

Starcoder and Starcoder 2 are two code-specific models by BigCode. In this article, we will have an introduction to both of these models.

Among the several use cases that LLMs have, coding assistant models are perhaps one of the most unique ones. The research in this field has been going on for a long time and developing performant models is difficult. However, most organizations keep the methodology private and only make the weights open-source. Starcoder and Starcoder 2 models are a big deviation from this practice. And that’s what makes the research valuable.
What are we going to cover regarding Starcoder and Starcoder 2?
- Why does Starcoder and Starcoder 2 research by BigCode matter?
- Why building coding assistant models are difficult?
- The details of Starcoder
- The details of Starcoder 2
- For each mode, we will discuss in short the:
- Dataset collection methodology
- Model Architecture and Training Details
- Results compared to other models
Why Does the Starcoder and Starcoder 2 Research by BigCode Matter?
In short, everything starting from the model weights to the dataset is open.
While more organizations are starting to make LLMs open source, in reality, they only open source the weights. Other important details like the dataset creation process, and the training regime, although detailed in the paper, we hardly get to see them.
Contrary to this, the BigCode research made everything public:
- The Starcoder and Starcoder 2 weights
- The dataset preparation process and the dataset itself
- Fine-tuning and inference code
- Along with that an OpenRAIL-M access that allows the model weights to be redistributed, used for downstream and commercial tasks as well.
This is a big deviation from other research organizations which only make the model weights open-source under a restrictive commercial license.
Why Building Coding Assistants Are Difficult?
Building coding LLMs or assistants contains the constraints already associated with building LLMs:
- Collecting a huge amount of high quality text data.
- If necessary create a new LLM architecture from scratch.
- The necessary compute for dataset processing, training, and evaluation.
On top of that, there are a few overheads:
- Although coding LLMs can be trained just on the collected code data for “next token prediction”, this may not always give the best results. Structuring the dataset and where each code sample begins or ends can become a crucial step between the best performing model and the average model.
- Although collecting licensed data is a concern in any large scale deep learning training, it is even more so for training coding LLMs. It is already given that each codebase belongs to someone. That means the license of the codebase comes into play. Even after collecting all the data (say, from GitHub), giving a chance to the users to remove their code from the dataset may be a necessary step.
- Even after the model has been trained, it may generate code from non-commercially licensed codebase verbatim. It may become a bigger issue if such code is used in a commercial product.
Later in the article, we will understand how the authors of Starcoder handled the above concerns. For now, let’s move on to the details of Starcoder.
Starcoder
Starcoder is the first model in the Starcoder family of models.
Released with the paper, StarCoder: may the source be with you! by Li et al., Starcoder soon became the most open code language model research.
Before moving forward, there is one important point to mention here. Although the paper was released only with Starcoder 15.5B and StarcoderBase 15.5B models, later more base models in the parameter ranges of 1B, 3B, and 7B were released on Hugging Face.
Dataset Collection Strategy for Starcoder
The Starcoder model was trained on The Stack v1.2. This is a de-duplicated version of the The Stack containing only permissively licensed code, and the code of the users who opted out has been removed.
Analyzing the dataset on Hugging Face reveals two points:
- It contains 237 million rows
- It is around 935 GB in size

The final dataset contains 86 programming languages which are outlined in tables 1 and 2 of the paper.
Different Dataset Formats
The Stack v1.2 contains several dataset formats from numerous sources. These include sources like:
- Jupyter notebooks converted to scripts and structured Python + Markdown text
- GitHub issues and commits
Furthermore, the authors also carried out different types of filtering on the datasets such as:
- Visual inspection to retain high quality data
- Applying XML filters to remove XML structured code
- Alpha filter to remove files with less than 25% alphabetic character
- HTML filters to remove code with excessive HTML boilerplate
- JSON and YAML filters where YAML files within 50-5000 characters and JSON files within 50-5000 characters and more than 50% alphabetic characters are retained in the dataset.
Starcoder Model Architecture and Training Details
The Starcoder 15.5B model is based on SantaCoder, also by authors from BigCode.
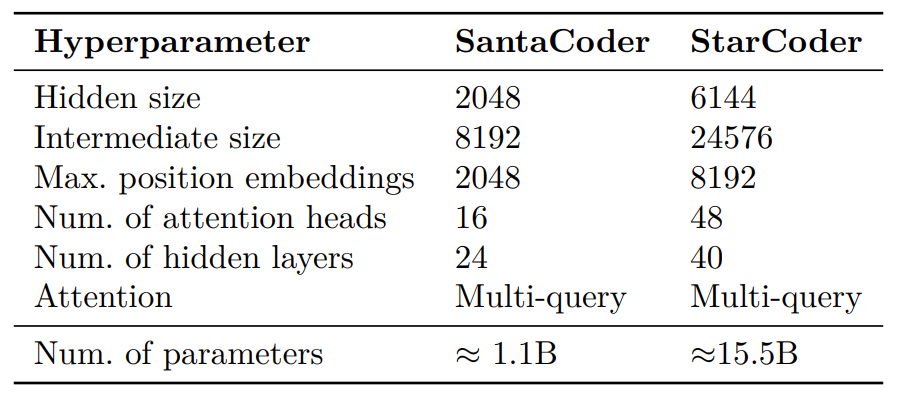
Like other LLMs, it is a decoder-only Transformer architecture. It supports a context length of up to 8K tokens. There are two versions of the Starcoder model:
- StarCoderBase: This is the base model that was trained on 1 trillion tokens of the Stack v1.2. It was trained for 250k iterations with a global batch size of 4M tokens with the Adam optimizer.
- StarCoder: This is a fine-tuned version of StarCoderBase trained on an additional 35B Python tokens. The model was trained for 2 epochs.
Evaluation and Benchmark
The authors evaluated the StarCoder and StarCoderBase models on several benchmarks. Here we will discuss the following:
- HumanEval
- MBPP
- DS-1000 for Data Science benchmark
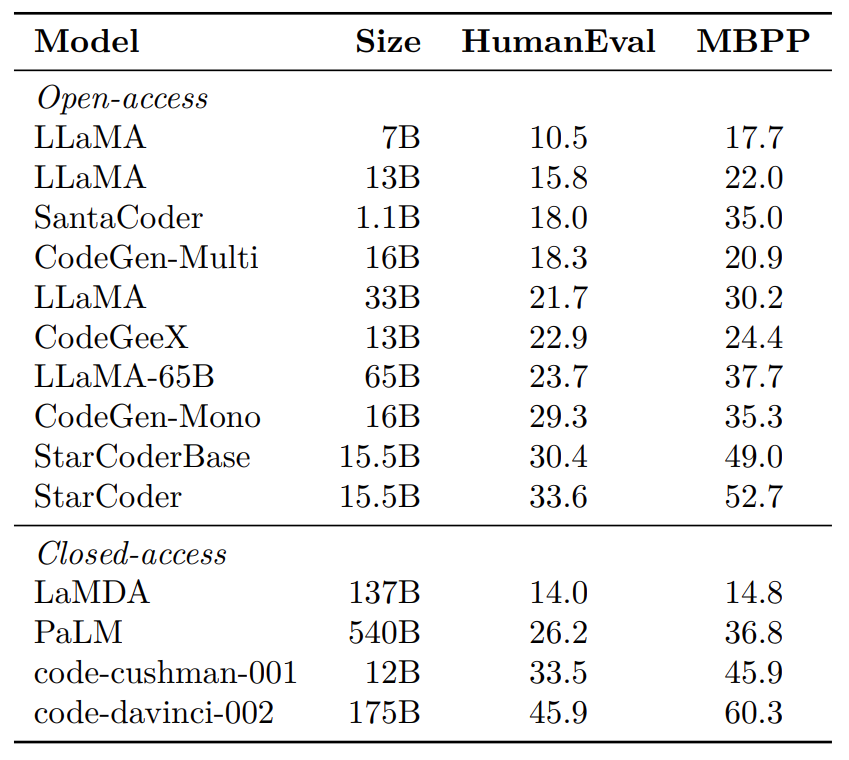
On HumanEval and MBPP, both the models surpass all the open-access models, even the ones that are substantially larger, like LLama-65B. For the closed source models, they are only behind code-davinci-002 and StarCodeBase scores less than code-cushman-001 on HumanEval.
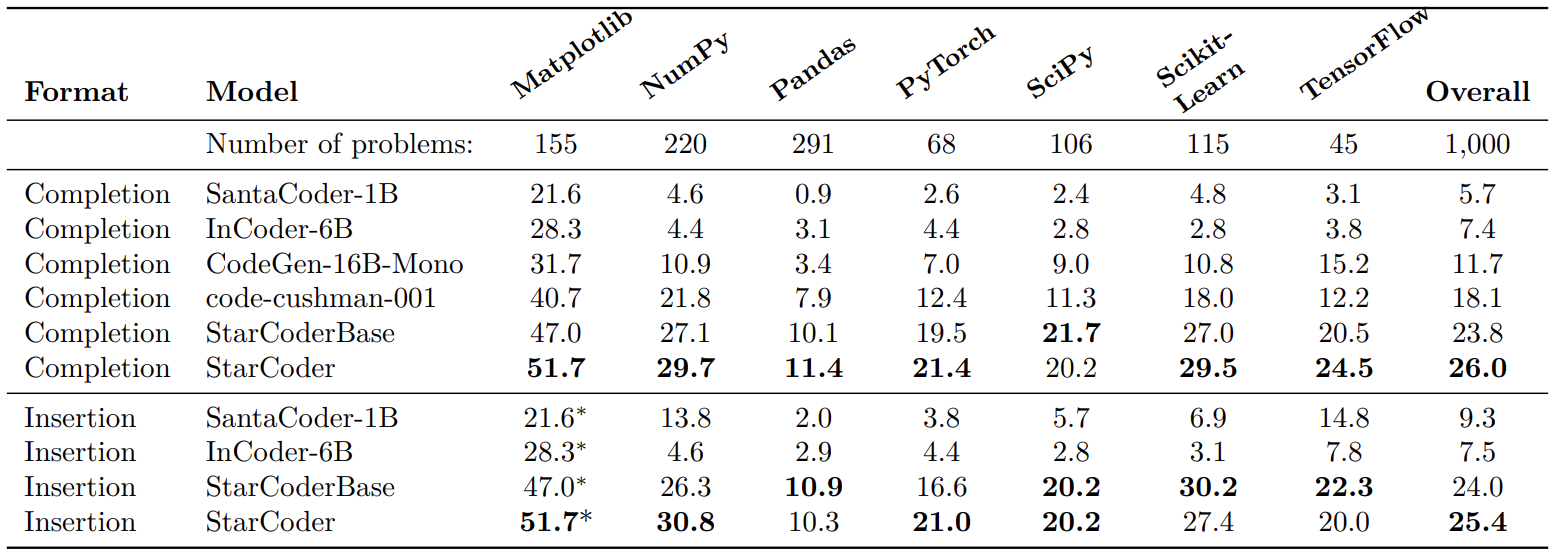
On the DS-1000 benchmark, StarCoder performs especially well on the code completion task while both perform well on the code insertion task.
I would highly recommend going through the benchmark section completely once to gain even more insights about the model’s performance.
StarCoder 2
Now, we will move on to the discussion of StarCoder 2. This is the next iteration of the StarCoder model. The paper titled StarCoder2 and The Stack v2: The Next Generation by Anton Lozhkov et al. introduces two things: a new model and a new version of the Stack, called The Stack v2.
Several things remain the same as in the StarCoder pipeline. We will discuss some of the important parts here.
Dataset Collection Strategy for StarCoder 2
The Stack v2 is built on top of the Software Heritage archive. Along with that, the authors also source data from:
- GitHub issues and pull requests
- Jupyter and Kaggle notebooks
- Codebase documentations
- Intermediate representations of code
- Math and coding datasets
When building coding LLMs, we need to be careful about the licensing. Only permissive licensed code from GitHub is used to train the StarCoder 2 models. Following is the license assignment logic used by the authors to select the permissively licensed code.
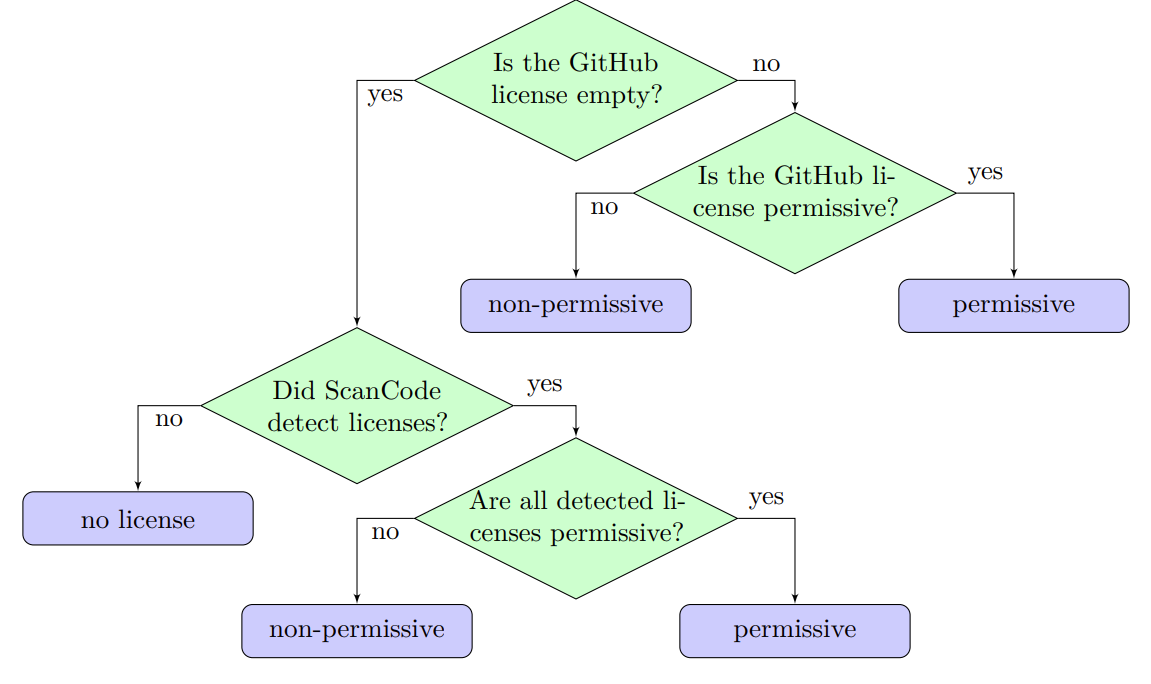
All the basic filtration techniques used in StarCoder are used here as well. The final dataset contains over 600 programming languages. However, there are four different versions of the dataset as outlined below (source Hugging Face datasets):
- bigcode/the-stack-v2: the full “The Stack v2” dataset
- bigcode/the-stack-v2-dedup: based on the bigcode/the-stack-v2 but further near-deduplicated
- bigcode/the-stack-v2-train-full-ids: based on the bigcode/the-stack-v2-dedup dataset but further filtered with heuristics and spanning 600+ programming languages. The data is grouped into repositories.
- bigcode/the-stack-v2-train-smol-ids: based on the bigcode/the-stack-v2-dedup dataset but further filtered with heuristics and spanning 17 programming languages. The data is grouped into repositories.
Starcoder 2 Model Architecture
There are three versions of the StarCoder 2 model: 3B, 7B, and 15B.
There are slight variations to the architecture compared to the first iteration:
- Instead of learned positional embeddings, the authors use RoPE (Rotary Positional Embeddings)
- Replacing the Multi-Query Attention (MQA) with Grouped Query Attention (GQA)
Following are the architectural details.
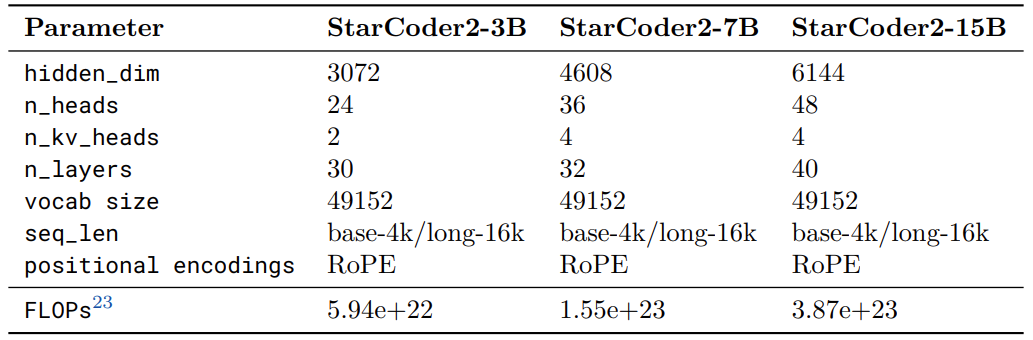
During the initial training phase, the authors train the models with a sequence length of 4096. All the models then undergo further pretraining for long-context training with 16,384 context length.
Evaluations and Benchmarks
The paper details the evaluations on several benchmarks. However, here we will cover the same ones that we covered for StarCoder.
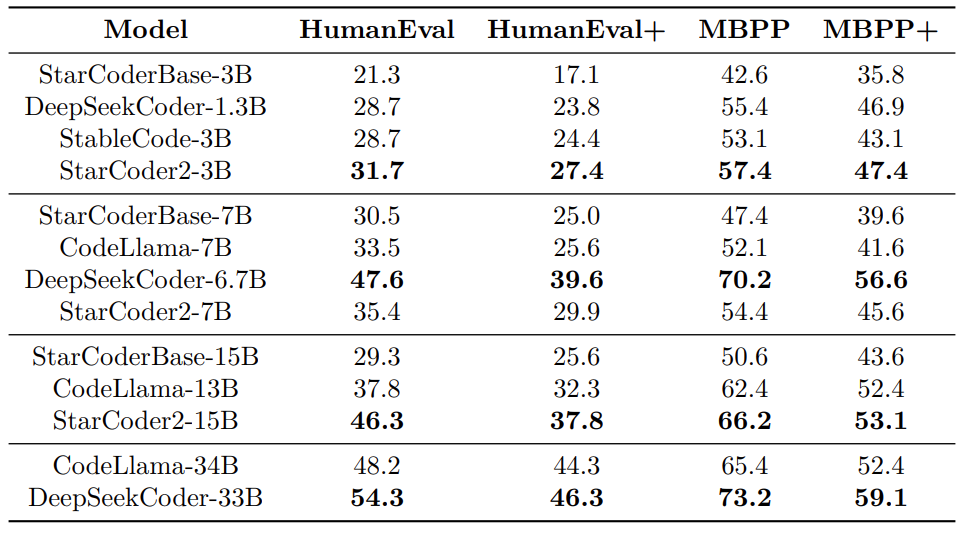
In HumanEval and MBPP benchmarks the StarCoder2-3B model is performing exceptionally well, beating all models of the same size. The results are similar for the StarCoder2-15B model, which also scores close to the CodeLlama-34B. However, the 7B variation of the StarCoder 2 model falls behind DeepSeekCoder-6.7B. The authors also point this out in the paper and mention that they don’t have a reason for this at the time of release.
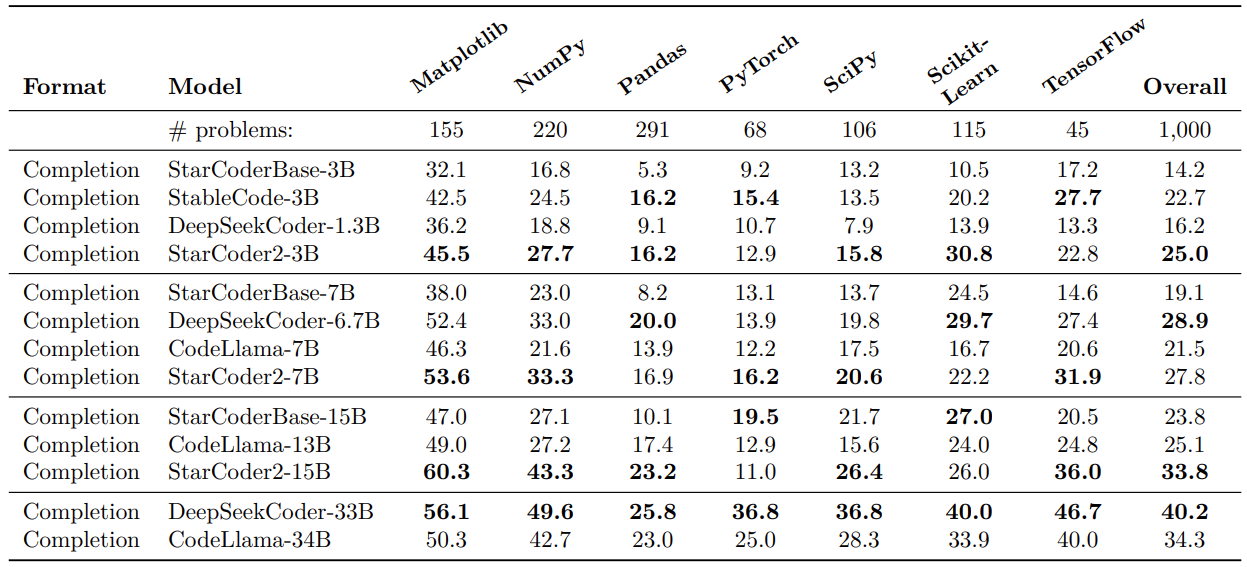
The DS-1000 dataset contains 1000 data science tasks in Python.
In this benchmark, all the StarCoder 2 models perform well in most cases. The 3B model falls behind StableCode-3B in some of the tasks (Pandas, PyTorch, TensorFlow). Overall, the StarCoder2 3B and 15B models are the best in their model sizes.
I would highly recommend going to all the benchmarks in the paper to gain more in-depth insights.
Summary and Conclusion
In this article, we covered the StarCoder and StarCoder 2 models. Starting from the dataset preparation, and the model architecture, to the benchmarks, we covered the important aspects of both papers. In future articles, we will cover how to use and fine-tune code models for personalized tasks. I hope that this article was worth your time.
If you have any doubts, thoughts, or suggestions, please leave them in the comment section. I will surely address them.
You can contact me using the Contact section. You can also find me on LinkedIn, and Twitter.
References
- StarCoder: may the source be with you!
- StarCoder 2 and The Stack v2: The Next Generation
- The Stack v1 de-duped

4 thoughts on “Introduction to StarCoder and StarCoder 2”