

In this article, we will be training the LRASPP MobileNetV3 on the Indian Driving Dataset subset for semantic segmentation.
In the last article, we fine-tuned the LRASPP MobileNetV3 on the KITTI dataset. However, we found that training smaller models, like LRASPP MobileNetV3 requires a large amount of data. For this, we will experiment with a subset of the Indian Driving Dataset in this article. We will use the semantic segmentation version of the Indian Driving Dataset (IDD) for training the model.

This is the second article in the series. In the next article, we will train on the entire IDD semantic segmentation dataset and export the model to ONNX format for optimized inference on both CPU and GPU.
- Fine Tuning LRASPP MobileNetV3 on the KITTI Segmentation Dataset (Part 1)
- Training LRASPP MobileNetV3 on Indian Driving Dataset Subset for Semantic Segmentation (This article)
We will cover the following points in this article
- We will start with the exploration of the Indian Driving Dataset for semantic segmentation.
- Next, we will explore the necessary source code components. This includes:
- The dataset preparation.
- Augmentations applied to the dataset.
- And training hyperparameters and settings.
- Then we will be training the LRASPP MobileNetV3 on the Indian Driving Dataset subset for semantic segmentation.
- After obtaining the trained models, we will run inference on real-life driving scenes.
Note: This article primarily aims to prepare a subset of the Indian Driving Dataset for Semantic Segmentation and kickstart the training experiments with the right hyperparameters. We will also explore the dataset in detail.
The Indian Driving Dataset Subset for Semantic Segmentation
The Indian Driving Dataset by IIIT Hyderabad contains several vision datasets sourced from cities across India. We are focusing on the semantic segmentation dataset here.
The semantic segmentation dataset contains two sets on the original website, part 1 and part 2. Part 2 is a smaller set containing around 6000 training images. We will use this set, however, from this page on Kaggle.
The Kaggle dataset contains the following components.
- The RGB images for training, validation, and testing and their corresponding JSON files.
- The grayscale 3-channel labels.
- And finally, the RGB masks as well.
It will be easier for us to work with them and get quickly started with the initial experiments. The primary reason for creating this Kaggle dataset is ease of use. The original dataset from the website contains only the JSON files with several layers of annotations according to the documentation. Furthermore, using the publicly available code to convert the JSON files into label mask images is not straightforward as it has not been updated in a while now. I have modified their source code to generate the grayscale label images from the JSON files and wrote a custom script to generate the RGB masks.
If you wish to train the model on your own, please go ahead and download the dataset from the Kaggle page. You should see the following structure after downloading the dataset.
idd_part_2/
├── test
│ └── images
├── train
│ ├── gray_labels
│ ├── images
│ ├── json
│ └── rgb_labels
└── val
├── gray_labels
├── images
├── json
└── rgb_labels
Exploring the Indian Driving Dataset Samples
The dataset contains 4 levels of label ID hierarchy. The following image from the website depicts it well.
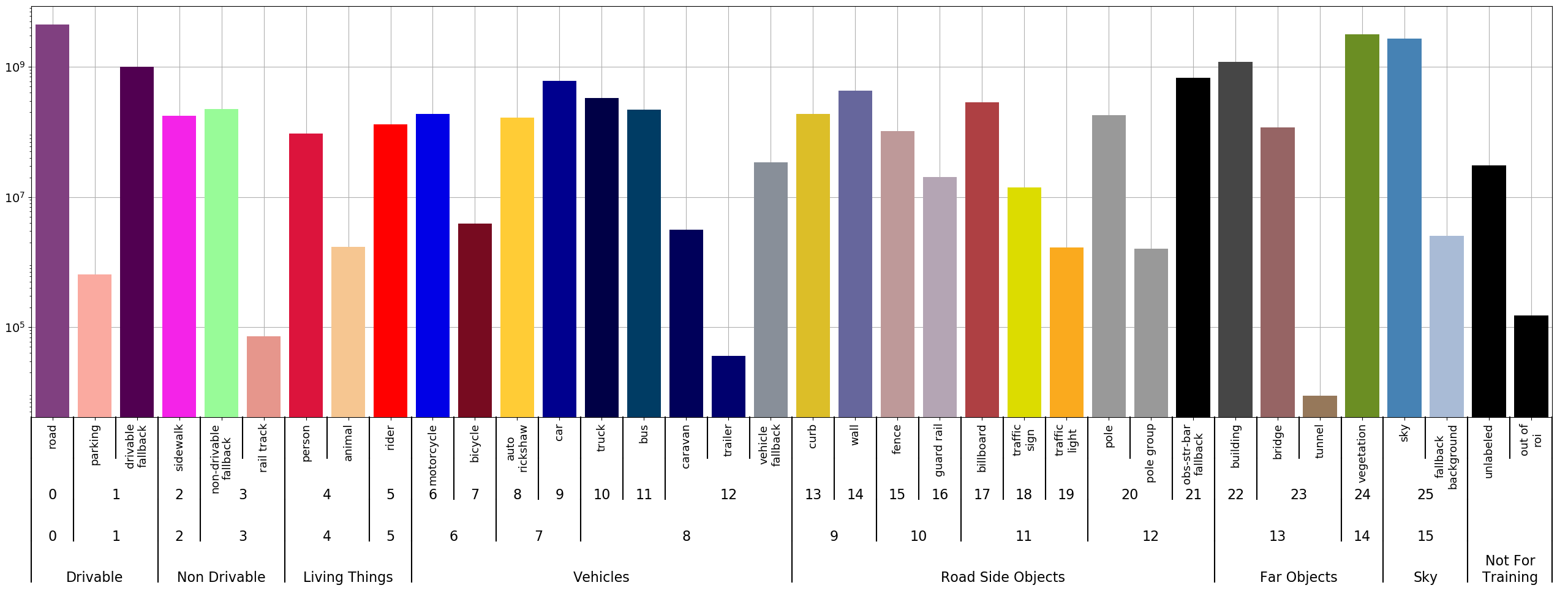
As we can see, the dataset contains supersets and subsets for various objects that can be found on the Indian roads. These include roads, animals, cars, parking areas, and many more real-life objects. Training any model on this dataset should teach it to learn about these scenes.
The version of the dataset that we use here is generated for level 3 of the label IDs containing 27 classes. This means that multiple objects have the same segmentation IDs.
- road
- parking and drivable fallback
- sidewalk
- rail track and non-drivable fallback
- person and animal
- rider
- motorcycle and bicycle
- autorickshaw and car
- truck, bus, caravan, trailer, train, and vehicle fallback
- curb and wall
- fence and guardrail
- billboard, traffic sign, and traffic light
- pole, polegroup, and obs-str-bar-fallback
- building, bridge, and tunnel
- vegetation
- sky and fallback background
- unabeled, ego vehicle, rectification border, out of roi, license plate – these are the void classes
You can find a complete list of the label IDs and their levels here.
Here are a few samples from the dataset along with the level 3 semantic segmentation maps.

In the final dataset that we are using, there are 5996 training samples and 1016 validation samples.
Project Directory Structure
Let’s take a look at the project directory structure.
├── input
│ ├── idd_part_2
│ │ ├── test
│ │ ├── train
│ │ └── val
│ └── inference_data
│ ├── video_1.mov
│ ├── video_2.mov
│ └── video_3.mov
├── outputs
│ ├── idd_lraspp_high_res
│ │ ├── accuracy.png
│ │ ├── best_model_iou.pth
│ │ ├── best_model_loss.pth
│ │ ├── loss.png
│ │ ├── miou.png
│ │ ├── model.pth
│ │ └── valid_preds
│ └── idd_training_lraspp
│ ├── accuracy.png
│ ├── best_model_iou.pth
│ ├── best_model_loss.pth
│ ├── loss.png
│ ├── miou.png
│ ├── model.pth
│ └── valid_preds
├── requirements.txt
└── src
├── config.py
├── datasets.py
├── engine.py
├── inference_image.py
├── inference_video.py
├── label_map_to_rgb.py
├── metrics.py
├── model.py
├── train.py
└── utils.py
- The
inputdirectory contains the training and inference data. We have already seen the structure of theidd_part_2directory in the above section. - The
outputsdirectory will contain all the training and inference results. - All the source code is present in the
srcdirectory. - The
requirements.txtfile contains all the major requirements that we need for this project.
All the source code, trained models, and inference data will be available via the download section. Downloading the dataset and maintaining it in the above structure will be a requirement only if you wish to train the model.
Download Code
Installing Dependencies
It is highly recommended to create a new Anaconda environment for the project. The first major requirement is PyTorch 2.0.1 which we can install using the following command.
conda install pytorch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2 pytorch-cuda=11.8 -c pytorch -c nvidia
Now install the rest of the requirements.
pip install -r requirements.txt
That’s all we need for the setup.
Training LRASPP MobileNetV3 on Indian Driving Dataset Subset
Now, we will focus on the training and inference experiments.
Note: We will not go into the details of the code. The code remains very similar to the previous post in the series with minor changes. However, we will discuss all our hyperparameter choices for dataset preparation and augmentation.
Although the dataset contains the RGB masks, you may go through the label_map_to_rgb.py script to check out how the RGB masks were generated from the grayscale masks. Running the script takes around 2.5 hours on a 10th generation i7 CPU without parallel processing.
All the following training and inference experiments were run on a system with 10GB RTX 3080 GPU, 10th generation i7 CPU, and 32 GB of RAM.
Dataset Preparation and Augmentation
The original images and masks in the dataset are 1920 pixels in width and 1080 pixels in height. We will resize them while training. However, we also apply some image augmentations.
- Horizontal flipping with 0.5 probability
- Random brightness and contrast with 0.2 probability
- Random sun flare with 0.2 probability
- Random fog with 0.2 probability
- Rotation with 0.25 probability
Only flipping and rotation augmentation will be applied to both images and masks. The color level augmentations are only applied to the images. The Albumentations library makes it easy to carry this out. I also recommend going through the datasets.py file if you are interested in diving deep into the dataset preparation process.
If you are interested, you may also read the following articles to know how to augment images for object detection:
- Applying Different Augmentations to Bounding Boxes in Object Detection using Albumentations
- Bounding Box Augmentation for Object Detection using Albumentations
Training Hyperparameters
For training, we are using:
- The Adam optimizer.
- A multi-step learning rate scheduler at epoch 40 with a gamma of 0.1
Additionally, we will also pass a few more parameters while executing the training script.
Executing the Training Script to Train the LRASPP MobileNetV3 Model on the Indian Driving Dataset Subset
We can execute the following script within the src directory to start the training.
python train.py --epoch 50 --lr 0.0005 --batch 8 --height 720 --width 1024 --out idd_training_lraspp --data ../input/idd_part_2/
Let’s go through the command line arguments:
--epochs: We are training for 50 epochs here.--lr: The initial learning rate for the Adam optimizer.--batch: The batch size for the data loaders.--heightand--width: The resolution for training. We are training at quite a high resolution here as that gives the best results for such a small model.--out: The output subdirectory name to be created to store the artifacts in theoutputsdirectory.--data: Path to the root dataset directory.
We are using the Mean IoU as the segmentation metric here. The model reached the best Mean IoU on epoch 49.
-------------------------------------------------- EPOCH: 49 Training 100%|████████████████████| 746/746 [05:37<00:00, 2.21it/s] Validating 100%|████████████████████| 127/127 [00:53<00:00, 2.38it/s] Best validation IoU: 0.4369429753421648 Saving best model for epoch: 49 Train Epoch Loss: 0.2200, Train Epoch PixAcc: 0.9217, Train Epoch mIOU: 0.545448 Valid Epoch Loss: 0.4401, Valid Epoch PixAcc: 0.8685 Valid Epoch mIOU: 0.436943 --------------------------------------------------
Here are the graphs from the training session.
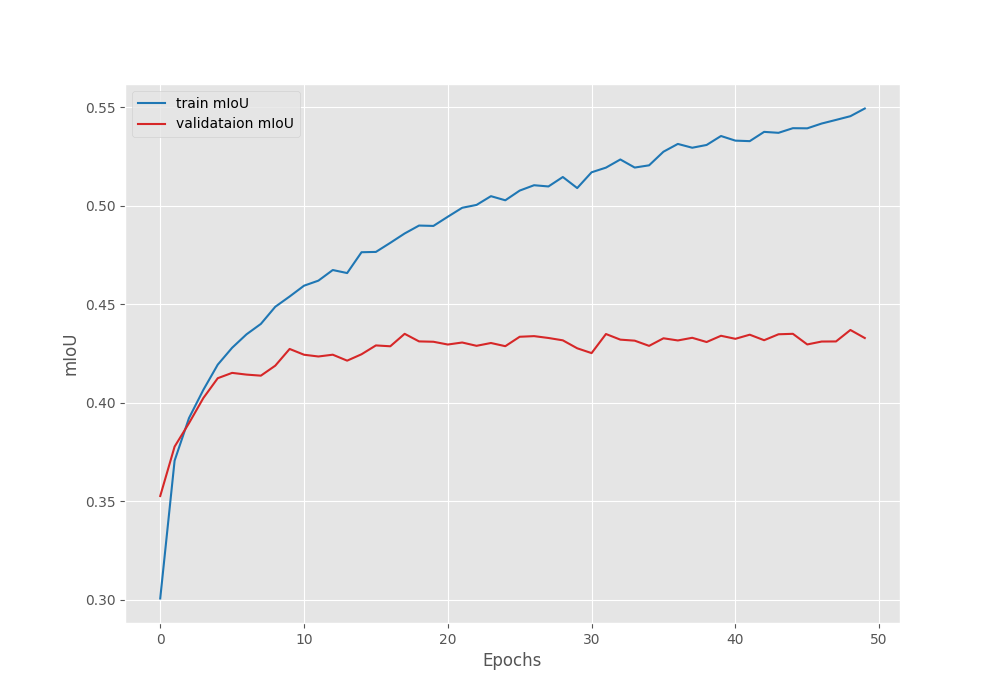
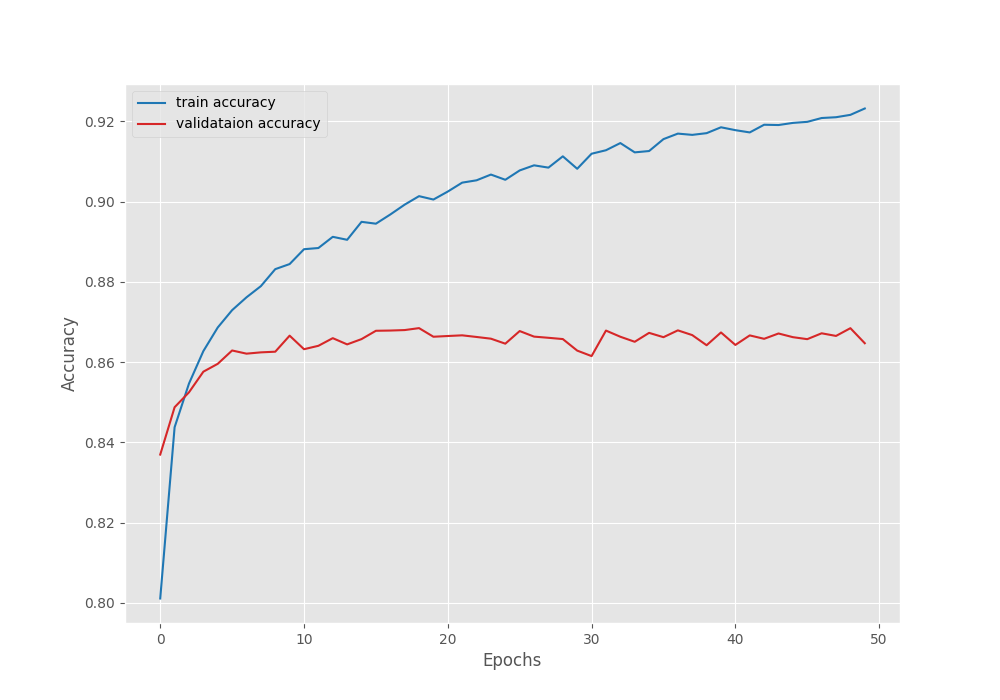
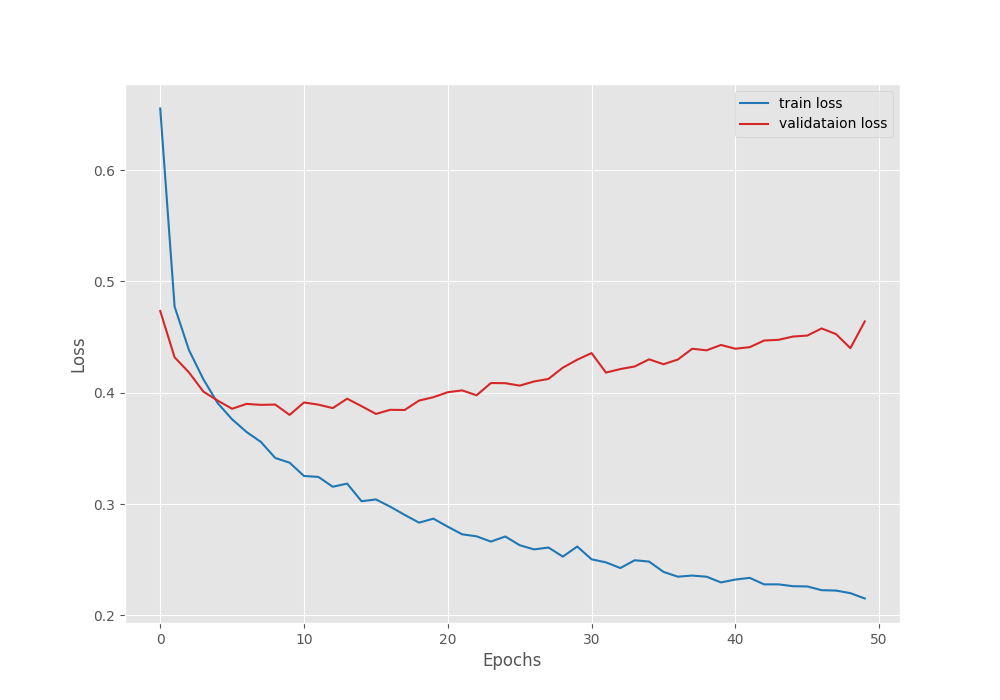
The validation loss graph seems to be moving upwards after epoch 20. This means that we need even more data to continue training the model.
For now, we will use the trained model for inference.
Inference on Test Images
Now, we will use the LRASPP MobileNetV3 model trained on the Indian Driving Dataset subset for running inference on the test images from the dataset.
We will use the inference_image.py script to run the inference on images.
python inference_image.py --model ../outputs/idd_training_lraspp/best_model_iou.pth --input ../input/idd_part_2/test/images/ --out ../outputs/image_inference
Here we pass the path to the best trained weights, the path to the test images directory, and the path to the directory where we want to store the results.
Following are some of the results that we obtain.

The results look very promising here, though they may not be the best. The model seems to be able to segment people, road, cars, vehicles, and buildings. The major issue is the low polygon segmentation masks that we are getting in the finer areas, like a person’s hands or legs. In some cases, the model seems to struggle when two objects are close together. We can surely improve all of this by training on even more data.
Inference on Video using the Trained Model
Let’s run inference on videos now.
We will use inference_video.py script to run inference on videos.
python inference_video.py --input ../input/inference_data/video_3.mov --model ../outputs/idd_training_lraspp/best_model_iou.pth --out ../outputs/video_inference
Here are the results.
The model can segment all the large objects quite well. However, it is struggling to segment the smaller objects. Furthermore, we can see flickering which most probably will be rectified with more training and perhaps training with a better loss function compared to Cross Entropy loss.
As the model has been fine-tuned on Indian road driving scenarios, let’s try it on a clip resembling similar conditions.
As we can see, the results are not that good. This means that the model is not yet trained properly to handle all scenarios such as high brightness and sun glares. The bigger issue: the model is able to segment all objects, however, the flickering is quite prominent.
Summary and Conclusion
In this article, we carried out the training of the LRASPP MobileNetV3 model on a subset of the Indian Driving Dataset for semantic segmentation. We explored the dataset in detail, discussed the training parameters, and ran inference as well. From our experiments, it is clear that the model needs to be trained on even more data to handle different scenarios. We will cover that in the next article. I hope that this article was worth your time.
If you have any questions, doubts, or suggestions, please leave them in the comment section. I will surely address them.
You can contact me using the Contact section. You can also find me on LinkedIn, and X.
Video Credit
- For the Indian road scenario video => https://www.youtube.com/watch?v=nFYaEaiTmiw

1 thought on “Training LRASPP MobileNetV3 on Indian Driving Dataset Subset for Semantic Segmentation”