the IMDb dataset that we will use on Kaggle. You can go ahead, download, and extract the dataset if you wish running the training on your own. It will extract two directories, aclImdb and imdb_mini. The imdb_mini is a subset of the dataset. However, we will use the full dataset present in aclImdb.
Here is the directory structure of aclImdb.
aclImdb/
└── aclImdb
├── imdbEr.txt
├── imdb.vocab
├── README
├── test
│ ├── labeledBow.feat
│ ├── neg
│ ├── pos
│ ├── urls_neg.txt
│ └── urls_pos.txt
└── train
├── labeledBow.feat
├── neg
├── pos
├── unsup
├── unsupBow.feat
├── urls_neg.txt
├── urls_pos.txt
└── urls_unsup.txt
We are mostly interested in the train and test directories. In the train directory, there is a neg and pos subdirectory. Each of these contain 12500 negative and positive movie review samples respectively in separate text files. While preparaing the dataset, we will use a small subset from the training set for validation.
The test directory is entirey reserved for testing after training the model. Here also, there are 12500 negative and 12500 positive movie review samples.
For now, we can ignore the other files and directories.
Let’s take a look at one positive and one negative movie review.


It’s clear that the reviews can be quite long and comprehensive. We must choose the hyperparameters accordingly while training to get the best possible results.
The Project Directory Structure
The following block contains the entire project directory structure.
├── aclImdb │ └── aclImdb │ ├── test │ ├── train │ ├── imdbEr.txt │ ├── imdb.vocab │ └── README ├── inference_data │ ├── sample_1.txt │ └── sample_2.txt ├── outputs │ ├── accuracy.png │ ├── loss.png │ └── model.pth └── transformer_encoder_classification.ipynb
- The
aclImdbdirectory contains the movie review dataset that we analyzed in the previous section. - We have a few unseen movie review samples in the
inference_datadirectory. Each text file contains one movie review. - The
outputsdirectory will contain all the training outputs. These include the trained model, the accuracy, and the loss plots. - Finally, we have the Jupyter Notebook that contains the code directly inside the project directory.
PyTorch Version
The codebase for this blog post has been developed using PyTorch 2.0.1. You may go ahead and install PyTorch in your environment if you wish to run the notebook for transformer encoder text classification.
The trained weights and the Jupyter Notebook will be available through the download section of this blog post. You can easily run just testing and inference using the trained model.
Text Classification using Transformer Encoder
Let’s start with the coding part of the blog post. While going though the Jupyter Notebook, we will not go through the dataset preparation code explanation in detail. If you wish to get a detailed explanation of the dataset preparation, please go through the Getting Started with Text Classification post. In that post, we go through each and every component of IMDb dataset preparation in detail.
Download Code
In this blog post, we will mostly focus on how to prepare a text classification model using the transformer encoder.
Starting with the import statements, setting seeds, and defining the necessary directory paths.
import torch
import os
import pathlib
import numpy as np
import glob
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import matplotlib.pyplot as plt
import re
import string
import math
from tqdm.auto import tqdm
from collections import Counter
from torch.utils.data import DataLoader, Subset, Dataset
from torch import nn
plt.style.use('ggplot')
# Set seed. seed = 42 np.random.seed(seed) torch.manual_seed(seed) torch.cuda.manual_seed(seed) torch.backends.cudnn.deterministic = True torch.backends.cudnn.benchmark = True
OUTPUTS_DIR = 'outputs'
os.makedirs(OUTPUTS_DIR, exist_ok=True)
data_dir = os.path.join('aclImdb/aclImdb/')
dataset_dir = os.path.join(data_dir)
train_dir = os.path.join(dataset_dir, 'train')
print(os.listdir(dataset_dir))
print(os.listdir(train_dir))
In the above code block, we define an output directory where the trained model and the plots will be stored. Along with that, the data_dir variable holds the path to the dataset root directory.
Defining the Training and Dataset Parameters
Let’s define the training and dataset parameters now.
MAX_LEN = 1024 # Use these many top words from the dataset. If -1, use all words. NUM_WORDS = 32000 # Vocabulary size. # Batch size. BATCH_SIZE = 32 VALID_SPLIT = 0.20 EPOCHS = 30 LR = 0.00001
Going over each of the variables that we have defined above:
MAX_LEN: This is going to be the maximum length of each review to consider while preparing the dataset. If the review is less than 1024 words, we will pad it with 0s and if it is more than 1024 words, then we will truncate it.NUM_WORDS: This is the number of unique words to consider from the entire dataset. The IMDb dataset contains more than 600000 unique words. However, it is not feasible to train a model with these many unique words. So, we will consider 32000 unique words from the entire dataset.BATCH_SIZE: The batch size for the data loaders.VALID_SPLIT: As we will split the training samples into a training and a validation set, we need a define a split. 20% of the samples will be used for validation and the rest for training.EPOCHS: The number of epochs to train for.LR: The learning rate for the optimizer.
Dataset Preparation
Let’s get on with the dataset preparation for training our transformer encoder for text classification.
Finding the Longest and Average Review Length from the IMDb Dataset
The following is a function that finds the longest review among all the training files that we have.
def find_longest_length(text_file_paths):
"""
Find the longest review length in the entire training set.
:param text_file_paths: List, containing all the text file paths.
Returns:
max_len: Longest review length.
"""
max_length = 0
for path in text_file_paths:
with open(path, 'r') as f:
text = f.read()
# Remove <br> tags.
text = re.sub('<[^>]+>+', '', text)
corpus = [
word for word in text.split()
]
if len(corpus) > max_length:
max_length = len(corpus)
return max_length
file_paths = []
file_paths.extend(glob.glob(os.path.join(
dataset_dir, 'train', 'pos', '*.txt'
)))
file_paths.extend(glob.glob(os.path.join(
dataset_dir, 'train', 'neg', '*.txt'
)))
longest_sentence_length = find_longest_length(file_paths)
print(f"Longest review length: {longest_sentence_length} words")
This gives the output as 2450 words. It seems like the longest review is quite comprehensive.
But not all reviews will be that long. The following function finds the average review length from the training set.
def find_avg_sentence_length(text_file_paths):
"""
Find the average sentence in the entire training set.
:param text_file_paths: List, containing all the text file paths.
Returns:
avg_len: Average length.
"""
sentence_lengths = []
for path in text_file_paths:
with open(path, 'r') as f:
text = f.read()
# Remove <br> tags.
text = re.sub('<[^>]+>+', '', text)
corpus = [
word for word in text.split()
]
sentence_lengths.append(len(corpus))
return sum(sentence_lengths)/len(sentence_lengths)
file_paths = []
file_paths.extend(glob.glob(os.path.join(
dataset_dir, 'train', 'pos', '*.txt'
)))
file_paths.extend(glob.glob(os.path.join(
data_dir, 'train', 'neg', '*.txt'
)))
average_length = find_avg_sentence_length(file_paths)
print(f"Average review length: {average_length} words")
Here, the output is 229.70464 words. As it seems, most of the reviews are short.
Finding Word Frequency in Text Documents
We need to find the frequency of all the words from the entire training set so that we can choose the top 32000 words.
def find_word_frequency(text_file_paths, most_common=None):
"""
Create a list of tuples of the following format,
[('ho', 2), ('hello', 1), ("let's", 1), ('go', 1)]
where the number represents the frequency of occurance of
the word in the entire dataset.
:param text_file_paths: List, containing all the text file paths.
:param most_common: Return these many top words from the dataset.
If `most_common` is None, return all. If `most_common` is 3,
returns the top 3 tuple pairs in the list.
Returns:
sorted_words: A list of tuple containing each word and it's
frequency of the format ('ho', 2), ('hello', 1), ...]
"""
# Add all the words in the entire dataset to `corpus` list.
corpus = []
for path in text_file_paths:
with open(path, 'r') as f:
text = f.read()
# Remove <br> tags.
text = re.sub('<[^>]+>+', '', text)
corpus.extend([
word for word in text.split()
])
count_words = Counter(corpus)
# Create a dictionary with the most common word in the corpus
# at the beginning.
# `word_frequency` will be like
word_frequency = count_words.most_common(n=most_common) # Returns all if n is `None`.
return word_frequency
In case you are wondering, here is a sample input sentence and its sample out.
Input:
'A SAMPLE SENTENCE...\n' 'This notebook trains a Transformer encoder model ...\n' 'for text classification using PyTorch Transformer encoder ...\n' 'module'
Output:
[('Transformer', 2), ('encoder', 2), ('...', 2), ('A', 1), ('SAMPLE', 1),
('SENTENCE...', 1), ('This', 1), ('notebook', 1), ('trains', 1), ('a', 1),
('model', 1), ('for', 1), ('text', 1), ('classification', 1), ('using', 1),
('PyTorch', 1), ('module', 1)]
Assigning Integer Indices to Words
We will follow a very naive tokenization technique. We will just assign an integer to each of the top 32000 words.
def word2int(input_words, num_words):
"""
Create a dictionary of word to integer mapping for each unique word.
:param input_words: A list of tuples containing the words and
theiry frequency. Should be of the following format,
[('ho', 2), ('hello', 1), ("let's", 1), ('go', 1)]
:param num_words: Number of words to use from the `input_words` list
to create the mapping. If -1, use all words in the dataset.
Returns:
int_mapping: A dictionary of word and a integer mapping as
key-value pair. Example, {'Hello,': 1, 'the': 2, 'let': 3}
"""
if num_words > -1:
int_mapping = {
w:i+1 for i, (w, c) in enumerate(input_words) \
if i <= num_words - 1 # -1 to avoid getting (num_words + 1) integer mapping.
}
else:
int_mapping = {w:i+1 for i, (w, c) in enumerate(input_words)}
return int_mapping
For the above example, it will return the following output.
{'Transformer': 1, 'encoder': 2, '...': 3, 'A': 4, 'SAMPLE': 5, 'SENTENCE...': 6, '
This': 7, 'notebook': 8, 'trains': 9, 'a': 10, 'model': 11, 'for': 12, 'text': 13,
'classification': 14, 'using': 15, 'PyTorch': 16, 'module': 17}
The Custom Dataset Class for Training the Transformer Encoder Model
The following code block defines an entire dataset class.
class NLPClassificationDataset(Dataset):
def __init__(self, file_paths, word_frequency, int_mapping, max_len):
self.word_frequency = word_frequency
self.int_mapping = int_mapping
self.file_paths = file_paths
self.max_len = max_len
def standardize_text(self, input_text):
# Convert everything to lower case.
text = input_text.lower()
# If the text contains HTML tags, remove them.
text = re.sub('<[^>]+>+', '', text)
# Remove punctuation marks using `string` module.
# According to `string`, the following will be removed,
# '!"#$%&\'()*+,-./:;<=>?@[\\]^_`{|}~'
text = ''.join([
character for character in text \
if character not in string.punctuation
])
return text
def return_int_vector(self, int_mapping, text_file_path):
"""
Assign an integer to each word and return the integers in a list.
"""
with open(text_file_path, 'r') as f:
text = f.read()
text = self.standardize_text(text)
corpus = [
word for word in text.split()
]
# Each word is replaced by a specific integer.
int_vector = [
int_mapping[word] for word in text.split() \
if word in int_mapping
]
return int_vector
def pad_features(self, int_vector, max_len):
"""
Return features of `int_vector`, where each vector is padded
with 0's or truncated to the input seq_length. Return as Numpy
array.
"""
features = np.zeros((1, max_len), dtype = int)
if len(int_vector) <= max_len:
zeros = list(np.zeros(max_len - len(int_vector)))
new = zeros + int_vector
else:
new = int_vector[: max_len]
features = np.array(new)
return features
def encode_labels(self, text_file_path):
file_path = pathlib.Path(text_file_path)
class_label = str(file_path).split(os.path.sep)[-2]
if class_label == 'pos':
int_label = 1
else:
int_label = 0
return int_label
def __len__(self):
return len(self.file_paths)
def __getitem__(self, idx):
file_path = self.file_paths[idx]
int_vector = self.return_int_vector(self.int_mapping, file_path)
padded_features = self.pad_features(int_vector, self.max_len)
label = self.encode_labels(file_path)
return {
'text': torch.tensor(padded_features, dtype=torch.int32),
'label': torch.tensor(label, dtype=torch.long)
}
The above class will clean the text of any HTML tags and return a review and its corresponding label pair. If a review is positive, its label is 1, else it is 0.
If you want to know how to prepare a custom dataset when dealing with CSV files, then take a look at the Disaster Tweet Classification article.
Preparing the Datasets and Data Loaders
The next step is preparing the datasets and the data loaders. For this, first, we need to assemble all the review text files.
# List of all file paths.
file_paths = []
file_paths.extend(glob.glob(os.path.join(
dataset_dir, 'train', 'pos', '*.txt'
)))
file_paths.extend(glob.glob(os.path.join(
dataset_dir, 'train', 'neg', '*.txt'
)))
test_file_paths = []
test_file_paths.extend(glob.glob(os.path.join(
dataset_dir, 'test', 'pos', '*.txt'
)))
test_file_paths.extend(glob.glob(os.path.join(
dataset_dir, 'test', 'neg', '*.txt'
)))
Next, we need to find the word frequency for each word and create an integer mapping for the top 32000 words.
# Get the frequency of all unqiue words in the dataset. word_frequency = find_word_frequency(file_paths) # Assign a specific intenger to each word. int_mapping = word2int(word_frequency, num_words=NUM_WORDS)
Next, create the training, validation, and test sets.
dataset = NLPClassificationDataset(
file_paths, word_frequency, int_mapping, MAX_LEN
)
dataset_size = len(dataset)
# Calculate the validation dataset size.
valid_size = int(VALID_SPLIT*dataset_size)
# Radomize the data indices.
indices = torch.randperm(len(dataset)).tolist()
# Training and validation sets.
dataset_train = Subset(dataset, indices[:-valid_size])
dataset_valid = Subset(dataset, indices[-valid_size:])
dataset_test = NLPClassificationDataset(
test_file_paths, word_frequency, int_mapping, MAX_LEN
)
# dataset_valid = NLPClassificationDataset()
print(f"Number of training samples: {len(dataset_train)}")
print(f"Number of validation samples: {len(dataset_valid)}")
print(f"Number of test samples: {len(dataset_test)}")
As of now, we have 20000 training, 5000 validation, and 25000 test samples respectively.
And finally, we can create the data loaders.
train_loader = DataLoader(
dataset_train,
batch_size=BATCH_SIZE,
shuffle=True,
num_workers=4
)
valid_loader = DataLoader(
dataset_valid,
batch_size=BATCH_SIZE,
shuffle=False,
num_workers=4
)
test_loader = DataLoader(
dataset_test,
batch_size=BATCH_SIZE,
shuffle=False,
num_workers=4
)
You can increase or decrease the batch size depending on the GPU memory that you have available.
In case you are interested in a more advanced post, take a look at Language Translation using PyTorch Transformer. This blog post takes you through an entire process of translating English sentences to French from scratch.
Counting Correct and Incorrect Predictions During Training
Now, we need to define a custom function to calculate the total number of correct and incorrect predictions during training.
def count_correct_incorrect(labels, outputs, train_running_correct):
# As the outputs are currently logits.
outputs = torch.sigmoid(outputs)
running_correct = 0
for i, label in enumerate(labels):
if label < 0.5 and outputs[i] < 0.5:
running_correct += 1
elif label >= 0.5 and outputs[i] >= 0.5:
running_correct += 1
return running_correct
It returns the total number of correct predictions from an entire batch.
The Training and Validation Function
Next are the training and validation functions.
# Training function.
def train(model, trainloader, optimizer, criterion, device):
model.train()
print('Training')
train_running_loss = 0.0
train_running_correct = 0
counter = 0
for i, data in tqdm(enumerate(trainloader), total=len(trainloader)):
counter += 1
inputs, labels = data['text'], data['label']
inputs = inputs.to(device)
labels = torch.tensor(labels, dtype=torch.float32).to(device)
optimizer.zero_grad()
# Forward pass.
outputs = model(inputs)
outputs = torch.squeeze(outputs, -1)
# Calculate the loss.
loss = criterion(outputs, labels)
train_running_loss += loss.item()
running_correct = count_correct_incorrect(
labels, outputs, train_running_correct
)
train_running_correct += running_correct
# Backpropagation.
loss.backward()
# Update the optimizer parameters.
optimizer.step()
# Loss and accuracy for the complete epoch.
epoch_loss = train_running_loss / counter
epoch_acc = 100. * (train_running_correct / len(trainloader.dataset))
return epoch_loss, epoch_acc
# Validation function.
def validate(model, testloader, criterion, device):
model.eval()
print('Validation')
valid_running_loss = 0.0
valid_running_correct = 0
counter = 0
with torch.no_grad():
for i, data in tqdm(enumerate(testloader), total=len(testloader)):
counter += 1
inputs, labels = data['text'], data['label']
inputs = inputs.to(device)
labels = torch.tensor(labels, dtype=torch.float32).to(device)
# Forward pass.
outputs = model(inputs)
outputs = torch.squeeze(outputs, -1)
# Calculate the loss.
loss = criterion(outputs, labels)
valid_running_loss += loss.item()
running_correct = count_correct_incorrect(
labels, outputs, valid_running_correct
)
valid_running_correct += running_correct
# Loss and accuracy for the complete epoch.
epoch_loss = valid_running_loss / counter
epoch_acc = 100. * (valid_running_correct / len(testloader.dataset))
return epoch_loss, epoch_acc
Each of the above functions returns the loss and accuracy for every epoch.
The Transformer Encoder Model for Text Classification
Here comes the most important part of the blog post. We need to define the Transformer Encoder model for text classification. We need to ensure that we connect every component properly to get the best results.
Before preparing the model, we need to define some model parameters.
# Model parameters. EMBED_DIM = 256 NUM_ENCODER_LAYERS = 3 NUM_HEADS = 4
Our model will consist of 256-dimensional embedding, 3 transformer encoder layers, and 4 heads for multi-head attention.
If you need a summary of the original transformer paper, then take a look at the Transformer Neural Network article. It covers all the essential components of the Attention is All You Need paper in a short and concise manner.
Next is the Transformer Encoder Model class.
class EncoderClassifier(nn.Module):
def __init__(self, vocab_size, embed_dim, num_layers, num_heads):
super(EncoderClassifier, self).__init__()
self.emb = nn.Embedding(vocab_size, embed_dim)
self.encoder_layer = nn.TransformerEncoderLayer(
d_model=embed_dim,
nhead=num_heads,
batch_first=True
)
self.encoder = nn.TransformerEncoder(
encoder_layer=self.encoder_layer,
num_layers=num_layers,
)
self.linear = nn.Linear(embed_dim, 1)
self.dropout = nn.Dropout(0.2)
def forward(self, x):
x = self.emb(x)
x = self.encoder(x)
x = self.dropout(x)
x = x.max(dim=1)[0]
out = self.linear(x)
return out
Now, let’s break it down a bit.
- First, we have an embedding layer that creates 256-dimensional embeddings for each word/token.
- Second, we define a nn.TransformerEncoderLayer. This accepts the number of heads that should go into each of the Transformer Encoder layers.
- Third, the nn.TransformerEncoder, accepts an object of the Transformer Encoder Layer and how many such layers to include in the entire model.
Here is the code to initialize the model, print its architecture, and the number of parameters.
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = EncoderClassifier(
len(int_mapping)+1,
embed_dim=EMBED_DIM,
num_layers=NUM_ENCODER_LAYERS,
num_heads=NUM_HEADS
).to(device)
print(model)
# Total parameters and trainable parameters.
total_params = sum(p.numel() for p in model.parameters())
print(f"{total_params:,} total parameters.")
total_trainable_params = sum(
p.numel() for p in model.parameters() if p.requires_grad)
print(f"{total_trainable_params:,} training parameters.\n")

All in all, we just use the encoder part of the Transformer model for text encoding, attach a linear layer for text classification, and entirely ditch the transformer decoder block.
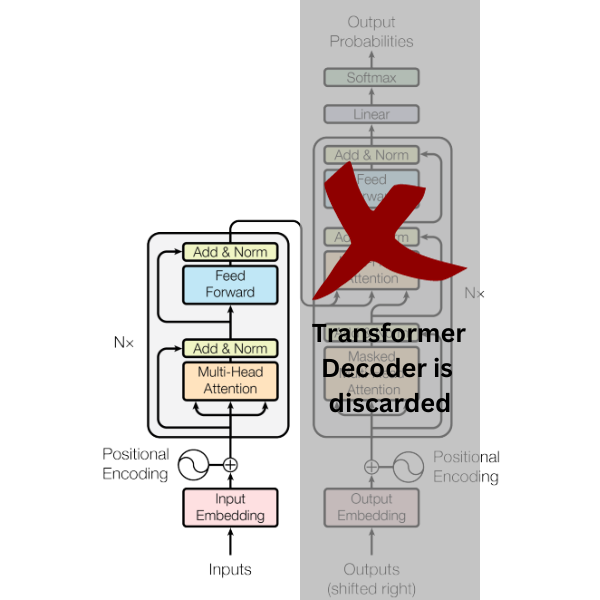
Defining the Loss Function, Optimizer, and Starting the Training
The next code block defines the BCE loss function and the Adam Optimizer.
criterion = nn.BCEWithLogitsLoss()
optimizer = optim.Adam(
model.parameters(),
lr=LR,
)
Next, we start the training for the specified number of epochs.
# Lists to keep track of losses and accuracies.
train_loss, valid_loss = [], []
train_acc, valid_acc = [], []
least_loss = float('inf')
# Start the training.
for epoch in range(EPOCHS):
print(f"[INFO]: Epoch {epoch+1} of {EPOCHS}")
train_epoch_loss, train_epoch_acc = train(model, train_loader,
optimizer, criterion, device)
valid_epoch_loss, valid_epoch_acc = validate(model, valid_loader,
criterion, device)
train_loss.append(train_epoch_loss)
valid_loss.append(valid_epoch_loss)
train_acc.append(train_epoch_acc)
valid_acc.append(valid_epoch_acc)
print(f"Training loss: {train_epoch_loss}, training acc: {train_epoch_acc}")
print(f"Validation loss: {valid_epoch_loss}, validation acc: {valid_epoch_acc}")
# Save model.
if valid_epoch_loss < least_loss:
least_loss = valid_epoch_loss
print(f"Saving best model till now... LEAST LOSS {valid_epoch_loss:.3f}")
torch.save(
model, os.path.join(OUTPUTS_DIR, 'model.pth')
)
print('-'*50)
It saves the model whenever the model reaches a new least loss. So, in the end, we will have the best possible model with us.
The model reached the best results on epoch 29. It achieved a validation accuracy of 88.039% and a validation loss of 0.289. These results are very good considering that we do not have a pretrained model. The entire model is trained from scratch.
Here are the accuracy and loss plots from training the Transformer Encoder model.
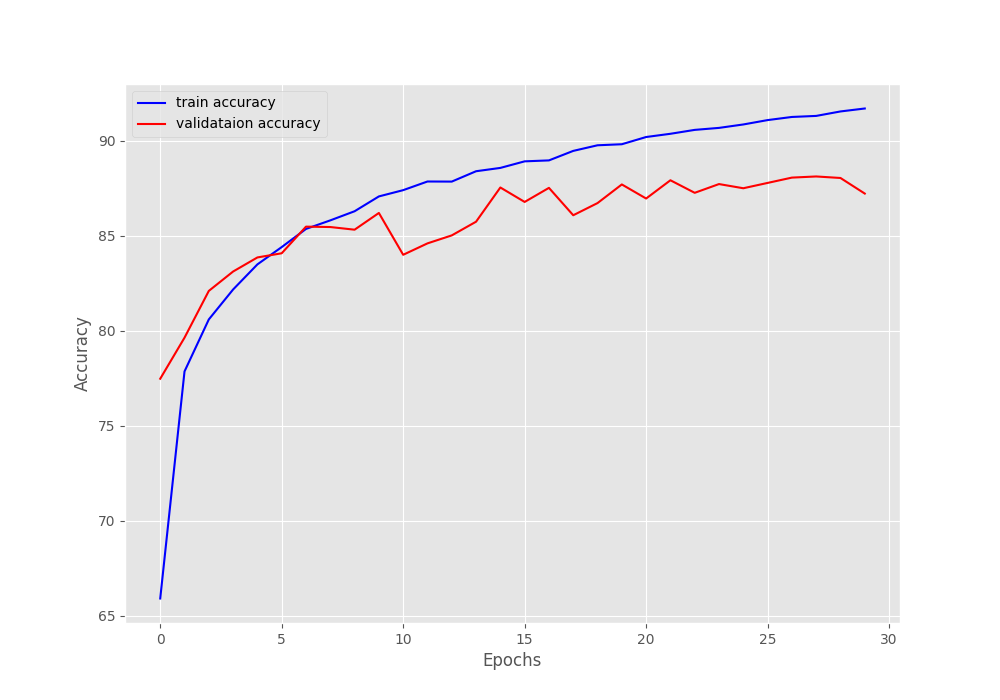
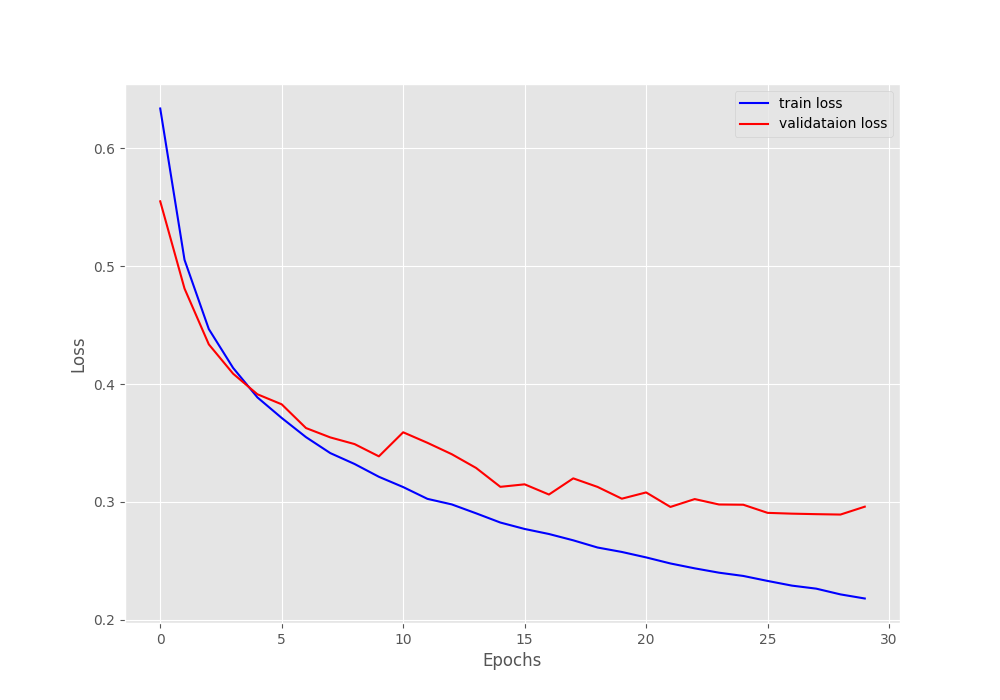
It looks like if we apply a learning rate scheduler, we can train the model for a bit longer.
Test and Inference
Now, let’s load the best model that we have and run it on the test dataset that we prepared earlier.
trained_model = torch.load(
os.path.join(OUTPUTS_DIR, 'model.pth')
)
test_loss, test_acc = validate(
trained_model,
test_loader,
criterion,
device
)
print(f"Test loss: {test_loss}, test acc: {test_acc}")
The test accuracy is 87.288% and the test loss is 0.297. Both of them are very close to the best validation accuracy and loss respectively.
Inference
For inference, there are a few text file samples in the inference_data directory. You can add more if you wish. As of now, one is a positive review and one is a negative review.
Let’s read the files and store the reviews in a list.
# A few real-life reviews taken from the internet.
sentences = []
infer_dir = 'inference_data/'
infer_data = os.listdir(infer_dir)
for data in infer_data:
f = open(f"{infer_dir}/{data}", 'r')
sentences.append(f.read())
There is a need for two helper functions here.
- One is to convert the text to integer vectors.
- Another is for padding the short vectors to the desired length.
def return_int_vector(int_mapping, text):
"""
Assign an integer to each word and return the integers in a list.
"""
corpus = [
word for word in text.split()
]
# Each word is replaced by a specific integer.
int_vector = [
int_mapping[word] for word in text.split() \
if word in int_mapping
]
return int_vector
def pad_features(int_vector, max_len):
"""
Return features of `int_vector`, where each vector is padded
with 0's or truncated to the input seq_length. Return as Numpy
array.
"""
features = np.zeros((1, max_len), dtype = int)
if len(int_vector) <= max_len:
zeros = list(np.zeros(max_len - len(int_vector)))
new = zeros + int_vector
else:
new = int_vector[: max_len]
features = np.array(new)
return features
Finally, we loop over the sentence and carry out the inference.
for sentence in sentences:
int_vector = return_int_vector(int_mapping, sentence)
padded_features = pad_features(int_vector, int(longest_sentence_length))
input_tensor = torch.tensor(padded_features, dtype=torch.int32)
input_tensor = input_tensor.unsqueeze(0)
with torch.no_grad():
output = trained_model(input_tensor.to(device))
preds = torch.sigmoid(output)
print(sentence)
print(f"Score: {preds.cpu().numpy()[0][0]}")
if preds > 0.5:
print('Prediction: POSITIVE')
else:
print('Prediction: NEGATIVE')
print('\n')
Following are the results.

It seems that the trained Transformer Encoder model is able to classify both reviews correctly.
For further experiments, you can play with the parameters while creating the model and see how it performs.
Summary and Conclusion
In this blog post, we trained a Transformer Encoder model for text classification. We went through the entire process of dataset and model preparation. This gave us an idea of how to use the encoder part of the Transformer architecture creating a high accuracy classifier. I hope that this blog post was worth your time.
If you have any doubts, thoughts, or suggestions, please leave them in the comment section. I will surely address them.
You can contact me using the Contact section. You can also find me on LinkedIn, and X.
