
In this article, we will explore the Phi-3 model from the official technical report published by Microsoft.
Language models, especially the Small Langauge Models (SLMs) have come a long way in the last couple of years. We have seen the scale of open-source language models reduce from 70B to 30B to 14B and now even below 7B parameters. All of this happens while trying to keep the performance the same as that of large language models to a certain extent. In this regard, perhaps the Phi family of models from Microsoft researchers are at the forefront. In this article, we will cover some of the important aspects of the Phi-3 model as mentioned in the Phi-3 technical report.
What will we cover in this article?
- Why do we need Phi-3?
- What is the architecture of Phi-3 and what are its variants?
- What is the dataset collection strategy and training regime of Phi-3?
- How does Phi-3 stack up against larger models and similar models in its class?
Note: This is not an in-depth guide to Phi-3. Instead, the aim is to condense the most important aspects of the technical report to get an instant overview of the model. This can be considered as a quick overview of the important elements of the Phi-3 technical report by Microsoft.
The Motivation Behind Phi-3
The primary reason behind the creation of Phi-3, especially the Phi-3 Mini with 3.8B parameters is rivaling it against larger models in the range of 7B parameters. At the moment, the AI industry considers 7B models as SLMs (Small Language Models). Although they are cheap in compute and can run fast enough locally, they are difficult to deploy on mobile and edge devices.
This led to the creation of the Phi-3 model across various scales competing with models much larger in parameters.
Phi-3 Architecture and Variants
The Phi-3 Mini model is based on the now well known Transformer decoder architecture. There are two variants of the model, one with a 4K context length and another with a 128K context length. It uses the same tokenizer as the Llama-2 and same vocabulary size as well (32064).
The following table shows more details.
| Model | Tokenizer | Vocabulary | Other Details |
| Phi-3 Mini (3.8B) | Llama 2 | 32064 | 3072 hidden dimensions, 32 heads, and 32 layers |
| Phi-3 Small (7B) | Tiktoken | 100352 | 4096 hidden dimensions, 32 heads, and 32 layers |
| Phi-3 Medium (14B) | Llama 2 | 32064 | 5120 hidden dimensions, 40 heads, 40 layers |
Additionally, we have the Phi-3 Vision model as well. It is a multimodal model capable of processing image and text prompts. It contains a Vision Transformer encoder and a Transformer Decoder. To be specific, the encoder is CLIP ViT-L/14. The model is capable of natural image understanding, reasoning, and has OCR capabilities as well.
Data Collection and Training Regine for Phi-3
Phi-3 follows the previous Phi model criteria for data collection, i.e., heavily filtered web, textbook, and academic data.
The models were trained in two phases: first mostly with web source data for teaching general knowledge, and second by merging with even more heavily filtered web data.
In the post-training phase, the models went under SFT (Supervised Fine Tuning) and DPO (Direct Preference Optimization).
You can find more details on fine-tuning Phi 1.5 with different methodologies in the following articles.
Phi-3 Benchmarks
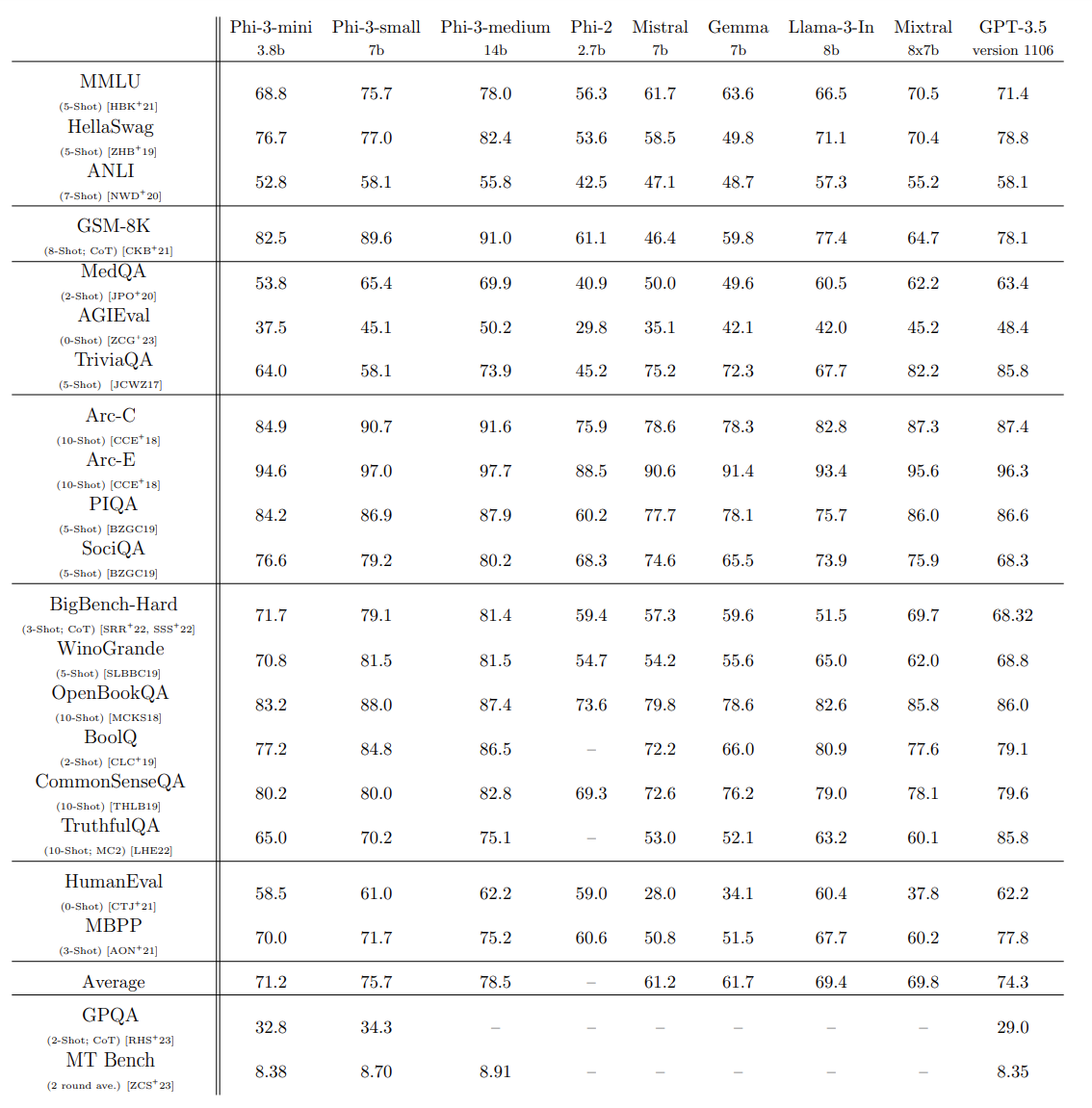
The authors stack the Phi-3 models against several industry leading models such as Mistral, LLama-3, Gemma, Mixtral, and GPT-3.5.
Interestingly, the Phi-3 Mini model with just 3.8B parameters beats almost all the 7B parameter models in several benchmarks including MMLU, HellaSwag, Arc, and HumanEval. In fact, it is able to beat the Llama-3 8B model in some cases as well and the Phi-3 Small 7B model beats Llama-2 8B in all benchmarks.
The following table from the technical report gives a more detailed overview.
Phi-3 on Mobile
Given the small size of Phi-3 Mini, the authors were able to run the 4-bit quantized version of the model on an iPhone with A16 bionic chip natively. The model produced 12 tokens per second.
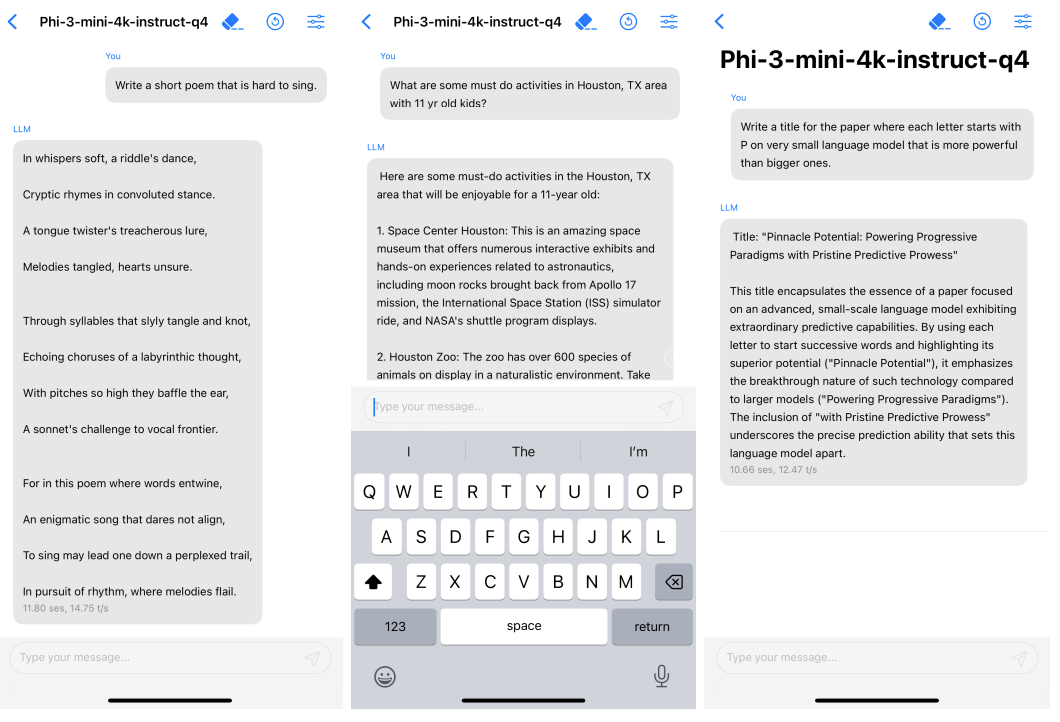
This gives us a much better idea of how the world of Small Language Models is going to be for mobile devices. We will be able to run very performant models locally on our mobile and edge devices instead of making API calls.
Notable Sections from the Technical Report to Go Through
Here are some sections from the technical report that are important but we skipped for brevity.
- Section 4 – Safety
- Section 5 – Weakness
Summary and Conclusion
We covered a short overview of the Phi-3 technical report here. We started from the motive for creating Phi-3, moved to the model architectures, and discussed the benchmarks briefly. I hope this gives you a good idea of where Phi-3 stands in the LLM landscape. Going through the entire report will surely give more insights.
If you have any doubts, thoughts, or suggestions, please leave them in the comment section. I will surely address them.
You can contact me using the Contact section. You can also find me on LinkedIn, and X.
References

Hi author,
I has look fine tune mask2former of blog of you, and want to download code to study, but don’t success. So can you give a link to download it.
Thank author very much.