

Vision-Language Models (VLMs) are transforming how we interact with the world, enabling machines to “see” and “understand” images with unprecedented accuracy. From generating insightful descriptions to answering complex questions, these models are proving to be indispensable tools. SmolVLM emerges as a compelling option for image captioning, boasting a small footprint, impressive performance, and open availability. This article will demonstrate how to build a Gradio application that makes SmolVLM’s image captioning capabilities accessible to everyone through a Gradio demo.
This article focuses on leveraging the power of SmolVLM through practical implementation. We will guide you through the process of building a Gradio application that showcases the model’s core ability: image captioning. The article includes the code and detailed explanations needed to start experimenting.
What We Will Cover?
- Image Captioning with SmolVLM
- Building a Gradio application to access SmolVLM functionality
Why We Need a SmolVLM Gradio Application?
Interacting directly with VLMs like SmolVLM often involves writing code to process visual data, formulate prompts, and interpret the model’s output. This can be challenging, especially for users who simply want to explore the model’s image captioning capabilities or quickly test it with their own images.
The SmolVLM Model: Small Yet Mighty
SmolVLM is a compact, open multimodal model that accepts arbitrary sequences of image and text inputs to produce text outputs. Designed for efficiency, SmolVLM can answer questions about images, describe visual content, create stories grounded on multiple images, or function as a pure language model without visual inputs. Its lightweight architecture makes it suitable for on-device applications while maintaining strong performance on multimodal tasks.
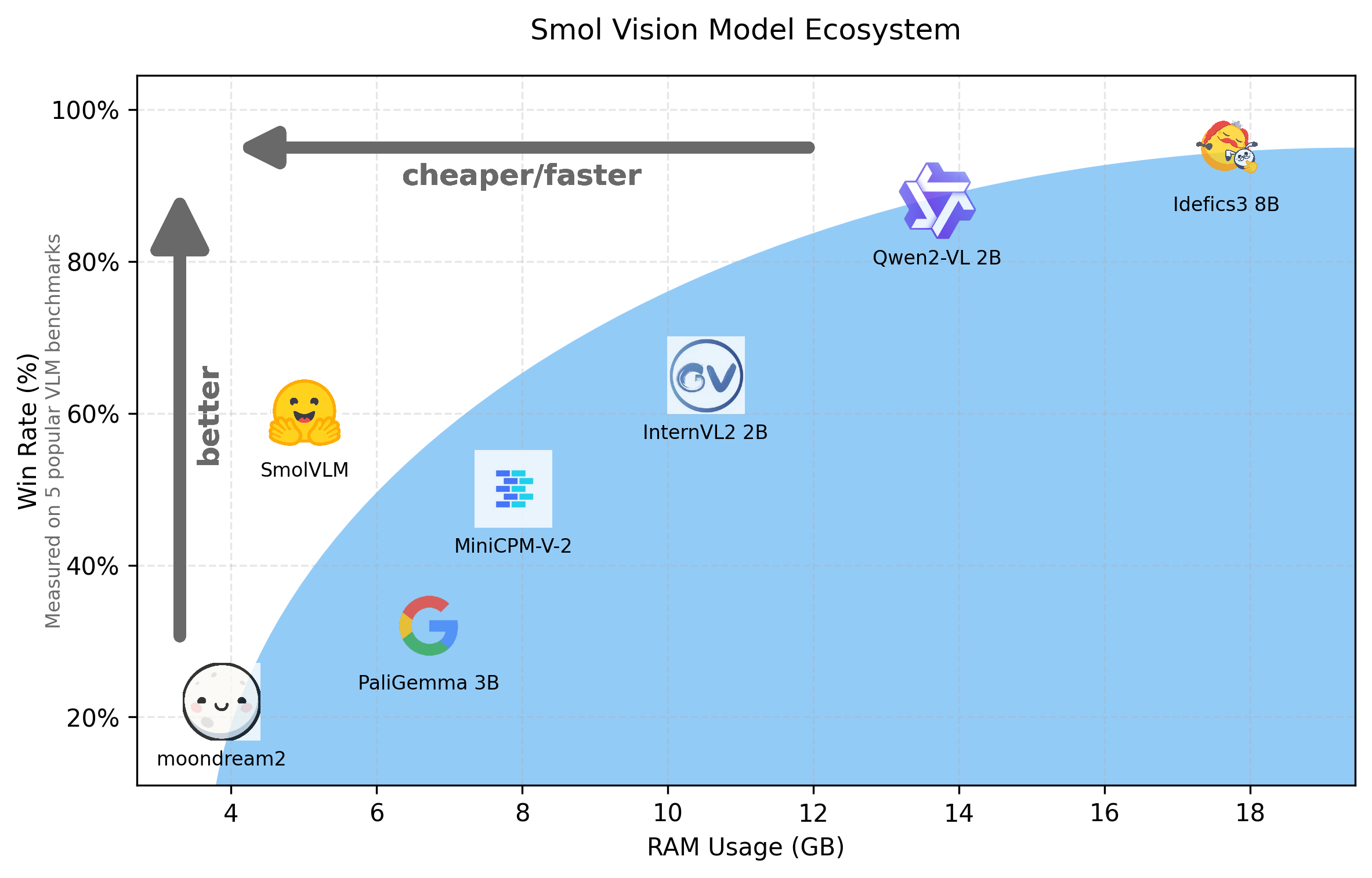
SmolVLM leverages the lightweight SmolLM2 language model to provide a compact yet powerful multimodal experience. It introduces a more radical image compression compared to Idefics3 to enable the model to infer faster and use less RAM. SmolVLM uses 81 visual tokens to encode image patches of size 384×384. Larger images are divided into patches, enhancing efficiency without compromising performance.
The SmolVLM model has three different parameter sizes: SmolVLM-256M, SmolVLM-500M, and SmolVLM-2B.
Directory Structure
Before we start building the SmolVLM Gradio application, let’s look at the directory structure.
├── app.py └── requirements.txt
- The
app.pyscript contains the Gradio application code. - The
requirements.txtfile lists the necessary libraries.
All the code can be downloaded from the download section.
Download Code
Installing Dependencies
The code requires PyTorch as its base framework. Create a new Anaconda environment and install the latest version of PyTorch from here.
Then, install the remaining libraries using the requirements file:
pip install -r requirements.txt
Building the SmolVLM Gradio Interface: A Simple Image Captioning Demo
Let’s dive into the code to build the Gradio demo.
First, we will cover the complete code and then break down each section of the code.
Complete Code for the SmolVLM Gradio Application
Here’s the complete code for the Gradio application.
import gradio as gr
import torch
from transformers import AutoProcessor, AutoModelForVision2Seq
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
model_id = "HuggingFaceTB/SmolVLM-Instruct"
# Load model and processor outside the function for efficiency
processor = AutoProcessor.from_pretrained(model_id)
model = AutoModelForVision2Seq.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
_attn_implementation="flash_attention_2",
).to(DEVICE)
def image_captioning(image_input, prompt):
"""Image Captioning Function."""
messages = [
{
"role": "user",
"content": [
{"type": "image"},
{"type": "text", "text": prompt},
],
},
]
prompt = processor.apply_chat_template(messages, add_generation_prompt=True)
inputs = processor(text=prompt, images=[image_input], return_tensors="pt").to(DEVICE)
prompt_length = inputs['input_ids'].shape[1]
generated_ids = model.generate(
**inputs,
max_new_tokens=200
)
generated_text = processor.decode(
generated_ids[0][prompt_length:],
skip_special_tokens=True
)
return generated_text
with gr.Blocks() as demo:
gr.Markdown("# SmolVLM Demo")
image_input = gr.Image(label="Input Image")
prompt_image = gr.Textbox(label="Prompt", value="Describe this image.")
caption_output = gr.Textbox(label="Caption Output")
image_button = gr.Button("Run")
image_button.click(
image_captioning,
inputs=[image_input, prompt_image],
outputs=[caption_output],
)
demo.launch(share=True)
You can directly copy-paste this code into your own file and execute via python app.py and start playing around.
Code Breakdown
Let’s break down each section of the code.
Import Statements and Loading the Loading the SmolVLM 2B Model
First, the import statements and loading the SmolVLM model and the processor.
import gradio as gr
import torch
from transformers import AutoProcessor, AutoModelForVision2Seq
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
model_id = "HuggingFaceTB/SmolVLM-Instruct"
# Load model and processor outside the function for efficiency
processor = AutoProcessor.from_pretrained(model_id)
model = AutoModelForVision2Seq.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
_attn_implementation="flash_attention_2",
).to(DEVICE)
This section imports the necessary libraries and loads the pre-trained SmolVLM model and its associated processor.
gradio: For creating the web interface.transformers: Provides access to the SmolVLM model.torch: Pytorch libraryPIL: Python Imaging Library (used for handling images).
The model and processor are loaded outside the image_captioning function for efficiency. This ensures that the model is loaded only once when the application starts.
We are using the 2.25B parameter SmolVLM model here.
Image Captioning Function
The image_captioning function accepts an image and a prompt as input and returns a caption.
# Load model and processor outside the function for efficiency
processor = AutoProcessor.from_pretrained(model_id)
model = AutoModelForVision2Seq.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
_attn_implementation="flash_attention_2",
).to(DEVICE)
def image_captioning(image_input, prompt):
"""Image Captioning Function."""
messages = [
{
"role": "user",
"content": [
{"type": "image"},
{"type": "text", "text": prompt},
],
},
]
prompt = processor.apply_chat_template(messages, add_generation_prompt=True)
inputs = processor(text=prompt, images=[image_input], return_tensors="pt").to(DEVICE)
prompt_length = inputs['input_ids'].shape[1]
generated_ids = model.generate(
**inputs,
max_new_tokens=200
)
generated_text = processor.decode(
generated_ids[0][prompt_length:],
skip_special_tokens=True
)
return generated_text
Here’s a breakdown:
- Prepare the input: The function accepts the image and prompt as input. It structures the input as a message suitable for the SmolVLM model, using the
AutoProcessor. Theapply_chat_templateadds any necessary formatting tokens for the model. - Process the input: The processor converts the image and prompt into tensors (numerical representations) that the model can understand. The
.to(DEVICE)moves the tensors to the GPU if available (CUDA). - Generate the caption: The
model.generate()method generates the caption.max_new_tokens=200limits the caption length to 200 tokens. - Decode the output: The processor decodes the generated token IDs back into human-readable text.
generated_ids[0][prompt_length:]ensures that only the newly generated tokens (the caption) are decoded, removing the prompt from the output.skip_special_tokens=Trueremoves any special tokens from the final text.
Gradio Interface
This section defines the Gradio interface.
with gr.Blocks() as demo:
gr.Markdown("# SmolVLM Demo")
image_input = gr.Image(label="Input Image")
prompt_image = gr.Textbox(label="Prompt", value="Describe this image.")
caption_output = gr.Textbox(label="Caption Output")
image_button = gr.Button("Run")
image_button.click(
image_captioning,
inputs=[image_input, prompt_image],
outputs=[caption_output],
)
demo.launch(share=True)
This section creates an image upload interface and a prompt text box with a default prompt. We can click the Run after uploading the image and providing the prompt to get the final output from the SmolVLM model.
Running the Application
We can run the application by executing the following command:
python app.py
Here are a few examples.
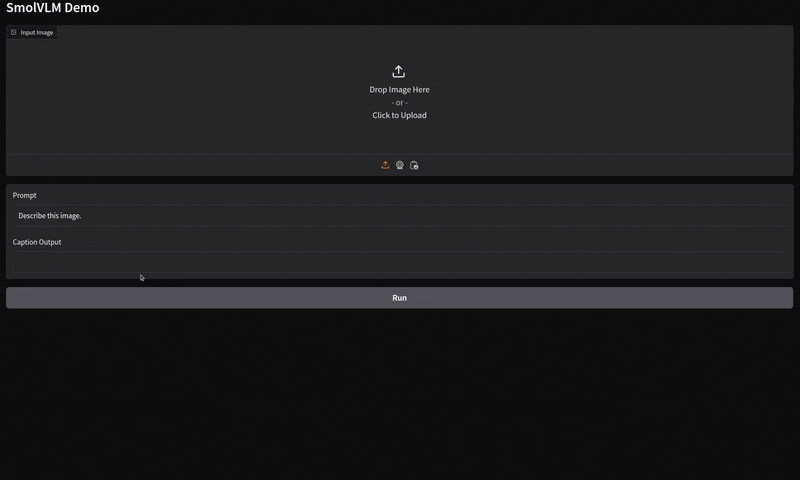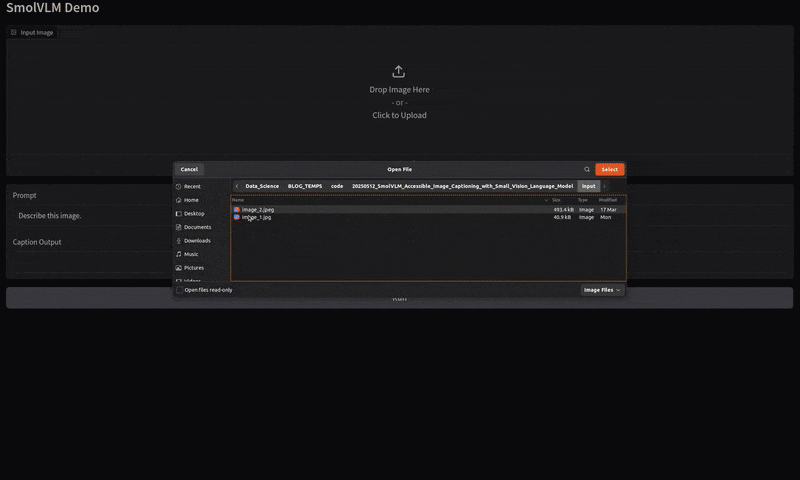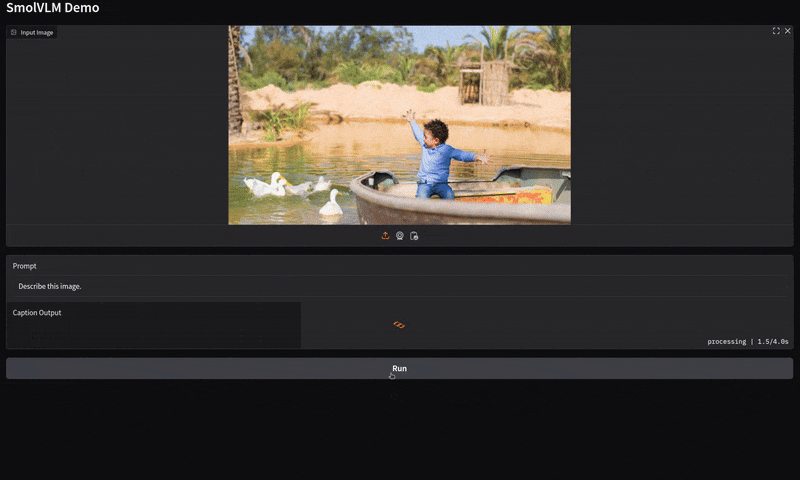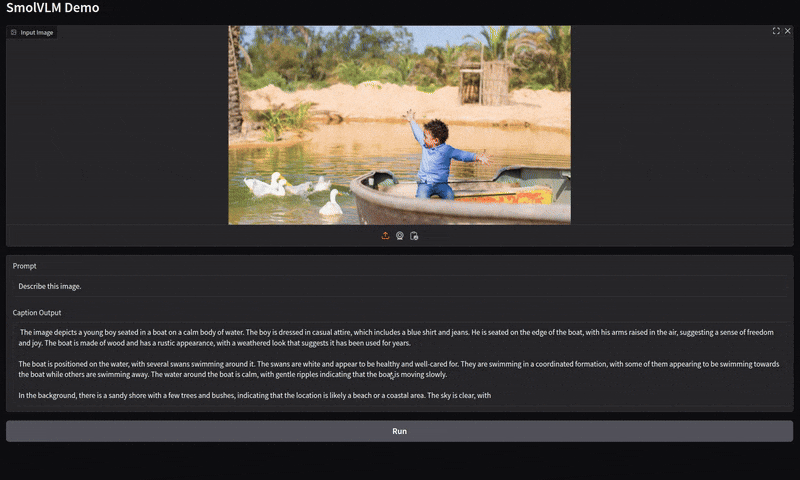
The first one is asking the model to describe an image using the default prompt. It is a simple one.
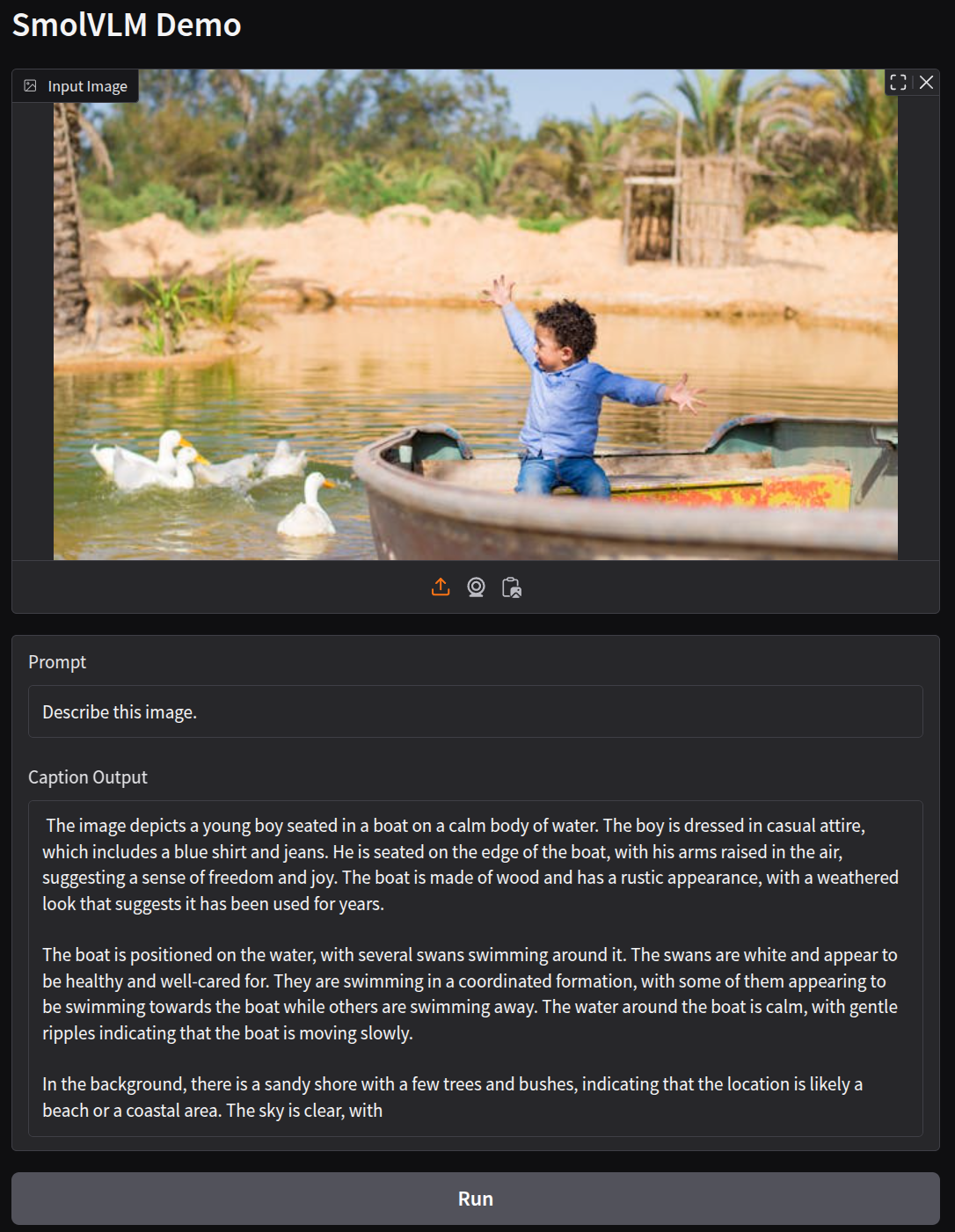
As we can see, the output is quite apt for the image.
Now, let’s try a slightly complex one where we ask the model to carry out OCR on a receipt by changing the prompt.
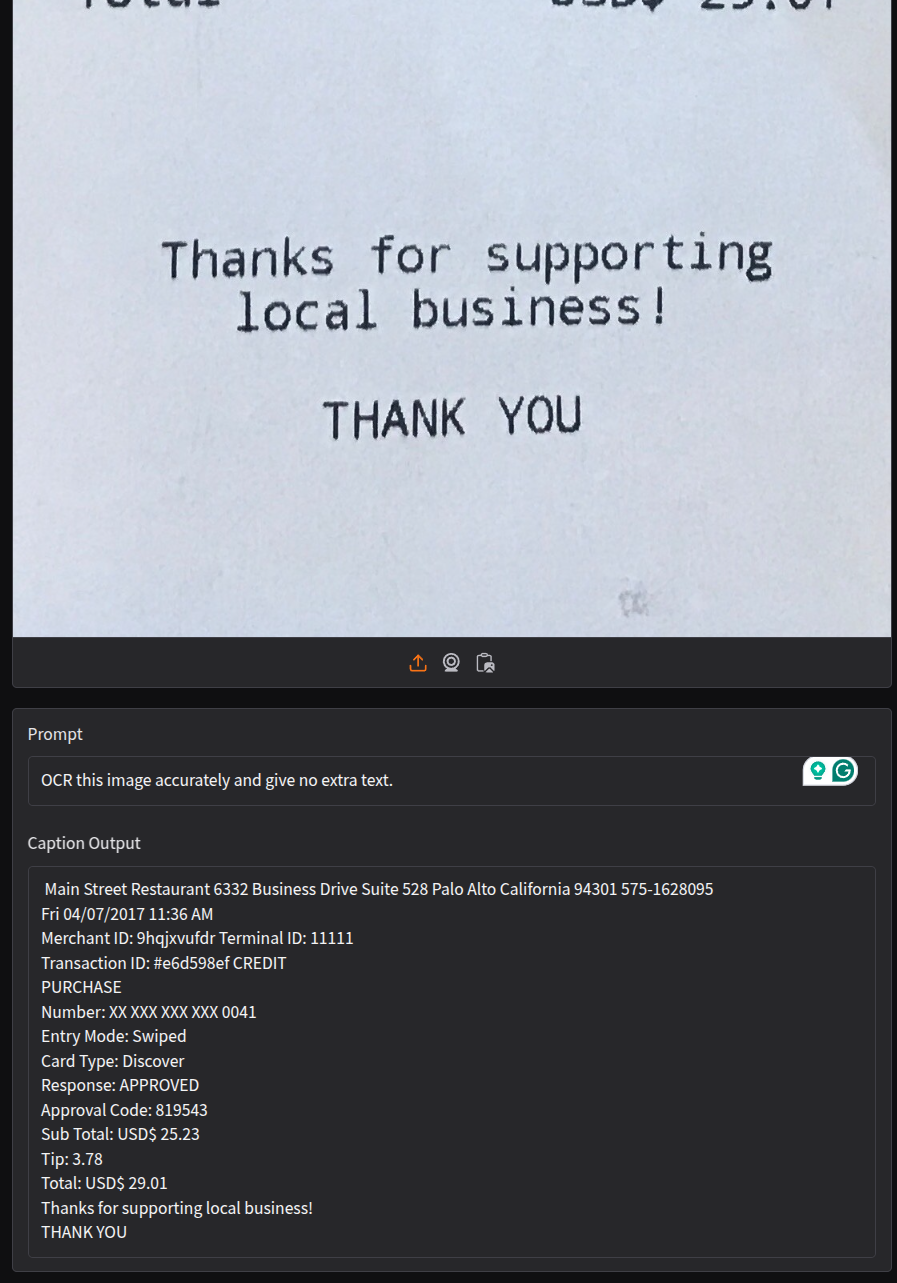
This time also the output is correct. However, we had to prompt the model in a certain way to achieve this. Changing the prompt changes the output format as well and the model starts adding extra context along with the OCR text.
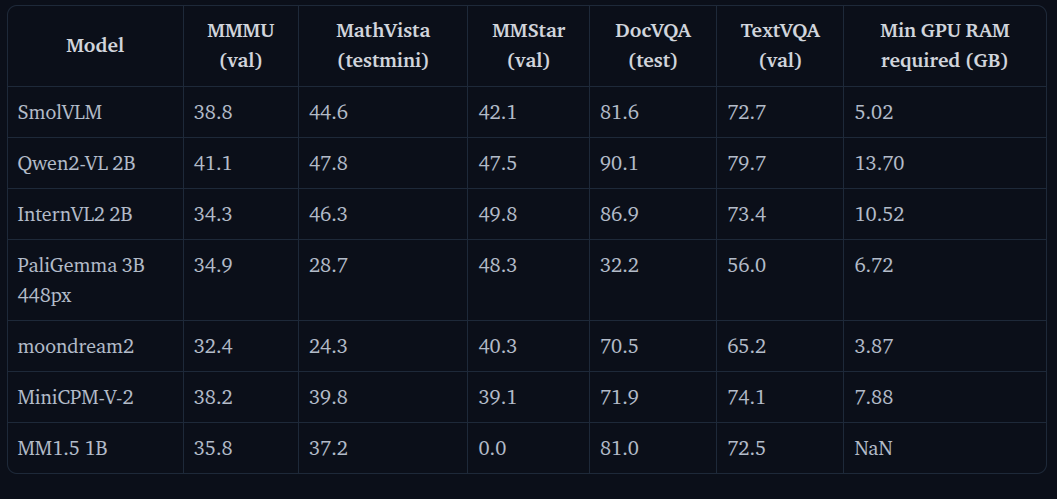
Furthermore, the following is the output with the SmolVLM-256M (256 million parameters) model using the same prompt.
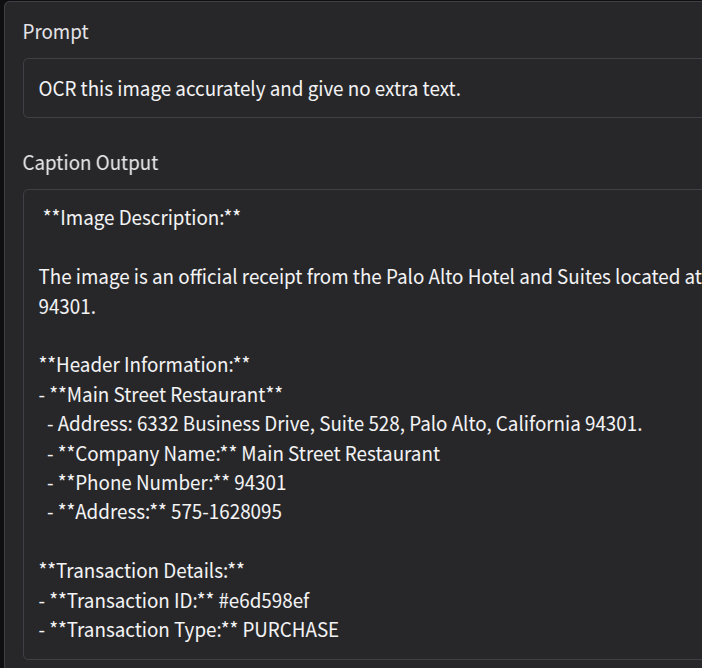
As we can see, it is almost completely failing.
Next Steps
From the above experiments, we found that the SmolVLM models, especially the smaller versions are not good at complex OCR tasks. In our next article, we are going to fine-tune the SmolVLM-256M model for receipt OCR tasks and check how the performance improves.
Summary and Conclusion
In this article, we explore the SmolVLM model. We covered a brief explanation of the model architecture and carried out inference using the SmolVLM-2B parameter model. We also experienced the limitations of the smaller models and discussed our next steps to mitigate this. I hope this article was worth your time.
If you have any questions, thoughts, or suggestions, please leave them in the comment section. I will surely address them.
You can contact me using the Contact section. You can also find me on LinkedIn, and X.
References

2 thoughts on “SmolVLM: Accessible Image Captioning with Small Vision Language Model”