In this article, we integrate SAM2, Molmo, and Whisper for creating a text-based as well as speech-to-text pipeline for automated object segmentation in images. ...
Integrating SAM2, Molmo, and Whisper for Object Segmentation


Machine Learning and Deep Learning
In this article, we integrate SAM2, Molmo, and Whisper for creating a text-based as well as speech-to-text pipeline for automated object segmentation in images. ...

In this article, we use SAM2 and Molmo for carrying out image segmentation using natural language. We provide a prompt to Molmo, get the coordinates, and pass these to SAM2.1 to segment the objects ...
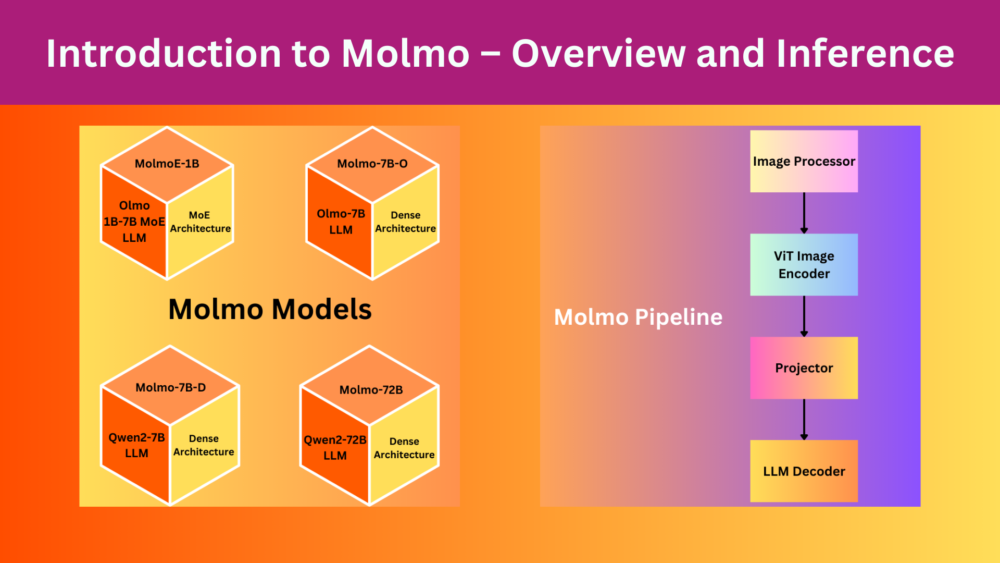
In this article, we walk through the Molmo and PixMo technical reports and carry out Molmo image description and pointing demos using the Hugging Face checkpoints. ...

In this article, we summarize the Metal Llama 3 technical report with the most crucial aspects such as the architecture, the pretraining data, the compute infrastructure, the post-training strategy, and multimodal capabilities of Llama 3. ...
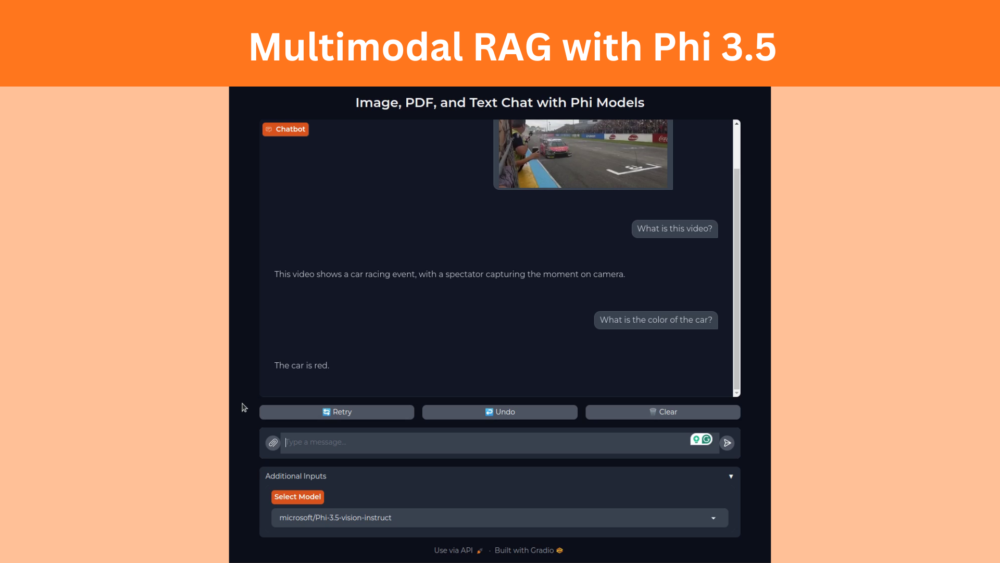
In this article, we create a multimodal RAG application from scratch to chat with PDFs, text files, images, and videos using the Phi-3.5 family of language models. ...
Business WordPress Theme copyright 2025