

A Support Vector Machine (SVM) is really a powerful Machine Learning Model. It is capable of performing both classification and regression. And Iris flower data set is just perfect for analyzing SVM. So, in this article, we are going to take a peek into the SVM model by using the Iris data set.
So, power up your jupyter notebook and follow along.
Getting the data
First, let’s load the data from the Scikit-Learn library.
from sklearn import datasets iris = datasets.load_iris
Analyzing the Data
In this section, we will be analyzing the Iris data set and also visualize the data for better understanding. Also, it is a good thing to keep in mind that the data set contains 150 instances.
Looking at the keys that are available with the data:
iris.keys()
dict_keys(['data', 'target', 'target_names', 'DESCR', 'feature_names', 'filename'])
Looks like we can gather a lot of information about the data set. You can start looking at the relevant keys one by one.
iris.target_names
array(['setosa', 'versicolor', 'virginica'], dtype='<U10')
So, we have three flowers as the target names in the data set. The Iris setosa, Iris versicolor, and Iris Virginica. As you must have observed, the target_name is an array.
Further, you can have a look at the `target` feature and how our machine learning model is going to interpret it.
iris.target
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, ...])
iris.target.dtype
dtype('int32')
So basically, we have the three flower names divided into three integer classes (0, 1, 2). There is not much else to take from here.
Now, taking a look into feature_names and data keys:
iris.feature_names
['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
We have four features available. ‘sepal length’, ‘sepal width’, ‘petal length’, and ‘petal width’ are given in cm.
iris.data
array([[5.1, 3.5, 1.4, 0.2], [4.9, 3. , 1.4, 0.2], [4.7, 3.2, 1.3, 0.2], [4.6, 3.1, 1.5, 0.2], [5. , 3.6, 1.4, 0.2], [5.4, 3.9, 1.7, 0.4], [4.6, 3.4, 1.4, 0.3], [5. , 3.4, 1.5, 0.2], ...
The data key contains a 2D array where each inner array four floating point values for the four features available for the flowers.
There is nothing fancy or very much intriguing about the data set here. The next section, where we will be classifying and visualizing the data is going to much more fun.
Visualizing the Data
Let’s plot the scatter matrices for petal length (cm) vs petal width (cm)and sepal length (cm)vs sepal width (cm). Maybe we can visualize some features that will help us proceed further with the classification.
# this will label the target names for the flowers
names = plt.FuncFormatter(lambda i, *args: iris.target_names[int(i)])
plt.figure(figsize=(12, 6))
plt.subplot(121)
plt.scatter(iris.data[:, 0], iris.data[:, 1], c=iris.target)
plt.xlabel(iris.feature_names[0])
plt.ylabel(iris.feature_names[1])
plt.subplot(122)
plt.scatter(iris.data[:, 2], iris.data[:, 3], c=iris.target)
plt.xlabel(iris.feature_names[2])
plt.ylabel(iris.feature_names[3])
plt.colorbar(ticks=[0, 1, 2], format=names)
save_fig('feature_plot')
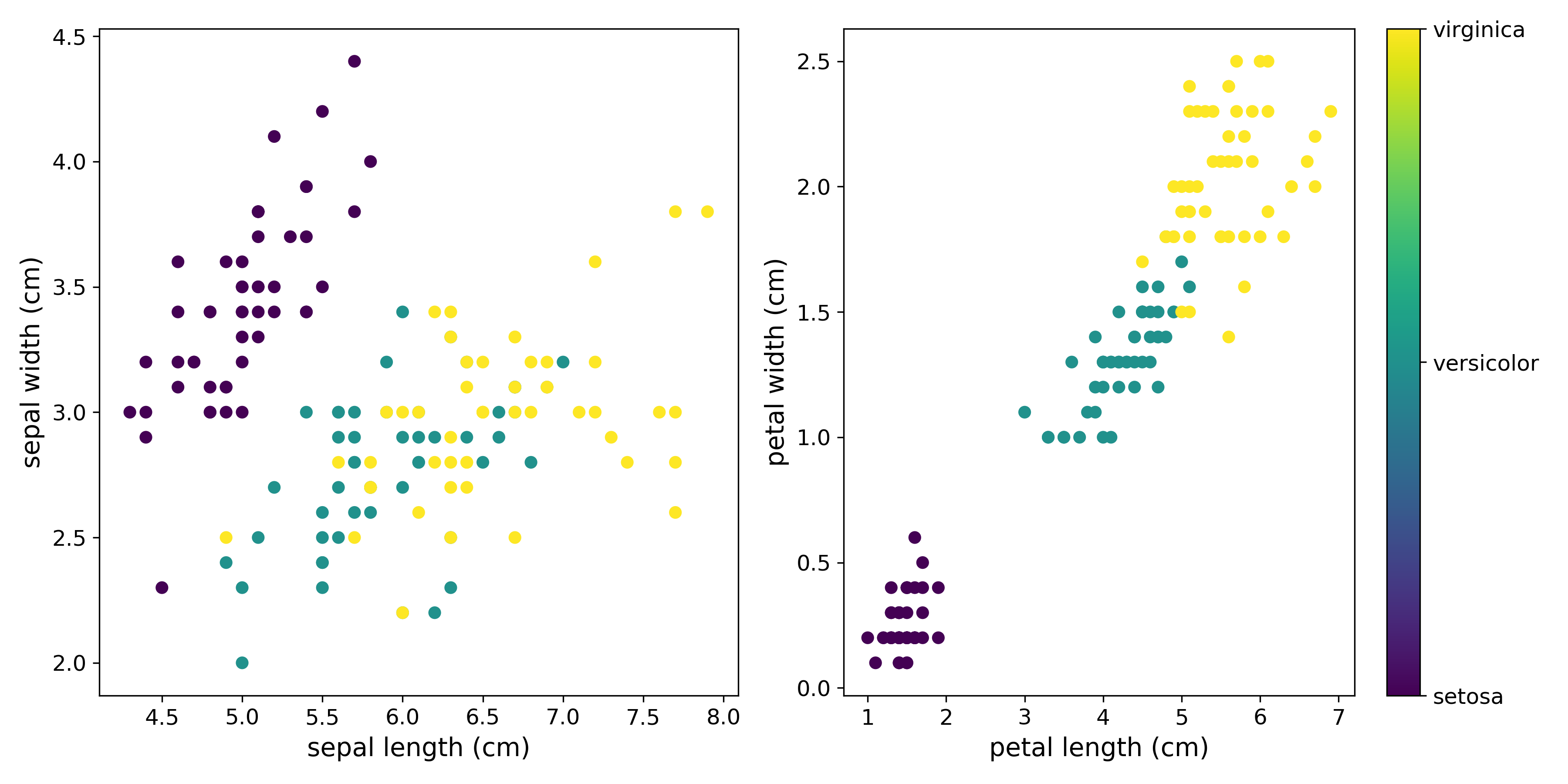
If you observe closely then you can see that the we are unable to distinguish between the three flowers when taking the plot of sepal length (cm) vs. sepal width (cm). The obvious distinction issue is between Iris Versicolor and Iris Virginica. But then again, the plot of petal length (cm) vs petal width (cm) gives an almost clear distinction between the three flowers. Looks like that should be our choosing criterion.
Classifying using Linear SVC
In this section of the article, we will be using linear SVC classification to classify the Iris data set. We will also check the accuracy to see how well our model performed.
from sklearn.svm import SVC from sklearn.model_selection import train_test_split X = iris['data'][:, (2, 3)] # Taking only the petal length and petal width y = iris['target'] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20) # SVM Classifier model svm_clf = SVC(kernel='linear', C=1.0) svm_clf.fit(X_train, y_train) # `C` is the penalty parameter of the error term
Now that we have fit our model, let’s predict on the test set and also check the accuracy:
# Testing and checking the accuracy from sklearn.metrics import accuracy_score y_pred = svm_clf.predict(X_test) # Accuracy accuracy = accuracy_score(y_test, y_pred) print(accuracy)
0.9666666666666667
Wow, we have above 96% accuracy. Not bad for a start.
Conclusion
In this article, you got to know how to fit a linear SVC model over the Iris data set. From here on, you can take many challenging tasks. Try finding some more complex data sets and fit a model using the Multi-class classification. Also, you can try to plot the decision boundary of the above model to get a clearer picture.
If you liked this article, then please share, like and subscribe. Also, follow me on Twitter and Facebook to get regular updates.
