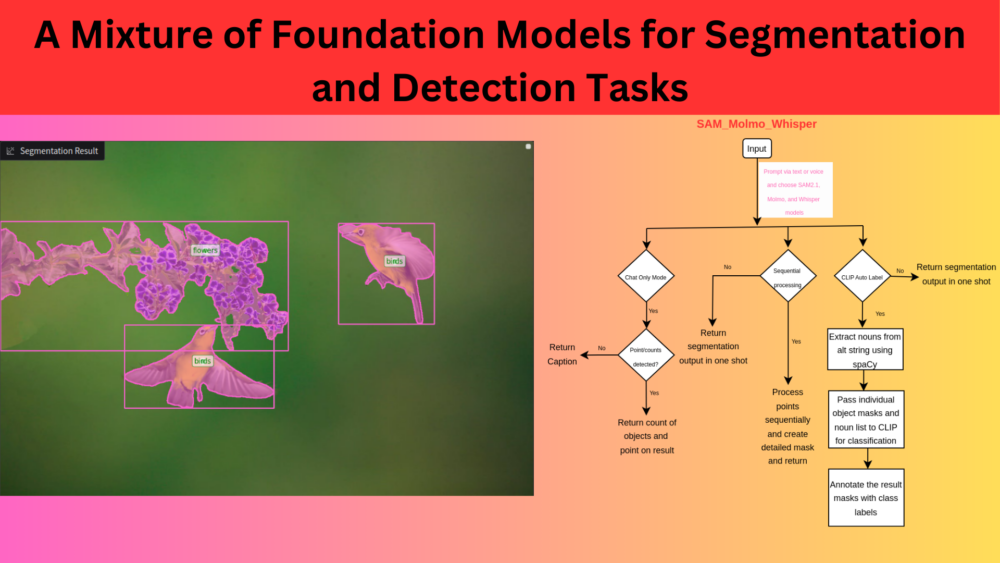
In this article, we explore how several foundation models in VLMs, Image Segmentation, and multi-modal models like CLIP help in open-ended class agnostic segmentation and detection tasks. ...
A Mixture of Foundation Models for Segmentation and Detection Tasks