

Phi-4-Mini and Phi-4-Multimodal are the latest SLM (Small Language Model) and multimodal models from Microsoft. Beyond the core language model, the Phi-4 Multimodal can process images and audio files. In this article, we will cover the architecture of the Phi-4 Mini and Multimodal models and run inference using them.
We will cover the following Phi-4 components
- Phi-4 Mini language model architecture
- Phi-4 multimodal model architecture
- A brief of the benchmarks
- Running inference using Phi-4 Mini language model
Phi-4 Mini and Phi-4 Multimodal Architecture
The Phi-4 Mini model was introduced in the technical report that you can find on the Hugging Face model page.
In this section, we will discuss the core components of the Phi-4 Mini language and multimodal models.
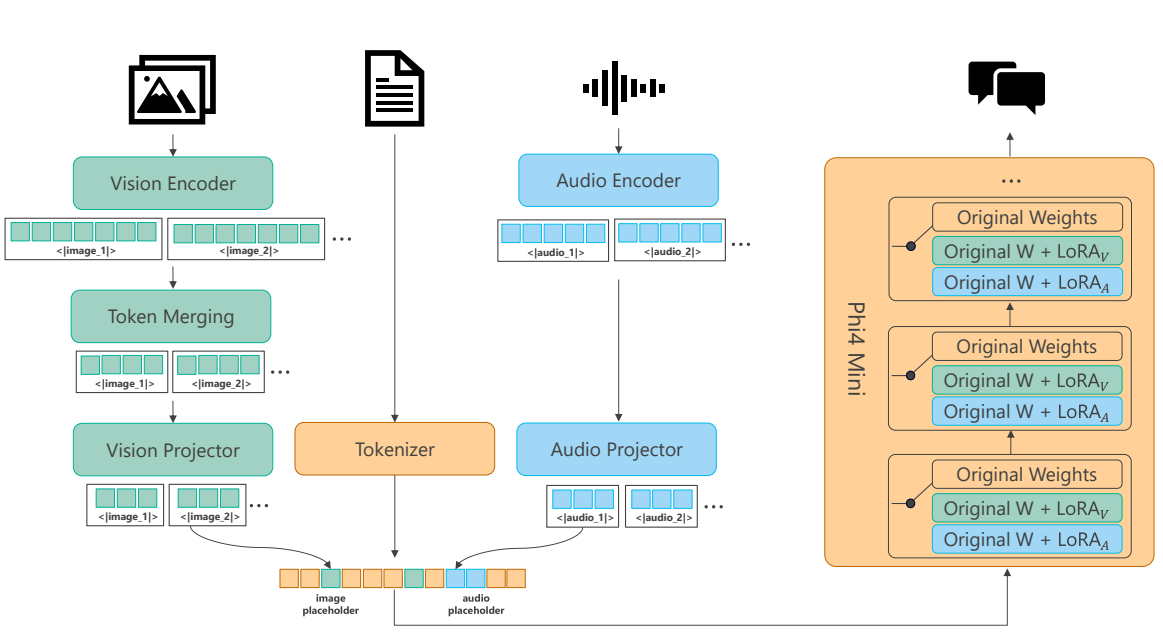
Core Transformer Backbone
At the foundation of Phi-4-Mini lies a decoder-only Transformer architecture, known for its robust sequence generation capabilities.
- Number of Layers: Phi-4-Mini consists of 32 Transformer layers. This depth enables the model to capture complex relationships and long-range dependencies.
- Hidden State Size: Each layer operates with a hidden state size of 3,072. This dimensionality provides the model with ample capacity for representing nuanced patterns.
- Attention Mechanism: Each Transformer block contains self-attention mechanism based on Group Query Attention.
Group Query Attention (GQA) for Memory Efficiency
Phi-4-Mini incorporates Group Query Attention to combat the memory demands of long-context generation.
- Implementation Details: Phi-4-Mini uses 24 query heads but only 8 key/value heads for a 3:1 ratio reducing memory consumption while maintaining quality.
RoPE
Phi-4-Mini utilizes Rotational Position Embedding (RoPE) to encode information on the ordering of tokens in the input sequence and also employs a fractional approach to enable handling longer contexts.
- Benefits: RoPE allows the model to extrapolate to sequences longer than its training data by encoding positional information as rotation matrices.
- Fractional ROPE: By only using some dimensions as a fraction in the ROPE implementation, it is easier to smoothly handle longer contexts by preserving 25% of the attention head as position-agnostic.
Tied Input/Output Embeddings
To reduce the number of parameters without sacrificing expressiveness, the model employs tied input/output embeddings.
- Mechanism: The same embedding matrix is used to represent tokens in both the input layer (converting tokens to vectors) and the output layer (converting vectors back to tokens).
- Advantages: This reduces the model size and ensures consistency between the input and output token representations.
Expanded Vocabulary and Tokenization
To better handle multilingual data and accommodate multimodal inputs, Phi-4-Mini features an expanded vocabulary and tokenization process.
- Vocabulary Size: The model uses a vocabulary size of 200,064 tokens.
- Tokenizer: The vocabulary is based on the 0200k_base Tiktoken tokenizer, designed to handle code, text, and special tokens efficiently.
Phi-4-Multimodal: Vision Modality Implementation
Vision support is a cornerstone of Phi-4-Multimodal. The vision modality is based on image encoders, projectors, and LoRA adaptors. It is implemented with the following features:
- Image Encoder: A SigLIP-400M image encoder is used. This serves as the foundation for transforming raw image data into meaningful high dimensional feature vectors. These encoders learn to create robust image representations.
- LLM2CLIP Fine tuning: LLM2CLIP fine tuning with image text pairs helps the encoders create more accurate and robust image representations.
- Projector: A projector is used to align the vision and text embeddings. The projector is a 2 layer MLP that projects features from vision dimensions to text embedding dimensions.
- Extra LORA Implementations: LLM based LORA adaptors are also deployed in the SFT stage for the vision modality.
- Parameter introduction due to Visuals: There is an increase of about 440M parameters due to image encoder and projector, while the visual adaption LoRA consumes another 370M parameters.
- Dynamic Multi-Crop Strategy: The ability to process images with diverse resolutions in a model requires an effective methodology. For the multi-crop strategy, the number of image crops are computed with the image height, width, and crop size to avoid unnecessary resizing. It follows a multi-crop strategy from InternVL2 that can find image number crops from the best aspect ratio.
Phi-4-Multimodal: Audio Modality Implementation
Audio modality is implemented to enable speech/audio functions such as speech recognition, translation, and summarization.
- Audio Inputs: Audio is fed as 80-dim log-Mel filter-bank features with a frame rate of 10ms.
- Audio Encoder: First we have an audio encoder consisting of 3 Convolution layers and 24 conformer layers to encode the input audio. The convolution layers produce a sub-sampling rate of 8, making the token rate for the language decoder about 80ms. The parameters for the encoders total about 460 million.
- Audio Projector: We then pass these extracted features to the audio projector implemented as a 2 layer MLP to map the features to a text-embedding space of 3072 dimension.
- LORA Adaptor implementation: To better assist in processing audio-modal information, LORA adaptors are implemented on all the attention and MLP layers in the Phi-4-Mini architecture. The rank used in this adaptation is 320. This LORA adaptor requires about 460M parameters. The speech token rate is around 80 ms, implying that 750 tokens are required for 1 min audio.
You can check this article to know more about QLoRA training with Phi 1.5.
Mixture-of-LoRAs: Unifying Multiple Modalities
Phi-4-Multimodal introduces the Mixture-of-LoRAs to simultaneously handle variable multi-modality use cases. Different LoRAs are trained to handle interaction between the differing modalities. Different types of tasks are enabled.
- Vision-Language: Single/multiple image QA/summarization tasks can be performed for the vision modality.
- Vision-Speech: Vision-Speech tasks such as QA are also enabled with vision and speech/audio input.
- Speech-Language: Speech QA/summarization/translation/recognition and audio understanding tasks are enabled with speech and language input and outputs.
Benchmarking Results
Phi-4-Mini and Phi-4-Multimodal are evaluated on a comprehensive suite of benchmarks to assess their performance in various domains. Here’s a summary of the key results:
- Language Understanding
- Achieves competitive or state-of-the-art results compared to other models of similar size. Often matching or surpassing models with nearly twice as many parameters. Especially strong on Math and instruction following capabilities.
- Coding
- Exhibits impressive coding abilities, including code generation, debugging, and code completion.
- Vision-Language
- Demonstrates strong performance on visual question answering, image captioning, and multimodal reasoning. A dynamic multi-crop strategy improves performance across different image resolutions.
- Speech-Language
- Achieves state-of-the-art performance on multilingual speech recognition and also translation, with exceptional ASR results.
Why Phi-4-Mini Matters?
Phi-4-Mini represents a significant achievement by combining the strengths of Transformer architectures with novel techniques like GQA and Mixture-of-LoRAs. The highly performant models and flexibility in tasks makes them suited for a variety of deployments. We now have a unified model for chat, vision understanding, and audio processing.
I highly recommend going through the paper and covering the pretraining, post-training, and benchmarks in detail.
Directory Structure
As we will create a sample Gradio application and a Jupyter Notebook, let’s take a look at the code directory structure.
├── input │ ├── audio.wav │ └── image.jpg ├── phi_4_mini_chat.py ├── phi_4_multimodal.ipynb ├── phi_4_multimodal.py └── requirements.txt
- The
inputdirectory contains the image and audio files that we are going to use for Phi-4 Multimodal inference. - There are two Python scripts,
phi_4_mini_chat.pyandphi_4_multimodal.py. The former is for running a Gradio application to chat with the Phi-4 Mini Instruct model. The latter creates a Gradio application to chat with the Phi-4 Multimodal model. - We also have the
phi_4_multimodal.ipynbJupyter Notebook, which makes it easier to run on Colab for Phi-4 Multimodal chat.
All the inference data, Python scripts, and Jupyter Notebook are available via the download code section.
Download Code
Installing Dependencies
You can install all the necessary requirements via the requirements.txt file.
pip install -r requirements.txt
Inference using Phi-4 Mini Instruct and Phi-4 Multimodal
From here on, we will focus on the inference code using the Phi-4 Mini Instruct and Phi-4 Multimodal models.
Phi-4 Mini Instruct Gradio Chat
First, we will create a Gradio application for Phi-4 Mini Instruct model. The code for this is present in the phi_4_mini_chat.py file.
Importing the Necessary Modules
The following code block imports all the necessary modules.
import torch
import gradio as gr
import threading
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
AutoProcessor,
TextIteratorStreamer
)
torch.random.manual_seed(0)
We will use streaming chat for which we are importing the TextIteratorStreamer class.
Loading the Model and Tokenizer
Next, we load the tokenizer, the model, and define the quantization configuration.
model_path = 'microsoft/Phi-4-mini-instruct'
device = 'cuda'
quant_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type='nf4',
bnb_4bit_use_double_quant=True
)
# Load model and tokenizer
processor = AutoProcessor.from_pretrained(
model_path,
trust_remote_code=True,
num_crops=4
)
tokenizer = AutoTokenizer.from_pretrained(
model_path, trust_remote_code=True
)
streamer = TextIteratorStreamer(
tokenizer, skip_prompt=True, skip_special_tokens=True
)
model = AutoModelForCausalLM.from_pretrained(
model_path,
quantization_config=quant_config,
device_map=device,
trust_remote_code=True
)
We load the model in INT4 quantized format, which would require less VRAM. If loading in FP16 or BF16 model, make sure to have at least 12 GB VRAM.
Function for Predicting Next Token
The following code block creates a function that carries out forward pass through the model and streams the tokens to the output text box.
def predict(message, history):
"""Generates a response from the Phi-4-Mini model given the chat history."""
# Build conversation history in the correct format
messages = [{'role': 'system', 'content': 'You are a helpful AI assistant.'}]
for human, assistant in history:
messages.append({'role': 'user', 'content': human})
messages.append({'role': 'assistant', 'content': assistant})
messages.append({'role': 'user', 'content': message})
tokenizer_template = tokenizer.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
inputs = tokenizer(tokenizer_template, return_tensors='pt').to(device)
input_ids, attention_mask = inputs.input_ids, inputs.attention_mask
generation_args = dict(
{'input_ids': input_ids.to(device), 'attention_mask': attention_mask.to(device)},
max_new_tokens=500,
temperature=0.0,
do_sample=False,
streamer=streamer
)
# Generate output from the model
thread = threading.Thread(
target=model.generate,
kwargs=generation_args
)
thread.start()
outputs = []
for new_token in streamer:
outputs.append(new_token)
final_output = ''.join(outputs)
yield final_output
Gradio Chat Interface
Finally, we create a Gradio Chat interface and launch the application.
# Gradio Interface
iface = gr.ChatInterface(
fn=predict,
title='Phi-4-Mini Chatbot',
description='Interact with the Phi-4-Mini language model.',
examples=[
['Can you explain the theory of relativity?'],
['Write a short poem about autumn leaves.']
]
)
iface.launch()
Launching the Application
We can launch the application using the following command.
python phi_4_mini_chat.py
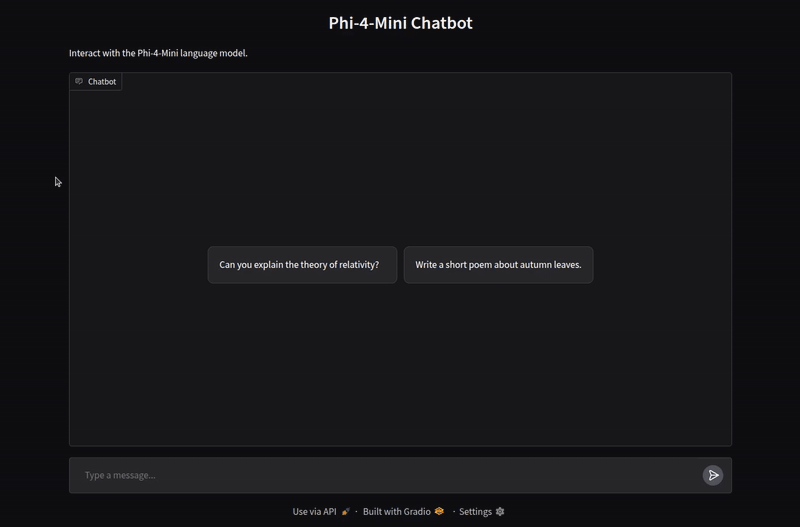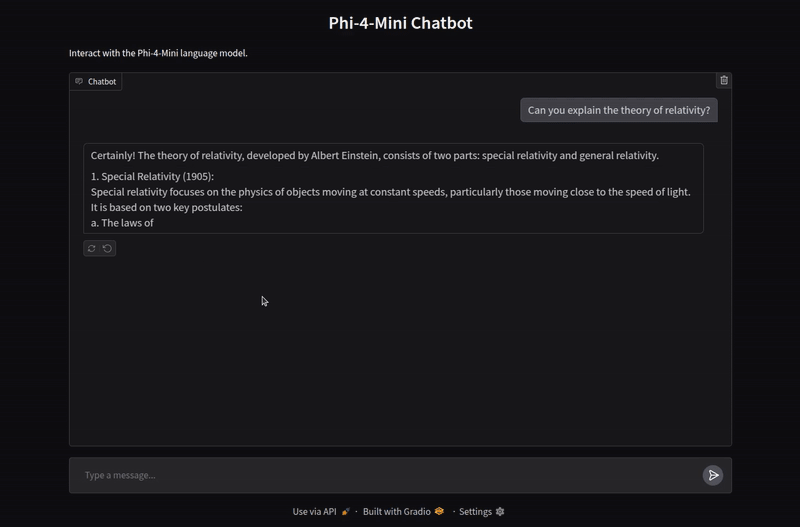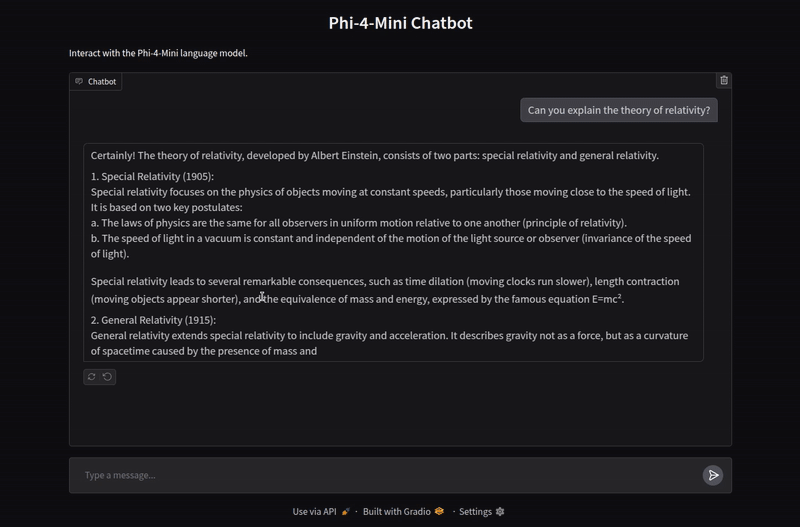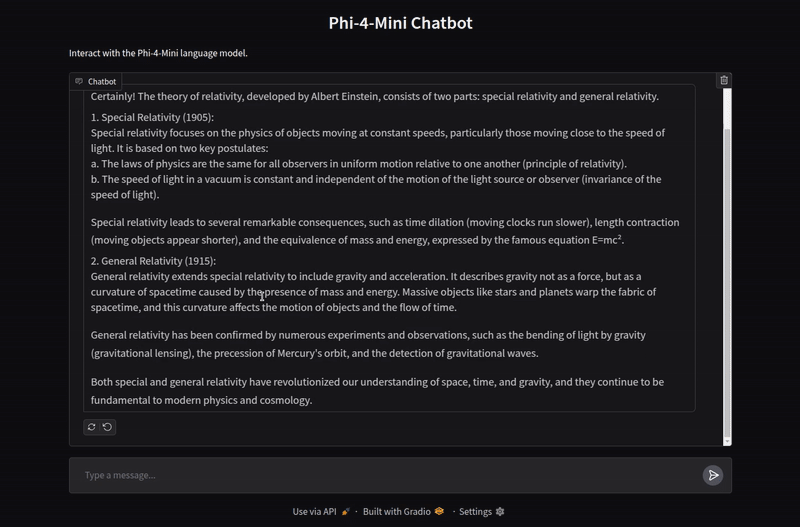
The application handles chat history as well for multi-turn chats. Here is a video showing some example chats.
We are not carrying out any extensive evaluation here. You can take this project further and implement more functionalities as per your requirement.
Phi-4 Multimodal Inference
Next, we will create a simple Gradio application for Phi-4 Multimodal inference. We will follow the code in phi_4_multimodal.ipynb Jupyter Notebook. We will also cover some caveats. The notebook can be run directly on Google Colab on a T4 GPU.
We will cover both, image and audio inference.
Importing the Modules
The first code block imports all the necessary modules.
import gradio as gr
from PIL import Image
import soundfile as sf
from transformers import (
AutoModelForCausalLM,
AutoProcessor,
GenerationConfig,
BitsAndBytesConfig
)
Although we are importing the BitsAndBytesConfig class, we will not be using it here. We will discuss the reason further.
Loading the Model and Processor
To run on Google Colab, we need to use eager attention implementation. The T4 GPU does not support Flash Attention 2 which is only available in Ampere GPUs and later generations.
# Define model path
model_path = 'microsoft/Phi-4-multimodal-instruct'
# Load model and processor
processor = AutoProcessor.from_pretrained(model_path, trust_remote_code=True)
# Useful for Colab on T4 GPus.
model = AutoModelForCausalLM.from_pretrained(
model_path,
device_map='cuda',
torch_dtype='auto',
trust_remote_code=True,
_attn_implementation='eager',
).cuda()
There are a few caveats here. At the time of writing this:
- The model does not support BitsAndBytes INT4 at the moment. Only FP16 or BF16 forward passes work. You can try with FP8 if you can on H100 and the likes using
fbgemm-gpulibrary. I have not tested this at the moment. - This leads to working with FP16 and BF16 configs which requires more than 11GB VRAM. Ideally, more than 12GB VRAM when working with images and a bit less for audio files less than 15 seconds.
- However, the Hugging Face configuration and code given on the official Phi-4 Multimodal page uses Flash Attention 2 by default.
- We are changing the attention implementation to
eagermode using_attn_implementation='eager'. In the official Hugging Face page, at the time of writing this, the keyword given to change attention implementation isattn_implementation. However, the correct keyword as per theconfig.jsonfile is_attn_implementationwhich we have used above. Hopefully, this is corrected by the time the article is published.
Define the Generation Configuration and Special Tokens
# Load generation config generation_config = GenerationConfig.from_pretrained(model_path) # Define prompt structure user_prompt = '<|user|>' assistant_prompt = '<|assistant|>' prompt_suffix = '<|end|>'
At the time of writing this, a chat template for the model is not available. So, we will manually define the special tokens for the chat template to create the prompts.
Processing Image and Audio
We will create a simple function here to process either image or audio based on what the user uploads.
def process_input(image_file, audio_file):
# Check which input was provided
if image_file is not None:
# Process image
try:
image = Image.open(image_file)
prompt = f"{user_prompt}<|image_1|>What is shown in this image?{prompt_suffix}{assistant_prompt}"
inputs = processor(text=prompt, images=image, return_tensors='pt').to('cuda:0')
generate_ids = model.generate(
**inputs,
max_new_tokens=1000,
generation_config=generation_config,
)
generate_ids = generate_ids[:, inputs['input_ids'].shape[1]:]
response = processor.batch_decode(
generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False
)[0]
return response
except Exception as e:
return f"Error processing image: {str(e)}"
elif audio_file is not None:
# Process audio
try:
audio, samplerate = sf.read(audio_file)
speech_prompt = 'Transcribe the audio to text.'
prompt = f"{user_prompt}<|audio_1|>{speech_prompt}{prompt_suffix}{assistant_prompt}"
inputs = processor(text=prompt, audios=[(audio, samplerate)], return_tensors='pt').to('cuda:0')
generate_ids = model.generate(
**inputs,
max_new_tokens=1000,
generation_config=generation_config,
)
generate_ids = generate_ids[:, inputs['input_ids'].shape[1]:]
response = processor.batch_decode(
generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False
)[0]
return response
except Exception as e:
return f"Error processing audio: {str(e)}"
else:
return 'Please upload either an image or an audio file.'
We keep the prompt hardcoded here. As we are not creating a full-fledged application, we carry out either of the two functionalities:
- If the user uploads an image, then the model simply describes the image by answering “What is shown in this image?”.
- If the user uploads an audio file containing speech, then the model transcribes its contents and outputs them to the text box.
Gradio Interface
The final code block contains the Gradio interface.
# Create Gradio interface
interface = gr.Interface(
fn=process_input,
inputs=[
gr.Image(type='filepath', label='Upload an Image'),
gr.Audio(type='filepath', label='Upload an Audio File')
],
outputs='text',
title='Phi-4 Multimodal Chat',
description='Upload an image to get a description or an audio file to get transcription. Single-turn responses only.',
allow_flagging='never'
)
# Launch the interface
interface.launch(share=True)
At the moment, this code does not handle memory and does not support multi-turn chat.
Following is an output when we upload an image and submit it to the model for processing.
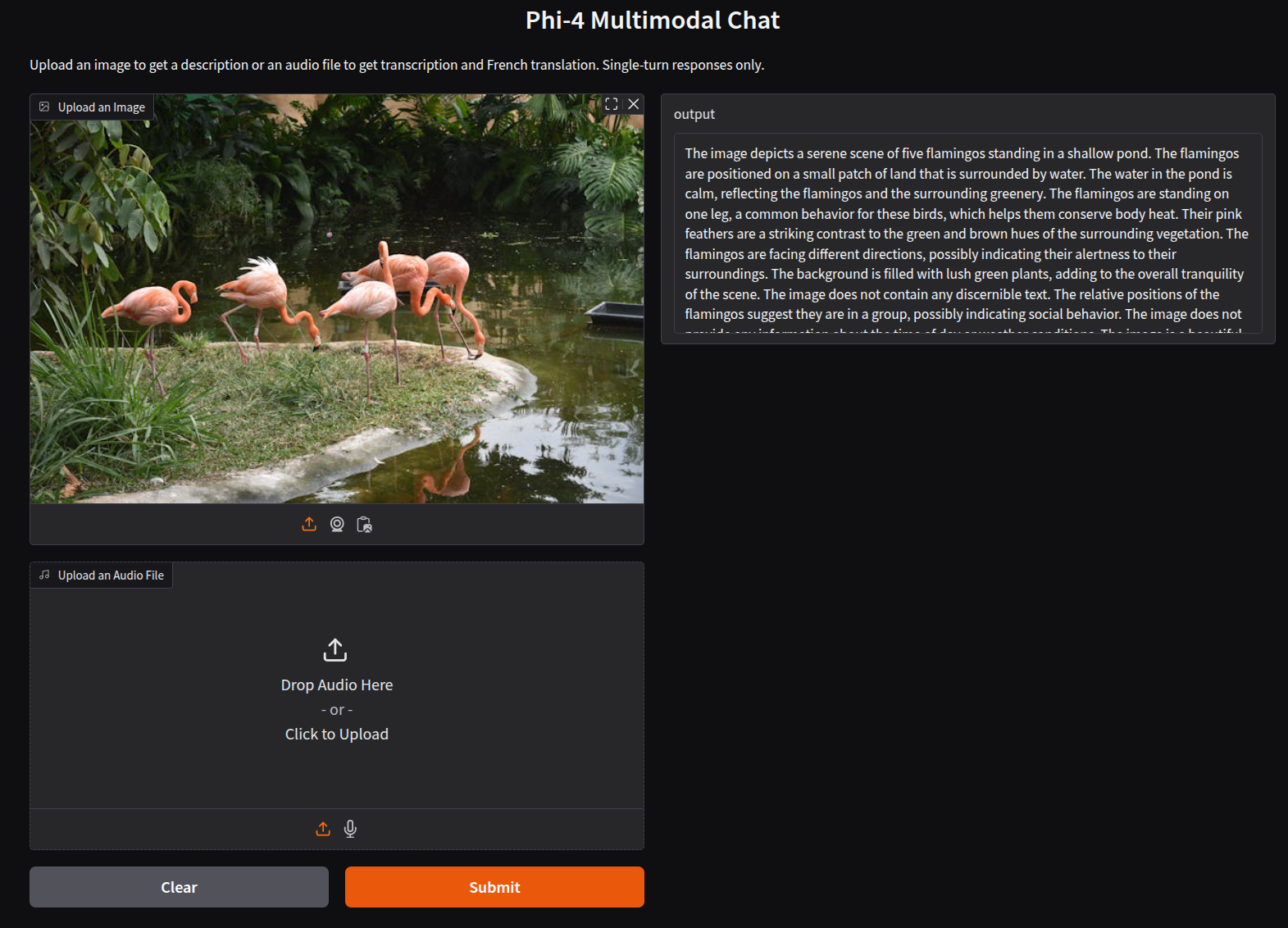
The output is quite detailed. By tuning the prompt we can get an even better output.
And this is the transcription after uploading an audio file.
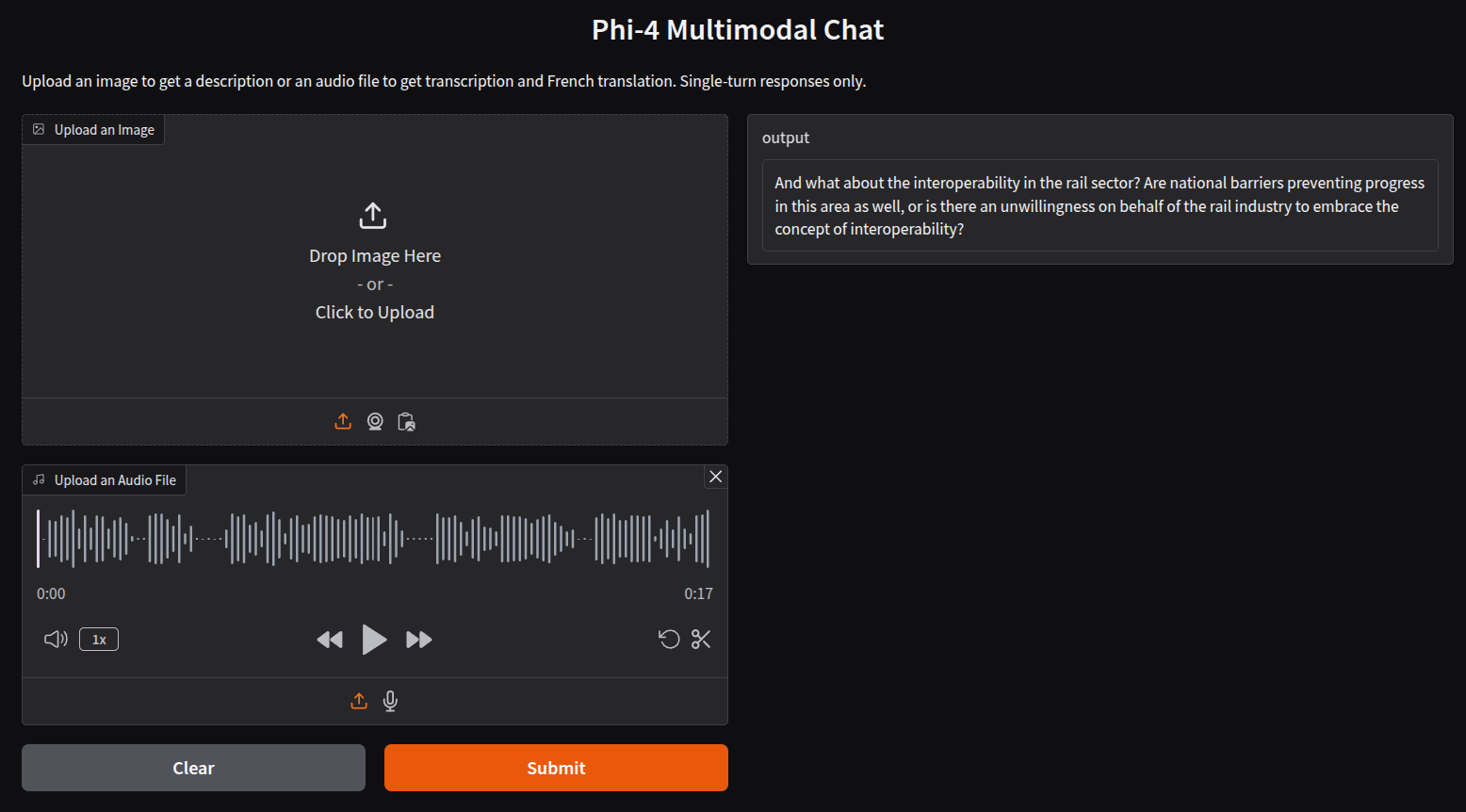
This transcription is also correct. You can upload any audio file of your choice to check how well the model performs in complex scenarios.
Summary and Conclusion
In this article, we covered the Phi-4 Mini and Phi-4 Multimodal models. We started with a discussion of the architectures and moved to the inference. We created simple Gradio applications and carried out instruction based chatting, video, and audio inference experiments. I hope this article was worth your time.
If you have any questions, thoughts, or suggestions, please leave them in the comment section. I will surely address them.
You can contact me using the Contact section. You can also find me on LinkedIn, and X.
References

1 thought on “Phi-4 Mini and Phi-4 Multimodal”