
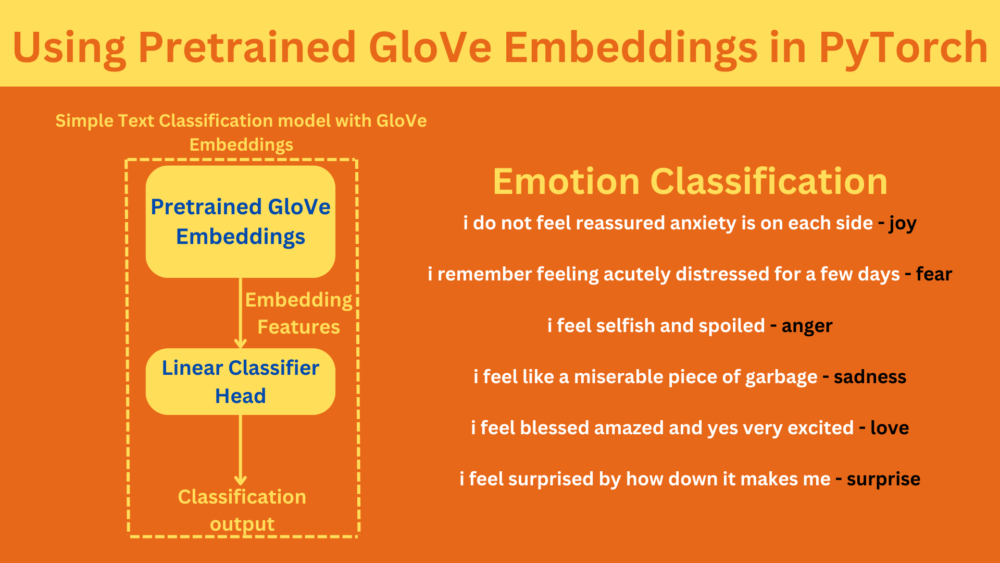
Nowadays, everything in NLP is either complex or large. With Large Language Models (LLMs) taking the front seat, models are bigger than ever, datasets are huge, and tasks are complex. Even for some simple tasks in NLP, it is much better to start with something pretrained and fine-tune it. In this article, although we will not deal with LLMs or huge datasets, we will start with something simpler. We will use pretrained GloVe embeddings for text classification in PyTorch. Although not too complex, it is essential to know what we can achieve with simple pretrained embeddings already available in PyTorch and not relying on multi-hundred million parameter models.

We will use the pretrained GloVe embeddings to build a very simple text classification neural network. Then we will train it on two different datasets and analyze the results.
Here are all the points that we will cover in the post:
- We will start with building the text classification neural network using pretrained GloVe embeddings in PyTorch. We will use the torchtext library for this.
- Next, we will train on two different datasets. One is an emotion classification dataset, and the other is the classic IMDB movie review classification dataset. Both of these will have their own notebooks.
- After each training, we will analyze the results and run inference as well.
Note: We will not go into the details of the GloVe embeddings but only some basisc information in this tutorial. We will cover how to use these pretrained embeddings for our use case in text classification.
The Text Classification Datasets for Training GloVe Embeddings
As discussed above, we will train the model built using the pretrained GloVe embeddings on two different datasets.
The Emotion Classification Dataset
The first dataset is a 6 class emotion classification dataset from Kaggle.
It contains three text files: train.txt, val.txt, and test.txt.
Each file contains a sentence followed by a semicolon, then the class name. All the new emotion sentences are separated by a new line.
The following figure will clear things out.

The 6 emotion classes are:
- anger
- fear
- joy
- love
- sadness
- surprise
Here is an image showing a sample sentence from each class.

As we can see, it is not always that easy to figure out the emotion of each sentence. Hopefully, the neural network with pretrained GloVe embeddings will do a much better job.
The IMDB Movie Review Dataset
The second dataset is the classic IMDB movie review dataset. This is also available on Kaggle. This particular version also contains a mini sample set for trying out smaller models. But we will deal with the large dataset in this aricle.
The complete set contains 25000 training and 25000 test samples, distributed among two classes, positive and negative reviews.
Out of the 25000 training samples, we will use 20000 for training and 5000 for validation. We will reserve the original 25000 test set for testing the model after training.
Here is one sample sentence from each of the classes.

It is clear that the reviews can be quite long as they are real user reviews for different movies.
Directory Structure
Let’s take a look at the entire project directory structure.
├── data │ ├── aclImdb │ │ └── aclImdb │ │ ├── test │ │ │ ├── neg │ │ │ ├── pos │ │ │ ├── labeledBow.feat │ │ │ ├── urls_neg.txt │ │ │ └── urls_pos.txt │ │ ├── train │ │ │ ├── neg │ │ │ ├── pos │ │ │ ├── unsup │ │ │ ├── labeledBow.feat │ │ │ ├── unsupBow.feat │ │ │ ├── urls_neg.txt │ │ │ ├── urls_pos.txt │ │ │ └── urls_unsup.txt │ │ ├── imdbEr.txt │ │ ├── imdb.vocab │ │ └── README │ └── emotions_dataset │ ├── test.txt │ ├── train.txt │ └── val.txt ├── outputs │ ├── emotions_dataset │ │ ├── accuracy.png │ │ ├── loss.png │ │ └── model.pth │ └── imdb_dataset │ ├── accuracy.png │ ├── loss.png │ └── model.pth ├── emotion_classification.ipynb ├── imdb_review_classification.ipynb └── model.py
- The
datadirectory contains both datasets. TheaclImdb/aclImdbfolder contains the training and test set. In each of these folders, the negative and positive review text files are present inside their respective class directories. For theemotions_datasetdirectory, all the samples are present inside respective text files. - Next, the
outputsdirectory contains training outputs such as the graphs, and trained models for each dataset. - Then, directly inside the parent project directory, we have two Jupyter Notebooks, for each of the datasets, and a single
model.pyfile where the model code is present.
If you wish to run the training yourself, please download the dataset from the above links. If you wish to run inference only, the pretrained models are available via the download link.
PyTorch and Torchtext Version
The code for this article was developed using PyTorch 2.0.1 and Torchtext 0.15.2. Be sure to install these in case you want to run the code locally.
A Few Basics on GloVe Embeddings
GloVe stands for Global Vectors for Word Representation.
In simple words, it is an unsupervised algorithm that learns the meanings and connections between words. After training a GloVe algorithm, it is possible to save it as a model and use it for fine-tuning purposes in NLP. It is useful because it has already learned the meanings and connections between millions and billions of words and can work very well even on large datasets.
Basically, the GloVe algorithm assigns a vector representation to each word. For example, the so-called 50-dimensional GloVe algorithm (or model) will convert a word into a vector containing 50 numbers. While training the GloVe algorithm, these vector representations for each word are continuously tuned till it learns the connections with other words and the meaning of the words.
As such, there are several pretrained versions of the GloVe algorithm available in Torchtext trained on different sizes of data.

For our purpose, we will use the glove.6B.50d version. This has been trained on 6 billion tokens, spanning 400,000-word vocabulary, and converts each word into a 50-dimensional vector.
We will keep the discussion of GloVe till this much in the article. We will cover GloVe embeddings in more detail possibly in a separate article.
Using Pretrained GloVe Embeddings in PyTorch for Text Classification
Let’s get into the technical concepts now. We will discuss a few parts of the data preparation and cleaning for each of the training experiments. But we will not go into the details of notebooks. That would be too verbose. If you are interested you can take a look at the Getting Started with Text Classification article. The code for each of the training experiments is very similar to that article except for minor changes. You may also take a look at Disaster Tweet Classification if you want to know how to deal with a different text classification dataset.
First of all, let’s get into the model preparation code.
Download Code
Preparing a Simple Text Classification Model using Glove Embeddings
The code for preparing the model is present in the model.py file. The following code block contains the entire code for model preparation.
import torch.nn as nn
import torch
import torch.nn.functional as F
from torchtext.vocab import GloVe
class GloveModel(nn.Module):
def __init__(self, embed_dim, num_classes):
super(GloveModel, self).__init__()
global_vectors = GloVe(name='6B', dim=embed_dim)
glove_weights = torch.load(f".vector_cache/glove.6B.{embed_dim}d.txt.pt")
self.embedding = nn.Embedding.from_pretrained(glove_weights[2])
self.linear1 = nn.Linear(embed_dim, num_classes)
self.dropout = nn.Dropout(0.3)
def forward(self, x):
x = self.embedding(x)
x = self.dropout(x)
x = x.max(dim=1)[0]
out = self.linear1(x)
return out
One of the important imports here is the GloVe from torchtext. This gives us access to all the pretrained GloVe embeddings.
In the GloveModel class, we pass the embed_dim as a parameter. We download the respective GloVe embeddings based on this embedding dimension. For example, if embed_dim=50, then we download the glove.6B.50d version (line 10).
This will download a PyTorch file (.pt extension) inside .vector_cache in the current working directory. The next line (line 11) actually loads the GloVe embeddings by extracting the embeddings into the glove.6B.50d.txt file. The contents of this file are different words along with their embeddings. Each word and respective embeddings are separated by a new line. Following is an example.
and 0.26818 0.14346 -0.27877 0.016257 0.11384 0.69923 -0.51332 -0.47368 -0.33075 -0.13834 0.2702 0.30938 -0.45012 -0.4127 -0.09932 0.038085 0.029749 0.10076 -0.25058 -0.51818 0.34558 0.44922 0.48791 -0.080866 -0.10121 -1.3777 -0.10866 -0.23201 0.012839 -0.46508 3.8463 0.31362 0.13643 -0.52244 0.3302 0.33707 -0.35601 0.32431 0.12041 0.3512 -0.069043 0.36885 0.25168 -0.24517 0.25381 0.1367 -0.31178 -0.6321 -0.25028 -0.38097 in 0.33042 0.24995 -0.60874 0.10923 0.036372 0.151 -0.55083 -0.074239 -0.092307 -0.32821 0.09598 -0.82269 -0.36717 -0.67009 0.42909 0.016496 -0.23573 0.12864 -1.0953 0.43334 0.57067 -0.1036 0.20422 0.078308 -0.42795 -1.7984 -0.27865 0.11954 -0.12689 0.031744 3.8631 -0.17786 -0.082434 -0.62698 0.26497 -0.057185 -0.073521 0.46103 0.30862 0.12498 -0.48609 -0.0080272 0.031184 -0.36576 -0.42699 0.42164 -0.11666 -0.50703 -0.027273 -0.53285
If we count the space separated numbers, we realize that there are 50 numbers for each word. This corresponds to the dimension of the embedding that we are using which is 50-dimensional.
Then we create an Embedding layer using the nn module. But we need to use the from_pretrained method to load the pretrained GloVe embeddings instead of initializing the layer from scratch. It accepts the weights which are present in the third dimension (glove_weights[2] because of 0-indexing). Its output is 50-dimensional corresponding to the embedding that we are using. The next layer is simply a linear layer. It has to have 50 input features because of the previous layer. The output features correspond to the number of classes that we have in the dataset. We can have more linear layers but we keep it simple for now.
The forward() method is simple. We just pass the input through each of the layers. Instead of average pooling, we use the maximum values from each tensor row before passing them to the linear layer.
Emotion Classification Training
First, we will go through the emotion classification dataset. Although we will not discuss the code in detail, still, we will go through the insights gained from the dataset preparation in each notebook.
The Dataset Statistics and Hyperparameters
We first have a key value mapping for each of the labels.
emotion_map = {
'anger': 0,
'fear': 1,
'joy': 2,
'love': 3,
'sadness': 4,
'surprise': 5
}
We already know that the dataset contains 6 classes. Along with that, in the notebook, there are functions to find the longest and average sentence length. The longest sentence contains 66 words and the average sentence length is 19.16 words.
We need the above statistics to clearly define the hyperparameters while preparing the data loaders and datasets.
In fact, while creating the dataset, we limit each tensor length to 66 (the longest sentence available). Any sentence shorter than this will be padded with zeros from the left.
The following is one of the tensors from the data loader.
{'text': tensor([ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 1, 138, 2, 678], dtype=torch.int32), 'label': tensor(4)}
The text key contains the sentence tensor, and the label key contains the label tensor.
Furthermore, for training, we choose a batch size of 1024 and will be training for 50 epochs.
Training Results for Emotion Classification
We use the Adam optimizer with a learning rate of 0.005. The loss function is Cross Entropy loss as it is a multi-class classification problem. During training, we save the best model according to the least validation loss.
The final model that we have consists of just over 40 million parameters. Also, we make all the parameters trainable.
Here is the truncated output:
[INFO]: Epoch 1 of 50 Training 100% 16/16 [00:00<00:00, 21.49it/s] Validation 100% 2/2 [00:00<00:00, 22.37it/s] Training loss: 1.7001921609044075, training acc: 30.881249999999998 Validation loss: 1.617775022983551, validation acc: 34.8 Saving best model till now... LEAST LOSS 1.618 -------------------------------------------------- . . . ------------------------------------------------- [INFO]: Epoch 33 of 50 Training 100% 16/16 [00:00<00:00, 66.06it/s] Validation 100% 2/2 [00:00<00:00, 17.50it/s] Training loss: 0.06901628873310983, training acc: 98.14375 Validation loss: 0.3358158618211746, validation acc: 88.05 Saving best model till now... LEAST LOSS 0.336 -------------------------------------------------- . . . [INFO]: Epoch 50 of 50 Training 100% 16/16 [00:00<00:00, 68.34it/s] Validation 100% 2/2 [00:00<00:00, 19.95it/s] Training loss: 0.041554856579750776, training acc: 98.8125 Validation loss: 0.3529830425977707, validation acc: 88.35 --------------------------------------------------
The best model was saved on epoch 33 with a validation accuracy of 88.05% and a validation loss of 0.336.
The following are the loss and accuracy graphs from the training.
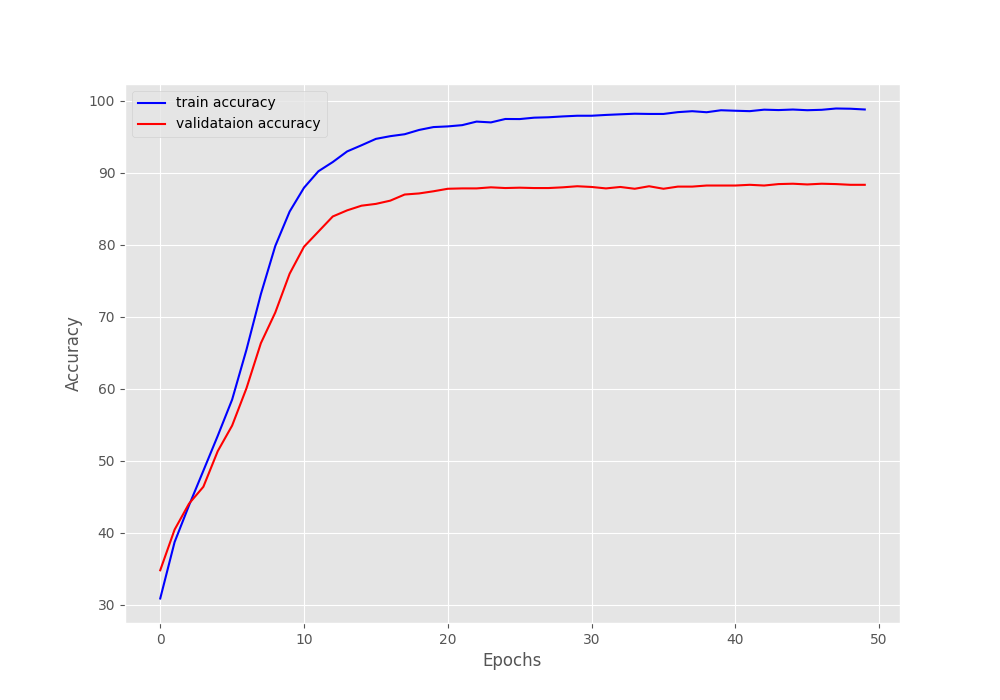
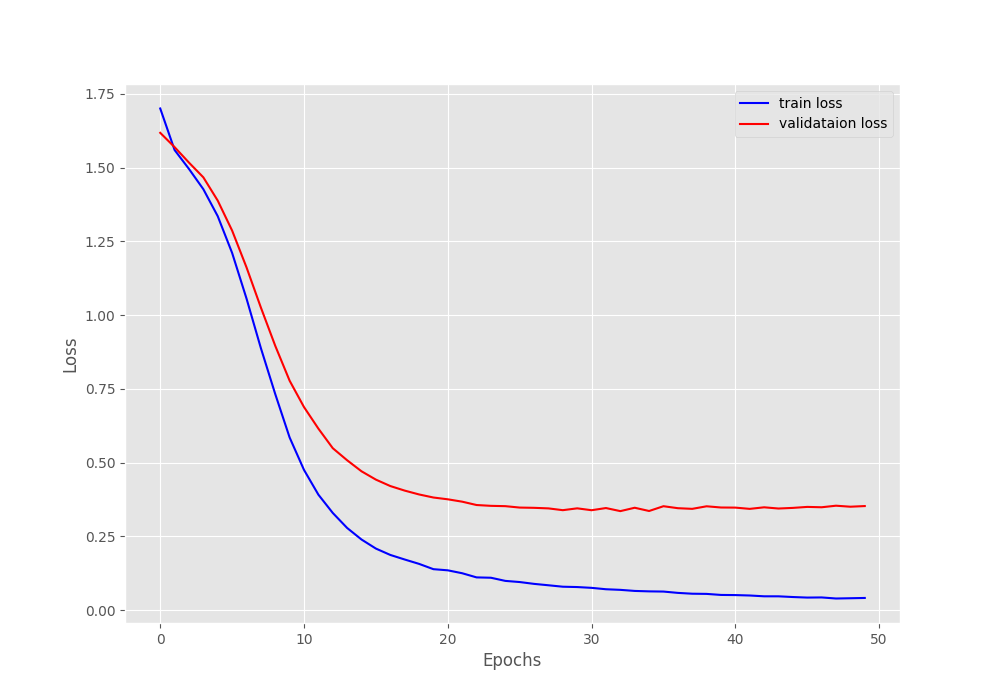
We can see that the plots have certainly plateaued out and we cannot improve the accuracy anymore without proper regularization.
Emotion Classification Inference
Let’s take a few sentences from the test set (test.txt) and run inference on them. The notebook contains the inference section after training. We have taken one sentence from each class.
These are the results from the output cell.
im feeling rather rotten so im not very ambitious right now sadness i am feeling totally relaxed and comfy joy i don t have to go around questioning broads or feeling suspicious fear i lie down he feels my belly listens to babys heartbeat gets mad at me for sitting up without rolling onto my side first and then tells me theres some protein in my urine nothing to be worried about though and asks if anything is bothering me anger i dont blame it all to them and im not angry at them infact i feel fairly sympathetic for them love i think or feel but like this person i am still amazed by them surprise
The inference predictions are below each sentence. As we can see, all the predictions are correct. You can easily compare them by opening the test.txt file and checking the label for each sentence.
IMDB Movie Review Classification Training using Pretrained GloVe Embeddings
The IMDB movie review classification has a very similar training pipeline apart from the dataset preparation part. As the movie reviews contain a lot of HTML tags, there is an additional preprocessing step.
Further, in this case, we have the longest review of 2450 words and the average review length is 229.70 words.
In this case, we split the data in the training folder to have 80-20 training and validation split. Also, we train for 100 epochs with a learning rate of 0.001.
We treat this as a binary classification problem and write our own function to find binary accuracy.
IMDB Movie Review Classification Training Results
The model reached the highest validation accuracy of 84.68% and a validation loss of 0.342 on epoch 91.
INFO]: Epoch 1 of 100 Training 100% 20/20 [00:02<00:00, 11.45it/s] Validation 100% 5/5 [00:00<00:00, 9.42it/s] Training loss: 0.6976423025131225, training acc: 52.05 Validation loss: 0.6939037442207336, validation acc: 50.9 Saving best model till now... LEAST LOSS 0.694 -------------------------------------------------- . . . [INFO]: Epoch 91 of 100 Training 100% 20/20 [00:02<00:00, 10.06it/s] Validation 100% 5/5 [00:00<00:00, 8.90it/s] Training loss: 0.11710701510310173, training acc: 96.585 Validation loss: 0.34183603525161743, validation acc: 84.68 Saving best model till now... LEAST LOSS 0.342 -------------------------------------------------- . . . [INFO]: Epoch 100 of 100 Training 100% 20/20 [00:02<00:00, 10.95it/s] Validation 100% 5/5 [00:00<00:00, 9.27it/s] Training loss: 0.0998268373310566, training acc: 97.07000000000001 Validation loss: 0.3431320071220398, validation acc: 84.94 --------------------------------------------------
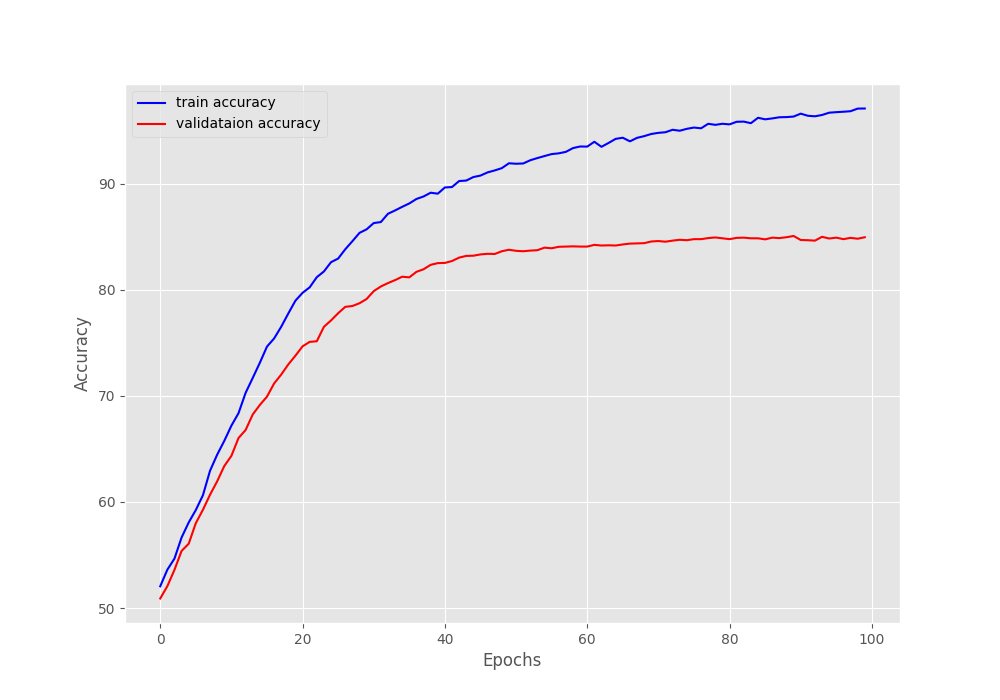
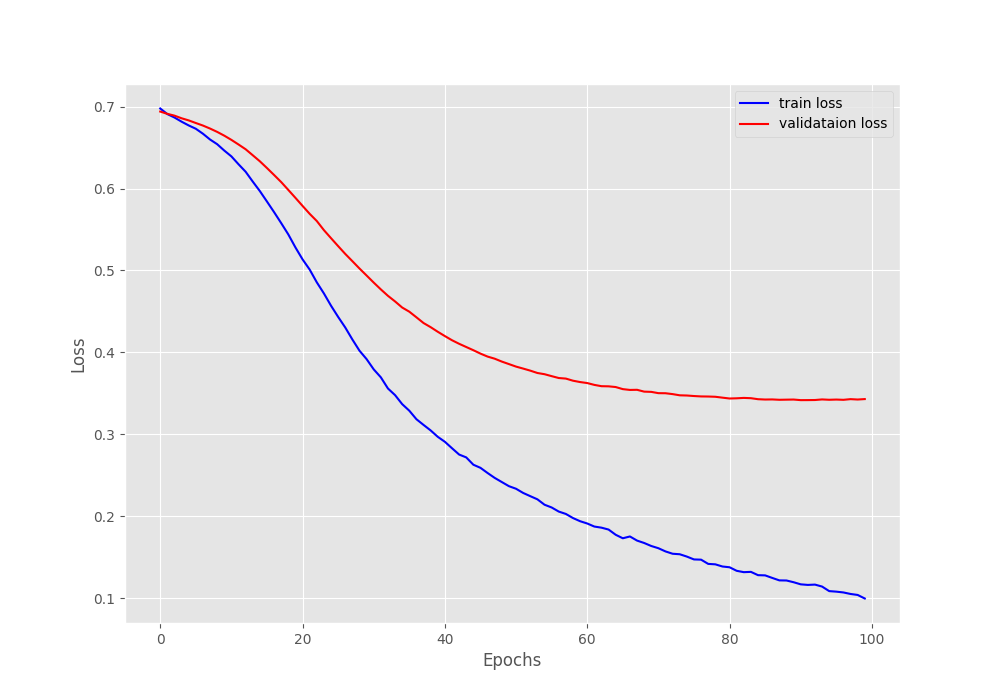
It is clear from the above graphs that the training results won’t improve any further using the current hyperparameters. But there is a large gap between the training and validation lines. Most probably, we need a better model. Maybe a GloVe embeddings with larger dimension.
IMDB Review Inference
We have two unique sentences from the internet for inference. The first one is a positive review and the second one is a negative review.
The following block shows the results.
Freakin fantastic . The darkest most foreboding Batman in cinema.The team didn’t default to rehashing old ground. It was a ride from start to finish. Prediction: POSITIVE Stops being watchable after 1 hour. Boring slog ensues pepperedwith woke clichés. It also blatantly copied other superior movies'sets such as Blade Runner (crowded city scenes) and the Joker(subway scenes) for examples. Dialogues are unbearable to listen to past half the movie. Prediction: NEGATIVE
This time too, the model predictions are correct.
What’s Next?
You can try training on much larger and more difficult datasets and see how the model performs when using pretrained GloVe embeddings. You will surely find some interesting insights.
Summary and Conclusion
In this article, we used the pretrained GloVe embeddings to build a simple neural network for text classification. As we carried out two training experiments for text classification we got to know how effective they are. I hope that this article was useful for you.
If you have any doubts, thoughts, or suggestions, please leave them in the comment section. I will surely address them.
You can contact me using the Contact section. You can also find me on LinkedIn, and X.
References

2 thoughts on “Using Pretrained GloVe Embeddings in PyTorch”