

In this article, we will be instruction tuning the OpenELM models on the Alpaca dataset. Along with that, we will also build Gradio demos to easily query the tuned models. Here, we will particularly work on the smaller variants of the models, which are the OpenELM-270M and OpenELM-450M instruction-tuned models.
This is the third article in the OpenELM series. Following are the previous two articles that may be worth a read in case you are new to OpenELM models:
Why Fine Tune Already Instruction Tuned Models?
The instruction-tuned OpenELM models provided by the authors from Apple are good, but we can improve them, specifically for single-shot querying. As going through the inference post from the above list reveals, there are a few pitfalls in the models. Furthermore, they were trained only on 60000 Ultrachat samples. And it is difficult to find the instruction template for the models.
To overcome at least one of the reasons, i.e., to create a good single-turn instruction model, we will be instruction tuning the sub-billion parameters OpenELM models on the Alpaca dataset here. In future articles, we will train on larger and more conversation oriented and task specific datasets.
Note: A lot of the topics that we will need throughout have been covered in previous articles. You will find links to the relevant ones wherever needed. We will keep the fine-tuning part very specific, only discussing the important sections, and move on to create the Gradio demo.
We will cover the following topics in this article
- Setting up the environment.
- We will directly jump into the coding part of the article, specifically, the dataset formatting and preprocessing.
- This will also include the hyperparameters and fine-tuning of the OpenELM models.
- After training, we will build a simple Gradio demo for querying the models with instructions to get answers.
The Alpaca Instruction Tuning Dataset
We will be using the Alpaca Instruction tuning dataset to train the models. There are ~52000 instruction samples in this dataset.
I recommend going through the GPT-2 fine tuning article where we discuss the Alpaca dataset format in detail.
Project Directory Structure
The following block shows the directory structure.
├── openelm_270m_alpaca_sft │ └── best_model ├── openelm_450m_alpaca_sft │ └── best_model ├── gradio_custom_chat_alpaca.py ├── openelm_270m_alpaca_sft.ipynb └── openelm_450m_alpaca_sft.ipynb
- We have two notebooks, each for fine-tuning the respective Open-ELM models along with the directories with the best weights.
- We also have a Python script for the Gradio demo, that we will go through in detail later.
Download Code
The downloadable zip file contains both the training notebooks, the best weights, and the gradio demo script.
Libraries and Dependencies
We are using PyTorch as the base framework and need the following Hugging Face libraries:
- accelerate
- transformers
- trl
- datasets
- sentencepiece
All of these are installed directly when running the notebooks. Further, we also need to provide access by logging in through our Hugging Face access token. We need this as the OpenELM models use the LLama 2 Tokenizer, a gated repository. This option is available through the notebooks as well.
A Few More Articles Dealing with Instruction Tuning of LLMs
- Fine Tuning Phi 1.5 using QLoRA
- Fine-Tuning OPT-350M for Extractive Summarization
- Fine-Tuning Phi 1.5 for Text Summarization
- Fine Tuning Qwen 1.5 for Coding
- Hugging Face Autotrain – Getting Started
Instruction Tuning OpenELM Models on the Alpaca Dataset
In the following sections, we will go through some of the important parts of the training phase.
Note: We will primarily cover the training and inference of the OpenELM-450M model. You will get access to both the notebooks and weights and can switch the models for inference easily. Furthermore, we will keep the theoretical explanations sparse as the previous articles linked above cover them in detail.
Importing Libraries and Training Configurations
The following are all the libraries and modules that we need along the way to fine-tune the OpenELM-450M-Instruct model.
import os
import torch
from datasets import load_dataset
from transformers import (
TrainingArguments,
AutoModelForCausalLM,
AutoTokenizer,
pipeline,
logging
)
from trl import SFTTrainer
We will use the SFTTrainer module from the trl library to easily manage the instruction-tuning pipeline.
The next code block contains all the training configurations and hyperparameters.
batch_size = 2 num_workers = os.cpu_count() epochs = 3 bf16 = True fp16 = False gradient_accumulation_steps = 4 seq_length = 4096 logging_steps = 50 learning_rate = 0.0002 model_name = 'apple/OpenELM-450M-Instruct' tokenizer_name = 'meta-llama/Llama-2-7b-hf' out_dir = 'openelm_450m_alpaca_sft' seed = 42
Let’s take a deeper look into this.
- The
seq_length,batch_size, andgradient_accumulation_steps: We are using a longer sequence length of 4096. This is uncommon for single-turn instruction. However, after we have trained the model, we can use it for summarization of articles, generating code, and much more. If we follow the same fine tuning steps, and just fine-tune on code completion datasets, then a larger sequence length will help in generating larger code blocks. Without RoPE (Rotaty Positional Embedding), the sequence length a model has been trained with effectively becomes the context length of the model during inference.
As the sequence length is larger, we use a smaller batch size (while training on a 24GB VRAM GPU). We make up for it using agradient_accumulation_stepsof 4 which makes the final batch size 8. - Next, we use a slightly higher learning rate of 0.0002.
- The tokenizer is the LLama 2 7B tokenizer which is the same as the authors used for pretraining the model.
- Also, the model was trained on a 24GB L4 GPU based on the Ada Lovelace architecture. So, we are training with BF16. You can do the same with any RTX GPU as well. However, if you train on P100 or T4, you will have to use
bf16=Falseandfp16=True.
Loading the Alpaca Dataset and Formatting It
The next step is loading the Alpaca Instruction Tuning dataset properly and preprocessing it in the required format.
dataset = load_dataset('tatsu-lab/alpaca')
full_dataset = dataset['train'].train_test_split(test_size=0.05, shuffle=True, seed=seed)
dataset_train = full_dataset['train']
dataset_valid = full_dataset['test']
print(dataset_train)
print(dataset_valid)
We are splitting it into 49401 training and 2601 validation samples.
The next function preprocess the data when executed.
def preprocess_function(example):
"""
Formatting function returning a list of samples (kind of necessary for SFT API).
"""
text = f"### Instruction:\n{example['instruction']}\n\n### Input:\n{example['input']}\n\n### Response:\n{example['output']}"
return text
After formatting, the dataset samples look like the following:
Schools - CodeConquest - DevDocs</s><s> ### Instruction: Find the population of Nashville, TN ### Input: ### Response: The population of Nashville, TN is 697,000 (as of July 2019).</s><s> ### Instruction: Optimize the following query. ### Input: SELECT * FROM table_name WHERE id = 1 ### Response: SELECT * FROM table_name WHERE id = 1 ORDER BY id</s><s> ### Instruction: What is a positive adjective for describing a relationship? ### Input: ### Response: A positive adjective for describing a relationship is harmonious.</s><s> ### Instruction: Describe the experience of using a Virtual Reality headset. . . .
Loading the OpenELM-450M-Instruct Model and the Tokenizer
The following code blocks load the model and the tokenizer.
if bf16:
model = AutoModelForCausalLM.from_pretrained(model_name, trust_remote_code=True).to(dtype=torch.bfloat16)
else:
model = AutoModelForCausalLM.from_pretrained(model_name, trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained(
tokenizer_name,
trust_remote_code=True,
use_fast=False
)
tokenizer.pad_token = '</s>'
By default, the tokenizer does not contain a pad token. So, we add the </s> as the padding token.
Setting Up Training Arguments
Let’s initialize the Training Arguments before we can start the training.
training_args = TrainingArguments(
output_dir=f"{out_dir}/logs",
evaluation_strategy='epoch',
weight_decay=0.01,
load_best_model_at_end=True,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
logging_strategy='steps',
save_strategy='epoch',
logging_steps=logging_steps,
num_train_epochs=epochs,
save_total_limit=2,
bf16=bf16,
fp16=fp16,
report_to='tensorboard',
dataloader_num_workers=num_workers,
gradient_accumulation_steps=gradient_accumulation_steps,
learning_rate=learning_rate,
lr_scheduler_type='constant',
seed=seed
)
We have all the training arguments defined in the above code block.
Initializing the SFTTrainer and Starting the Training
The next step is to initialize the Supervised Fine-Tuning class and start the training process.
trainer = SFTTrainer(
model=model,
train_dataset=dataset_train,
eval_dataset=dataset_valid,
max_seq_length=seq_length,
tokenizer=tokenizer,
args=training_args,
formatting_func=preprocess_function,
packing=True
)
We just need to call the trainer() method to start the training.
history = trainer.train()
model.save_pretrained(f"{out_dir}/best_model")
tokenizer.save_pretrained(f"{out_dir}/best_model")
We save the best model weights and the tokenizer to the output directory.
Following are the training logs.
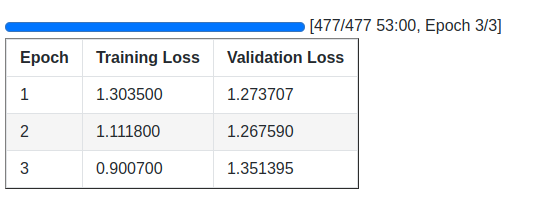
This ends the instruction tuning phase of the OpenELM-450M-Instruct model.
Building a Gradio Demo for Easy Inference
From here on, we will cover the coding part for building a Gradio demo for easier inference of the OpenELM model we just trained.
Before moving further, be sure to install Gradio using the following command.
pip install gradio
Let’s start by importing the libraries & modules, and loading the model and the tokenizer.
import gradio as gr
import threading
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
TextIteratorStreamer
)
device = 'cuda'
tokenizer = AutoTokenizer.from_pretrained(
'openelm_450m_alpaca_sft/best_model', trust_remote_code=True
)
model = AutoModelForCausalLM.from_pretrained(
'openelm_450m_alpaca_sft/best_model',
device_map=device,
trust_remote_code=True
)
We want to stream the text as the inference is happening and not wait till the entire inference has happened. To couple that with the Gradio output, we need to use the TextIteratorStreamer.
streamer = TextIteratorStreamer(
tokenizer, skip_prompt=True, skip_special_tokens=True
)
CONTEXT_LENGTH = 4096
We also manage a context length of 4096. When the entire input sequence is larger than 4096 tokens, we will truncate it.
Next, we have the function to carry out the next token prediction.
def generate_next_tokens(instructions, inputs):
if len(inputs) == 0:
inputs = '\n'
prompt = f"</s><s> ### Instruction:\n{instructions}\n### Input:\n{inputs}\n### Response:\n"
print('Prompt: ', prompt)
print('*' * 50)
tokenized_inputs = tokenizer(prompt, return_tensors='pt').to(device)
input_ids, attention_mask = tokenized_inputs.input_ids, tokenized_inputs.attention_mask
# A way to manage context length + memory for best results.
print('Global context length till now: ', input_ids.shape[1])
if input_ids.shape[1] > CONTEXT_LENGTH:
input_ids = input_ids[:, -CONTEXT_LENGTH:]
attention_mask = attention_mask[:, -CONTEXT_LENGTH:]
print('-' * 100)
generate_kwargs = dict(
{'input_ids': input_ids.to(device), 'attention_mask': attention_mask.to(device)},
streamer=streamer,
max_new_tokens=1024,
repetition_penalty=1.2
)
thread = threading.Thread(
target=model.generate,
kwargs=generate_kwargs
)
thread.start()
outputs = []
for new_token in streamer:
outputs.append(new_token)
final_output = ''.join(outputs)
yield final_output
The function accepts two user inputs, one mandatory instructions and an optional inputs, just like the dataset format.
We create our own prompt text for proper input to the model. Along with that, we manage the context length as well. We use the following keyword arguments for generation:
streamer=streamer: This is the text streamer class that we initialized earlier.max_new_tokens=1024: Each time, the model will generate a maximum of 1024 new tokens.repetition_penalty=1.2: A repetition penalty helps when generating longer answers.
The inference happens on a separate thread so that the token yielding to the output block is not blocked. This way we can stream the output as each of the tokens is being decoded.
Finally, we need to create the input boxes and the output text box using Gradio and start the interface.
instructions = gr.Textbox(lines=5, label='Instruction')
inputs = gr.Textbox(lines=5, label='Input')
output_text = gr.Textbox(label='Generated Text')
iface = gr.Interface(
fn=generate_next_tokens,
inputs=[instructions, inputs],
outputs=output_text,
title='OpenELM Alpaca Instruction'
)
iface.launch()
This ends the code that we need to build a Gradio demo for the instruction tuned OpenELM model. In the following section, we will carry out a few inference experiments.
Inference Experiments using the Instruction Tuned OpenELM Model with Gradio Demo
We can execute the following command to start the demo.
python gradio_custom_chat_alpaca.py
Then open the local host, that is, http://127.0.0.1:7860 when it appears on the terminal.
Following is the default template when we first open the web page.
We can provide only an Instruction or both, an Instruction and an Input.
Let’s start with a simple instruction.

We ask the mode “What is deep learning?”.
It gives a concise answer that looks right – nothing much to contemplate here.
Let’s give an instruction and input to the model.

We ask it to write a short article on LLMs and it does a fairly good job, although it does not get into the modern aspects of LLMs.
Next, we ask it to write a simple email.
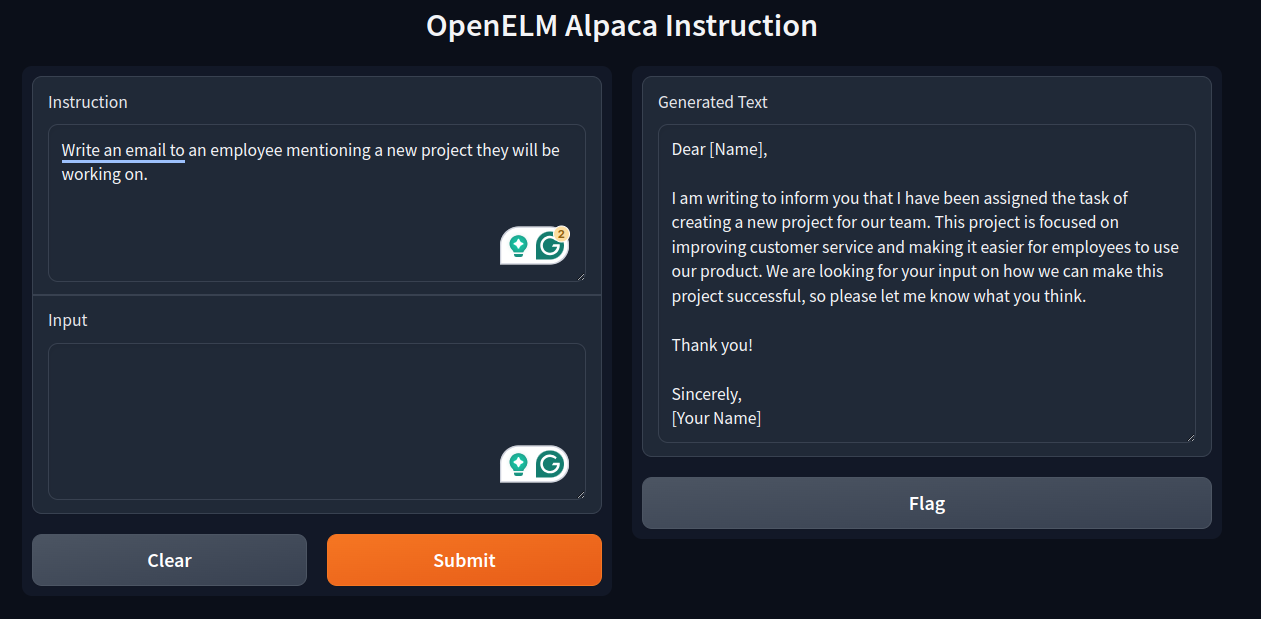
It does a good job here as well. Some parts could have been better.
Similarly, it does well on very simple coding and mathematics tasks.
Limitations of Single Turn Instruction and General Instruction Tuning
There are several limitations to the current model and approach.
- As the model is small it is unable to solve complex mathematical and coding problems.
- We have trained the model for single instruction, so, multi-turn instructions do not work well.
- Furthermore, it is not a chat model and the model does not have a system prompt.
We will try to fine tune the smaller OpenELM models for chatting in future articles.
Summary and Conclusion
We covered the instruction tuning of OpenELM models on the Alpaca dataset in this article. We covered the essential parts of the training process and built a simple Gradio demo for providing instruction as well. Along with that, we discussed a few limitations of the approach that we would like to address in future articles. I hope this article was worth your time.
If you have any doubts, thoughts, or suggestions, please leave them in the comment section. I will surely address them.
You can contact me using the Contact section. You can also find me on LinkedIn, and Twitter.

1 thought on “Instruction Tuning OpenELM Models on Alpaca Dataset and Building Gradio Demos”