

Deep learning has picked up really well in recent years. Deep learning has had a positive and prominent impact in many fields. Computer vision, speech, NLP, and reinforcement learning are perhaps the most benefited fields among those.
In this article, we will focus on how deep learning changed the computer vision field. We will get to know in detail about the use cases that deep learning has contributed to the computer vision field.
Deep learning and neural networks have contributed many state-of-the-art benchmark results in the field of computer vision. We will cover some of the best use cases in deep learning for computer vision.
What We will Cover?
- Image recognition and classification.
- Detection.
- Object localization and detection.
- Face detection.
- Segmentation
- Semantic segmentation.
- Instance segmentations.
- Using Autoencoders and GANs
- Image denoising.
- Image deblurring.
- Image super-resolution.
- Image colorization.
- Image style transfer.
Image Recognition and Classification
In image recognition, a neural network will see a digital photograph and can tell what’s in it. This is perhaps on of the most applied used cases in deep learning for computer vision.

In a world, where everything is getting digital too quickly, image recognition has been a great advantage. Starting from recognizing faces, to animals, to cars, this application can be extended to almost anything that can be made into a digital photograph.
In deep learning, we use the term classification more instead of recognition.
In classification, we have a bunch of digital images, and each image belongs to a specific class. The images can be of animals, vehicles, birds, humans, etc.
For example, the above is a photo of the very famous CIFAR10 dataset. The CIFAR10 dataset has been a standard benchmarking dataset for many novel neural network algorithms and models.
Another very large dataset which has led to many state-of-the-art deep neural network classification models is the ImageNet dataset. The ImageNet dataset contains more than 14 million images. Most of the contributions have been through ILSVRC (ImageNet Large Scale Visual Recognition Challenge). This is an annual challenge held by ImageNet where deep learning researchers and practitioners try to beat the previous state-of-the-art results. This challenge had been held continuously from 2010 to 2016.
Detection
In object detection, the neural network model performs two tasks. First, it recognizes an object to tell the class of the object. Then it tells where the object is present in the image.
In this section, we will see two applications of detection in deep learning. One is image localization and detection, and the other is face detection.
Let’s start with image localization and detection.
Image Localization and Detection
In image localization and detection, the neural network algorithm finds an object in the image and then draws a bounding box around it.
Starting with image localization, we mainly detect only one object in this method. We will detect where an object is in the image and tell the class of the image.
For example, take a look at the following photograph.

In object detection, the neural network model tries to to find multiple objects in an image. After finding the objects, it draws the bounding boxes around them.
The following image is an example of object detection in deep learning.
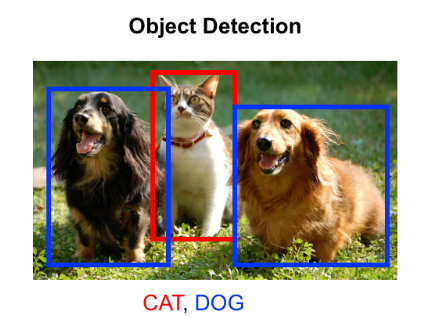
There are many application of object detection and localization.
- For self-driving cars, it can detect pedestrians, other vehicles, road signs, stop signals, etc.
- In medical usage, detection can be used to detect lung nodules in an x-ray image.
- We can also detect disease in plant leaves and specify the exact location of the disease on the leaf.
There are many more use cases of object detection and localization in deep learning. Take a look at the following Wikipedia article where you can find even more links.
Face Detection
Detecting faces is another very important and specific use case is object detection.
In face detection, the very first step is to detect the face of a human being in an image. From there on, we can extend the application even further.

After detecting a face of a person on image, we can:
- Use face recognition to know who the person is.
- Can use landmark detection to get the facial key points in the image.
- It can detect the emotion of the person of the image.
- It can be used to tell the age and gender of a person as well.
Face detection and recognition are most prominent in fields like security, marketing analysis, etc. One of the most interesting use cases has been the usage of face detection to unlock smartphones. This shows how far the application and algorithms in the field of computer vision has come.
Segmentation
Image segmentation in deep learning computer vision is another very useful application. We can divide image segmentation into two categories. They are semantic segmentation and instance segmentation.
In some cases, it is arguable that segmentation is a part of detection. But we will keep this section separate to get a better understanding of it.
Remember how in image classification, the neural network recognizes and classifies each image. In image segmentation, the deep neural network tries to classify each pixel of an image.
The following image will make things clearer.

You can see that in the image each object has a different segmentation color. Specifically, the pixels which are classified with the same labels are given the same segmentation color.
Now, let’s see what semantic segmentation is?
Semantic Segmentation
In semantic segmentation, we will label each category of an image with the same segmentation color. Every pixel in the image will be labeled with a class label.
For example, if an image contains two cars and two bikes. Then the two cars will be segmented with the same label (color) and the two bikes will be segmented with another label.
Let’s take a look at a picture to get a concrete idea.
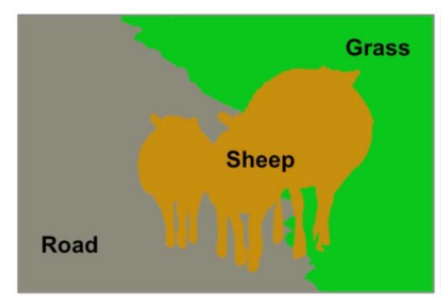
In the above image, you can see that the sheep are segmented into one class, the grass into one class, and the road into another class. I hope that the image does a good job of making things clear about semantic segmentation.
Instance Segmentation
Now, moving on to instance segmentation.
We can say that instance segmentation is a combination of both semantic segmentation and object detection. Each of the objects in the image are detected as well segmented into different classes. Along with that, each object belonging to the same class is given a different background color.
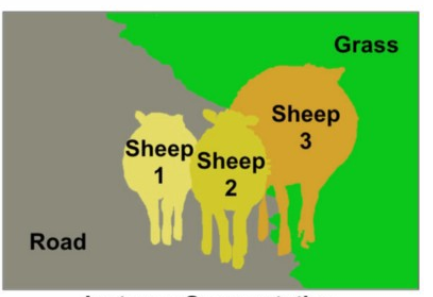
There is one important point out here though. Notice that we are not drawing any bounding boxes around the objects. Instead each of the object has a different segmentation color to help with detection.
Now, image segmentation has many use cases and they are really important ones. Let go over some of them.
- Using image segmentation in medical imaging analysis to segment out tissues, bones, and tumors.
- Image segmentation in self-driving vehicles to help in navigation and detecting pedestrians.
- Using image segmentation in video surveillance.
There are many more usages of image segmentation. You can find more of them here.
Autoencoders and GANs
Autoencoder and GANs (Generative Adversarial Networks) perhaps form the most interesting use cases in deep learning for computer vision.
They give rise to really interesting and important application which seemed like a distant dream a decade ago.
Let’s go over some of the most interesting ones in this section.
Image Denoising using Autoencoders
We are talking about images and computer vision in this article. And we know that images always cannot be sharp and clear. Sometimes images can be noisy.
In cases of noisy images, we can use autoencoders to denoise them. The following image shows in a very high level how we can use autoencoders to denoise images.
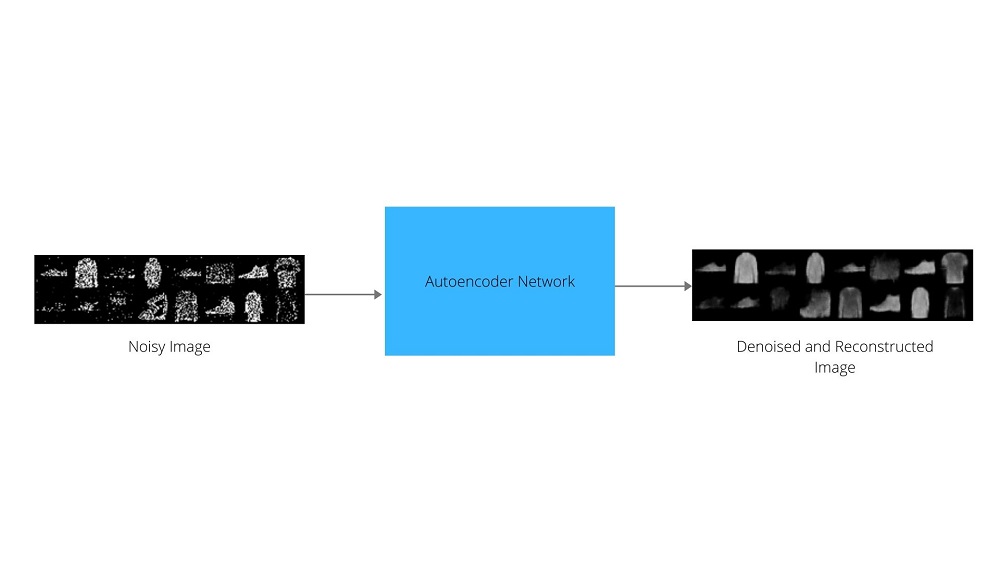
Now, if you want to get hands-on with denoising autoencoders, then check out this tutorial. It will pave the way for you to get started with denoising images with autoencoders.
And in case, you want to start learning about autoencoders from theory to implementation, you can check out my autoencoders section here.
Image Deblurring using GANs
We can also deblur out of depth images, motion blurred images, and other kinds of blurry images using neural networks for computer vision.
Although both autoencoders and GANs can perform image deblurring, we will focus on GANs here.
Note: We will not go into the details of GANs in this article.
There are many types of generative adversarial networks. But for image deblurring, we will focus on GAN architecture called the DeblurGAN.
The following image shows the architecture of DeblurGAN and how we can deblur a blurry image.
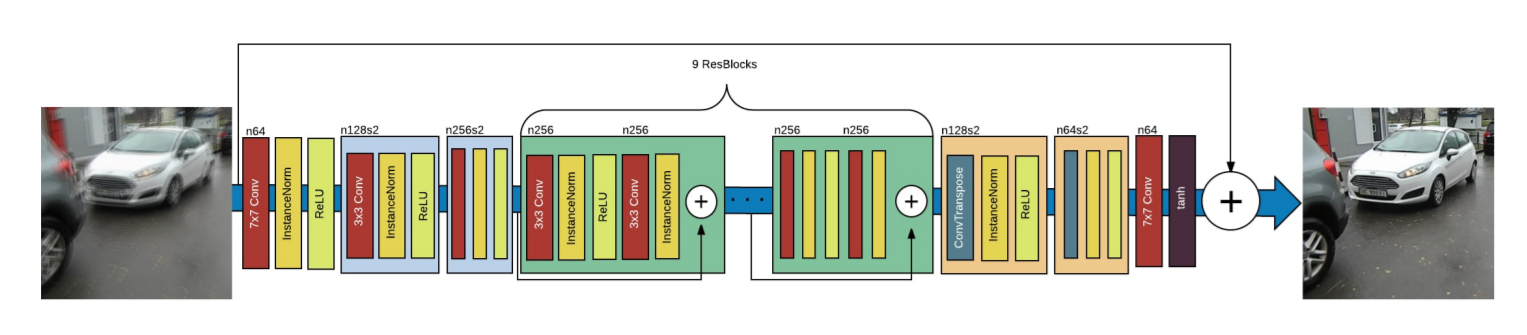
It not just about deburring images, DeblurGAN can also help in object detection after deblurring an image. For example, after deblurring an image, we can run the famous YOLO object detection algorithm to detect objects with more accuracy.

You can see in the above image, how deblurring the photo helps in increasing the object detection accuracy.
Image Super-Resolution using GANs
We can also use GANs to convert a lower resolution image into a high resolution image.
This particular method in deep learning is called image super-resolution. In this post, we will focus on the results of SRGAN (Super-Resolution GAN).
In image super-resolution, we try to get a high-resolution image from its low-resolution counterpart. And SRGAN is one such method to carry out image super-resolution.
There are many other methods and neural network models to carry out image-super resolution as well. The following image shows a comparison of the results between SRGAN and other methods.

You can read more about SRGAN from the original paper here.
Image Colorization
It is also possible to do image colorization using deep learning.
We can use convolutional autoencoders to convert gray scale images to RGB (Red, Green, Blue) images.

If you are interesting in practically applying image colorization using autoencoders, then you can take a look at this GitHub project by Aayushktyagi.
We can also carry out image colorization using GANs. The paper Image Colorization using Generative Adversarial Networks by Kamyar Nazeri et al. shows the approach to image colorization using Generative Adversarial Networks.
The following image shows the result from the above mentioned paper.

In the above image, you can see three columns, (a), (b), and (c). These three columns correspond to the grayscale image, original image, and the colorized image with their GAN approach respectively. If you observe closely, then you can know that the results are pretty accurate. This shows the diverse fields a GAN can be used in.
Image Style Transfer
Image style transfer using deep learning and neural networks is perhaps one of the most interesting things that we can do today.
In image style transfer, we take two different images. Generally, one image is called the content image, and the other image is called the style image. The content image contains the context, or places, things, and people in it. And the style image contains a specific texture drawing. Specifically, the style image used is most often a painting by some famous painter. Then the neural network combines the content from the content image, and the texture from the style to generate a totally new image. This new image contains the content from the first image and the texture style from the second image.
If things are getting a bit confused here, then you will find the following illustrations really helpful.

In the above figure, the first image shows the content image. The second image to the right shows the result after we apply style transfer to the first image. The small image that you see at the bottom is actually the style image whose texture is applied to the content image.
If you want to get into the details, then you can read the Image Style Transfer Using Convolutional Neural Networks paper by Gatys et al. If you want to get into the implementation part, then check out this GitHub repository by hwalsuklee.
Summary and Conclusion
In this post, you learnt how deep learning is advancing with the computer vision field to create new and better solutions to existing problems. You also learnt how we can carry out some really amazing things like style transfer using deep learning. If you just starting out with deep learning and computer vision, then I hope that you find this article helpful.
You can leave your thoughts in the comment section, and I will try my best to address them.
You can contact me using the Contact section. You can also find me on LinkedIn, and Twitter.
