

For more than two years now, vision encoders with language representation learning have been the go-to models for multimodal modeling. These include the CLIP family of models: OpenAI CLIP, OpenCLIP, and MetaCLIP. The reason is the belief that language representation, while training vision encoders, leads to better multimodality in VLMs. In these terms, SSL (Self Supervised Learning) models like DINOv2 lag behind. However, a methodology, Web-SSL, trains DINOv2 models on web scale data to create Web-DINO models without language supervision, surpassing CLIP models.
We will cover the following topics regarding Web-SLL in this article
- The need for Web-DINO using the Web-SSL methodology.
- What changes were made to the previous SSL DINOv2 training?
- What was the process to curate the data and train the model?
- How were the downstream tasks and benchmarking done?
What Was the Need for Web-DINO Using the Web-SSL Framework?
For a few years now, vision encoders trained with language supervision have been leading the LLM vision encoder race.
This means that when we need a vision encoder to build a multimodal model, e.g., Phi-4 multimodal, researchers typically use vision encoders trained with language supervision. These include the models primarily in the CLIP family: OpenAI CLIP, OpenCLIP, SigLIP, or even MetaCLIP. For example, the above mentioned model uses a SigLIP encoder.
Llama-3.2 11B vision took a slightly different approach by training the standard Vision Transformer models with image-text pairs. But language supervision nonetheless.
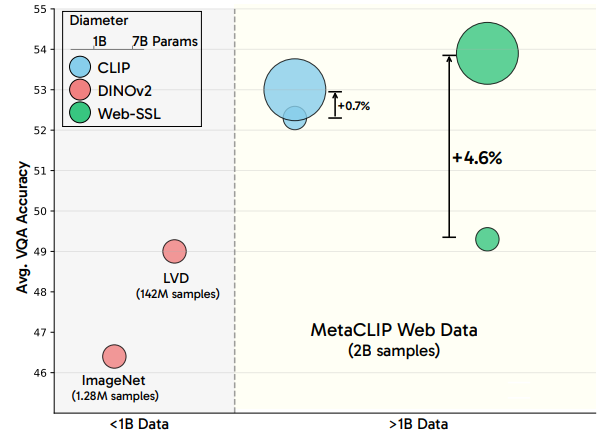
This is where Web-DINO comes into the picture. Introduced in the paper Scaling Language-Free Visual Representation Learning by Fan et al., it takes a different view of the problem. The authors summarize that pure vision supervision trained encoders do not perform well because of the difference in the dataset. Vision encoders like DINOv2 have been trained mostly with datasets with samples in the hundred-million range. What if we scale the dataset to multi-billion samples? Would the same Vision Transformer models like DINOv2 trained with the same SSL methodology outperform CLIP-like models with language supervision? The short answer is yes.
Once we start to train DINOv2 with more than a billion samples, we see it outperform CLIP at VQA tasks when paired with an LLM.
To this end, the contributions of the paper are threefold:
- A new series of web-scaled DINO models, Web-DINO, ranging from 1B to 7B parameters.
- A new training methodology, Web-SSL (Web Self-Supervised Learning).
- And a new data filtering framework to get the best out of training DINOv2 on web-scale data.
SSL 2.0 – Changes Made to DINOv2 SSL Training
Web-DINO is essentially DINOv2 trained with changes to its previous SSL training pipeline.
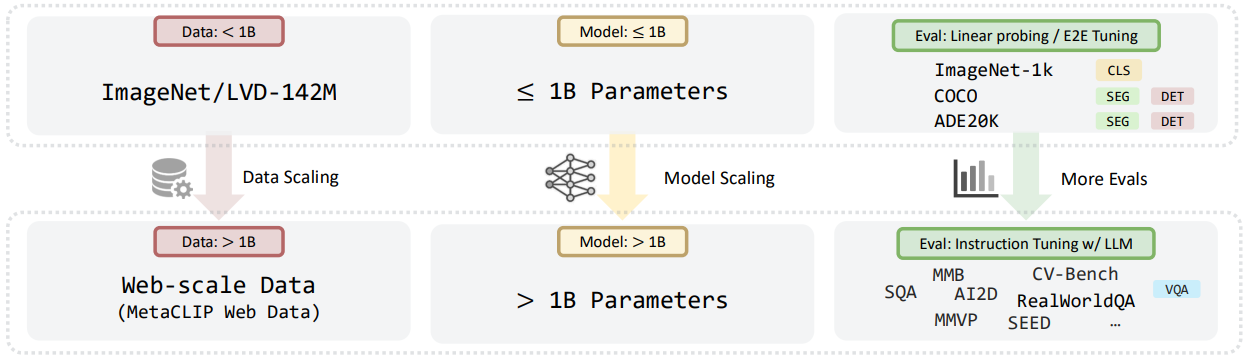
From ImageNet and LVD-142M to MetaCLIP Web Data (MC-2B)
Almost all previous Vision Transformer based encoders trained via SSL were trained on either ten-million scale or a few hundred-million scale datasets. For instance, DINOv2 was trained on the LVD-142M dataset.
This is where the authors make the first change to the training strategy. Instead of using ImageNet or LVD-142M pretraining, they use 2 billion samples from the MetaCLIP dataset. They term this as the MC-2B.
Although the MetaCLIP dataset contains image-text pairs to train the corresponding open-source versions of CLIP. The authors train the new SSL models only on the 2B images. For comparison, they also train the CLIP model on image-text pairs of the MC-2B dataset. This leads to a fair comparison, unlike previous attempts where comparison were made between models even when they were trained on different distributions of datasets.
Scaling Vision Transformers from Million to Billion Scale Parameters
The next stage includes increasing the model size. Instead of experimenting with a few hundred million parameter models, the authors create a series of ViT models. All ranging from 1B to 7B parameters.

The ViT-1B model is an adaptation of ViT-g, and the others are new configurations based on the 1B model. They term this series of models as Web-DINO. These are primarily DINOv2 models scaled from 1B to 7B scale. However, their Hugging Face page also has a 300M model, which might prove easier for experimentation.
To ensure fair comparison with CLIP, the authors train all models with 224×224 resolution.
Multimodal LLM Evaluation
To prove that language-free training of ViTs can beat CLIP-like models, evaluating them on ImageNet1K, segmentation, or depth estimation is not enough. The only way to prove that these models are better is to test them in a multimodal setting.
Traditionally, CLIP vision encoders are a standard for most multimodal language models. This means that the authors had to adapt these new Web-SSL trained models for multimodal settings.
To achieve this, the authors had to follow these steps:
- They add a lightweight MLP adapter to project the vision encoder features to the same dimensionality as the LLM. In the first stage, only this adapter is trained.
- In the second stage, they fine-tune both, the adapter and the LLM. The vision encoder remains frozen in these two stages.
For fair analysis, they evaluate the resulting multimodal models on 16 VQA benchmarks.
Web-DINO Benchmarks
In this section, we will discuss some of the important benchmark results as presented in the paper. This will give us a better overview of where the model is beating CLIP and where it is lacking.
Model Scaling Benchmark of Web-DINO and CLIP
The following figure shows how the new Web-DINO models trained through the Web-SSL framework performs against CLIP when trained on the same MC-2B dataset. This is a model for performance comparison.

Here, the x-axis shows the model sizes and the y-axis shows the accuracy. The general trend here is that the Web-DINO series of models keeps on improving when the model size increases. The CLIP models do not show much prominent increase in performance with model scaling. This is especially true for OCR & Chart VQA and the Vision-Centric VQA benchmarks. However, for the OCR & Chart VQA, the CLIP models, although not showing scaling behavior, still outperform the Web-DINO models with smaller scale models.
Scaling Training Examples Seen
The authors also carried out benchmarks on scaling examples seen during training. They trained the Web-DINO and CLIP models from 1B to 8B (>2B meaning multiple training epochs) samples.

There are primarily two observations here. First, the larger Web-DINO model such as the 7B versions outperforms the CLIP-7B model. Second, apart from OCR and Chart VQA, Web-DINO shows diminishing returns in scaling dataset for other tasks.
Benchmarking on Classic Vision Tasks
Image classification, segmentation, and depth estimation are some of the fundamental tasks in Computer Vision.
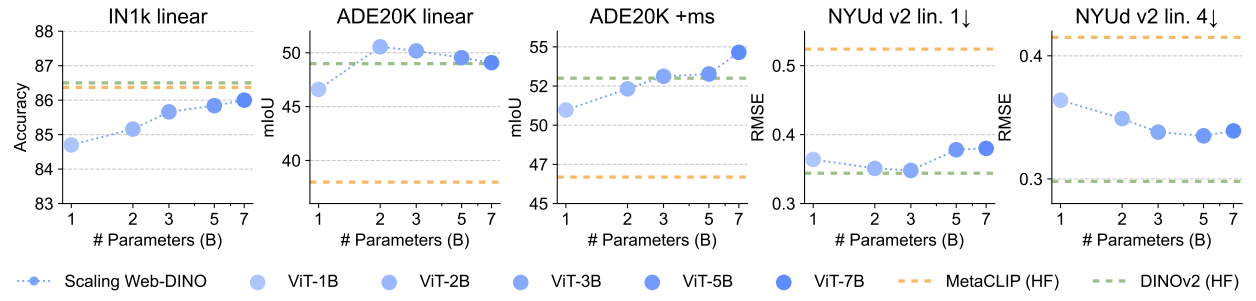
The Web-DINO series of models outperforms MetaCLIP and DINOv2 on the ADE20K segmentation benchmark when scaling to larger ones.
Data Filtering Benchmark
The authors carried out two data filtering benchmarks:
- Light Filter: It identifies images with text and retains 50.3% of the images from the MC-2B dataset.
- Heavy Filter: It identifies images containing charts and documents from the MC-2B dataset and retains only 1.3% of the images.

The above shows the benchmark of Web-DINO 2B model with light and heavy filters. When applying filters, the General and Vision Centric benchmarks take a hit for obvious reasons, as the data samples reduce. However, we can see an improvement in the OCR Chart benchmark. For ChartQA, OCRBench, TextVQA, and DocVQA, we can see clear improvements when applying both light and heavy filters. This shows that with filtered MC-2B, we can train powerful vision encoders even with small task-centric datasets using the Web-SSL framework.
The paper also contains results for Web-MAE, and ImageNet scaling benchmarks along with other details. I highly recommend going through the paper once to gain a deeper understanding on these.
Using Web-DINO from Hugging Face
All the Web-DINO models are available on Hugging Face Web-SSL page. It is quite straightforward to use the models for forward pass and obtain the hidden states for downstream tasks. They have an additional 300M parameter model as well, which is not mentioned in the paper. This can be a good starting point for experimentation with downstream task,s given its small size.
from transformers import AutoImageProcessor, Dinov2Model
import torch
from PIL import Image
processor = AutoImageProcessor.from_pretrained('facebook/webssl-dino300m-full2b-224')
model = Dinov2Model.from_pretrained('facebook/webssl-dino300m-full2b-224')
# Process an image
image = Image.open('path/to/image.jpg')
inputs = processor(images=image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
cls_features = outputs.last_hidden_state[:, 0] # CLS token features
patch_features = outputs.last_hidden_state[:, 1:] # patch-wise token features
In future articles, we will try to carry out downstream tasks using the pretrained Web-DINO models.
Summary and Conclusion
In this article, we covered the Web-DINO models, which use the new Web-SSL 2.0 framework for scaling vision encoders without language supervision. We started with the need for this framework, the models, and the benchmarks. In future articles, we will cover downstream tasks using these models. I hope this article was worth your time.
If you have any questions, thoughts, or suggestions, please leave them in the comment section. I will surely address them.
You can contact me using the Contact section. You can also find me on LinkedIn, and X.
References

1 thought on “Web-SSL: Scaling Language Free Visual Representation”