

In vision, learning internal representations can be much more powerful than learning pixels directly. Also known as latent space representation, these internal representations and learning allow vision models to learn better semantic features. This is the core idea of I-JEPA, which we will cover in this article.

Welcome to the first article in the JEPA series. Here, we will discuss the I-JEPA model introduced in the paper Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture. We will cover the following topics in this article.
- What is I-JEPA, and why do we need it?
- How does it differ from other self-supervised vision learning?
- What is the architecture of I-JEPA?
- What is its methodology?
- How does I-JEPA perform compared to other similar frameworks?
What is I-JEPA?
I-JEPA stands for Image-based Joint-Embedding Predictive Architecture. It’s a method for teaching computer vision models to understand images without needing hand-labeled data, a process called self-supervised learning.
The core idea is pretty straightforward: take an image, show the model a part of it (the “context block”), and then ask the model to predict what other parts of the image (the “target blocks”) look like. But I-JEPA doesn’t predict the actual pixels of the target blocks. Instead, it predicts an abstract representation of those target blocks. Think of it like predicting the “meaning” or “essence” of a patch rather than its exact visual details.
Why Do We Need I-JEPA?
So, why do we need something like I-JEPA? Current self-supervised methods for vision often fall into two camps, each with its own challenges.
- Invariance-based methods: These methods learn by comparing different augmented views of the same image (e.g., cropped, color-changed). They try to make the model realize these different views still represent the same thing. While they can learn good semantic features, the augmentations themselves introduce strong biases. These biases might not be helpful for all tasks or different types of data, and it’s not always clear how to apply these image-specific tricks to other data like audio.
- Generative methods (like masked autoencoders): These methods work by masking out parts of an image and training the model to reconstruct the missing pixels or tokens. They require less prior knowledge than invariance-based methods. However, focusing on pixel-level reconstruction often leads to representations that are less semantically rich. The model might get good at filling in textures but miss the bigger picture.
I-JEPA tries to get the best of both worlds. It aims to learn highly semantic (meaningful) image representations without relying on those hand-crafted data augmentations. By predicting abstract representations instead of pixels, I-JEPA encourages the model to focus on higher-level concepts and ignore unnecessary pixel-level noise. This helps it learn more robust and useful features. Plus, the paper shows it’s quite scalable and efficient.
How Does It Differ From Other Self-Supervised Vision Learning?
I-JEPA carves out its own niche by how it learns from images. Let’s see how it stacks up against the two main families of self-supervised learning:
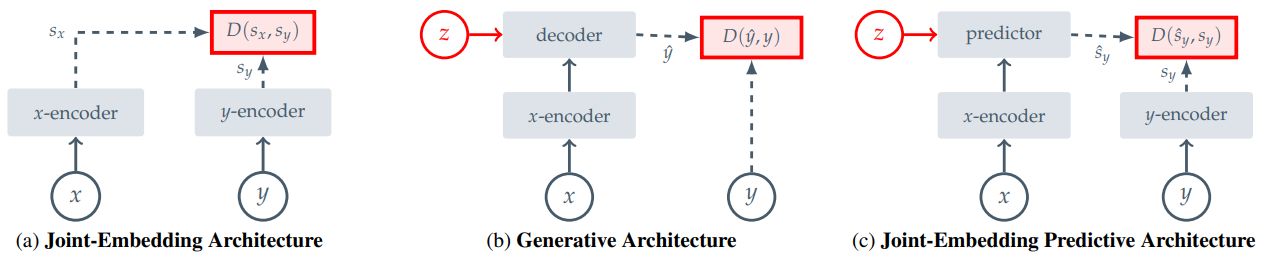
Invariance-Based Methods (e.g., SimCLR, DINO)
The biggest difference is that I-JEPA doesn’t use hand-crafted data augmentations to create multiple “views” of an image. Invariance-based methods train an encoder to produce similar embeddings for these different views. I-JEPA, on the other hand, works with a single image. It predicts representations of target blocks using a context block from that same image. It’s a predictive task, not directly an invariance task.
The paper categorizes I-JEPA as a Joint-Embedding Predictive Architecture (JEPA). This is distinct from the more general Joint-Embedding Architectures (JEAs) that invariance-based methods often use. While JEAs aim for similar embeddings for compatible inputs (like augmented views), JEPAs aim to predict the embedding of one input (a target block) from another (a context block), conditioned on some information (like the target’s location).
Generative Methods (e.g., MAE, BEiT)
Generative methods usually try to reconstruct the input signal itself-either the raw pixels or some tokenized version of image patches. For example, Masked Autoencoders (MAE) learn by predicting the pixel values of masked patches.
I-JEPA takes a different route. It predicts information in an abstract representation space. This means it’s not trying to get every pixel right in the target. Instead, it’s trying to capture the higher-level features or semantic content of the target patches. The representation space itself is learned during training, rather than being fixed like pixels or predefined tokens. As the paper states, “The I-JEPA method is non-generative and the predictions are made in representation space.”
A core design element that sets I-JEPA apart is its specific masking strategy. It carefully selects target blocks that are large enough to be semantically meaningful and uses a context block that is informative and spatially distributed.
What Is the Architecture of I-JEPA?
The architecture of I-JEPA consists of three main components, all based on Vision Transformers (ViTs):

- Context Encoder: This is a standard ViT. Its job is to process the visible patches of the “context block”-the part of the image given to the model as a clue.
- Target Encoder: This is also a ViT. It’s responsible for computing the representations of the “target blocks”-the parts of the image the model needs to predict. Crucially, the weights of this target encoder are not learned directly through backpropagation. Instead, they are an exponential moving average (EMA) of the context encoder’s weights. This is an important detail to prevent the model from finding trivial solutions (a problem known as representation collapse). The paper notes that target representations are computed from the output of this encoder.
- Predictor: This is a “narrower” (lighter-weight) ViT. It takes two things as input:
- The output representation from the context encoder (i.e., what the model “sees” from the context block).
- Positional mask tokens. These tokens tell the predictor where in the image the target block is located.
Based on these inputs, the predictor outputs a predicted representation for that specific target block.
The overall setup uses a single image. The context encoder only sees the context patches. The predictor then tries to “fill in the blanks” in the representation space for various target locations. The use of an EMA for the target encoder creates an asymmetry between how the context and target representations are generated, which is a common technique in joint-embedding architectures to avoid collapse.
What Is Its Methodology?
I-JEPA’s learning process revolves around predicting abstract representations of image blocks.
Objective
Given a “context block” from an image, the main goal is to predict the representations of several “target blocks” within that same image.
Generating Targets
- First, an input image is divided into a sequence of non-overlapping patches.
- The target encoder processes these patches to create patch-level representations.
- From these representations, I-JEPA randomly samples M blocks (the paper uses M=4 as typical). These become the target representations that the model aims to predict.
- A key point from the paper is that “target blocks are obtained by masking the output of the target-encoder, not the input.” This ensures the targets are already in an abstract, potentially more semantic, representation space. These target blocks are chosen to be relatively large to capture semantic information.
Generating Context
- A single “context block” is sampled from the image. This block is designed to be informative and spatially distributed.
- To make the prediction task non-trivial, any regions in this context block that overlap with the chosen target blocks are removed (masked out).
- This masked context block is then fed through the context encoder to get its representation.
Making Predictions
- For each of the M target blocks, the predictor takes the representation of the context block and a set of “mask tokens.” These mask tokens are learnable and include positional information, essentially telling the predictor where to look for the target.
- The predictor then outputs its predicted patch-level representation for that specific target block.
Calculating Loss
- The learning signal comes from comparing the predictor’s output with the actual target representation (from the target encoder). The loss is simply the average L2 distance (mean squared error) between the predicted and actual patch-level representations, summed over all M target blocks.
- The parameters of the context encoder and the predictor are updated using standard gradient-based optimization to minimize this loss.
- The parameters of the target encoder are updated using an exponential moving average (EMA) of the context encoder’s parameters. This means the target encoder’s weights lag slightly behind and are a smoothed version of the context encoder’s weights.
Masking Strategy
The paper emphasizes a “multi-block masking strategy”.

Typically, four target blocks are sampled with a certain scale (e.g., 15-20% of image area) and aspect ratio. A single, larger context block (e.g., 85-100% of image area) is also sampled, and any overlaps with the targets are removed from it. This ensures targets are semantic and the context is informative yet sparse (efficient to process).
This process encourages the model to learn relationships between different parts of an image at a high level of abstraction.
Learn more about training Vision Transformers from scratch.
How Does I-JEPA Perform Compared to Other Similar Frameworks?
The paper presents a comprehensive set of experiments showing that I-JEPA learns strong image representations and performs well across various benchmarks.
General Performance
I-JEPA is highly scalable, especially when used with Vision Transformers. It achieves strong results on diverse downstream tasks, including linear classification (evaluating features with a simple linear layer), object counting, and depth prediction. A key advantage highlighted is its efficiency.
Comparisons
In this section, we will analyze how I-JEPA performs against other approaches that try to accomplish the same objective.

MAE (Masked Autoencoders – pixel reconstruction)
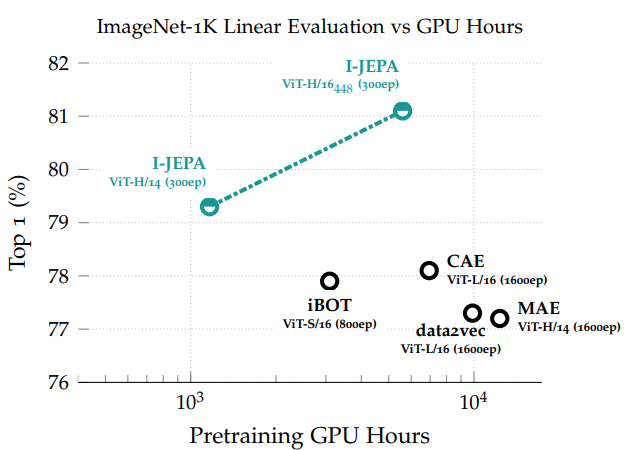
On ImageNet-1K linear probing, I-JEPA consistently outperforms MAE.
It’s also more efficient. Figure 5 shows I-JEPA achieving better results with significantly fewer GPU hours. The paper states I-JEPA converges roughly 5 times faster than MAE because predicting in representation space is computationally cheaper than predicting pixels for many epochs.
data2vec (predicts representations like I-JEPA)
I-JEPA generally shows better performance on ImageNet-1K linear probing.
It also demonstrates better computational efficiency and learns more semantic off-the-shelf representations (useful without extensive fine-tuning).
CAE (Context Autoencoders)
I-JEPA outperforms CAE on ImageNet-1K linear probing while using less compute.
View-Invariant Methods (e.g., iBOT, DINO – use data augmentations)
I-JEPA is competitive with these methods on semantic tasks like ImageNet-1K linear probing, without needing the hand-crafted augmentations. A large I-JEPA model (ViT-H/16 trained on 448px images) matches the performance of a strong iBOT model.
On low-shot ImageNet-1K (using only 1% of labels), I-JEPA with larger inputs surpasses previous methods, including those using augmentations.
For low-level vision tasks like object counting and depth prediction on the Clevr dataset, I-JEPA actually outperforms view-invariance methods like DINO and iBOT. This suggests I-JEPA captures local image features more effectively.
In terms of efficiency, a large I-JEPA model (ViT-H/14) requires less compute than even a small iBOT model (ViT-S/16).
Key Ablation Study Insights
Predicting in the representation space is crucial. When I-JEPA was modified to predict pixels directly (like MAE), its performance on 1% ImageNet-1K dropped significantly.
This highlights the benefit of abstract targets.
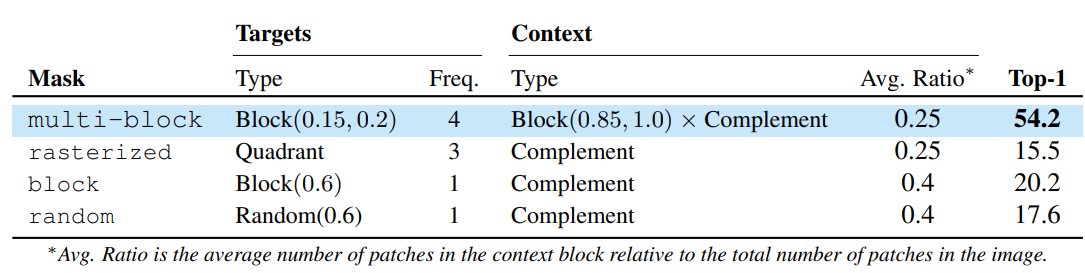
The multi-block masking strategy is important. Compared to other masking approaches (like trying to predict three quadrants from one, or random masking), the proposed strategy of predicting multiple, relatively large target blocks from an informative context leads to better semantic representations.
Summary and Conclusion
We covered the I-JEPA paper in this article. We covered the need for I-JEPA, how it differs from other self-supervision techniques, its architectures, and how it compares against other similar models. In the next article, we will work with the I-JEPA model while creating a simple image similarity application.
If you have any questions, thoughts, or suggestions, please leave them in the comment section. I will surely address them.
You can contact me using the Contact section. You can also find me on LinkedIn, and X.
Reference
- I-JEPA: The first AI model based on Yann LeCun’s vision for more human-like AI
- Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture

2 thoughts on “JEPA Series Part 1: Introduction to I-JEPA”