

DINOv2 is one of the most well-known self-supervised vision models. Its pretrained backbone can be used for several downstream tasks. These include image classification, image embedding search, semantic segmentation, depth estimation, and object detection. In this article, we will cover the image classification task using DINOv2. This is one of the most of the most fundamental topics in deep learning based computer vision where essentially all downstream tasks begin. Furthermore, we will also compare the results between fine-tuning the entire model and transfer learning.
Among others, we will answer the following questions in detail in this article?
- Why do we need a comparison between fine-tuning and transfer learning results with DINOv2 for image classification?
- How do we approach the problem statement?
- How do we set up the project and which dataset will we use?
- What results can we expect from this experiment?
Why use DINOv2 for Image Classification for Fine-Tuning vs Transfer Learning?
One of the primary highlights of the DINOv2 paper was its ability to perform exceptionally well in downstream tasks without fine-tuning the backbone. The DINOv2 model, based on a modified Vision Transformer backbone was trained on more than 142 million images in a self-supervised manner. This led to a powerful backbone that can be used for numerous downstream tasks by just adding and training a task head.
This is exactly what we will be testing in this article’s experiments.
In our previous article, we covered the basics of DINOv2. We covered tasks, results, and comparisons with other similar models and frameworks in the self-supervised arena.
The authors explicitly focused on linear probing for image classification where they trained a linear classifier on ImageNet on top of the frozen features.
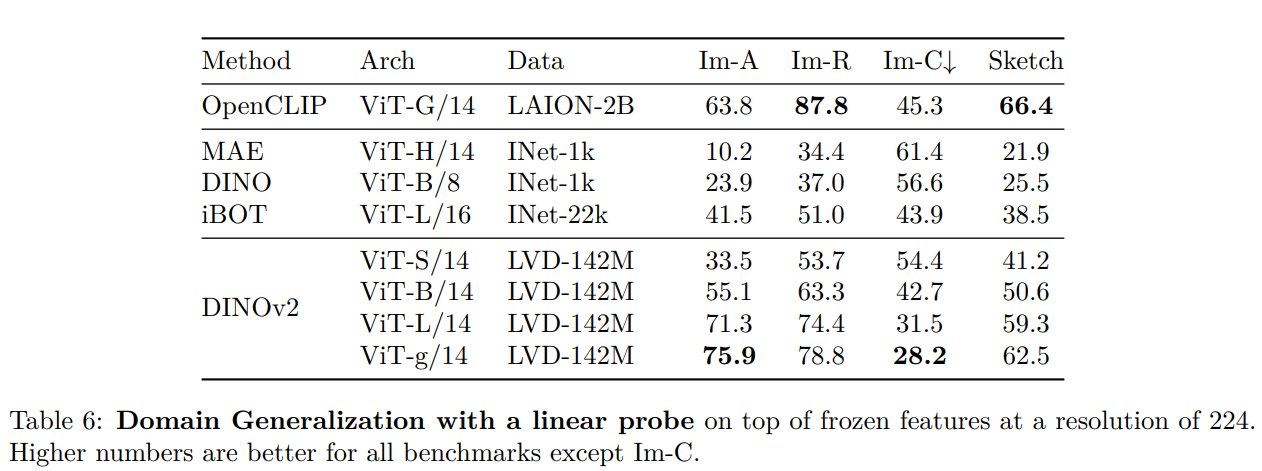
In this article, we will test this out on a smaller dataset and will try to assert its relevance.
How Do We Approach the Problem Statement?
We will download the official backbone weights from Torchhub and carry out two separate experiments:
- During the first experiment, we will make both, the backbone (DINOv2 pretrained) and the linear classifier trainable.
- In the second experiment, we will freeze the backbone, and make the linear classifier only trainable.
By the end of these experiments, we should have a definite result with us.
The Cotton Disease Classification Dataset
There is no doubt that the LVD-142M dataset that the DINOv2 model has been trained on must have almost every type of image that we can think of. Still, to compare and contrast the results, we try to choose a unique dataset.
For our experiments, we choose the Customized Cotton Disease Dataset from Kaggle. The dataset contains images of cotton pests and cotton leaf diseases.
If you wish to replicate the training results, I recommend downloading the dataset. After downloading and extracting it, you should see the following directory structure.
├── Cotton-Disease-Training
│ └── trainning
│ └── Cotton leaves - Training
├── Cotton-Disease-Validation
│ └── validation
│ └── Cotton plant disease-Validation
└── Customized Cotton Dataset-Complete
└── content
├── trainning
└── validation
Although there are several subdirectories, we will focus on the Cotton-Disease-Training and Cotton-Disease-Validation directories. They contain the training and validation data respectively.
There are a total of 6628 training and 356 validation samples across 8 classes. The classes are:
['Aphids', 'Army worm', 'Bacterial blight', 'Cotton Boll Rot', 'Green Cotton Boll', 'Healthy', 'Powdery mildew', 'Target spot']
Following are a few images from the dataset.

If you are interested, do take a look at training a Vision Transformer model on the cotton disease classification dataset. The article also covers the visualization of activation maps after fine-tuning the model.
Directory Structure
Following is the project directory structure.
├── input
│ ├── Cotton-Disease-Training
│ ├── Cotton-Disease-Validation
│ ├── Customized Cotton Dataset-Complete
│ ├── inference_data
│ └── customized-cotton-disease-dataset.zip
├── outputs
│ └── transfer_learning
└── src
├── datasets.py
├── inference.py
├── model.py
├── train.py
└── utils.py
- The
inputdirectory contains the downloaded dataset we saw in the previous section. - The
outputsdirectory will contain all the training and inference results. - All the Python code files are present in the
srcdirectory.
All the code files and trained models are available via the download code section. To train the model on your own, you will need to download the dataset and arrange it in the above directory structure.
Download Code
Training DINOv2 for Image Classification – Fine-Tuning vs Transfer Learning
Let’s get down to the training experiments and results without any further delay. Although we will not discuss all the Python code files in detail, we will do so for some of the important ones.
Loading the Pretrained DINOv2 Model
Loading the pretrained DINOv2 model is straightforward. We can do so easily with TorchHub. It is worthwhile to note that the official DINOv2 repository provides ImageNet-1k fine-tuned models as well. However, we will load the pretrained backbone only and add our classifier head on top of that.
The code for preparing the model is present in src/model.py file.
import torch
from collections import OrderedDict
def build_model(num_classes=10, fine_tune=False):
backobone_model = torch.hub.load('facebookresearch/dinov2', 'dinov2_vits14')
model = torch.nn.Sequential(OrderedDict([
('backbone', backobone_model),
('head', torch.nn.Linear(
in_features=384, out_features=num_classes, bias=True
))
]))
if not fine_tune:
for params in model.backbone.parameters():
params.requires_grad = False
return model
if __name__ == '__main__':
model = build_model()
print(model)
# Total parameters and trainable parameters.
total_params = sum(p.numel() for p in model.parameters())
print(f"{total_params:,} total parameters.")
total_trainable_params = sum(
p.numel() for p in model.parameters() if p.requires_grad)
print(f"{total_trainable_params:,} training parameters.")
We are using the smallest DINOv2 model for our use case, the DINOv2 VIT-Small14. The pretrained backbone contains exactly 22,059,656 parameters. We will either fine-tune or freeze (during transfer learning) the backbone according to the fine_tune parameter in the build_model function.
First, we load the model from torch.hub. Printing the DINOv2 backbone model gives us the following architecture.
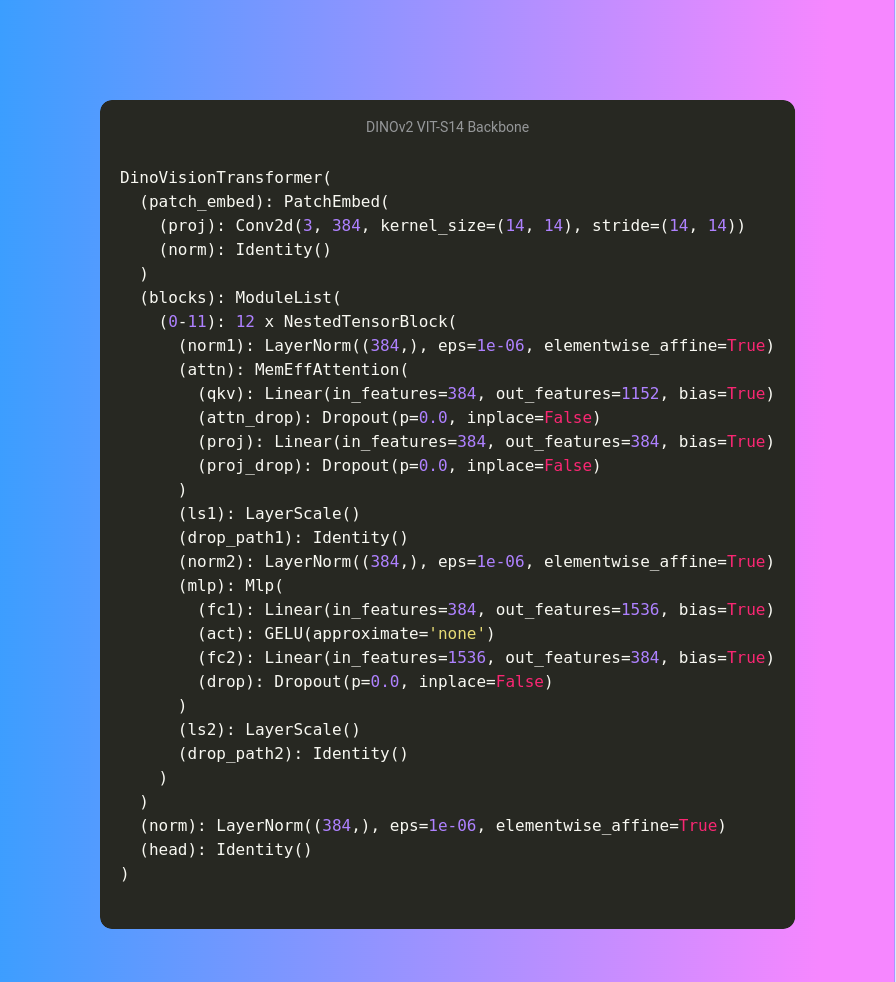
As we can see, the final layer of the backbone contains 384 output features. So, applying a linear classifier on top of it will require 384 input features.
After loading the backbone, we create a Sequential Model with named OrderDict. This helps us to separate the backbone and the head. Following that, according to the fine_tune parameter we either freeze or unfreeze the backbone.
The Dataset Transforms
We use quite a few dataset transforms and augmentations during the training dataset preparation. Following is the code chunk from src/datasets.py.
# Training transforms
def get_train_transform(image_size):
train_transform = transforms.Compose([
transforms.Resize((image_size, image_size)),
transforms.RandomResizedCrop((224, 224)),
transforms.RandomHorizontalFlip(p=0.5),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
])
return train_transform
# Validation transforms
def get_valid_transform(image_size):
valid_transform = transforms.Compose([
transforms.Resize((image_size, image_size)),
transforms.CenterCrop((224, 224)),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
])
return valid_transform
For training:
- First, we are resizing the images to 256×256 resolution.
- Second, we apply RandomResizedCrop with a resolution of 224×224.
- Third, we apply horizontal flipping with a 50% probability.
For the validation dataset, we resize the images into 256×256 resolution and use center cropping of 224×224. This follows the exact rule that the authors follow for fine-tuning on the ImageNet-1k dataset.
I was unable to find the LVD-142M normalization statistics for fine-tuning purposes. So, we are using the ImageNet-1K normalization values instead.
Training Arguments and Hyperparameters
The train.py file in the src directory is the executable training script. It allows us to pass the following command line arguments while training.
parser.add_argument(
'-e', '--epochs',
type=int,
default=10,
help='Number of epochs to train our network for'
)
parser.add_argument(
'-lr', '--learning-rate',
type=float,
dest='learning_rate',
default=0.001,
help='Learning rate for training the model'
)
parser.add_argument(
'-b', '--batch-size',
dest='batch_size',
default=32,
type=int
)
parser.add_argument(
'--save-name',
dest='save_name',
default='model',
help='file name of the final model to save'
)
parser.add_argument(
'--fine-tune',
dest='fine_tune',
action='store_true',
help='whether to fine-tune the model or train the classifier layer only'
)
parser.add_argument(
'--out-dir',
dest='out_dir',
default='results',
help='output sub-directory path inside the `outputs` directory'
)
parser.add_argument(
'--scheduler',
type=int,
nargs='+',
default=[1000],
help='number of epochs after which learning rate scheduler is applied'
)
For each of the training experiments, we will use a different learning rate. As during transfer learning, we are training the classifier head only, the learning rate can be higher compared to the fine-tuning stage. Furthermore, the --out-dir argument would allow us to save the results in different subdirectories in the outputs directory for each training run.
Additionally, we are using the SGD optimizer as mentioned in the paper. In section B Implementation Details of the paper, under section B.3 Linear probing evaluation, the authors mention that they use the SGD optimizer for linear probing. However, for pretraining, AdamW is used.
Fine Tuning Experiment with DINOv2 for Image Classification
We will start with the fine-tuning experiment. The following command can be executed within the src directory.
python train.py -lr 0.0001 --epochs 20 --batch 32 --out-dir fine_tuning --fine-tune
For fine-tuning, we are using a learning rate of 0.0001 and a batch size of 32. We do not apply any learning rate scheduler here as the base learning rate is already low. We are using a lower batch size as the training runs were carried out on an RTX 3070 Ti laptop GPU. This way, we can keep the same batch size for both transfer learning and fine-tuning for fair comparison. During fine-tuning, we need more VRAM as all the parameters are being tuned.
We get the following results after training (trimmed for brevity).
Namespace(epochs=20, learning_rate=0.0001, batch_size=32, save_name='model', fine_tune=True, out_dir='fine_tuning', scheduler=[1000])
[INFO]: Number of training images: 6628
[INFO]: Number of validation images: 357
[INFO]: Classes: ['Aphids', 'Army worm', 'Bacterial blight', 'Cotton Boll Rot', 'Green Cotton Boll', 'Healthy', 'Powdery mildew', 'Target spot']
Computation device: cuda
Learning rate: 0.0001
Epochs to train for: 20
Using cache found in /home/sovit/.cache/torch/hub/facebookresearch_dinov2_main
/home/sovit/.cache/torch/hub/facebookresearch_dinov2_main/dinov2/layers/swiglu_ffn.py:51: UserWarning: xFormers is not available (SwiGLU)
warnings.warn("xFormers is not available (SwiGLU)")
/home/sovit/.cache/torch/hub/facebookresearch_dinov2_main/dinov2/layers/attention.py:33: UserWarning: xFormers is not available (Attention)
warnings.warn("xFormers is not available (Attention)")
/home/sovit/.cache/torch/hub/facebookresearch_dinov2_main/dinov2/layers/block.py:40: UserWarning: xFormers is not available (Block)
warnings.warn("xFormers is not available (Block)")
Sequential(
(backbone): DinoVisionTransformer(
(patch_embed): PatchEmbed(
(proj): Conv2d(3, 384, kernel_size=(14, 14), stride=(14, 14))
(norm): Identity()
)
(blocks): ModuleList(
(0-11): 12 x NestedTensorBlock(
(norm1): LayerNorm((384,), eps=1e-06, elementwise_affine=True)
(attn): MemEffAttention(
(qkv): Linear(in_features=384, out_features=1152, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=384, out_features=384, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
)
(ls1): LayerScale()
(drop_path1): Identity()
(norm2): LayerNorm((384,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=384, out_features=1536, bias=True)
(act): GELU(approximate='none')
(fc2): Linear(in_features=1536, out_features=384, bias=True)
(drop): Dropout(p=0.0, inplace=False)
)
(ls2): LayerScale()
(drop_path2): Identity()
)
)
(norm): LayerNorm((384,), eps=1e-06, elementwise_affine=True)
(head): Identity()
)
(head): Linear(in_features=384, out_features=8, bias=True)
)
22,059,656 total parameters.
22,059,656 training parameters.
[INFO]: Epoch 1 of 20
Training
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 208/208 [00:57<00:00, 3.62it/s]
Validation
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 12/12 [00:01<00:00, 6.86it/s]
Training loss: 1.424, training acc: 48.899
Validation loss: 1.222, validation acc: 57.983
Best validation loss: 1.2215932880838711
Saving best model for epoch: 1
--------------------------------------------------
LR for next epoch: [0.0001]
[INFO]: Epoch 2 of 20
Training
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 208/208 [01:12<00:00, 2.86it/s]
Validation
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 12/12 [00:01<00:00, 6.75it/s]
Training loss: 0.736, training acc: 74.713
Validation loss: 1.199, validation acc: 62.745
Best validation loss: 1.1988442229727905
Saving best model for epoch: 2
--------------------------------------------------
LR for next epoch: [0.0001]
[INFO]: Epoch 3 of 20
Training
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 208/208 [01:15<00:00, 2.74it/s]
Validation
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 12/12 [00:01<00:00, 6.96it/s]
Training loss: 0.498, training acc: 82.891
Validation loss: 0.712, validation acc: 75.630
Best validation loss: 0.7115460994342963
Saving best model for epoch: 3
--------------------------------------------------
.
.
.
LR for next epoch: [0.0001]
[INFO]: Epoch 19 of 20
Training
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 208/208 [01:14<00:00, 2.77it/s]
Validation
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 12/12 [00:01<00:00, 6.68it/s]
Training loss: 0.107, training acc: 96.349
Validation loss: 0.359, validation acc: 89.916
--------------------------------------------------
LR for next epoch: [0.0001]
[INFO]: Epoch 20 of 20
Training
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 208/208 [01:17<00:00, 2.70it/s]
Validation
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 12/12 [00:01<00:00, 6.98it/s]
Training loss: 0.101, training acc: 96.334
Validation loss: 0.285, validation acc: 92.997
Best validation loss: 0.2845952277518033
Saving best model for epoch: 20
--------------------------------------------------
LR for next epoch: [0.0001]
TRAINING COMPLETE
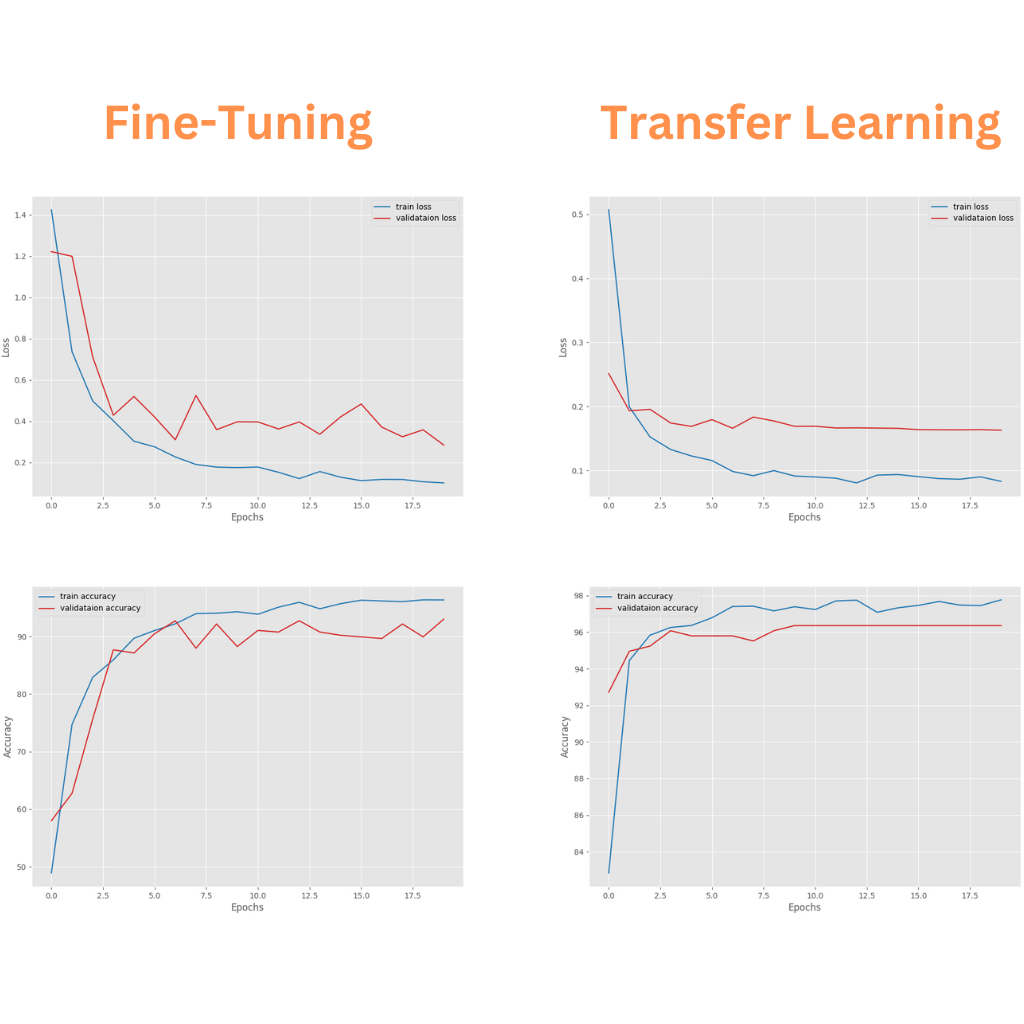
We have the lowest validation loss of 0.284 and the highest validation accuracy of 92.99% on the last epoch.
Following are the accuracy and loss graphs from the fine-tuning training run.
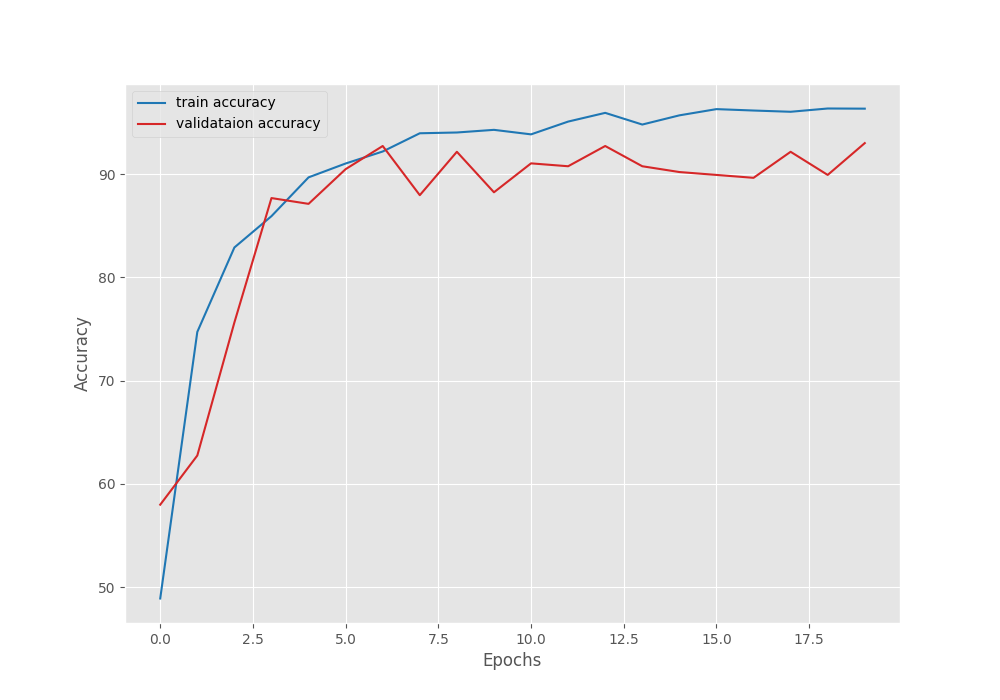
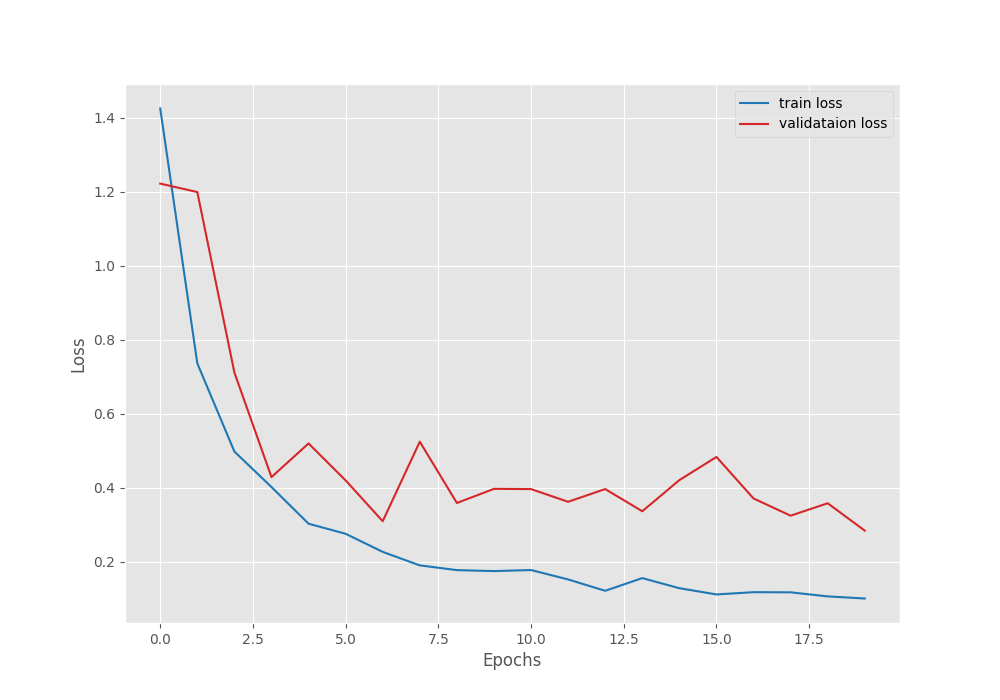
Perhaps training for a bit longer would have resulted in slightly lower validation loss and slightly higher validation accuracy. However, it is difficult to say so concretely.
Transfer Learning Experiment with DINOv2 for Image Classification
Next, coming to the transfer learning experiment.
python train.py -lr 0.0005 --epochs 20 --batch 32 --out-dir transfer_learning --scheduler 10
For transfer learning, we are using a learning rate of 0.0005 and the same batch size of 32. We are applying a learning rate scheduler after 10 epochs to reduce the learning rate by a factor of 10.
Following are the results that we get.
Namespace(epochs=20, learning_rate=0.0005, batch_size=32, save_name='model', fine_tune=False, out_dir='transfer_learning', scheduler=[10])
[INFO]: Number of training images: 6628
[INFO]: Number of validation images: 357
[INFO]: Classes: ['Aphids', 'Army worm', 'Bacterial blight', 'Cotton Boll Rot', 'Green Cotton Boll', 'Healthy', 'Powdery mildew', 'Target spot']
Computation device: cuda
Learning rate: 0.0005
Epochs to train for: 20
Using cache found in /home/sovit/.cache/torch/hub/facebookresearch_dinov2_main
/home/sovit/.cache/torch/hub/facebookresearch_dinov2_main/dinov2/layers/swiglu_ffn.py:51: UserWarning: xFormers is not available (SwiGLU)
warnings.warn("xFormers is not available (SwiGLU)")
/home/sovit/.cache/torch/hub/facebookresearch_dinov2_main/dinov2/layers/attention.py:33: UserWarning: xFormers is not available (Attention)
warnings.warn("xFormers is not available (Attention)")
/home/sovit/.cache/torch/hub/facebookresearch_dinov2_main/dinov2/layers/block.py:40: UserWarning: xFormers is not available (Block)
warnings.warn("xFormers is not available (Block)")
Sequential(
(backbone): DinoVisionTransformer(
(patch_embed): PatchEmbed(
(proj): Conv2d(3, 384, kernel_size=(14, 14), stride=(14, 14))
(norm): Identity()
)
(blocks): ModuleList(
(0-11): 12 x NestedTensorBlock(
(norm1): LayerNorm((384,), eps=1e-06, elementwise_affine=True)
(attn): MemEffAttention(
(qkv): Linear(in_features=384, out_features=1152, bias=True)
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=384, out_features=384, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
)
(ls1): LayerScale()
(drop_path1): Identity()
(norm2): LayerNorm((384,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=384, out_features=1536, bias=True)
(act): GELU(approximate='none')
(fc2): Linear(in_features=1536, out_features=384, bias=True)
(drop): Dropout(p=0.0, inplace=False)
)
(ls2): LayerScale()
(drop_path2): Identity()
)
)
(norm): LayerNorm((384,), eps=1e-06, elementwise_affine=True)
(head): Identity()
)
(head): Linear(in_features=384, out_features=8, bias=True)
)
22,059,656 total parameters.
3,080 training parameters.
[INFO]: Epoch 1 of 20
Training
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 208/208 [00:19<00:00, 10.88it/s]
Validation
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 12/12 [00:01<00:00, 8.18it/s]
Training loss: 0.507, training acc: 82.830
Validation loss: 0.251, validation acc: 92.717
Best validation loss: 0.2513936141816278
Saving best model for epoch: 1
--------------------------------------------------
LR for next epoch: [0.0005]
[INFO]: Epoch 2 of 20
Training
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 208/208 [00:19<00:00, 10.85it/s]
Validation
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 12/12 [00:01<00:00, 8.01it/s]
Training loss: 0.199, training acc: 94.448
Validation loss: 0.193, validation acc: 94.958
Best validation loss: 0.1931647778643916
Saving best model for epoch: 2
--------------------------------------------------
LR for next epoch: [0.0005]
[INFO]: Epoch 3 of 20
Training
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 208/208 [00:19<00:00, 10.43it/s]
Validation
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 12/12 [00:01<00:00, 7.84it/s]
Training loss: 0.152, training acc: 95.836
Validation loss: 0.196, validation acc: 95.238
--------------------------------------------------
LR for next epoch: [0.0005]
[INFO]: Epoch 4 of 20
Training
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 208/208 [00:21<00:00, 9.54it/s]
Validation
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 12/12 [00:01<00:00, 6.92it/s]
Training loss: 0.133, training acc: 96.258
Validation loss: 0.174, validation acc: 96.078
Best validation loss: 0.17411072571606687
Saving best model for epoch: 4
--------------------------------------------------
LR for next epoch: [0.0005]
[INFO]: Epoch 5 of 20
Training
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 208/208 [00:21<00:00, 9.61it/s]
Validation
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 12/12 [00:01<00:00, 7.14it/s]
Training loss: 0.123, training acc: 96.364
Validation loss: 0.169, validation acc: 95.798
Best validation loss: 0.16880107550726584
Saving best model for epoch: 5
--------------------------------------------------
LR for next epoch: [0.0005]
[INFO]: Epoch 6 of 20
Training
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 208/208 [00:22<00:00, 9.28it/s]
Validation
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 12/12 [00:01<00:00, 6.98it/s]
Training loss: 0.115, training acc: 96.786
Validation loss: 0.179, validation acc: 95.798
--------------------------------------------------
LR for next epoch: [0.0005]
[INFO]: Epoch 7 of 20
Training
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 208/208 [00:23<00:00, 8.89it/s]
Validation
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 12/12 [00:01<00:00, 6.92it/s]
Training loss: 0.098, training acc: 97.405
Validation loss: 0.166, validation acc: 95.798
Best validation loss: 0.16586051349683353
Saving best model for epoch: 7
--------------------------------------------------
.
.
.
LR for next epoch: [5e-05]
[INFO]: Epoch 19 of 20
Training
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 208/208 [00:27<00:00, 7.44it/s]
Validation
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 12/12 [00:01<00:00, 6.90it/s]
Training loss: 0.090, training acc: 97.450
Validation loss: 0.164, validation acc: 96.359
--------------------------------------------------
LR for next epoch: [5e-05]
[INFO]: Epoch 20 of 20
Training
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 208/208 [00:27<00:00, 7.68it/s]
Validation
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 12/12 [00:01<00:00, 6.93it/s]
Training loss: 0.083, training acc: 97.767
Validation loss: 0.163, validation acc: 96.359
Best validation loss: 0.16278913566687456
Saving best model for epoch: 20
--------------------------------------------------
LR for next epoch: [5e-05]
TRAINING COMPLETE
Interestingly, we crossed 95% validation accuracy within just 3 epochs. Compared to fine-tuning, the model converged a lot faster. In fact, we can say that the model never converged during the fine-tuning stage. The final validation accuracy in this run is 96.356% with a validation loss of 0.163.
The following are the transfer learning accuracy and loss graphs.
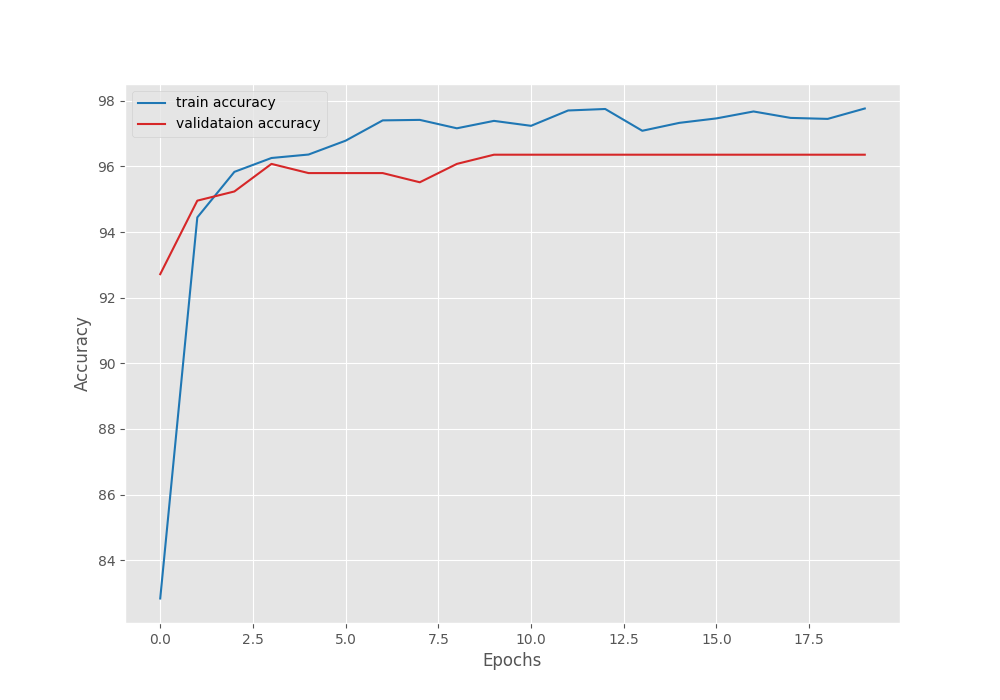
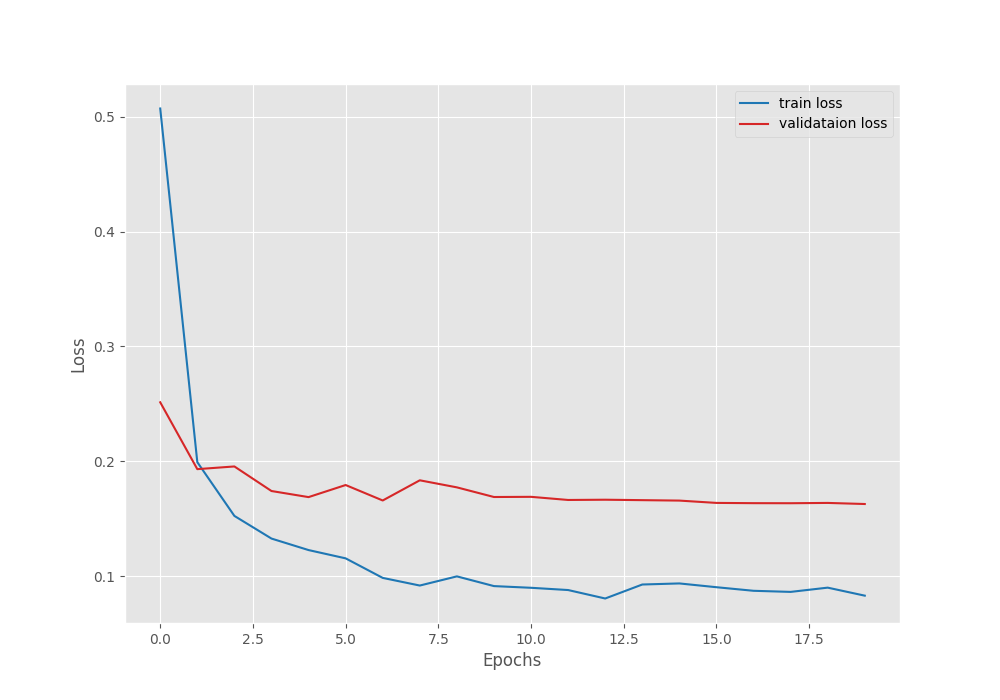
It seems as though the validation accuracy plateaued after applying learning scheduling, however, the validation loss still kept improving marginally.
Observations and Takeaways
From an initial analysis, it is clear that transfer learning with DINOv2 for image classification works really well. Perhaps, as the authors suggested, we do not need to fine-tune the entire model on a new dataset.
However, there are other factors to consider. For example, during fine-tuning, we are tuning all the parameters. The ImageNet-1k normalization values that we used may not be the optimal ones. Also, we never experimented with using a lower learning rate for the backbone and a higher one for the classifier head when fine-tuning. That can make a difference in such cases.
If you tend to dive deeper and follow up on some of the experiments discussed in this section, do share your findings in the comment section. It will surely help others learn as well.
Summary and Conclusion
In this article, we used a pretrained DINOv2 backbone model for image classification. We carried out two experiments, fine-tuning and transfer learning. It is clear that from the get-go, transfer learning works extremely well with a frozen DINOv2 backbone. Although we can dive a bit deeper into the fine-tuning experiments. I hope this article was worth your time.
If you have any doubts, thoughts, or suggestions, please leave them in the comment section. I will surely address them.
You can contact me using the Contact section. You can also find me on LinkedIn, and X.

2 thoughts on “DINOv2 for Image Classification: Fine-Tuning vs Transfer Learning”