

In the previous post, we covered the basics of Detection Transformer (DETR) for object detection. We also used the pretrained DETR models for running inference on videos. In this article, we will use pretrained DETR models and fine tune them on custom datasets. We will train four DETR models and compare their mAP (mean Average Precision) metric. After getting the best model, we will also run inference on unseen data from the internet.

After going through this article, you will be able to train any DETR model on your dataset. In fact, you will get introduced to a new library that you can easily use for datasets of any scale.
Before jumping into the exciting parts of this article, let’s take a look at the content that we will cover here.
- We will start with a discussion of the dataset that we will use in this article. We will use an interesting aquarium creature detection dataset to train the DETR models.
- Then we will move on to setting up the
vision_transformerslibrary that we will use for training the DETR models. - We will carry out four training experiments. One for each of DETR ResNet50, DETR ResNet50 DC5, DETR ResNet101, and DETR ResNet101 DC5.
- Finally, we will choose the best model to run inference on unseen data.
This article is going to be both, exciting and informative at the same time. Hope you enjoy it.
The Aquarium Detection Dataset to Train the DETR Models
We will train the DETR models on an aquarium dataset containing different types of marine creatures. You can find the original dataset on Roboflow (Aquarium Dataset). But we are going to use a slightly different version of the dataset here. A few of the wrong annotations from the original dataset have been corrected.
You can find the new Aquarium dataset here on Kaggle. For now, you may go ahead and download the dataset. After extracting you will find the following directory structure.
Aquarium Combined.v2-raw-1024.voc ├── test [126 entries exceeds filelimit, not opening dir] ├── train [894 entries exceeds filelimit, not opening dir] ├── valid [254 entries exceeds filelimit, not opening dir] ├── README.dataset.txt └── README.roboflow.txt
The dataset contains the images and annotations in three subdirectories. The annotations are in XML (Pascal VOC) format. The train directory contains 894 images and annotations combined. So, there are 447 training images. Similarly, the valid and test directories also contain the images and annotations together. This accounts for 127 and 63 validation and test images respectively.
There are a total of 7 classes in the dataset.
- fish
- jellyfish
- penguin
- shark
- puffin
- stingray
- starfish
For now, let’s take a look at the ground truth images to get a better understanding of the dataset.

The images are quite diverse. If trained with the right hyperparameters, our DETR models will be able to do pretty well even on unseen data.
The vision_transformers Library
Although the official repository of Facebook is available for the DETR models, it may be quite difficult to fine tune the models using that.
For the past few months, I have been working on a new vision_transformers library specially dedicated transformer based vision models. At the moment, there are pretrained models available for image classification and object detection. For this article, we will only focus on the object detection models. As of now, all four DETR models are available in the library. It is straightforward to fine tune models and run inference after training. Before we can start the training process, we need to set it up locally.
Note: The repository works best on Ubuntu as we use pycocotools for evaluation.
I would recommend creating a new Anaconda environment for installing the dependencies of this library. First, clone the repository and make it the working directory.
git clone https://github.com/sovit-123/vision_transformers.git
cd vision_transformers
Next, we need to install PyTorch. It is best to install PyTorch with proper CUDA support from the official website. For example, the following command installs PyTorch 2.0.0 with CUDA 11.7 support.
conda install pytorch torchvision torchaudio pytorch-cuda=11.7 -c pytorch -c nvidia
Then, install the rest of the requirements.
pip install -r requirements.txt
The above repository gives us access to all the training and inference code. Finally, to get access to the model APIs from vision_transformers, we need to do a pip installation.
pip install vision_transformers
That is all we need to setup vision_transformer to train the DETR models for this article.
The Project Directory Structure to Train the DETR Models
It is important to manage the directory structure so that you can easily use the training and inference commands from this article. Here is the complete directory structure of the project.
├── input
│ ├── Aquarium Combined.v2-raw-1024.voc
│ └── inference_data
└── vision_transformers
├── data
├── examples
├── example_test_data
├── readme_images
├── runs
├── tools
├── vision_transformers
├── README.md
├── requirements.txt
└── setup.py
- The
inputdirectory contains the Aquarium dataset we downloaded earlier. It has aninference_datadirectory that can contain any images or videos that we will later use for inference. - Then we have the
vision_transformersdirectory. This is the repository that we cloned in the previous section. The tools directory contains the training and inference scripts. Essentially, we will need thetrain_detector.py,inference_image_detect.py, andinference_video_detect.pyinside this. - The
datadirectory contains the YAML files which are important to carry out the training of the models. We will see the details in the next section.
The repository has a lot going on inside with a good amount of utilities. But we will leave that for another article. For this article, let’s entirely focus on training the Detection Transformer models.
You will find the YAML file and the trained weights in the downloadable content that comes with this post. If you intend on running inference, just copy and paste the runs directory inside the cloned vision_transformers directory. If you want to train your own model, you need to download the dataset and arrange it according to the above structure.
Train DETR on The Aquarium Dataset
As we will be training 4 different Detection Transformer models on the custom dataset, we need to follow a proper strategy. Just training each model for the same number of epochs and choosing the best model may be a waste of computing resources.
Therefore, first, we will train each of the models for 20 epochs. Then, we will train the best performing among them for more epochs.
But before we move to the training, let’s prepare the dataset YAML file.
Download Code
The Dataset YAML File
The dataset YAML file will reside inside the vision_transformers/data directory. It contains all the information about the dataset. These include:
- The image paths.
- The annotation paths.
- All the class names.
- And the number of classes.
The repository already contains a YAML file for the Aquarium dataset. However, we will modify it according to the relative paths of our directory structure.
Copy and paste the following data into the data/aquarium.yaml file.
# Images and labels direcotry should be relative to train.py
TRAIN_DIR_IMAGES: '../input/Aquarium Combined.v2-raw-1024.voc/train'
TRAIN_DIR_LABELS: '../input/Aquarium Combined.v2-raw-1024.voc/train'
VALID_DIR_IMAGES: '../input/Aquarium Combined.v2-raw-1024.voc/valid'
VALID_DIR_LABELS: '../input/Aquarium Combined.v2-raw-1024.voc/valid'
# Class names.
CLASSES: [
'__background__',
'fish', 'jellyfish', 'penguin',
'shark', 'puffin', 'stingray',
'starfish'
]
# Number of classes (object classes + 1 for background).
NC: 8
# Whether to save the predictions of the validation set while training.
SAVE_VALID_PREDICTION_IMAGES: True
The first four lines indicate the path to the training and validation data. These are the paths to the images and annotation files. We have the images and annotation files in the same directory.
Then we provide the class names to CLASSES. The first class has to be __background__. Then the rest of the class names are the object classes from the dataset. NC indicates the number of classes including the background. So, here, along with 7 object classes, we have a total of 8 classes.
The final attribute is SAVE_VALID_PREDICTION_IMAGES. If we set this to True, the code will save predictions from the validation loop after each training epoch. It is a good way to check the performance of the model as the training is going on.
Training the Detection Transformer Models
Training the Detection Transformer models using this library is quite easy. We just need to execute one script. It is the train_detector.py present inside the tools subdirectory.
We will start with the training of the DETR ResNet50 model.
Note: All training experiments were run on a machine with 10 GB RTX 3080 GPU, 10th generation i7 CPU, and 32 GB of RAM.
Train DETR ResNet50
To start the training, execute the following command in your terminal within the vision_transformers library.
python tools/train_detector.py --epochs 20 --batch 2 --data data/aquarium.yaml --model detr_resnet50 --name detr_resnet50
Let’s go through the command line arguments in the above command:
--epochs: It is the number of epochs that we want to train the model for. As we discussed earlier, we will train each model for 20 epochs first.--batch: This indicates the batch size for the data loaders. We will use a batch size of 2 for all training experiments.--data: This is the path to the dataset YAML file. We are using theaquarium.yamlfile.--model: Here, we need to provide the model name. We can choose fromdetr_resnet50,detr_resnet50_dc5,detr_resnet101,detr_resnet101_dc5.--name: This is the directory name where all the training results including the trained weights will be saved. All results will be saved inruns/training/{name}directory.
If you wish to know more about the DETR models with DC5 layers, please go through the previous introductory article on DETR. It has a brief explanation of the DETR architecture and running inference using pretrained models as well.
We evaluate the object detection performance through the mAP (Mean Average Precision) metric on the validation set. Here are the results from the best epoch.
IoU metric: bbox Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.172 Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.383 Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.126 Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.094 Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.107 Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.247 Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.088 Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.250 Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.337 Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.235 Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.330 Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.344 BEST VALIDATION mAP: 0.17192136022687962 SAVING BEST MODEL FOR EPOCH: 20
The model reaches an mAP of 17.2% for IoU=0.50:0.95 on the last epoch.
Here are the mAP graphs.
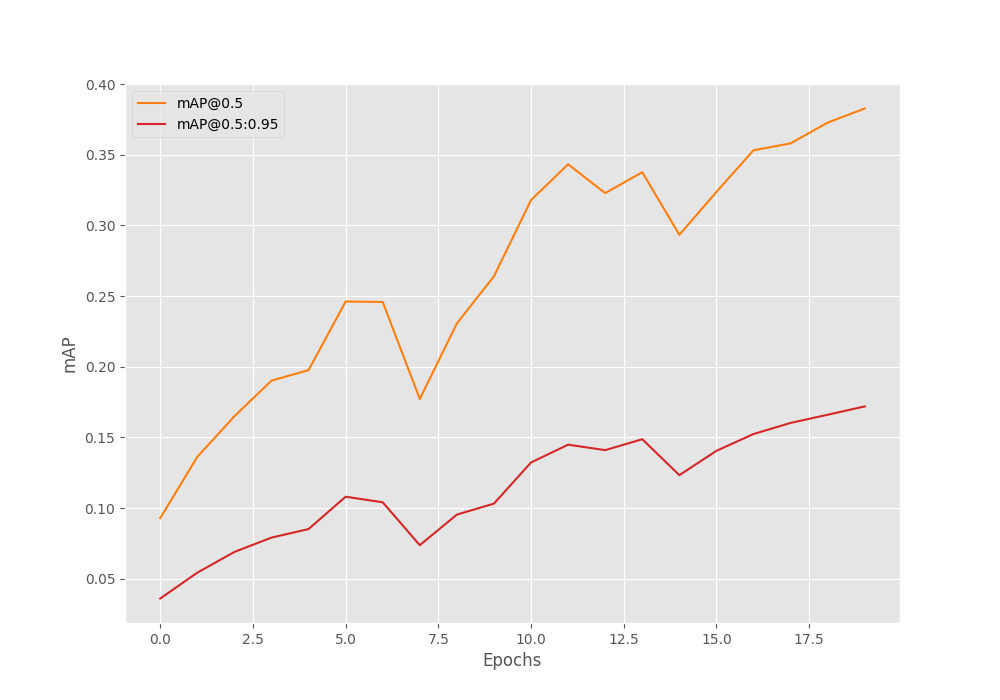
The mAP was obviously improving. But let’s train the other models before concluding anything.
Train DETR ResNet50 DC5
We can use a similar command as the previous one while changing the model and resulting directory name.
python tools/train_detector.py --epochs 20 --batch 2 --data data/aquarium.yaml --model detr_resnet50_dc5 --name detr_resnet50_dc5
This time also, the model reaches the highest mAP on epoch 20. But is lower compared to the previous one.
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.161 Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.360 Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.123 Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.141 Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.155 Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.233 Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.096 Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.248 Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.345 Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.379 Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.373 Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.340 BEST VALIDATION mAP: 0.16066837142161672 SAVING BEST MODEL FOR EPOCH: 20
The DETR ResNet50 DC5 model eaches an mAP of just 16%.
Here are the graphs.
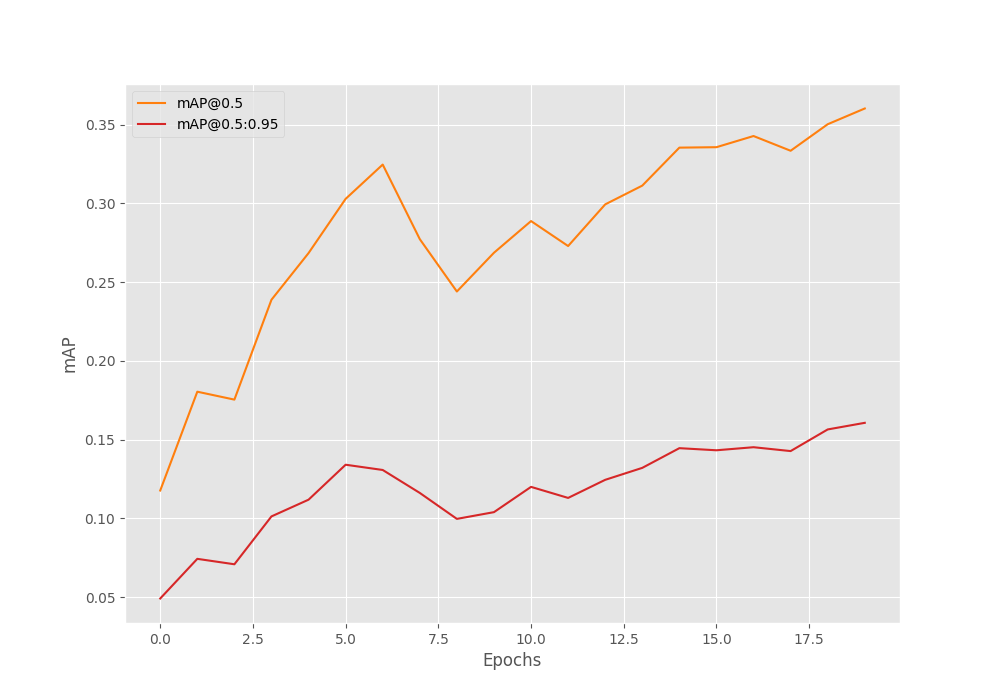
There is slightly more fluctuation in the graphs this time.
Train DETR ResNet101 Model
The DETR ResNet101 model contains more than 60 million parameters. So, we can expect it to perform better than the previous two models.
python tools/train_detector.py --epochs 20 --batch 2 --data data/aquarium.yaml --model detr_resnet101 --name detr_resnet101
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.175 Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.381 Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.132 Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.089 Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.113 Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.260 Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.095 Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.269 Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.362 Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.298 Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.451 Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.351 BEST VALIDATION mAP: 0.17489964894400944 SAVING BEST MODEL FOR EPOCH: 17
It reaches the best mAP of 17.5% on epoch 17. It is only a bit better compared to the other two, but better nonetheless.
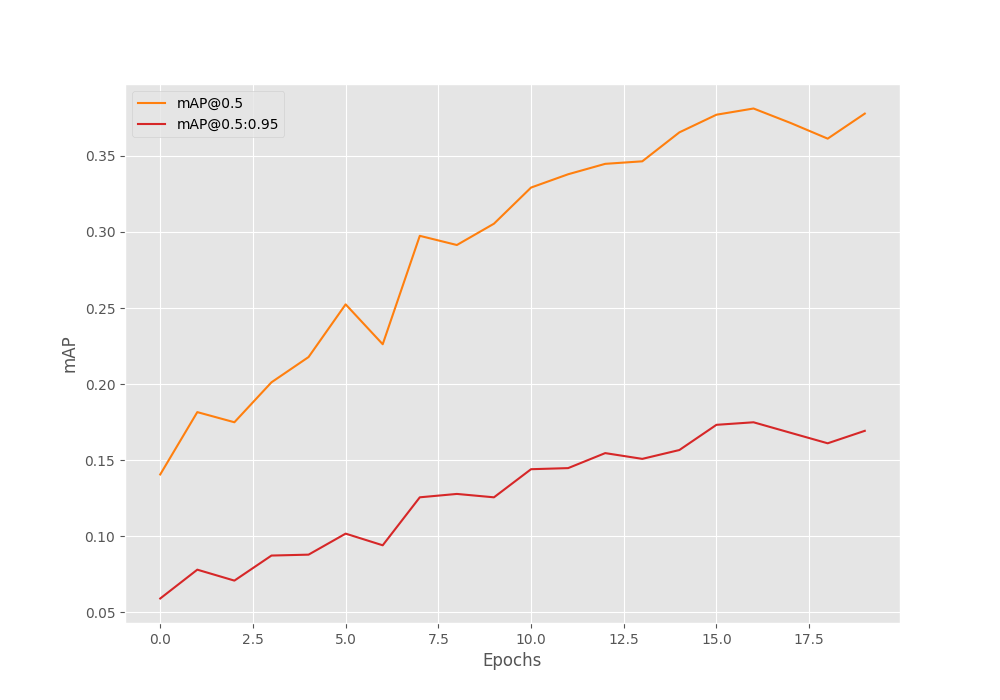
It looks like the mAP was improving faster this time. Most probably more training will help.
DETR ResNet101 DC5 Model
Now, coming to the final model. The DETR ResNet101 DC5 model is supposed to work best for small objects. As we have a lot of small objects in our dataset, we can expect it to perform the best.
python tools/train_detector.py --epochs 20 --batch 2 --data data/aquarium.yaml --model detr_resnet101_dc5 --name detr_resnet101_dc5
IoU metric: bbox Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.206 Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.438 Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.178 Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.110 Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.093 Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.303 Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.099 Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.287 Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.391 Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.317 Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.394 Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.394 BEST VALIDATION mAP: 0.20588343074278573 SAVING BEST MODEL FOR EPOCH: 20
The model reaches an mAP of 20% on epoch 20. This is best till now.
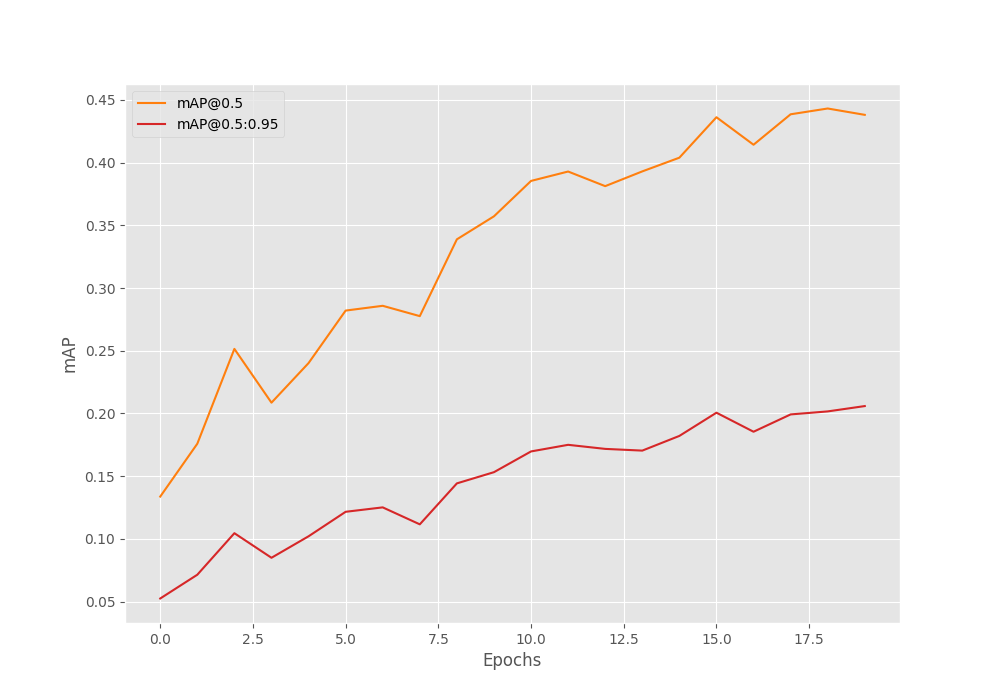
We will train this model for more epochs now. Let’s train it for 60 epochs. This time, we get the best model on epoch 48.
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.239 Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.501 Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.186 Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.119 Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.143 Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.328 Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.109 Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.290 Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.394 Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.349 Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.369 Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.398 BEST VALIDATION mAP: 0.23894132553612263 SAVING BEST MODEL FOR EPOCH: 48
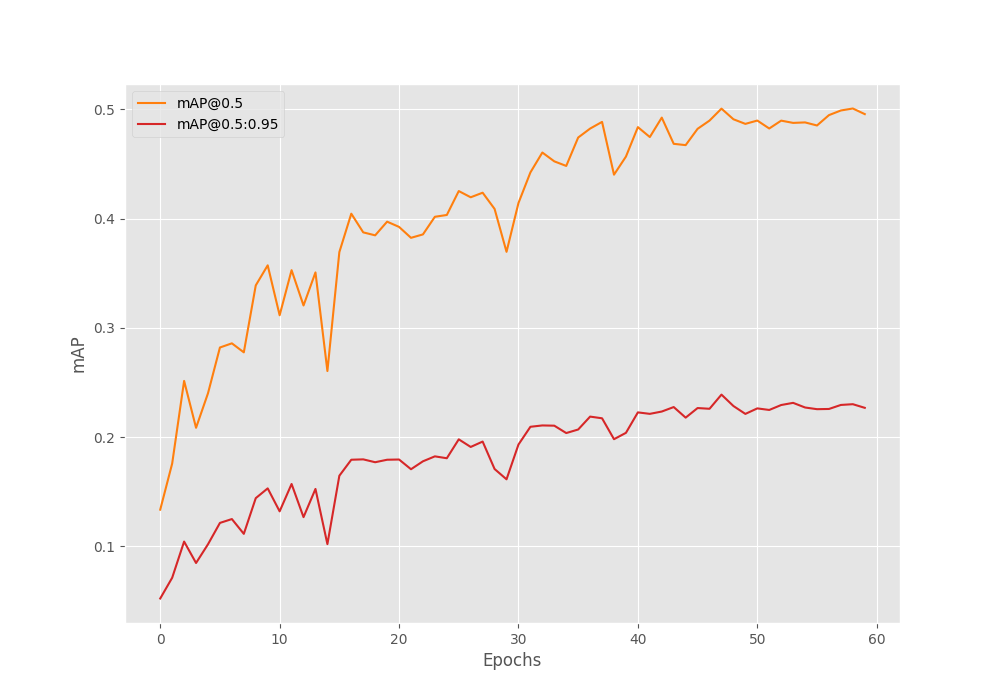
The model reaches an mAP of 24% for IoU=0.50:095. This is not bad considering we have only 447 training samples. Generally, transformer models need a good amount of data to perform well.
Inference on Test Images
Now that we have the best trained weights with us, let’s run inference on the test images from the dataset. We will use the inference_image_detect.py script inside the tools directory for this.
python tools/inference_image_detect.py --weights runs/training/detr_resnet101_dc5_60e/best_model.pth --input "../input/Aquarium Combined.v2-raw-1024.voc/test"
To get started right away, we just need two command line arguments.
--weights: This is the path to the weight file that we want to use for inference. In our cases, we are providing the path to the best weights for the model that we trained for 60 epochs.--input: This flag can accept either an image file or a directory containing images. We provide the path to the test directory here.
By default, the script uses a score threshold of 0.5 that we can modify with the --threshold flag. Here are a few results after running the above script. You can find the results in runs/inference directory.

As we can see, the model is able to detect sharks, fish, and stingrays efficiently. But it is unable to detect puffins very well. In fact, if you go through all the results in your directory, you will find that it has issues with detecting starfish as well. Most probably, this has to do with the small number of instances for these classes.
For now, let’s move on to some interesting video inference results.
Inference on Videos
We can just as easily run inference on videos using the inference_video_detect.py script. You can find a few videos to run inference within the source code zip file that comes with this post.
python tools/inference_video_detect.py --weights runs/training/detr_resnet101_dc5_60e/best_model.pth --input ../input/inference_data/video_1.mp4 --show
Here we have an additional flag, --show. This shows the results on screen as the inference is going on. On an RTX 3080 GPU, the model ran at 38 FPS on average.
The results are good but there are a few false detections where the mode is detecting the corals as fish. You can try and play around with the score threshold to get even better results.
Here is another result.
The above results are also very good considering these are unseen environments for the model. In a few of the frames, it is detecting the stingrays as fish, but other than that, the detections look good.
Further Improvements to Train DETR Models
The very first thing that we can try is collecting more data. DETR models can surpass convolutional models with the help of more data. If you collect more data and train the model, please let others know about your findings in the comment section.
Summary and Conclusion
In this article, we trained DETR models on a custom dataset. We started with downloading the dataset, setting up the vision_transformers library, and running the training experiments. Then we chose the best model to run inference experiments on unseen data. This gave us an idea of where the model needs improvements. I hope that this article was worth your time.
If you have any doubts, thoughts, or suggestions, please leave them in the comment section. I will surely address them.
You can contact me using the Contact section. You can also find me on LinkedIn, and X.
References

Awesome tutorial. I am using this on a custom dataset, and I notice that with a learning rate of 0.0001, everything performs as expected. There is a gradual increase in the metrics with each epoch and the final epoch map50 is 99%. However, if I use any other number for the learning rate (etc 0.0002, 0.0005), then the metrics are poor through the whole training process. After the same number of epochs, the map50 is as low as 0.02% and sometimes even 0. Do you have any insight on why this could be happening?
Hello Maria. You are right, DETR is particularly sensitive to learning rate. I will try to figure out a few more things with more experiments. Will update once done.