
In this tutorial, we will be focusing on two simple yet important concepts in regard to deep learning training. They are learning rate scheduler and early stopping. Further in the article, you will get to know how to use learning rate scheduler and early stopping with PyTorch while training your deep learning models.
Now, this concept may not be too advanced but are just as important for any newcomer to the field. So, if you are new to deep learning or starting out with deep learning with PyTorch, then I hope that this article helps.
So, what will we cover in this article?
- A brief about learning rate scheduler and early stopping in deep learning.
- Implementing learning rate scheduler and early stopping with PyTorch. We will use a simple image classification dataset for training a deep learning model.
- Then we will train our deep learning model:
- Without either early stopping or learning rate scheduler.
- With early stopping.
- With learning rate scheduler.
And each time observe how the loss and accuracy values vary. This will give us a pretty good idea of how early stopping and learning rate scheduler with PyTorch works and helps in training as well.
Note: We will not write any code to implement any advanced callbacks for early stopping and learning rate scheduler with PyTorch. We will use very simple code and that will give us an idea of how these work. This will also help new learners understand how to implement early stopping and learning rete scheduler with PyTorch code. Further on, they can integrate with any training code they want.
I hope that you are interested to follow this tutorial till the end. Let’s start with learning a bit about learning rate scheduler and early stopping in deep learning.
Learning Rate Scheduler
While training very large and deep neural networks, the model might overfit very easily. This becomes a larger issue when the dataset is small and simple. We can easily know this when while training, the validation loss, and training loss gradually start to diverge. This means that the model is starting to overfit. Also, using a single and high-value learning rate might cause the model to miss the local optima altogether during the last phases of training. During the last phases, the parameters should be updated gradually, unlike the initial training phases.
Trying to train a large neural network while using a single static learning rate is really difficult. This is where learning rate scheduler helps. Using learning rate scheduler, we can gradually decrease the learning rate value dynamically while training. There are many ways to do this. But the most commonly used method is when the validation loss does not improve for a few epochs.
Let’s say that we observe that the validation loss has not decreased for 5 consecutive epochs. Then there is a very high chance that the model is starting to overfit. In that case, we can start to decrease the learning rate, say, by a factor of 0.5.
We can continue to this for a certain number of epochs. When we are sure that the learning rate is so low that the model will not learn anything, then we can stop the training.
Early Stopping
Early stopping is another mechanism where we can prevent the neural network from overfitting on the data while training.
In early stopping, when we see that the training and validation loss plots are starting to diverge, then we just terminate the training. This is usually done in these two cases:
- We are very sure that the model is starting to overfit.
- We are also sure that using learning rate scheduler to reduce learning rate and more training will not help the model.
It actually depends on the machine learning engineer/researcher which to use of the two. While training large and deep learning neural networks on very large datasets, it is more common to use learning rate scheduler so that we are very sure that the neural network has reached the optimum solution.
We will not go into more theoretical details here. In the rest of the tutorial, we will see how to implement learning rate scheduler and early stopping with PyTorch.
Directory Structure and the Input Data
Now, let’s take a look at how to setup the directory for this mini-project.
├───input
│ └───alien-vs-predator-images
│ └───data
│ ├───train
│ │ ├───alien
│ │ └───predator
│ └───validation
│ ├───alien
│ └───predator
├───outputs
└───src
│ dataset.py
│ models.py
│ train.py
│ utils.py
- First, we have the
inputfolder. Inside that, we have thealien-vs-predator-imagesand thendataas the subfolders. Thedatafolder contains the respective training and validation images for thealienclass and thepredatorclass. - Then we have the
outputsfolder which will contain all the loss and accuracy plots along with the trained model after we have completed the training. - Finally, we have the
srcfolder which contains the four Python files in which we will be writing the code.
Coming to the data, we will be using Alien vs. Predator images from Kaggle. This is a very small dataset containing somewhere around 900 images belonging to the predator and alien classes. You can go ahead and download the dataset.
After downloading, extract it inside the input folder. The actual images that we will be using are inside the alien-vs-predator-images/data. So, if you see any other folders, you can ignore them as they are just a repetition of the images.

Just to have an idea, figure 2 shows a few images from the dataset belonging to the alien and predator classes. This is a very basic image classification dataset. We will not focus much on it. Instead, we will focus on the important concept at hand, implementing learning rate scheduler and early stopping with Pytorch.
Libraries and Dependencies
As we will use the PyTorch deep learning framework, let’s clarify the version. I am using PyTorch 1.7.1 for this tutorial, which is the latest at the time of writing the tutorial.
There are other basic computer vision library dependencies as well, which most probably you already have. If you find missing anything, just install them as you go.
Code for Learning Rate Scheduler and Early Stopping with PyTorch
From this section onward, we will write the code for implementing learning rate scheduler and early stopping with PyTorch.
We have four 4 Python files and we will tackle them one at a time. So, let’s move onward and start writing the code.
Writing the Learning Rate Scheduler and Early Stopping Classes
To implement the learning rate scheduler and early stopping with PyTorch, we will write two simple classes.
The code that we will write in this section will go into the utils.py Python file. We will write the two classes in this file.
Starting with the learning rate scheduler class.
The Learning Rate Scheduler Class
Actually, PyTorch provides many learning rate schedulers already. And we will also be using one of that, ReduceLROnPlateau() to be particular. Then why write a class again for that? Well, we will try to write the code in such a way that using the functions will become easier and also it will adhere to the coding style of early stopping which we will implement later.
The following code block contains the complete learning rate scheduler class, that is LRScheduler().
import torch
class LRScheduler():
"""
Learning rate scheduler. If the validation loss does not decrease for the
given number of `patience` epochs, then the learning rate will decrease by
by given `factor`.
"""
def __init__(
self, optimizer, patience=5, min_lr=1e-6, factor=0.5
):
"""
new_lr = old_lr * factor
:param optimizer: the optimizer we are using
:param patience: how many epochs to wait before updating the lr
:param min_lr: least lr value to reduce to while updating
:param factor: factor by which the lr should be updated
"""
self.optimizer = optimizer
self.patience = patience
self.min_lr = min_lr
self.factor = factor
self.lr_scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(
self.optimizer,
mode='min',
patience=self.patience,
factor=self.factor,
min_lr=self.min_lr,
verbose=True
)
def __call__(self, val_loss):
self.lr_scheduler.step(val_loss)
For, the whole utils.py file, we just need the torch module.
Coming to the LRScheduler class, I have provided the necessary documentation for easier understanding. This class will reduce the learning rate by a certain factor when the validation loss does not decrease for a certain number of epochs. Specifically, when the learning rate scheduler is executed internally, then the new_learning_rate = old_learning_rate * factor. So, smaller the factor, the lower the new learning rate value will be.
Going over the code briefly.
First, the __init__() function.
- This accepts the
optimizer,patience,min_lr, andfactoras parameters. You may read the description in the code documentation to know what each parameter does. - The
patience,min_lr, andfactorhave some initial values. - From lines 20 to 23, we initialize the four variables first.
- At line 25, we initialize the
self.lr_schedulerobject of theReduceLROnPlateau()class. Let’s go over the arguments it takes. First is the optimizer that we have provided. Then we havemode. It can be eitherminormax. We are usingminwhich means that the learning rate will be updated when the metric that we are monitoring has stopped reducing. This is apt when we use validation loss as the monitoring metric. Then we have thepatience,factor, andmin_lr.min_lrdefines the minimum value that the learning rate will reduce to. Finally,verbose=Truewill print a message whenever the learning rate is updated.
Secondly, the __call__() function.
This function contains just one line of code. That is, to take one step of the learning rate scheduler while providing the validation loss as the argument. The __call__() function will be executed whenever we will provide the validation loss as an argument to the object of the LRScheduler() class. Things will become clearer when we will actually use this in the training script.
Moving ahead, we will write the code for early stopping.
The Early Stopping Class
Now, Pytorch does not have any pre-defined class for early stopping. Therefore, we will write a very simple logic for that.
The following block contains the code for the early stopping class.
class EarlyStopping():
"""
Early stopping to stop the training when the loss does not improve after
certain epochs.
"""
def __init__(self, patience=5, min_delta=0):
"""
:param patience: how many epochs to wait before stopping when loss is
not improving
:param min_delta: minimum difference between new loss and old loss for
new loss to be considered as an improvement
"""
self.patience = patience
self.min_delta = min_delta
self.counter = 0
self.best_loss = None
self.early_stop = False
def __call__(self, val_loss):
if self.best_loss == None:
self.best_loss = val_loss
elif self.best_loss - val_loss > self.min_delta:
self.best_loss = val_loss
# reset counter if validation loss improves
self.counter = 0
elif self.best_loss - val_loss < self.min_delta:
self.counter += 1
print(f"INFO: Early stopping counter {self.counter} of {self.patience}")
if self.counter >= self.patience:
print('INFO: Early stopping')
self.early_stop = True
Going over all the variables in the __init__() function.
self.patiencedefines the number of times we allow the validation loss to not improve before we early stop our training. Mind that this is not the number of consecutive epochs. Rather it is the cumulative number of times the validation loss does not improve during the whole training process.self.min_deltais the minimum difference between the new loss and the best loss for the new loss to be considered an improvement.- Then we have
self.counterwhich keeps count of the number of times the current validation loss does not improve. - Finally, we have
self.best_lossandself.early_stopwhich areNoneandFalserespectively.
Then we have the __call__() function which implements the early stopping logic. At the beginning of training, we make the current loss as the best loss at line 56. Line 57 checks whether the current loss is less than the best loss by the min_delta amount. If so, then we update the best validation loss value. If not, we increment the counter by 1 at line 60. Whenever the counter is greater than the patience value, then we update the self.early_stop to True and print some information on the screen. After this, further actions will be taken in the training script.
That’s it for the learning rate scheduler and early stopping code.
Preparing the Dataset
In this section, we will prepare the dataset that we will train our deep learning model on. Before moving further, make sure that you have downloaded the dataset and achieved the directory structure as discussed before.
We will write the code in dataset.py Python file for preparing the dataset.
For preparing the dataset, we will use the ImageFolder module of PyTorch. This will make our work way easier as we already have our extracted dataset in the way the ImageFolder module expects it to be.
Actually, by using the ImageFolder module, we can completely get rid of our custom dataset class and quickly move on to the training. It has its advantages and disadvantages, but for this tutorial, we want to focus on early stopping and learning rate scheduler.
The ImageFolder expects the dataset to be in the following format.
root/dog/xxx.png root/dog/xxy.png root/dog/xxz.png root/cat/123.png root/cat/nsdf3.png root/cat/asd932_.png
And our dataset is already in that format. Let’s take a look at our dataset folder structure a bit.
├───input │ └───alien-vs-predator-images │ └───data │ ├───train │ │ ├───alien │ │ └───predator │ └───validation │ ├───alien │ └───predator
So, up till train and validation folders, it will be the root path and we can easily prepare the training and validation sets.
So, let’s get down to writing the code in dataset.py.
Starting off with the libraries and modules that we need.
import torch from torchvision import transforms, datasets
Next, let’s define the image transforms and augmentations for training and validation.
# define the image transforms and augmentations
train_transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.RandomHorizontalFlip(),
transforms.RandomVerticalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
val_transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
For the training transforms, we are:
- Resizing all the images to 224×224 dimensions.
- Flipping the images horizontally and vertically with a random probability.
- Converting the images to tensors which divides all the pixel values by 255.0 and changes the dimension format to [channel, height, width].
- Normalizing all the pixel values by using the ImageNet normalization stats.
For the validation transforms, we do not apply any augmentations like flipping that we did in the case for training.
Finally, the training and validation datasets and dataloaders.
# traning and validation datasets and dataloaders
train_dataset = datasets.ImageFolder(
root='../input/alien-vs-predator-images/data/train',
transform=train_transform
)
train_dataloader = torch.utils.data.DataLoader(
train_dataset, batch_size=32, shuffle=True,
)
val_dataset = datasets.ImageFolder(
root='../input/alien-vs-predator-images/data/validation',
transform=val_transform
)
val_dataloader = torch.utils.data.DataLoader(
val_dataset, batch_size=32, shuffle=False,
)
We are applying the respective transforms for training and validation datasets. The batch size for the data loaders is 32 and we are shuffling the training data loaders as well. Now, our data loaders are ready for training.
The Deep Learning Model
We will use an ImageNet pre-trained model in this tutorial. Specifically, we will use the ResNet50 pre-trained model.
We will freeze all the hidden layer parameters and make only the classification layer learnable.
The code here will go into the models.py Python file.
The following code block contains all the code we need for preparing the model.
import torch.nn as nn
import torchvision.models as models
def resnet50(pretrained=True, requires_grad=False):
model = models.resnet50(progress=True, pretrained=pretrained)
# either freeze or train the hidden layer parameters
if requires_grad == False:
for param in model.parameters():
param.requires_grad = False
elif requires_grad == True:
for param in model.parameters():
param.requires_grad = True
# make the classification layer learnable
model.fc = nn.Linear(2048, 2)
return model
At line 5, we are loading the ResNet50 model with the ImageNet pre-trained weights. As we will pass requires_grad=False, so, all the intermediate model parameters will be frozen. The final classification layer at line 14 has 2 output features. This corresponds to the two classes that we have, alien and predator. Finally, we return the model.
Moving ahead, we will start writing our training script.
Training Script for Learning Rate Scheduler and Early Stopping with PyTorch
This is the final code file that we will deal with in this tutorial. It is the training script that we will execute, the train.py Python file.
As always, the first code block contains all the libraries and modules that we will need for the training script.
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib
import matplotlib.pyplot as plt
import time
import models
import argparse
from dataset import train_dataloader, val_dataloader
from dataset import train_dataset, val_dataset
from utils import EarlyStopping, LRScheduler
from tqdm import tqdm
matplotlib.style.use('ggplot')
At lines 10 and 11, we are importing the train_dataset, val_dataset and train_dataloader, and val_dataloader from dataset. We are also importing EarlyStopping and LRScheduler from utils at line 12.
Construct the Argument Parser and Initialize the Model
We will write the code to construct the argument parser which will tell whether we want to apply learning rate scheduler or early stopping.
# construct the argument parser
parser = argparse.ArgumentParser()
parser.add_argument('--lr-scheduler', dest='lr_scheduler', action='store_true')
parser.add_argument('--early-stopping', dest='early_stopping', action='store_true')
args = vars(parser.parse_args())
So, while executing train.py, we can either provide --lr-scheduler or --early-stopping as the command line arguments. The code will be executed accordingly.
The next code block defines the computation device and loads the deep learning model as well.
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f"Computation device: {device}\n")
# instantiate the model
model = models.resnet50(pretrained=True, requires_grad=False).to(device)
# total parameters and trainable parameters
total_params = sum(p.numel() for p in model.parameters())
print(f"{total_params:,} total parameters.")
total_trainable_params = sum(
p.numel() for p in model.parameters() if p.requires_grad)
print(f"{total_trainable_params:,} training parameters.")
Starting from line 26, we calculate the total number of parameters in the model. We also print the information on the screen about the total number of parameters and the number of trainable parameters.
The Learning Parameters
Now, we will define the learning/training parameters which include the learning rate, epochs, the optimizer, and the loss function.
# learning parameters lr = 0.001 epochs = 100 # optimizer optimizer = optim.Adam(model.parameters(), lr=lr) # loss function criterion = nn.CrossEntropyLoss()
We will be starting off with a learning rate of 0.001 and we will train for 100 epochs. The optimizer is the Adam optimizer and we are using the Cross Entropy loss function.
Initializing Learning Rate Scheduler and Early Stopping According to Command Line Arguments
While running the training script, we can either run it as it is, or we can provide either of the command line arguments for utilizing either the learning rate scheduler or early stopping. In that case, we can define some variable names for the loss plot, accuracy plot, and model so that they will be saved to disk with different names.
# strings to save the loss plot, accuracy plot, and model with different ... # ... names according to the training type # if not using `--lr-scheduler` or `--early-stopping`, then use simple names loss_plot_name = 'loss' acc_plot_name = 'accuracy' model_name = 'model'
If we are neither using learning rate scheduler nor early stopping, then we will use the simple strings in the above code block. Else, we will initialize the learning rate scheduler and early stopping and change the variable names accoringly.
# either initialize early stopping or learning rate scheduler
if args['lr_scheduler']:
print('INFO: Initializing learning rate scheduler')
lr_scheduler = LRScheduler(optimizer)
# change the accuracy, loss plot names and model name
loss_plot_name = 'lrs_loss'
acc_plot_name = 'lrs_accuracy'
model_name = 'lrs_model'
if args['early_stopping']:
print('INFO: Initializing early stopping')
early_stopping = EarlyStopping()
# change the accuracy, loss plot names and model name
loss_plot_name = 'es_loss'
acc_plot_name = 'es_accuracy'
model_name = 'es_model'
In the above code block, we are initializing the learning rate scheduler and early stopping according to the command line argument that is provided. Along with that, we also changing the plot and model names that we will use to save loss & accuracy plots and the trained model to disk.
The Training Function
The training function is going to be the standard PyTorch classification training function that we usually see. We will call the function fit().
# training function
def fit(model, train_dataloader, train_dataset, optimizer, criterion):
print('Training')
model.train()
train_running_loss = 0.0
train_running_correct = 0
counter = 0
total = 0
prog_bar = tqdm(enumerate(train_dataloader), total=int(len(train_dataset)/train_dataloader.batch_size))
for i, data in prog_bar:
counter += 1
data, target = data[0].to(device), data[1].to(device)
total += target.size(0)
optimizer.zero_grad()
outputs = model(data)
loss = criterion(outputs, target)
train_running_loss += loss.item()
_, preds = torch.max(outputs.data, 1)
train_running_correct += (preds == target).sum().item()
loss.backward()
optimizer.step()
train_loss = train_running_loss / counter
train_accuracy = 100. * train_running_correct / total
return train_loss, train_accuracy
The first task is to put the model into training mode, which we are doing at line 62. We define train_running_loss and train_running_correct to keep track of the loss values and accuracy in each iteration. Starting from line 68, we iterate through the batches of data. We perform the standard operations like getting the batch loss, number of correct predictions, calculating the gradients, and updating the model parameters. After each epoch, we calculate the train_loss and train_accuracy and return those values (lines 81 to 83).
The Validation Function
The validation function will be very similar to the training function. Except, we need neither backpropagate the loss for gradient calculation nor update the model parameters.
# validation function
def validate(model, test_dataloader, val_dataset, criterion):
print('Validating')
model.eval()
val_running_loss = 0.0
val_running_correct = 0
counter = 0
total = 0
prog_bar = tqdm(enumerate(test_dataloader), total=int(len(val_dataset)/test_dataloader.batch_size))
with torch.no_grad():
for i, data in prog_bar:
counter += 1
data, target = data[0].to(device), data[1].to(device)
total += target.size(0)
outputs = model(data)
loss = criterion(outputs, target)
val_running_loss += loss.item()
_, preds = torch.max(outputs.data, 1)
val_running_correct += (preds == target).sum().item()
val_loss = val_running_loss / counter
val_accuracy = 100. * val_running_correct / total
return val_loss, val_accuracy
Note that we are doing all the model predictions inside the with torch.no_grad() block. This ensures that we are not calculating any gradients which saves memory and time while validating. As in the case of training, we are returning the validation loss and accuracy at the end.
The Training Loop
As we have coded above, we will train and validate the model for 200 epochs. We can do that using a simple for loop. There are some other details that we need to take care of within the training loop. Let’s write the code, then we will get into those details.
# lists to store per-epoch loss and accuracy values
train_loss, train_accuracy = [], []
val_loss, val_accuracy = [], []
start = time.time()
for epoch in range(epochs):
print(f"Epoch {epoch+1} of {epochs}")
train_epoch_loss, train_epoch_accuracy = fit(
model, train_dataloader, train_dataset, optimizer, criterion
)
val_epoch_loss, val_epoch_accuracy = validate(
model, val_dataloader, val_dataset, criterion
)
train_loss.append(train_epoch_loss)
train_accuracy.append(train_epoch_accuracy)
val_loss.append(val_epoch_loss)
val_accuracy.append(val_epoch_accuracy)
if args['lr_scheduler']:
lr_scheduler(val_epoch_loss)
if args['early_stopping']:
early_stopping(val_epoch_loss)
if early_stopping.early_stop:
break
print(f"Train Loss: {train_epoch_loss:.4f}, Train Acc: {train_epoch_accuracy:.2f}")
print(f'Val Loss: {val_epoch_loss:.4f}, Val Acc: {val_epoch_accuracy:.2f}')
end = time.time()
print(f"Training time: {(end-start)/60:.3f} minutes")
First, at lines 109 and 110, we initialize four lists, train_loss, train_accuracy & val_loss, val_accuracy. They will store the training loss & accuracy and validation loss & accuracy for each epoch while training.
We start the training from line 112. At lines 114 and 117, we call the fit() and validate() functions by providing the required arguments. From lines 120 to 123, we append the accuracy and loss values to the respective lists.
The important stuff starts from line 124. If we provide --lr-scheduler command line argument while executing the training script, then the learning rate scheduler’s __call__() method will be executed at line 125. This in-turn makes the scheduler take one step by taking the current validation loss as the argument.
Else, if we provide --early-stopping command line argument while executing the training script, then lines 126 to 129 will be executed. Line 127 executes the __call__() method of the EarlyStopping() class. At line 128, we check whether the early_stop variable of the class is True. If so, then we print the early stopping message and break out of the training loop.
Finally, we just need to plot and save the accuracy and loss graphs. Along with that we will also save the trained model to disk. The following code block does that.
print('Saving loss and accuracy plots...')
# accuracy plots
plt.figure(figsize=(10, 7))
plt.plot(train_accuracy, color='green', label='train accuracy')
plt.plot(val_accuracy, color='blue', label='validataion accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.savefig(f"../outputs/{acc_plot_name}.png")
plt.show()
# loss plots
plt.figure(figsize=(10, 7))
plt.plot(train_loss, color='orange', label='train loss')
plt.plot(val_loss, color='red', label='validataion loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.savefig(f"../outputs/{loss_plot_name}.png")
plt.show()
# serialize the model to disk
print('Saving model...')
torch.save(model.state_dict(), f"../outputs/{model_name}.pth")
print('TRAINING COMPLETE')
This marks the end of the training script as well as all the code that we need for this tutorial. We are all set to execute our training script.
Executing the train.py Script
Now it is time to execute our training script and analyze how everything is affected while using learning rate scheduler and early stopping with PyTorch.
First, we will train our model for 100 epochs without using learning rate scheduler or early stopping. Open up your terminal/command line in the src folder and type the following command.
python train.py
You should see output similar to the following.
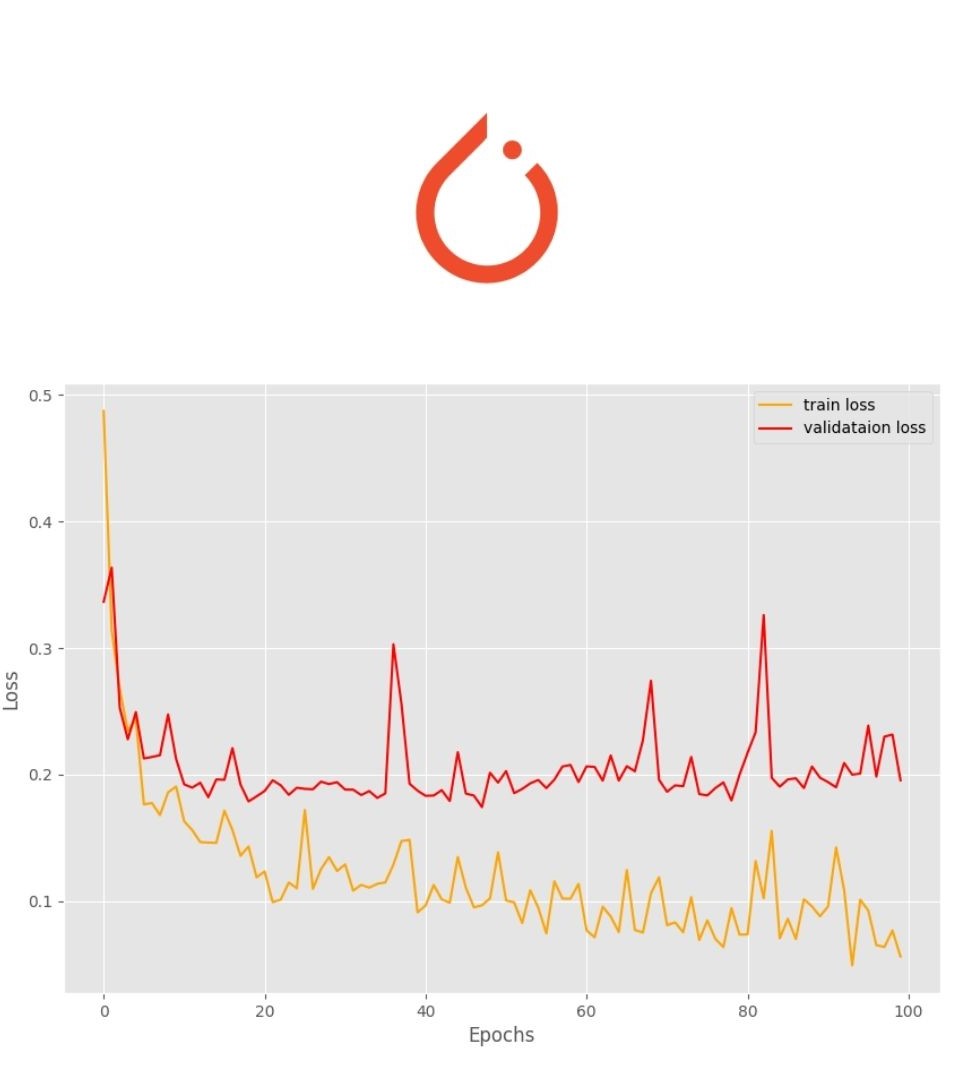
Computation device: cuda:0 23,512,130 total parameters. 4,098 training parameters. Epoch 1 of 100 Training 22it [00:22, 1.01s/it] Validating 7it [00:03, 2.00it/s] Train Loss: 0.4871, Train Acc: 78.82 Val Loss: 0.3365, Val Acc: 89.00 Epoch 2 of 100 Training ... Epoch 100 of 100 Training 22it [00:06, 3.34it/s] Validating 7it [00:02, 3.36it/s] Train Loss: 0.0565, Train Acc: 98.13 Val Loss: 0.1956, Val Acc: 89.00 Training time: 15.710 minutes Saving loss and accuracy plots... Saving model... TRAINING COMPLETE
The final epoch gives a validation accuracy of 89% and validation loss of 0.1956. Let’s analyze the graphical plots saved on the disk and get some more information.
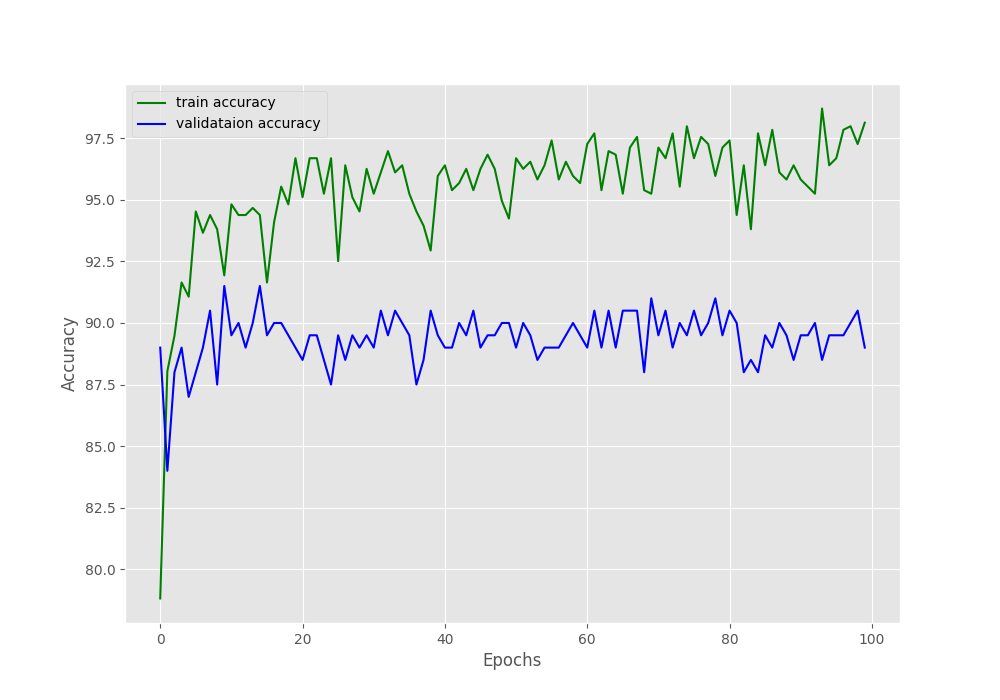
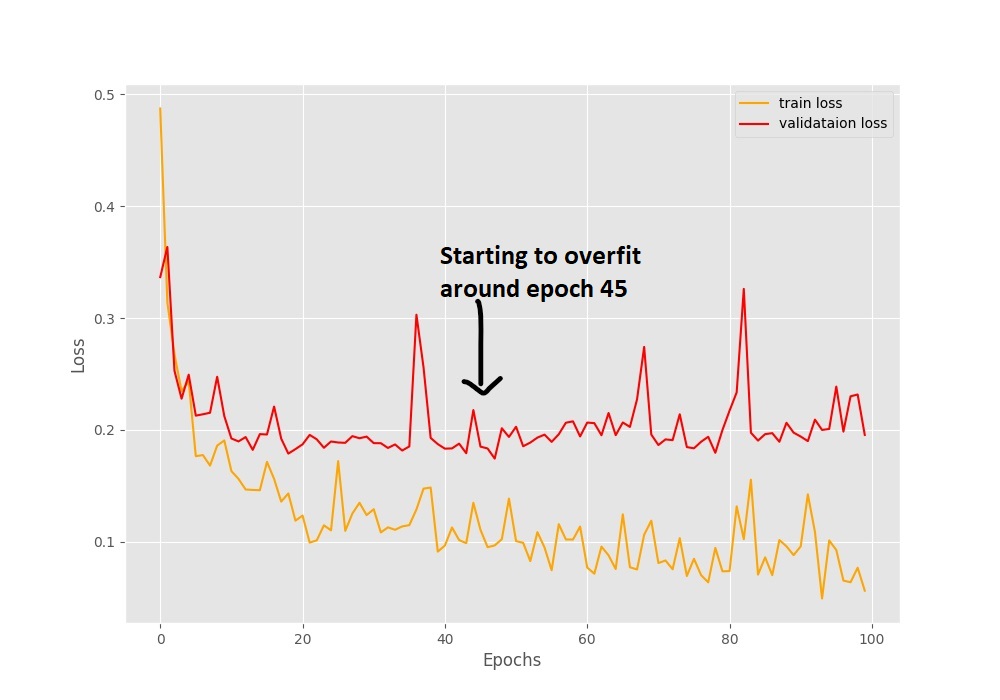
In the accuracy plot in figure 3, we can see a lot of fluctuations. The ups and downs are very severe between some of the epochs where the accuracy is differing by more than 3%. The loss plot also shows a similar trend but provides us with some more info. We can see that around epoch 45, the validation loss line starts to diverge (move upward). This is a clear indication that the model is starting to overfit and we need to reduce the learning rate for proper training to continue.
Now, let’s execute the training script along with learning rate scheduler and see whether this make a difference.
python train.py --lr-scheduler
The following is the sample output.
Computation device: cuda:0 23,512,130 total parameters. 4,098 training parameters. INFO: Initializing learning rate scheduler Epoch 1 of 100 Training 22it [00:06, 3.40it/s] Validating 7it [00:01, 4.46it/s] Train Loss: 0.5721, Train Acc: 71.47 Val Loss: 0.3808, Val Acc: 90.00 Epoch 2 of 100 Training 22it [00:05, 3.91it/s] Validating 7it [00:01, 4.77it/s] Train Loss: 0.3678, Train Acc: 85.73 Val Loss: 0.2921, Val Acc: 87.50 ... Epoch 100 of 100 Training 22it [00:07, 2.80it/s] Validating 7it [00:02, 2.90it/s] Train Loss: 0.0999, Train Acc: 97.12 Val Loss: 0.1799, Val Acc: 90.00 Training time: 16.432 minutes Saving loss and accuracy plots... Saving model... TRAINING COMPLETE
If you observe the outputs on your console, then you will get to see all the instances where the learning rate scheduler kicks in.
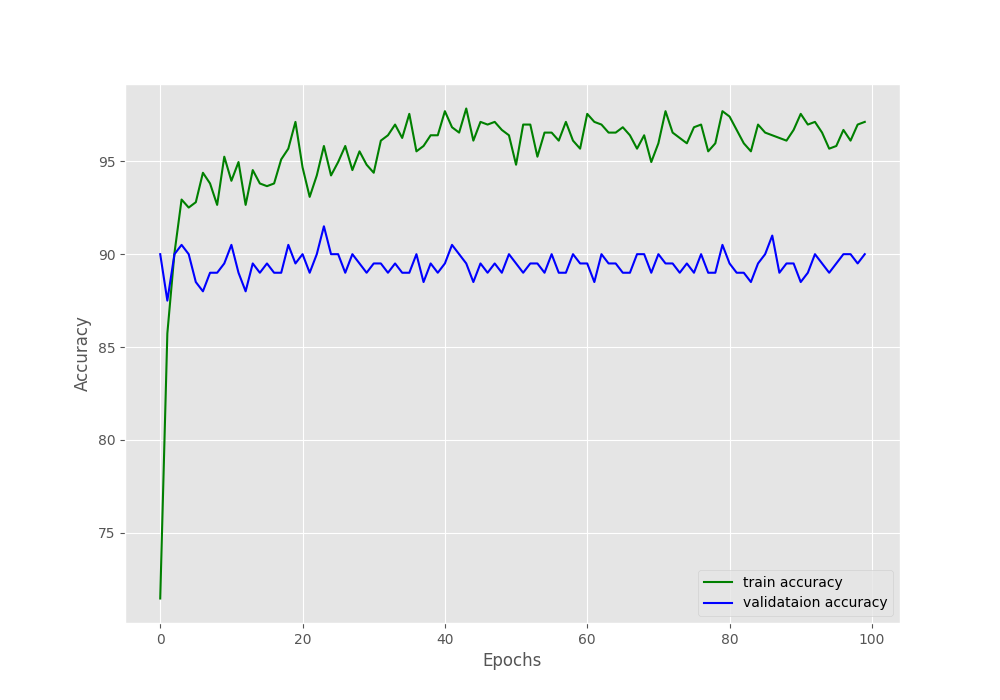
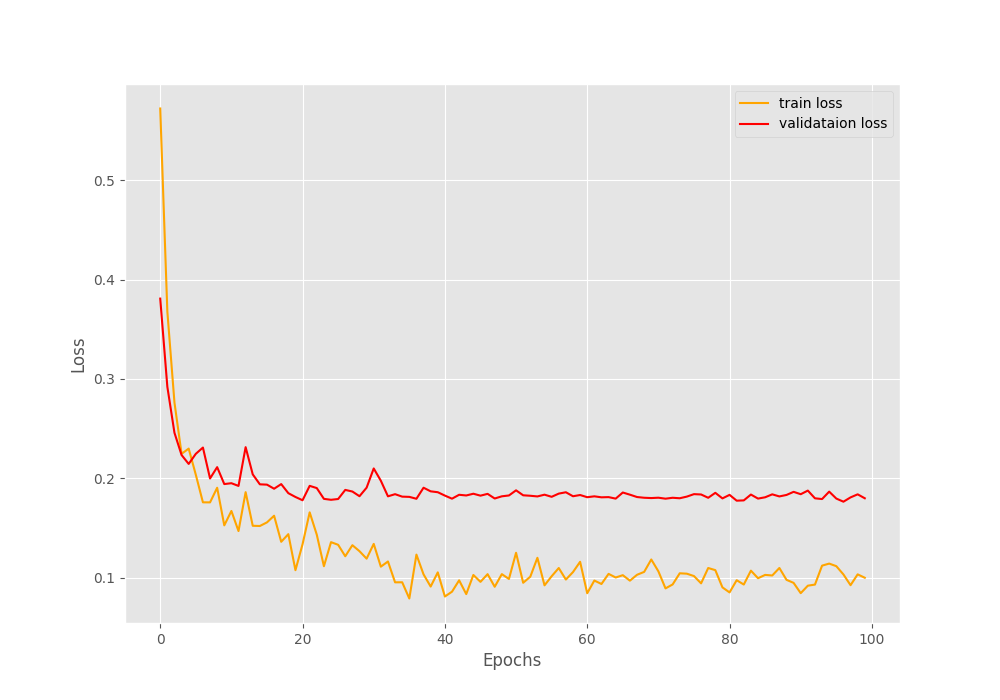
We can clearly see that the accuracy plot is a lot smoother here. By the end of the training, we are getting a validation accuracy of 90% which is higher than the previous case.
Figure 6 provides us with more useful information. This time, there is no divergence of the validation loss plot. This means that using learning rate scheduler actually worked. But if you observe closely, the validation loss starts to plateau around epoch 55. This means that we can train our model for 50-55 epochs and still get good results.
Finally, let’s use early stopping with our training script.
python train.py --early-stopping
python train.py --early-stopping Computation device: cuda 23,512,130 total parameters. 4,098 training parameters. INFO: Initializing early stopping Epoch 1 of 100 Training 22it [00:06, 3.47it/s] Validating 7it [00:01, 4.75it/s] Train Loss: 0.5843, Train Acc: 65.27 Val Loss: 0.4036, Val Acc: 88.00 Epoch 2 of 100 Training 22it [00:05, 4.07it/s] Validating 7it [00:01, 4.92it/s] Train Loss: 0.3393, Train Acc: 88.76 Val Loss: 0.2934, Val Acc: 89.50 ... Epoch 11 of 100 Training 22it [00:06, 3.19it/s] Validating 7it [00:01, 4.23it/s] INFO: Early stopping counter 4 of 5 Train Loss: 0.1460, Train Acc: 95.24 Val Loss: 0.2461, Val Acc: 88.00 Epoch 12 of 100 Training 22it [00:05, 3.69it/s] Validating 7it [00:01, 4.15it/s] Train Loss: 0.1557, Train Acc: 94.24 Val Loss: 0.1993, Val Acc: 89.50 Epoch 13 of 100 Training 22it [00:06, 3.65it/s] Validating 7it [00:01, 4.21it/s] Train Loss: 0.1428, Train Acc: 94.96 Val Loss: 0.1944, Val Acc: 89.50 Epoch 14 of 100 Training 22it [00:05, 3.68it/s] Validating 7it [00:01, 4.30it/s] INFO: Early stopping counter 5 of 5 INFO: Early stopping Training time: 1.737 minutes Saving loss and accuracy plots... Saving model... TRAINING COMPLETE
The training stopped after the validation loss did not improve 5 times in total. And our training stopped after 14 epochs. The following are the loss and accuracy plots. The final validation accuracy is comparable to the learning rate schedule case but the loss is obviously higher.
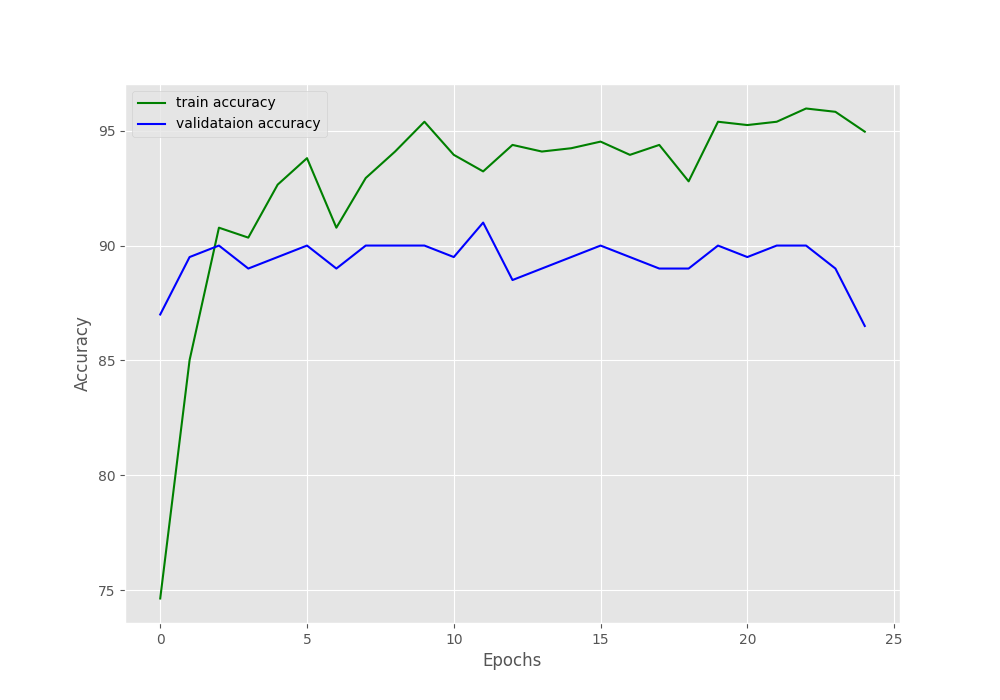
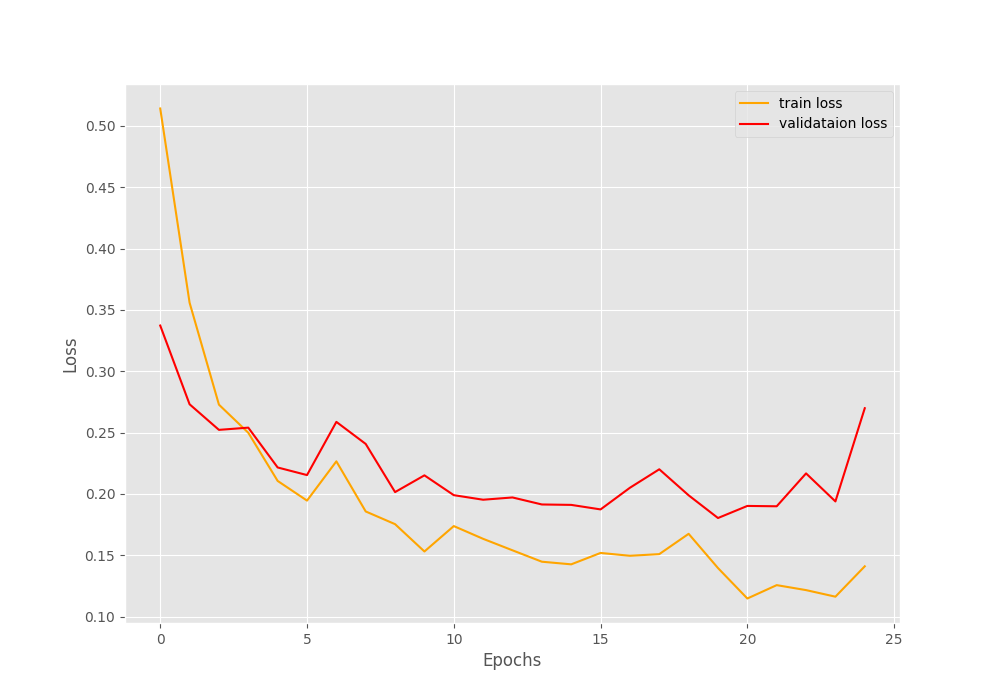
The accuracy and loss plots show the results for the 6 epochs only. Such an early end of training might result in the model not learning properly.
Although early stopping stopped the training after 6 epochs, it is very clear that using a learning rate scheduler and continuing training for more epochs is helpful. We inferred that from the previous case also. Maybe we do not need to train for 100 epochs, around 50-55 epochs is a good amount of training for the model to learn.
Summary and Conclusion
In this tutorial, you got to learn how to use the learning rate scheduler and early stopping with PyTorch. You also saw how both affect deep learning training and where they can be used to obtain better results. I hope that you learned something new.
If you have any doubts, thoughts, or suggestions, then please leave them in the comment section. I will surely address them.
You can contact me using the Contact section. You can also find me on LinkedIn, and X.

Hi Sovit,
First of all, thanks for sharing.
I notice you set the default patience for both ‘lr_scheduler’ and ‘early_stopping’ as 5. So if run with the default patience, early_stopping will stop the training right after lr_scheduler reducing the learning rate. Wouldn’t you want to set early_stopping’s patience greater than lr_scheduler’s so it has a chance to see if the halving the learning rate could reduce the validation error? That is maybe why you training stopped early before the optimal. Regards
Hi Jeo. Thanks for reaching out. If you take a look, then we are not using ‘lr_scheduler’ and ‘early_stopping’ both in a single training cycle. We are using either ‘lr_scheduler’ or ‘early_stopping’. But if you really think that the code uses both at the same time at some point, then please point line number. I will surely correct that out.
Thank you for the great explanation!!
Happy that you liked it.
Hello, Sovit Ranjan Rath, how can I reach you?
You can send an email at [email protected]
You should reset the counter when a new best validation loss is reached. Otherwise the “patience” mechanism will stop working after some time.
Hi. Thanks. Will check out what you have mentioned.
Yes i was going to right the same thing. It should be 5 consecutive epochs with no gain rather than 5 cumulative epochs (for a patience value of 5)
Hello Greg. I have updated the relevant code in utils.py. Have updated the colab notebook and src zip file as well.
Thanks for notifying these bugs.
Hi!
Just wanted to clarify something. Suppose we have a consecutive validation loss of
0.6920, 0.6923, 0.6921, 0.6922 > this loss causes the counter to increase in every step, it compares if the loss is smaller than the best loss i.e 0.6920(according to the code). Just wanted to clarify should the counter not reset from 0.6923 –> 0.6921 as the loss has decreased. Why should the comparison be done w.r.t 0.6920?
Hi Nayan. So, when the loss goes from 0.6923 to 0.6921, then 0.6920 is still the best loss. The counter will only reset if we have 0.6919 somewhere ahead. I hope this clarifies that doubt.
Thanks! Got your point 🙂
Welcome. Glad I could help.