

Unsloth has become synonymous with easy fine-tuning and faster inference of LLMs with fewer hardware requirements. From training LLMs to converting them into various formats, Unsloth offers a host of functionalities.
This article will cover some of the most important aspects of starting with Unsloth.
What will we cover while getting started with Unsloth?
- What is Unsloth?
- Why do we need Unsloth?
- How to install Unsloth on Ubuntu?
- How to we run inference with various LLMs?
- What is the ShareGPT chat template format and why do we need it?
- How to figure out chat template values for different models?
What is Unsloth?
Unsloth is a deep learning library that provides optimized inference and fine-tuning of LLMs.
The project was started by Daniel Han and Michael Han, now with several contributors on their GitHub repository.
Why Do We Need Unsloth?
Unsloth allows inference and fine-tuning of LLMs with low GPU VRAM requirements, making them extremely accessible. We can train an 8B parameter LLM on a 10GB VRAM system. Additionally, it provides various model weight exporting techniques for Ollama, vLLM, and GGUF. Furthermore, it is highly compatible with the Hugging Face Transformers library, making it versatile.
Naive fine-tuning of LLMs is expensive and compute-intensive. We need tens of gigabytes of VRAM (often surpassing hundreds of gigabytes) for full-tuning of LLMs. Although fine-tuning with QLoRA and LoRA mitigates some of the issues, it is only a solution till 3B parameter models when having a system with 10GB or 16GB VRAM. Larger models often require more VRAM even with QLoRA training.
This is where Unsloth shines. It makes training models up to 8B parameters (like the recent Llama 3.1 and its variants) a breeze even with 10GB VRAM. Unsloth can reduce memory requirements by up to 70% while providing 2x faster inference with their optimized pipeline. They also provide 4-bit quantized models so we can download models that are half in size.
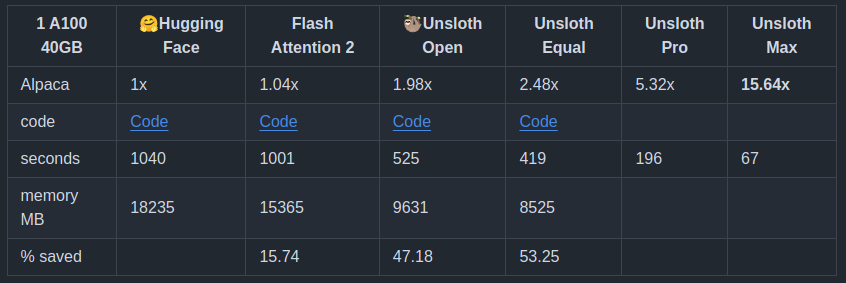
Figure 3 shows the speedup and GPU memory saving percentage when using Unsloth compared to naive Hugging Face and Flash Attention 2 implementations.
Unsloth lets developers get started with the least friction possible. Their support for the Tesla T4 GPU ensures wide use across Colab and Kaggle notebooks.
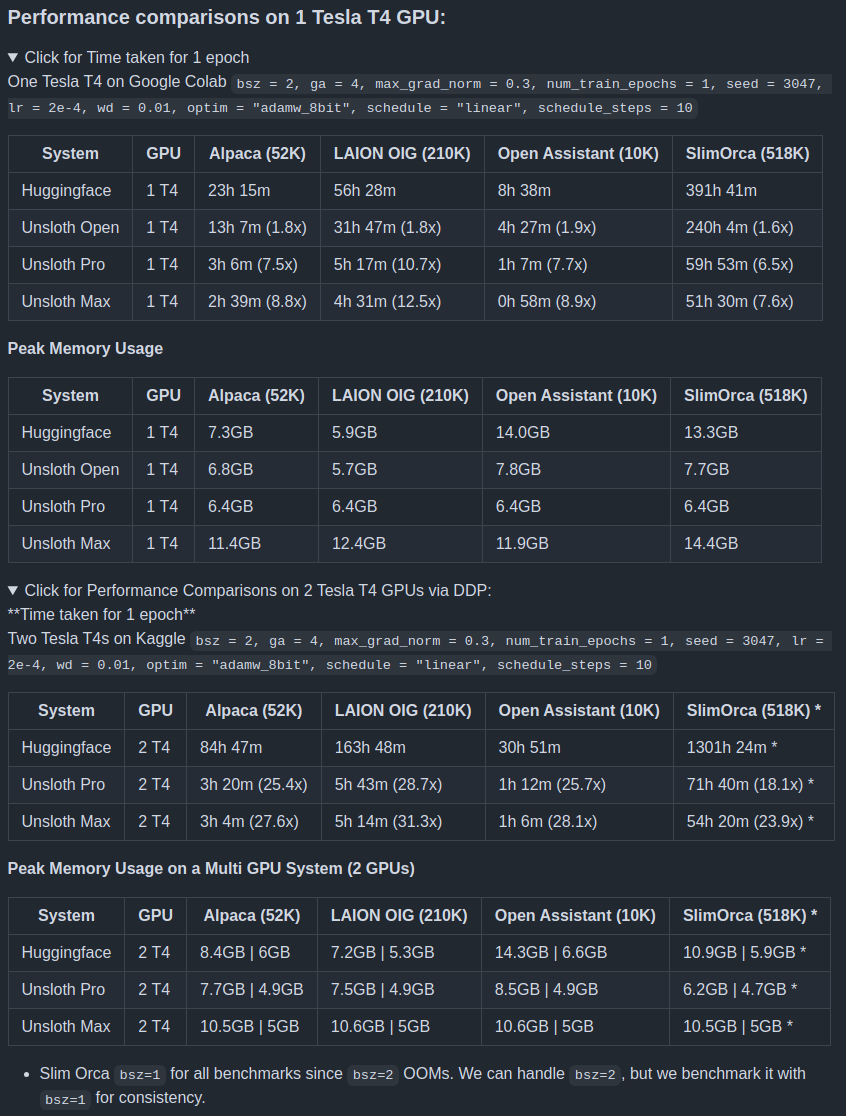
Figure 4 shows the number of hours and peak GPU memory required when training with Unsloth on various datasets with 1 and 2 Tesla T4 GPUs.
What are the Key Features of Unsloth?
The following are some of the key features of Unsloth:
- Unsloth’s kernels are written in OpenAI Triton language with a manual backpropagation engine.
- It supports all modern GPUs starting from 2018 and some older GPUs like Tesla T4 which makes it easier to fine-tune models on Colab.
- Linux setup is easy.
- Supports 4-bit and 16-bit fine-tuning of LLMs via LoRA and QLoRA.
- It is 5x faster compared to naive HuggingFace + Flash Attention implementation.
- There is no loss in accuracy when fine-tuning LLMs with all optimizations that Unsloth provides.
Unsloth supports all the Llama models, its derivatives, and other major model families as well. You can check the supported models here.
Additionally, they provide 4bit quantized models directly for download via Hugging Face saving both time and storage.
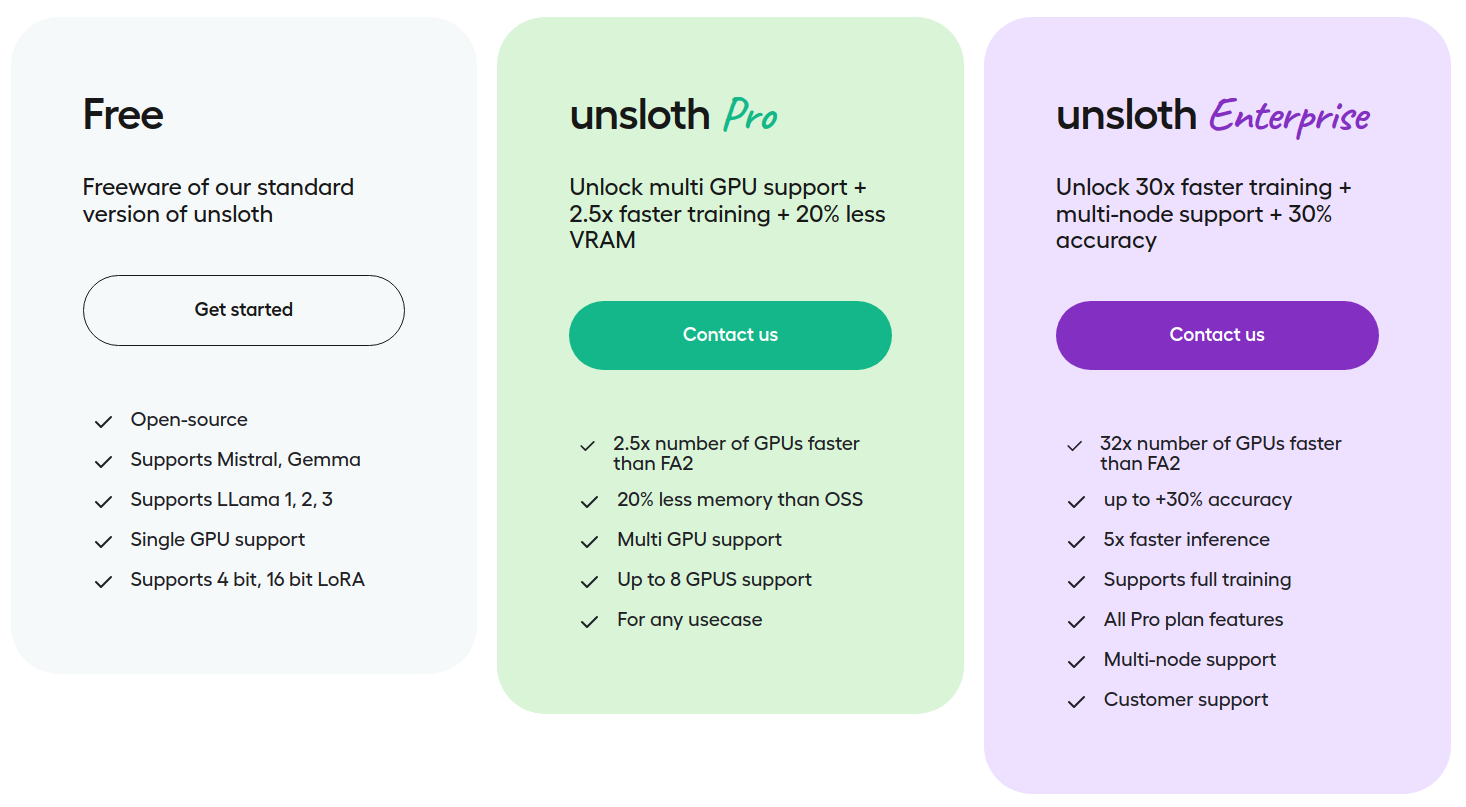
Apart from the open-source library, they also provide paid services. These include even faster training and inference, more GPU memory saving, multi-GPU support, and full fine-tuning of LLMs.
How to Install Unsloth on Ubuntu?
We will cover the installation on Ubuntu which is quite straightforward. It is highly recommended that you use the conda package manager which makes the installation even easier.
The first step is to create a new Anaconda environment with PyTorch and xformers, and activate the environment.
conda create --name unsloth_env \
python=3.11 \
pytorch-cuda=12.1 \
pytorch cudatoolkit xformers -c pytorch -c nvidia -c xformers \
-y
conda activate unsloth_env
Then install Unsloth and the rest of the requirements including the Hugging Face libraries.
pip install "unsloth[colab-new] @ git+https://github.com/unslothai/unsloth.git" pip install --no-deps trl peft accelerate bitsandbytes
If you wish to install it on Windows or via pip, please follow the instructions here.
Directory Structure
Let’s take a look at the directory structure for all the code that we will cover here.
├── unsloth_gemma2_2b.ipynb ├── unsloth_llama_3_1_8b.ipynb └── unsloth_mistralv03.ipynb
The directory contains three Jupyter Notebooks covering the inference of various models.
All the Jupyter Notebooks are available for download via the Download Code section.
Download Code
How to Run Inference Using Unsloth?
In this section, first, we will cover inference using LLMs with some of the important aspects of Chat Templates.
Inference Using Llama 3.1 8B
We will start with the inference using the Llama 3.1 8B model. The code for this resides in the unsloth_llama_3_1_8b.ipynb file. All notebooks contain setup steps for easily installing the libraries and running the code on Colab.
Importing the Necessary Libraries
Let’s start with the import statements.
from unsloth import FastLanguageModel from transformers import TextStreamer from unsloth.chat_templates import get_chat_template
Following are the functions and classes that we import:
FastLanguageModelfromunlsoth: We will use theFastLanguageModelclass to load the pretrained Llama 3.1 model.TextStreamerfromtransformers: TheTextStreamerclass allows us to stream the results as the tokens are generated by the LLM instead of waiting for the entire result.get_chat_template: This function allows us to load the chat template for a particular model and also map the special chat template tokens to another format (more on this later).
Load the Model
Now, let’s load the Llama 3.1 8B model.
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = 'unsloth/Meta-Llama-3.1-8B-Instruct-bnb-4bit',
max_seq_length=8192,
# load_in_4bit=True # Not needed when loading 4-bit models directly.
)
Just like the Transformers library, we use the from_pretrained method above to load the model. We can also specify a max_seq_length although that may not be necessary during inference.
One important aspect is the load_in_4bit argument. We have commented that out as we are specifically loading the unsloth/Meta-Llama-3.1-8B-Instruct-bnb-4bit which has already been quantized to 4-bit. We can also download the full precision model from Unsloth and pass load_in_4bit=True. However, the current method allows the download of smaller files as the weights have been reduced by almost 4x.
Tokenizer and Template Mapping
In the next code block, we load the chat template which also returns the updated tokenizer.
tokenizer = get_chat_template(
tokenizer,
chat_template = 'llama-3.1',
mapping = {'role' : 'from', 'content' : 'value', 'user' : 'human', 'assistant' : 'gpt'}, # ShareGPT style
)
A few important things are happening in the above code block.
- The chat template also loads the tokenizer.
- The
chat_templateargument accepts the model version/name. - We do mapping from the chat template tokens of Llama 3.1 to ShareGPT style chat template tokens.
The mapping does the following:
- The
role,content,user,assistanttokens are part of Llama 3.1 tokens. Check the tokenizer_config.json of Llama 3.1. - We replace them with
from,value,human,gptrespectively.
The above mapping allows us to switch between any model and not worry about managing history with different template tokens. We just need to take a look at the chat template of each model once to modify the mapping argument, then the rest of the code (as we will see later) remains the same.
For example, this is how a conversation thread in ShareGPT style might look like:
[
[{'from': 'human', 'value': 'Hi there!'},
{'from': 'gpt', 'value': 'Hi how can I help?'},
{'from': 'human', 'value': 'What is 2+2?'}],
[{'from': 'human', 'value': 'What's your name?'},
{'from': 'gpt', 'value': 'I'm Daniel!'},
{'from': 'human', 'value': 'Ok! Nice!'},
{'from': 'gpt', 'value': 'What can I do for you?'},
{'from': 'human', 'value': 'Oh nothing :)'},],
]
Before carrying out inference, we need to do one more optimization. We can apply the for_inference method to enable 2x faster inference using Unsloth.
# Enable native 2x faster inference FastLanguageModel.for_inference(model)
Carrying Out Inference
In the next code block, we use the ShareGPT style template to apply the chat template and get the input tokens. Because we have mapped the tokens above, the following will remain the same no matter the model we choose from Unsloth.
messages = [
{'from': 'human', 'value': 'Continue the fibonnaci sequence: 1, 1, 2, 3, 5, 8,'},
]
inputs = tokenizer.apply_chat_template(
messages, tokenize=True, add_generation_prompt=True, return_tensors='pt'
).to('cuda')
Next, we initialize the text streamer and pass the input tokens through the model.
text_streamer = TextStreamer(tokenizer)
_ = model.generate(
input_ids=inputs, streamer=text_streamer, max_new_tokens=1024, use_cache=True
)
Following is the output that we get.
<|begin_of_text|><|start_header_id|>system<|end_header_id|> Cutting Knowledge Date: December 2023 Today Date: 26 July 2024 <|eot_id|><|start_header_id|>human<|end_header_id|> Continue the fibonnaci sequence: 1, 1, 2, 3, 5, 8,<|eot_id|><|start_header_id|>assistant<|end_header_id|> The Fibonacci sequence is a series of numbers in which each number is the sum of the two preceding numbers: 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144,...<|eot_id|>
The interesting point to observe here is that Llama 3.1 still works with its own chat template tokens internally because that’s what it has been trained on. The mapping only helps to maintain a consistent chat template on the user level, and internally, these tokens are mapped to the original tokenizer.
Of course, we can use the original chat template tokens according to the model. But think about the case when we try to create a chat application with options for multiple models. It will be challenging to manage history when switching between different models because the messages list will have to contain the original chat template tokens.
Instead, just knowing and replacing the proper chat template tokens once when calling get_chat_template makes the rest of the pipeline streamlined.
To get an idea of what a multi-turn chat with a system prompt might look like, we have the next chat example. For the system prompt, we can set the value of the from key as system.
# Let's try with some system prompt.
messages = [
{"from": "system", "value": "You are a pro gamer. You answer everything concisely touching upon the most important points. You mostly play sim racing."},
{"from": "human", "value": "Who are you?"},
]
inputs = tokenizer.apply_chat_template(
messages, tokenize=True, add_generation_prompt=True, return_tensors='pt'
).to('cuda')
_ = model.generate(
input_ids=inputs, streamer=text_streamer, max_new_tokens=1024, use_cache=True
)
We get the following output.
<|begin_of_text|><|start_header_id|>system<|end_header_id|> Cutting Knowledge Date: December 2023 Today Date: 26 July 2024 You are a pro gamer. You answer everything concisely touching upon the most important points. You mostly play sim racing.<|eot_id|><|start_header_id|>human<|end_header_id|> Who are you?<|eot_id|><|start_header_id|>assistant<|end_header_id|> I'm Vroom, a pro sim racer. I compete in iRacing and Assetto Corsa Competizione.<|eot_id|>
As expected, the output of the model aligns with the system prompt.
For a final example, let’s try a multi-turn template.
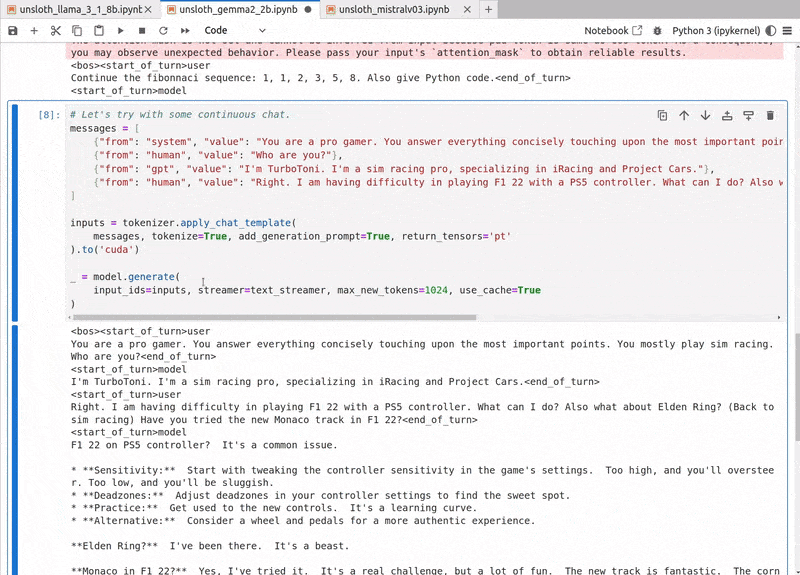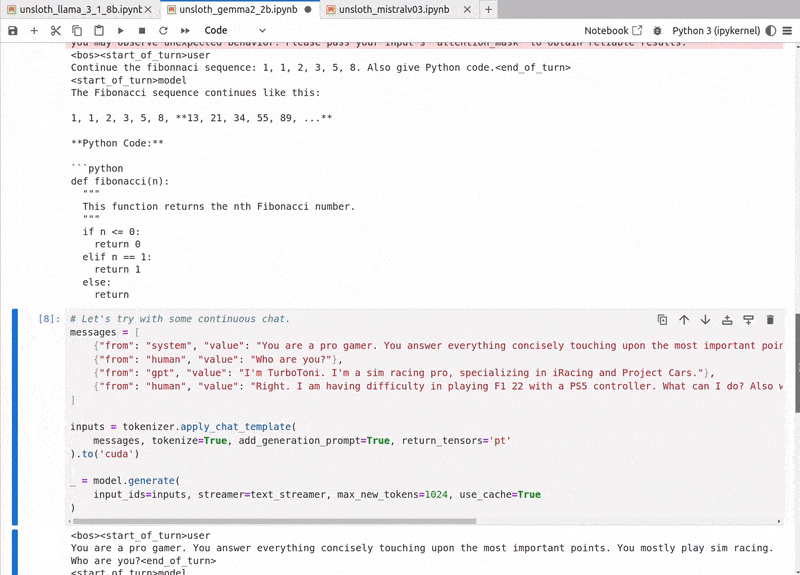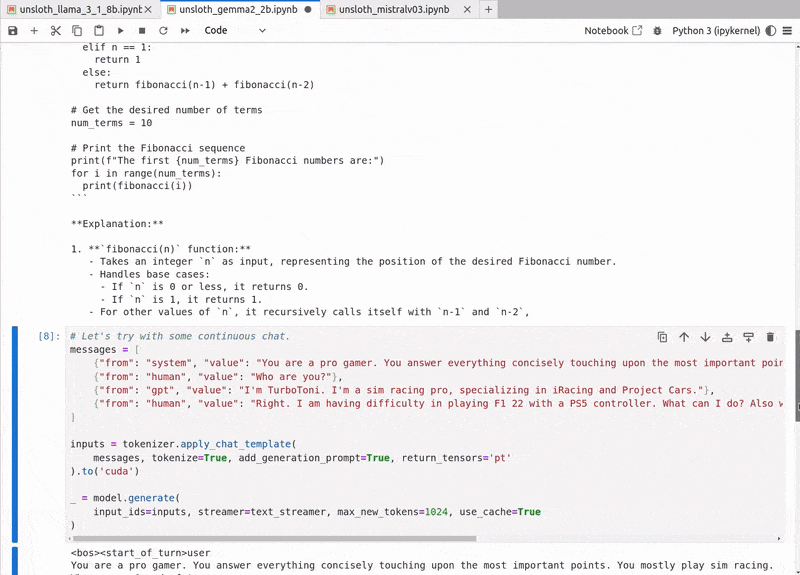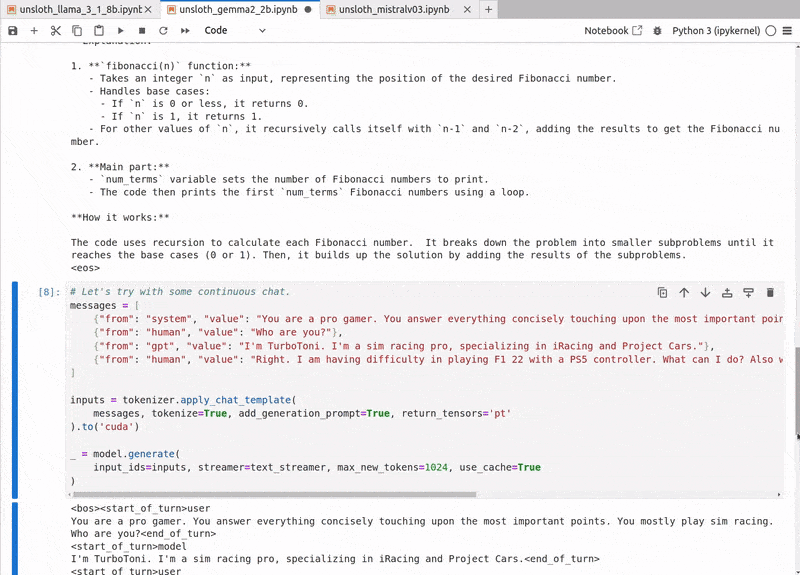
# Let's try with some continuous chat.
messages = [
{"from": "system", "value": "You are a pro gamer. You answer everything concisely touching upon the most important points. You mostly play sim racing."},
{"from": "human", "value": "Who are you?"},
{"from": "gpt", "value": "I'm TurboToni. I'm a sim racing pro, specializing in iRacing and Project Cars."},
{"from": "human", "value": "Right. I am having difficulty in playing F1 22 with a PS5 controller. What can I do? Also what about Elden Ring? (Back to sim racing) Have you tried the new Monaco track in F1 22?"},
]
inputs = tokenizer.apply_chat_template(
messages, tokenize=True, add_generation_prompt=True, return_tensors='pt'
).to('cuda')
_ = model.generate(
input_ids=inputs, streamer=text_streamer, max_new_tokens=1024, use_cache=True
)
The output aligns with the system prompt.
<|begin_of_text|><|start_header_id|>system<|end_header_id|> Cutting Knowledge Date: December 2023 Today Date: 26 July 2024 You are a pro gamer. You answer everything concisely touching upon the most important points. You mostly play sim racing.<|eot_id|><|start_header_id|>human<|end_header_id|> Who are you?<|eot_id|><|start_header_id|>gpt<|end_header_id|> I'm TurboToni. I'm a sim racing pro, specializing in iRacing and Project Cars.<|eot_id|><|start_header_id|>human<|end_header_id|> Right. I am having difficulty in playing F1 22 with a PS5 controller. What can I do? Also what about Elden Ring? (Back to sim racing) Have you tried the new Monaco track in F1 22?<|eot_id|><|start_header_id|>assistant<|end_header_id|> For F1 22 on PS5 controller, try adjusting the sensitivity and dead zone in the game's settings. You can also use the PS5's built-in controller settings to customize the stick and button responsiveness. As for Elden Ring, I'm not a fan of action games, but I've heard it's a great experience. I'll stick to sim racing, though. The new Monaco track in F1 22 is a great addition! It's a challenging circuit, and the new layout adds some excitement. I've spent a few hours racing there, and it's become one of my favorite tracks.<|eot_id|>
With the above examples, we get a clear idea for two tasks:
- Loading a 4-bit quantized model with Unsloth.
- Running inference with ShareGPT chat template for a more streamlined developer experience.
Loading Different Chat Models with ShareGPT Chat Template
Earlier, we discussed how we can load any mode and our chat conversation template remains the same.
To get a hands-on example, the following code block shows loading the Mistral v-0.3 chat model and its chat template.
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = 'unsloth/mistral-7b-instruct-v0.3-bnb-4bit',
max_seq_length=8192,
# load_in_4bit=True # Not needed when loading 4-bit models directly.
)
tokenizer = get_chat_template(
tokenizer,
chat_template='mistral',
mapping={'role' : 'from', 'content' : 'value', 'user' : 'human', 'assistant' : 'gpt'}, # ShareGPT style
)
When calling the get_chat_template function, we pass the chat_template value as mistral. The original chat template of Mistral v-0.3 is the same as Llama 3.1, so, we do not need to make any changes. After the above, the rest of the inference code remains the same.
Similarly, we can load the Gemma2-2B instruction-tuned model.
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = 'unsloth/gemma-2-2b-it-bnb-4bit',
max_seq_length=8192,
# load_in_4bit=True # Not needed when loading 4-bit models directly.
)
tokenizer = get_chat_template(
tokenizer,
chat_template='gemma2',
mapping={'role' : 'from', 'content' : 'value', 'user' : 'human', 'assistant' : 'gpt'}, # ShareGPT style
)
The only change here is that the value of the chat_template argument is gemma2.
Figuring Out chat_template Argument Value According to the Model
Unsloth provides several pretrained and chat models. It might be difficult to figure out all the possible values for the chat_template argument.
For example, in our examples:
- For Llama 3.1, the value was
llama-3.1. - For Gemme2, the value
gemma2. - However, for Mistral v-0.3, the value was
mistralwithout any version information.
One solution is visiting the chat template documentation of Unsloth. It provides the key arguments for the possible models. However, it might not be updated on time for new models.
The best solution to find the chat_template argument values is to visit the source code file.
Here, searching for CHAT_TEMPLATES[“ in the browser will give you all the possible values for each model. For instance, Llama 3.1 accepts both llama-3.1 and llama-31 as the chat template values. Similarly, Qwen-2.5 accepts qwen-2.5, qwen-25, qwen25, and qwen2.5 as the values.
The above shows that the authors of Unsloth favor developer experience and provide flexibility in getting a solution up and running in minimal time.
Summary and Conclusion
In this article, we covered how to get started with LLM inference using Unsloth. We started with the discussion of the need for Unsloth, how to set it up, the steps for carrying out inference, and finally the different chat templates for the models. I hope this article was worth your time.
If you have any questions, thoughts, or suggestions, please leave them in the comment section. I will surely address them.
You can contact me using the Contact section. You can also find me on LinkedIn, and X.

2 thoughts on “Unsloth – Getting Started”