

The Llama 3 series of models were a substantial contribution to the world of LLMs and VLMs. Because of Meta’s open-source efforts, the community of researchers and developers can build on top of the Llama family of models. In this article, we will take a closer look at the Llama 3.2 Vision models.
We will cover the architecture of the Llama 3.2 vision model and focus on its inference and visual understanding capabilities. While doing so, we will employ the Unsloth library and build a simple Gradio application to instruct the model for describing images.
What will we cover in Llama 3.2 Vision?
- How is the Llama 3 Vision model architecture created? We will cover the details as mentioned in the paper.
- What kind of visual information can we ingest into the model?
- How to use Llama 3.2 vision model using Unsloth and Jupyter Notebook?
- How to create a Gradio application using Llama 3.2 vision?
Llama 3 Vision Model Architecture
The Llama 3 Vision architecture was introduced in the original release of the paper. We discussed the details of the paper and architecture at some length in our Llama 3 article.
The Llama 3 Vision model follows a compositional approach. Rather than fine-tuning the entire model again, the authors connect pretrained components, fine-tuning the necessary parts only.
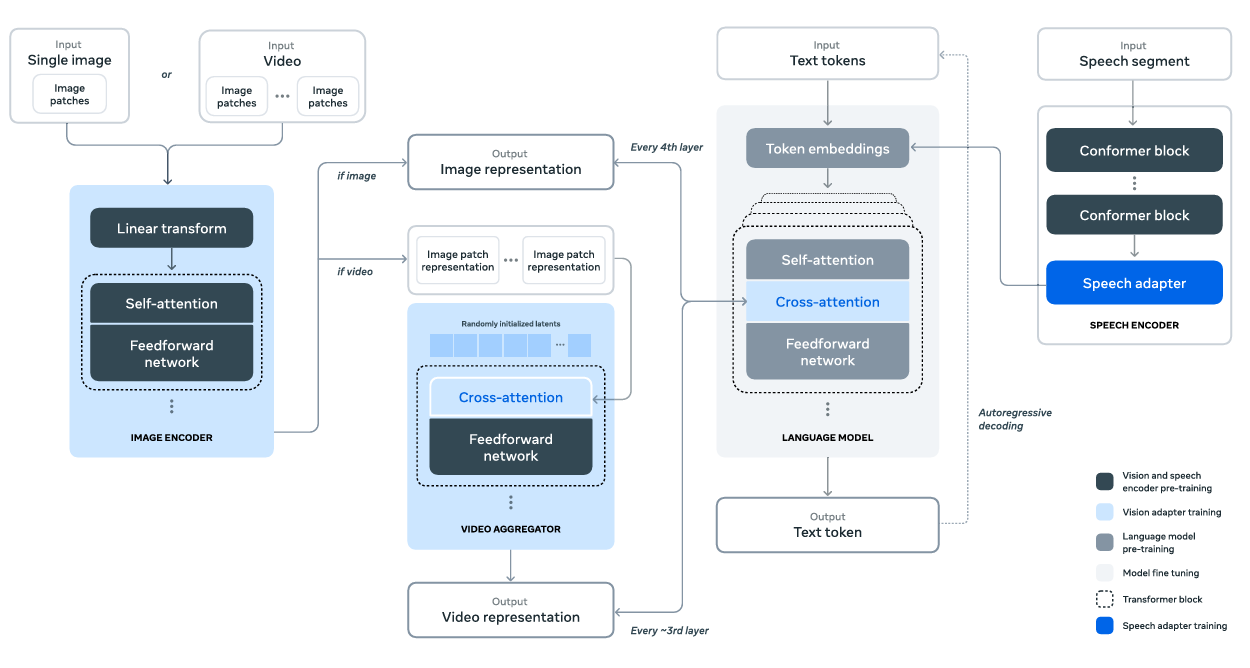
The above figure shows the compositional architecture approach to build the multimodal model. This includes the vision and speech adapters as well. However, we will only discuss the vision capabilities of the Llama 3 model here.
Different Components of the Model Architecture
There are three primary components in the model: image encoder, image adapter, and video adapter.
Image Encoder
The image encoder processes the input images and creates image representations, i.e., embeddings that we can feed to the cross-attention layers. Before the image encoder accepts any image, we convert them to patches.
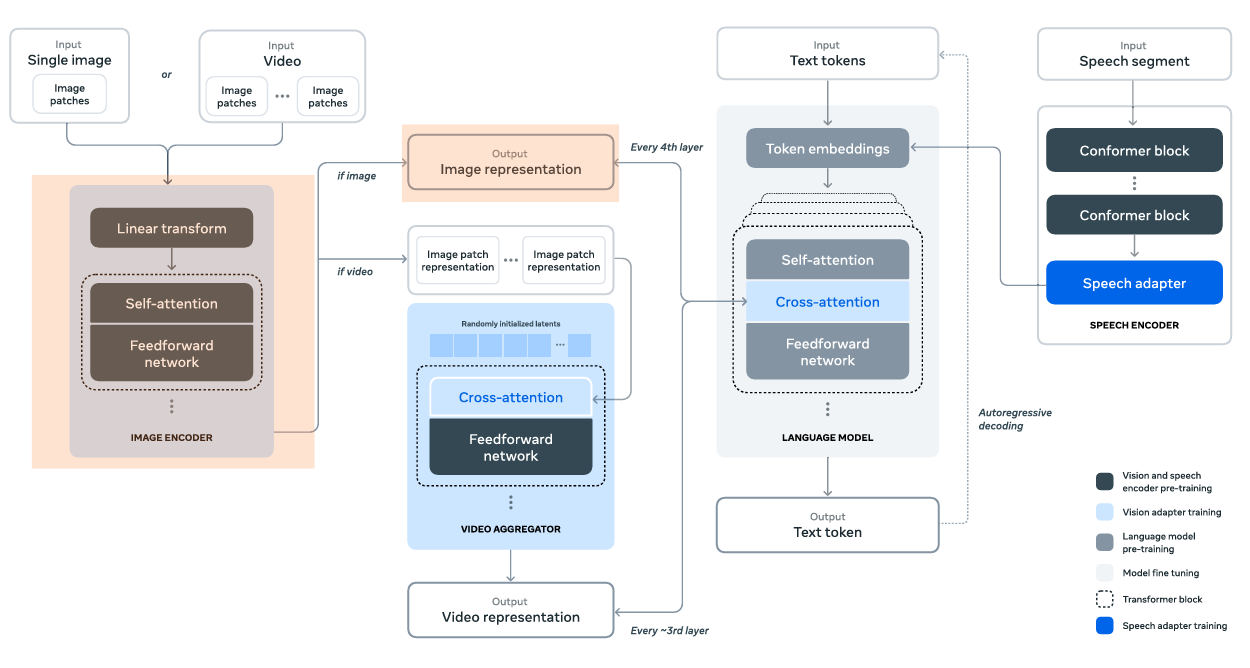
Interestingly, the authors use the standard ViT (Vision Transformer) model, that is, the ViT-H/14 model as the image encoder. In addition to the original layers, the authors add 8 gated self-attention layers. This makes a total of 40 transformer blocks in the final image encoder.
Image Adapter
The image adapters refer to the cross-attention layers that concatenate the visual tokens from the image encoder and text tokens from the Llama 3 LLM.
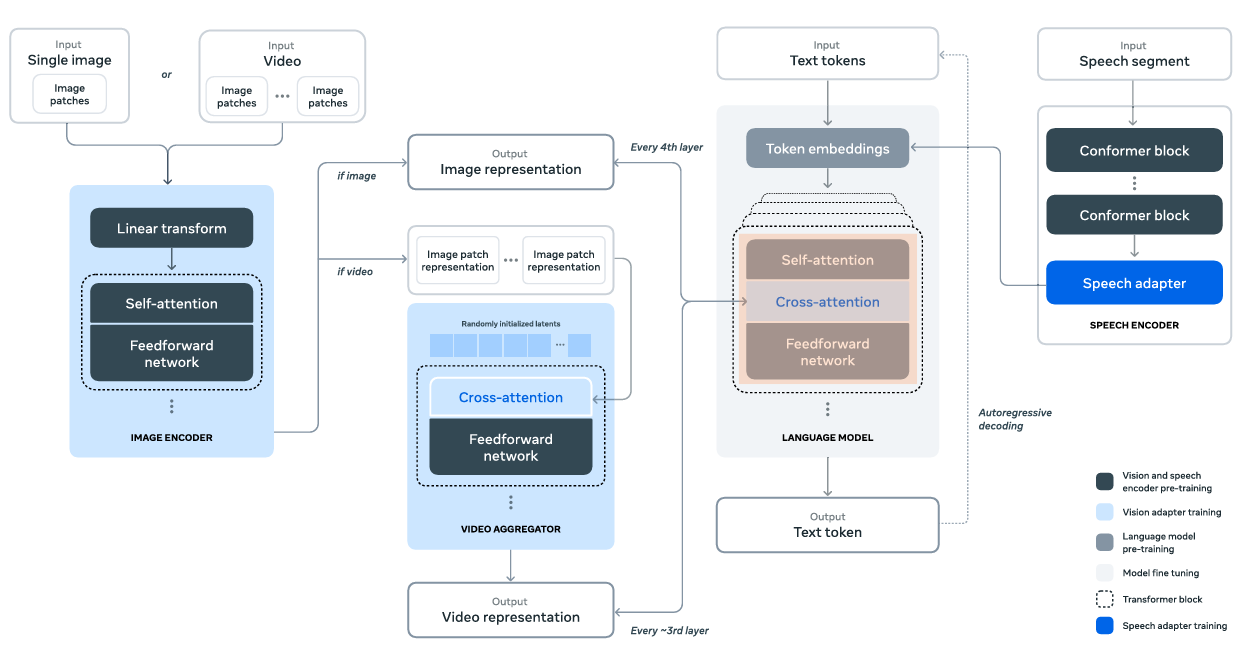
The cross-attention layers are applied after every fourth self-attention layer in the language model. This means, that after every fourth self-attention layer, the visual tokens are fetched from the image encoder to be concatenated.
There is a downside to this process, however. The cross-attention layers can amount to an increase in ~25% of model parameters. For instance, for the Llama 3 405B model, the cross-attention layers alone (excluding the image encoder) lead to an increase of ~100B parameters.
Video Adapter
Although the figure mentions this, at the time of writing this, we do not have a Llama 3.2 Vision model that can process videos natively.
The paper mentions that the video adapter goes through the same preprocessing step as the images. That is, creating patches from 64 uniformly sampled frames, passing them through the image encoder, and creating the visual tokens.
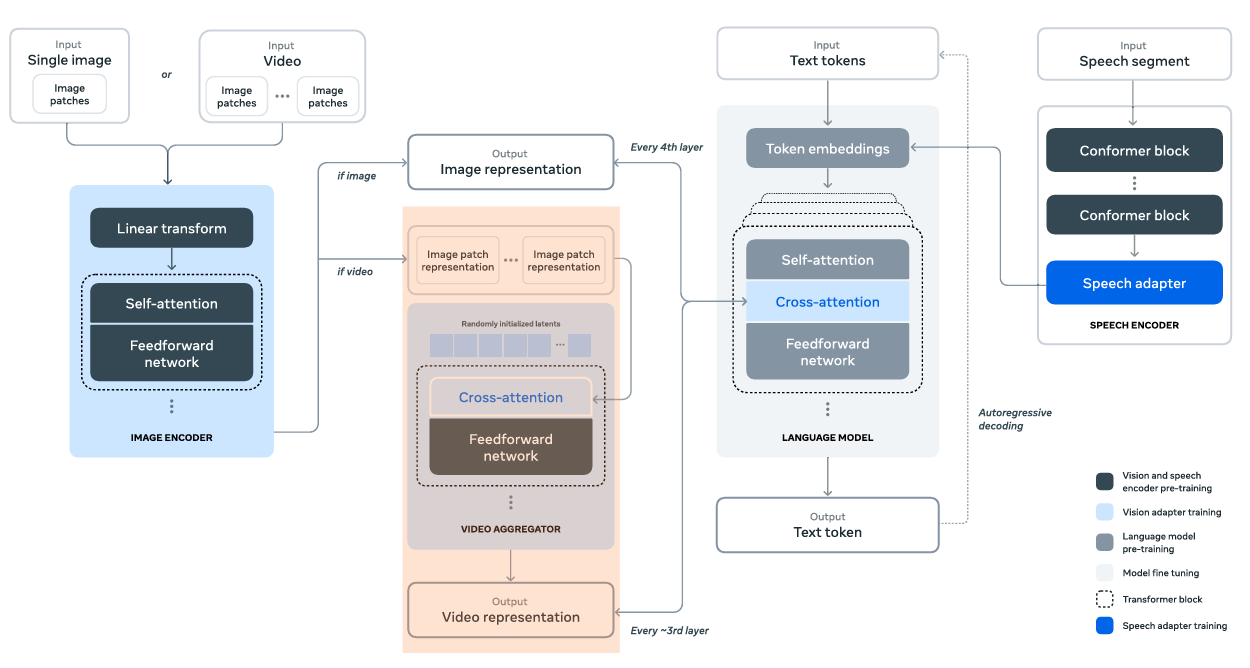
In addition to that, the video visual tokens go through a video cross-attention module and video aggregator layer to preserve the temporal information.
This completes a high level overview of the Llama 3.2 Vision model architecture. I highly recommend the reader to go through Section 7 of the paper which discusses the data curation, pretraining, and post-training of the vision adapter models.
Directory Structure
Let’s go through the directory structure before jumping into the coding part.
├── input │ ├── calculator-1.png │ ├── image_1.jpg │ ├── image_2.jpg │ ├── image_3.jpg │ ├── receipt-1.jpeg │ ├── receipt-2.jpeg │ ├── watch-face-1.jpg │ └── watch-face-2.jpg ├── app.py └── unsloth_llama_3_2_vision.ipynb
- The
inputdirectory contains the images we will use for running inference on the model. - We have a Jupyter Notebook laying out the process of loading the Llama 3 vision model, processing the images, and running inference using Unsloth.
- The
app.pyscript contains a Gradio application for chatting with the model using a GUI.
The Download Code section provides a compressed file with the input images, the Jupyter Notebook, and the Gradio application.
Download Code
Installing Requirements
We have covered the installation of the Unsloth library in our previous article. However, for ease of following through, here are all the requirements.
- Create an Anaconda environment, install Unsloth and other dependencies
conda create --name unsloth_env \
python=3.11 \
pytorch-cuda=12.1 \
pytorch cudatoolkit xformers -c pytorch -c nvidia -c xformers \
-y
conda activate unsloth_env
pip install "unsloth[colab-new] @ git+https://github.com/unslothai/unsloth.git" pip install --no-deps trl peft accelerate bitsandbytes
- Install Gradio
pip install gradio
Inference using Llama 3.2 Vision
In this section, we will cover the coding details. First, we will cover the basics of loading the model and running inference in the Jupyter Notebook. Second, we will build a simple Gradio application for chatting with images using a GUI.
Using a Jupyter Notebook with Llama Vision
All the code shown here resides in the unsloth_llama_3_2_vision.ipynb notebook.
Importing the Modules
Let’s start with importing the necessary libraries and modules.
from unsloth import FastVisionModel from transformers import TextStreamer from PIL import Image
- The
FastVisionModellet’s us load VLMs (Vision Language Models) in Unsloth. - The TextStreamer class helps to stream outputs as they are generated rather than waiting for the model to output the entire response.
- Using PIL
Image, we will load the images.
Loading the Model
Loading the model is straightforward. Similar to the Hugging Face Transformers library, we can use the from_pretrained method from FastVisionModel.
model, tokenizer = FastVisionModel.from_pretrained(
model_name='unsloth/Llama-3.2-11B-Vision-Instruct-bnb-4bit',
# load_in_4bit=True # Not needed when loading 4-bit models directly.
)
text_streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
We are directly loading the 4-bit quantized model, so, no need to pass the load_in_4bit argument. We also create a text_streamer class object to stream the output text.
Loading the model alone requires around 8GB of VRAM and it is recommended to have at least 10GB of VRAM to run the inference comfortably.
Helper Function for Forward Pass
We need a helper function that we can call repeatedly just by passing an image and an instruction for inference. The next code block achieves that.
def describe_image(image_path, instruction='Describe the image accurately.'):
messages = [
{'role': 'user', 'content': [
{'type': 'image'},
{'type': 'text', 'text': instruction}
]}
]
image = Image.open(image_path)
input_text = tokenizer.apply_chat_template(messages, add_generation_prompt=True)
inputs = tokenizer(
image,
input_text,
add_special_tokens=False,
return_tensors='pt',
).to('cuda')
_ = model.generate(
**inputs,
streamer=text_streamer,
max_new_tokens=1024,
use_cache=True,
temperature=1.5,
min_p=0.1
)
The describe_image function does the following tasks:
- It creates a
messageslist which defines the prompt format for the Llama 3.2 Vision model. It contains two primary key-value pairs. First, therolekey defines theuserrole. Second, thecontentkey again contains a list with two dictionaries. The first one defines thetypeasimagefor image input. The second one defines thetypeastextfor the prompt instruction. - Next, we read the image from the path.
- Then we apply the chat template by passing the
messageslist. Theadd_generation_promptargument ensures that the proper chat prompt tokens are added after the user instructions so that the model knows where to start responding from. - We feed the above
input_textinto thetokenizeralong with the image and load the tokenized input to the CUDA device. - Finally, we call the
generatemethod of the model and pass the necessary arguments for generating the response.
Let’s try passing an example image and instruction. We pass the following image to the model as input.

For inference, we need to call the describe_image function with the image path. It already contains a default prompt.
describe_image('input/image_2.jpg')
We get the following response from the image.
The image presents a circular mirror reflection on a beach, with the mirror itself placed on the sand and rocks, surrounded by a large rock formation. In the foreground, a circular mirror is positioned on the sand, near a cluster of large rocks. The mirror is made of reflective metal or glass, and its round shape is defined by a thin brown frame. Inside the mirror, a man is reflected, looking upwards towards the sky, where clear blue conditions can be seen. He has dark hair and is dressed in a white, open-necked shirt with the top button undone. In the middle ground, the rock formation dominates the scene, with a large rock formation rising behind the mirror. The rock formation is dark, with moss covering parts of its surface, creating a natural and rugged landscape. In front of the mirror, there is a small rock formation, composed of sand and rocks. The ground around the mirror appears wet, with small pools of water reflecting the light. In the background, the beach stretches out, with more rocks and a shoreline. The overall atmosphere suggests a serene and peaceful environment, with the calm ocean waves and the mirror reflecting the sky creating a sense of tranquility. The mood and composition of the image evoke a sense of wonder and awe, inviting the viewer to reflect on their own life and surroundings. The use of the circular mirror as a framing device adds to the sense of introspection and contemplation, while the natural surroundings create a sense of harmony and balance.
The model describes the image accurately. Further in the article, after building the Gradio application, we will see more such results and also analyze some failure cases.
Building a Gradio Application with Llama 3 Vision
This is going to be a simple single-turn chat application.
Let’s directly jump into the code without any delay. All the code is in app.py.
Necessary Imports
The following are all the modules and libraries that we need to build the application.
from unsloth import FastVisionModel from transformers import TextIteratorStreamer from PIL import Image import threading import torch import gradio as gr
One difference here is the import of TextIteratorStreamer and threading. We will need to output the tokens to the Gradio text box in a non-blocking way. This requires the above two.
Initializing the Model, Tokenizer, Streamer, and CUDA Device
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model, tokenizer = FastVisionModel.from_pretrained(
model_name = 'unsloth/Llama-3.2-11B-Vision-Instruct-bnb-4bit',
# load_in_4bit=True # Not needed when loading 4-bit models directly.
)
streamer = TextIteratorStreamer(
tokenizer, skip_prompt=True, skip_special_tokens=True
)
All the code in the above block is similar to what we had in the Jupyter Notebook.
The Inference Function
The next code block defines a function that will be called whenever the user inputs a text into the Gradio chat box.
def describe_image(user_input, history):
print(user_input)
messages = [
{'role': 'user', 'content': [
{'type': 'image'},
{'type': 'text', 'text': user_input['text']}
]}
]
input_text = tokenizer.apply_chat_template(messages, add_generation_prompt=True)
inputs = tokenizer(
Image.open(user_input['files'][0]),
input_text,
add_special_tokens=False,
return_tensors='pt',
).to(device)
generate_kwargs = dict(
**inputs,
streamer=streamer,
max_new_tokens=1024,
use_cache=True,
temperature=1.5,
min_p=0.1
)
thread = threading.Thread(
target=model.generate,
kwargs=generate_kwargs
)
thread.start()
outputs = []
for new_token in streamer:
outputs.append(new_token)
final_output = ''.join(outputs)
yield final_output
Let’s go through some of the important parts:
user_inputandhistoryparameters: These parameters are part of the GradioChatInterfaceclass. We have to mandatorily use them, although the parameter names can be different. Theuser_inputis a dictionary that stores the user prompt and the uploaded image path intextandfileskeys respectively. Following is an example:
{
‘text’: ‘What is this?’,
‘files’:
[‘/tmp/gradio/dbdb3e4515f5f5c6f12cd9e4dcc82cdfc98a876631c1f2168d7e54887556db47/3703035378_c6034cac51.jpg’]
}
Thehistoryparameter stores the user input history over multiple turns. However, we are not going to use that in this project.- We are passing the
user_input['text']to the messages list anduser_input['files'][0]to prepare themessagesand the final inputs. - The
generate_kwargsvariable defines the generation keyword arguments that we pass to thegeneratemethod of the model when callingthreadingconstructor. Thestartmethod of the constructor object starts the model’s generation process in one thread. - We tap into the
streameroutputs within aforloop as they are being generated, append them to a list, join the list elements, and yield the output to the Gradio text box.
Main Code Block
Finally, we have a main function where we define the Gradio ChatInterface and launch it.
def main():
iface = gr.ChatInterface(
fn=describe_image,
multimodal=True,
title='Llama 3.2 Vision Chat',
)
iface.launch(share=True)
if __name__ == '__main__':
main()
The ChatInterface class accepts the above describe_image function with multimodal input for uploading images.
We can execute the script using the following command to start the application.
python app.py
Examples and Experiments
In this section, we will discuss several examples and experiments along with the results that we get when chatting with the model. These will include the strengths and shortcomings of the model.
Explanation of Big Bang Expansion
Let’s start with a complex image.

The uploaded image shows the Big Bang expansion and the instruction is “Describe this image”. The primary challenge here is the bright colors and text. However, it seems that the model can extract the text accurately including the expansion taking place over 13.77 billion years.
In fact, it gives a short explanation of all the primary events mentioned in this image. The model seems to be doing a good job here.
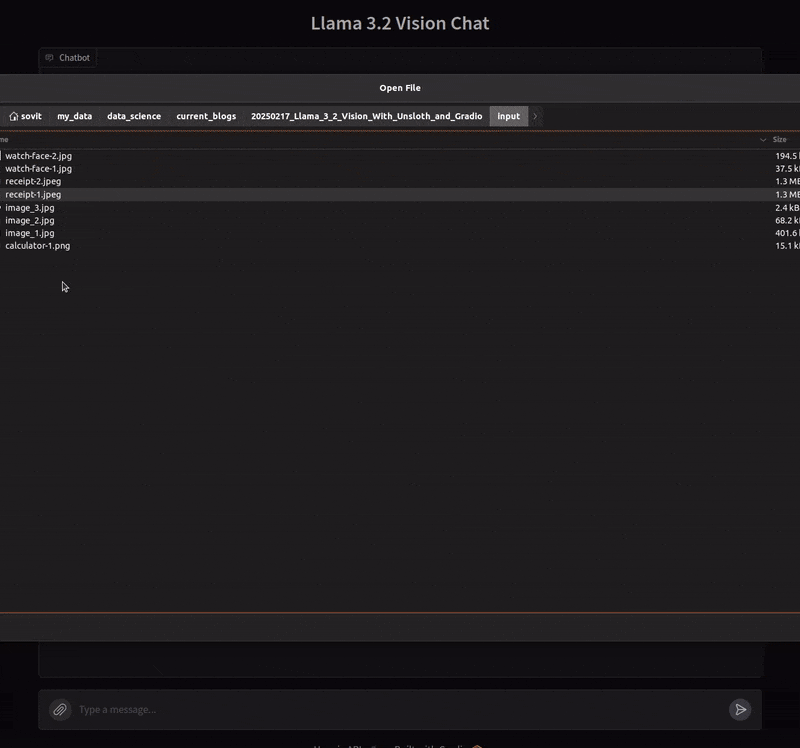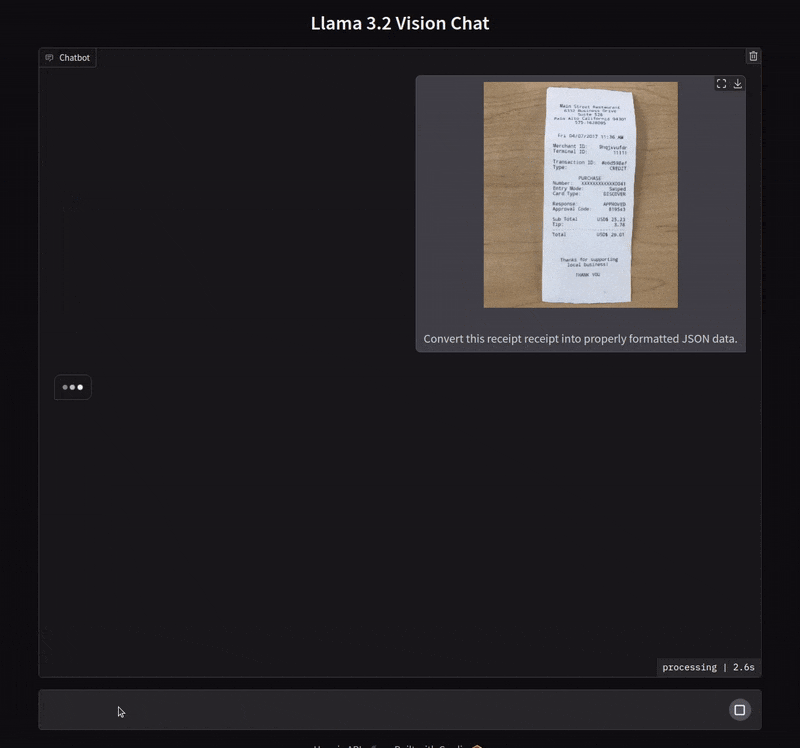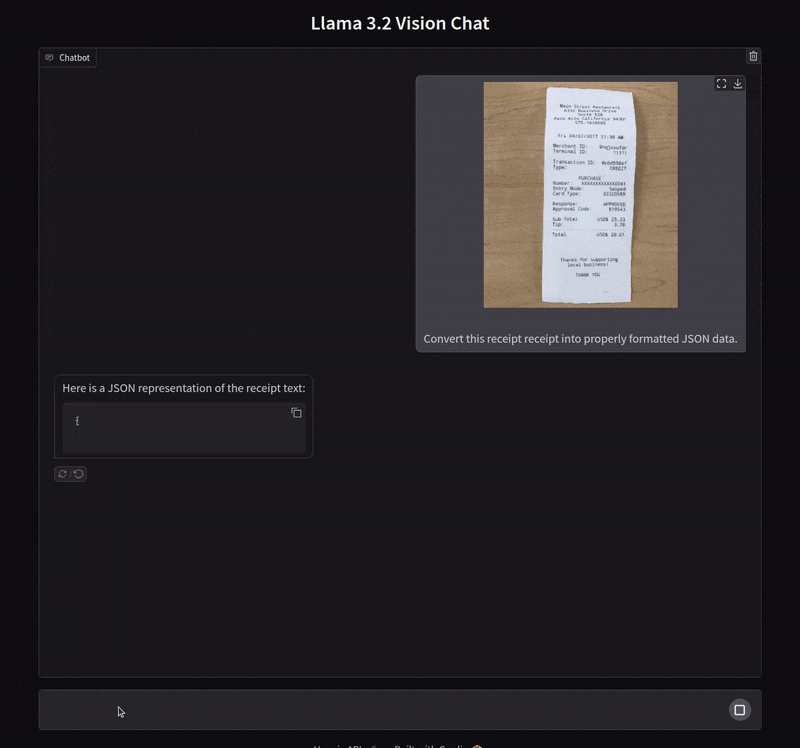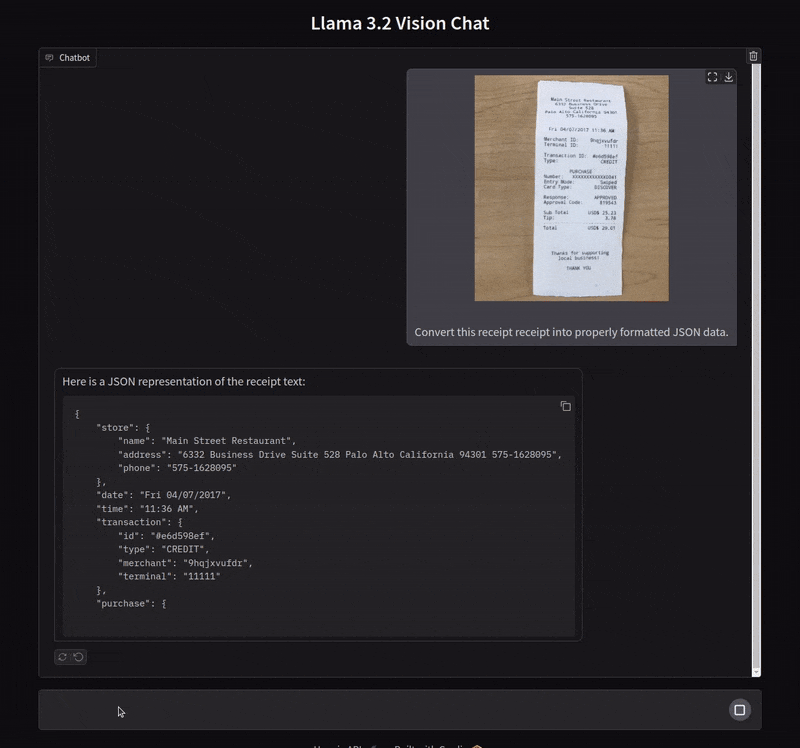
Extracting Data from Receipts in JSON Format
In the next example, we ask the model to extract the text from a receipt in JSON format.

In this case, the model creates keys for almost all the primary components. However, it misses the timestamp which we ask in the next chat.
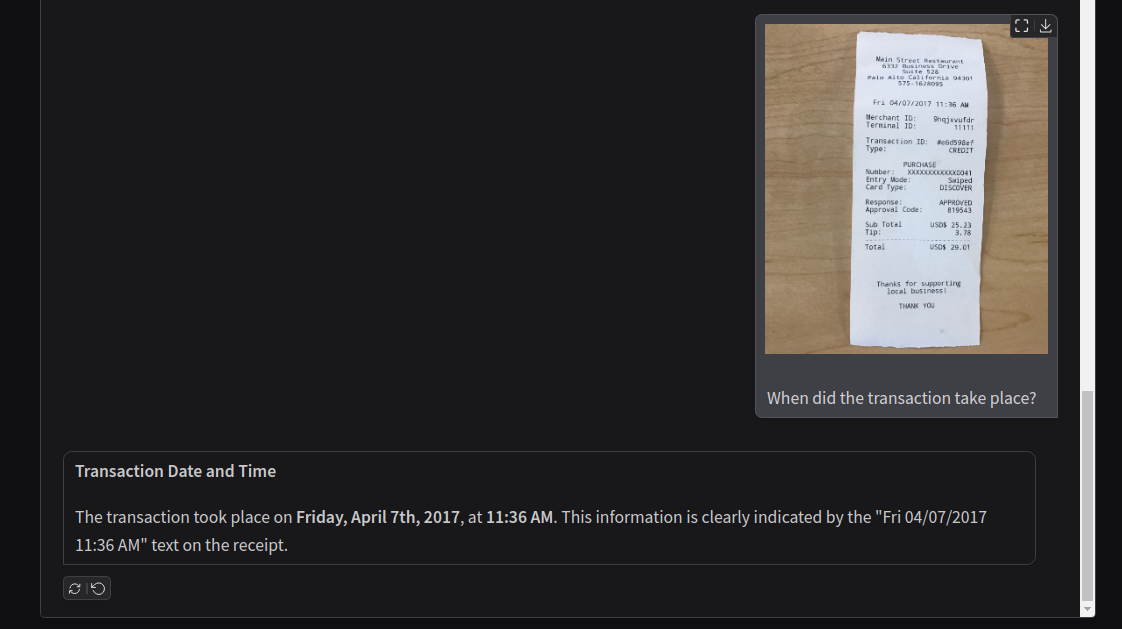
It accurately extracts the information. The model does not seem to face any difficulty in extracting small text from images.
Questions About Digital Calculator (Partial Failure Case)
Next, we ask the model a few questions by uploading images from digital calculators.
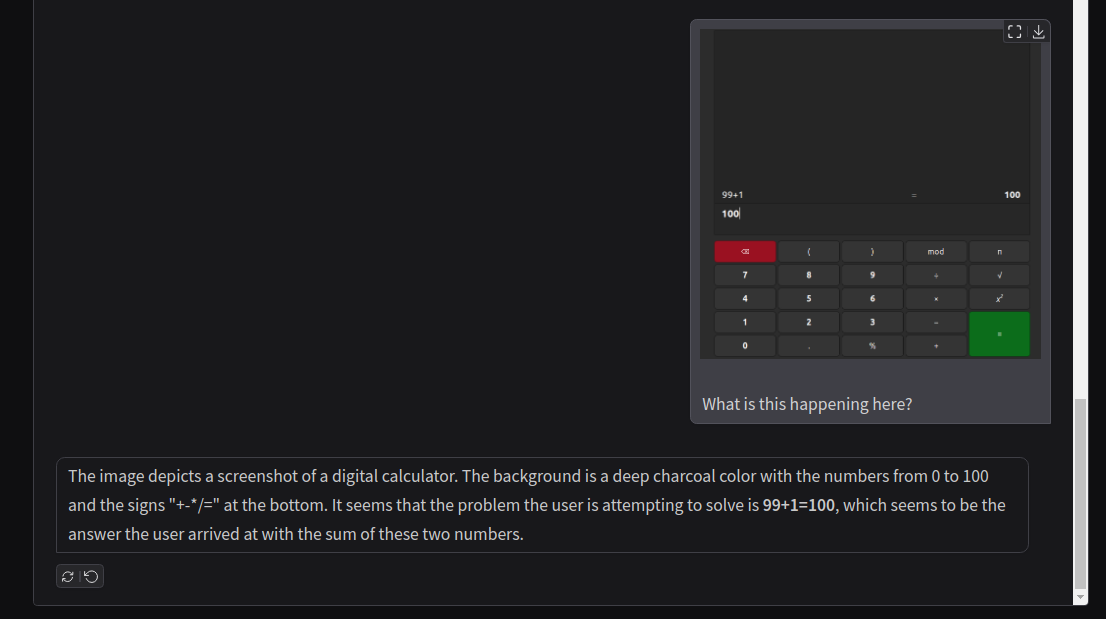
Although the model can accurately predict the arithmetic operation, it wrongly describes the number pad as being in the range from 0 to 100. We can consider this as a partial failure case for Llama 3.2 Vision.
LaTeX Equations (Failure Cases)
The model is inconsistent in generating the raw LaTeX equation from images.
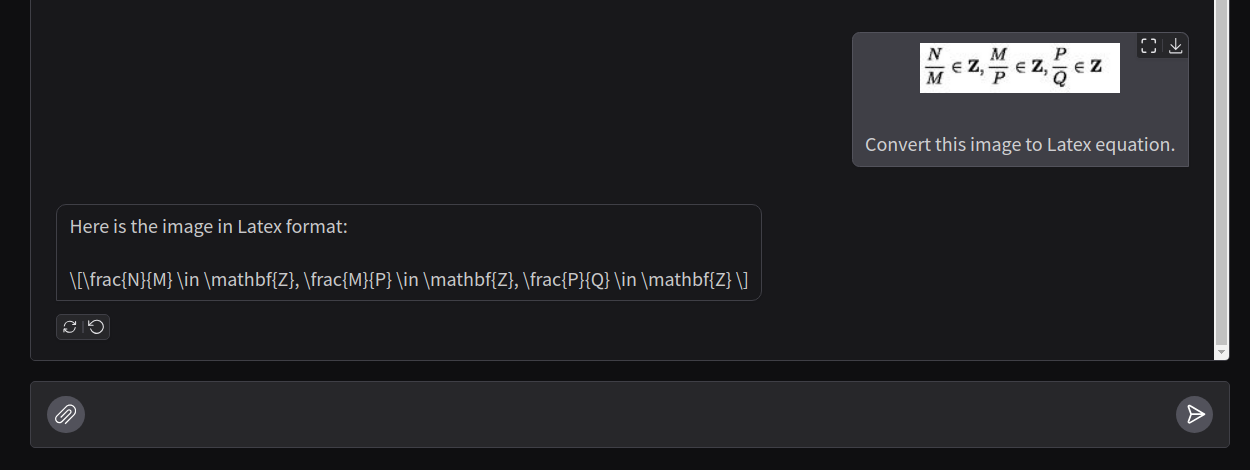
This time, the model generates the equation almost correctly. However, there are unnecessary square brackets, and the ending of the forward is also wrong.
VLMs can be particularly probabilistic in nature, so, let’s try once more.
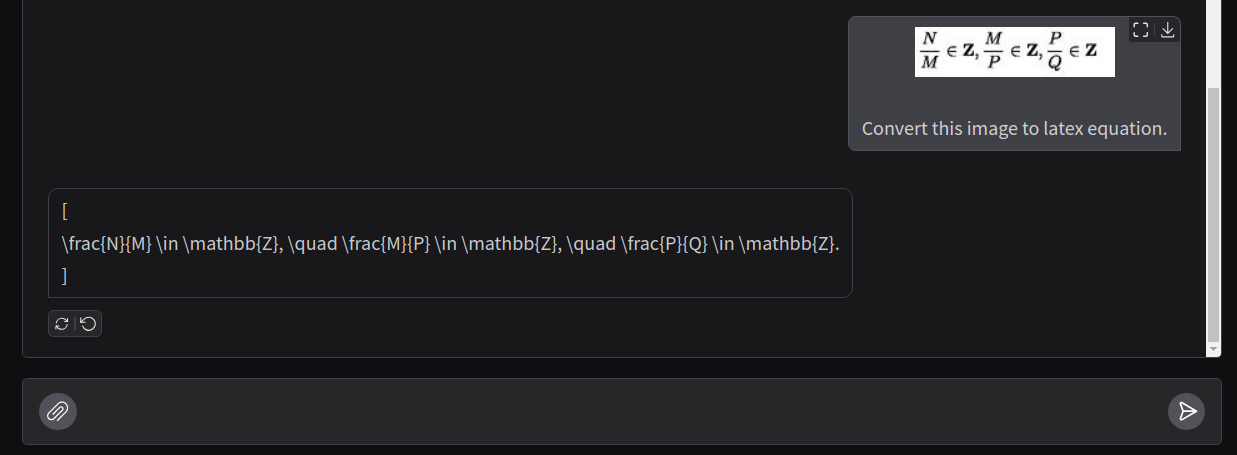
This time it adds two square brackets which will hinder automated function calling if we further want the equation to be rendered.
Let’s try once more.
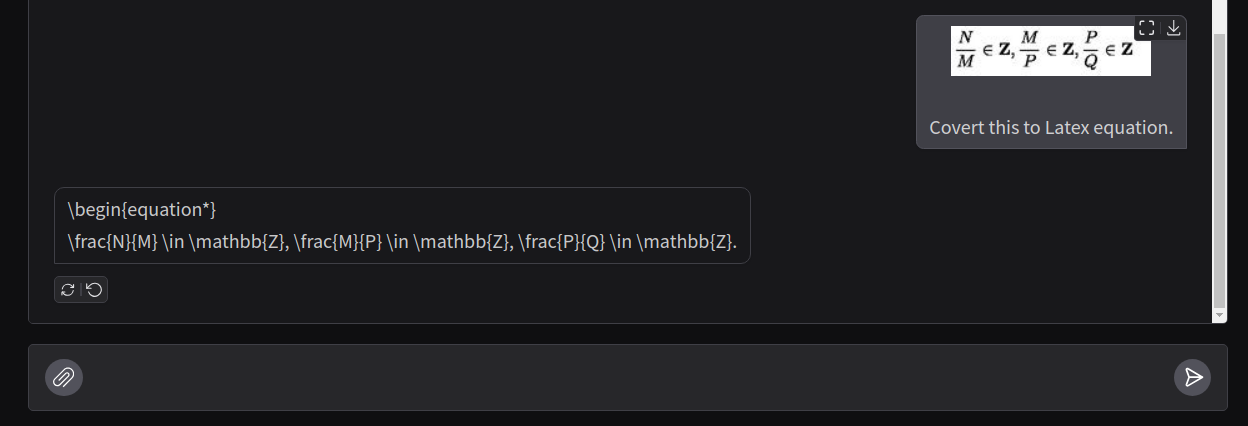
As we can see, it adheres to a different format this time which is fine. It adds the \begin equation component. However, it also adds an asterisk and does not end the equation.
As we can see, generating LaTeX equations is hit or miss using the Llama 3.2 Vision 11B model.
Telling Time on Watch Faces (Failure Cases)
When Molmo VLM was released, it made waves for being able to tell time on watch faces. It was simply trained to do so.
Let’s try that with Llama Vision.
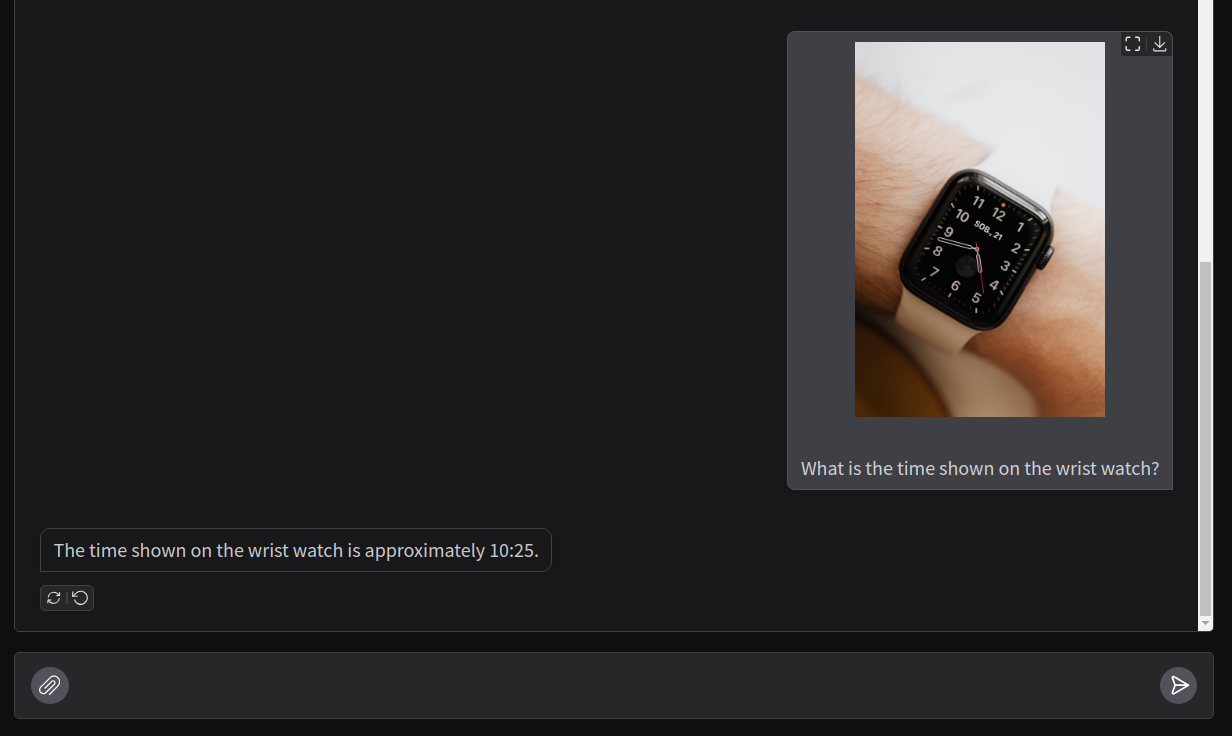
For a digital watch, the prediction is completely off.
Let’s try an extremely simple example.
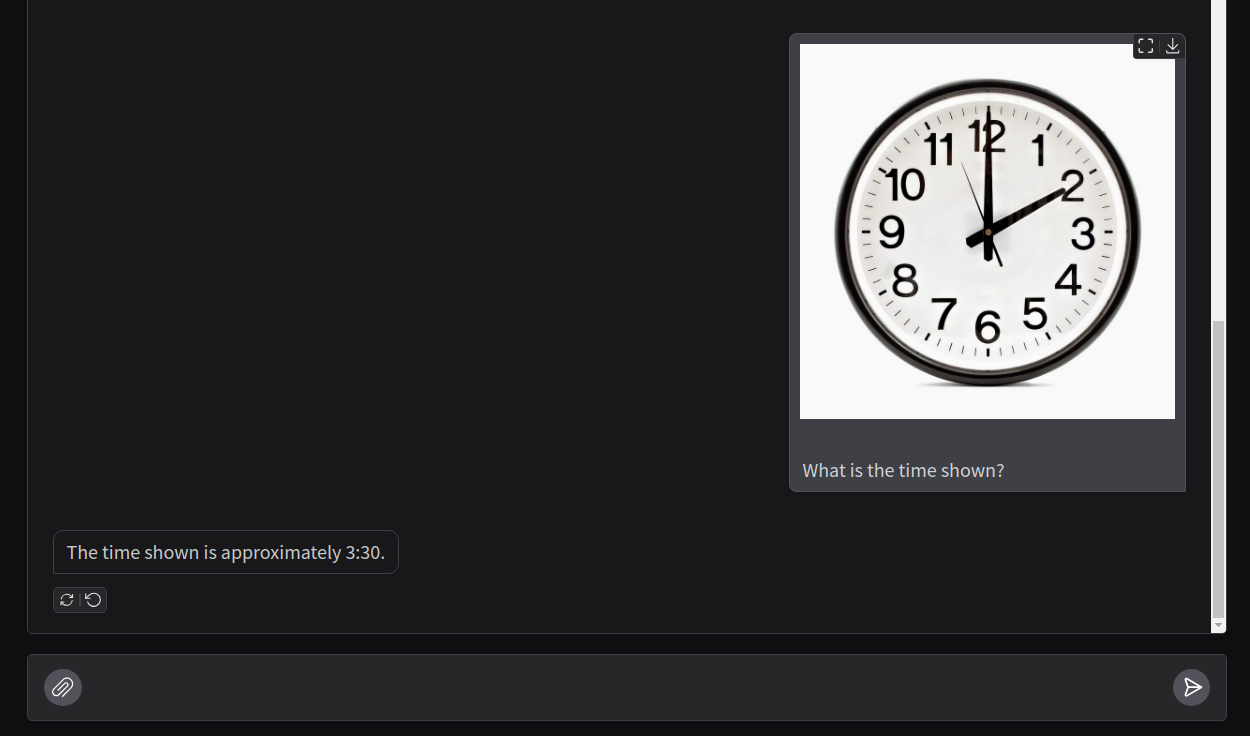
The analysis of time from watch faces is completely wrong by Llama 3.2 Vision model. The best guess is that it has not been trained to do so.
Takeaways
Here are a few takeaways from our experiments:
- The Llama 3.2 Vision model is extremely powerful at generating detailed captions for images. We experienced this first hand with “mirror image” and the “big bang” image.
- It can also generate JSON schemas and tell details from digital calculators.
- However, it falls short of generating LaTeX equations consistently and telling time on watch faces. One hypothesis is that this can be due to the fact that we are using the model in 4-bit format and we are using the 11B model. However, the 7B Molmo VLM can carry these out in a quantized format. Furthermore, we also tried the same experiments with the 11B and 90B models on Sambanova AI and it failed there as well. So, there is scope for fine-tuning and improvement after all.
Summary and Conclusion
We covered the Llama 3 Vision model in this article. Starting with the architecture, we moved on to inference using Jupyter Notebook and built a simple Gradio application. We analyzed the strengths and weaknesses of the model. The application did not include multi-turn chat that we intend to cover in future articles and also fine-tuning the model on LaTeX equations and telling time on watch faces. These are going to be interesting experiments. I hope this article was worth your time.
If you have any questions, thoughts, or suggestions, please leave them in the comment section. I will surely address them.
You can contact me using the Contact section. You can also find me on LinkedIn, and Twitter.
References

3 thoughts on “Llama 3.2 Vision – With Unsloth and Gradio”