

Vision-Language understanding models are rapidly transforming the landscape of artificial intelligence, empowering machines to interpret and interact with the visual world in nuanced ways. These models are increasingly vital for tasks ranging from image summarization and question answering to generating comprehensive reports from complex visuals. A prominent member of this evolving field is the Qwen2.5-VL, the latest flagship model in the Qwen series, developed by Alibaba Group. With versions available in 3B, 7B, and 72B parameters, Qwen2.5-VL promises significant advancements over its predecessors.

In this article, we’ll explore Qwen2.5-VL, offering a deep dive into its architecture, data curation strategies, and benchmark performance. We’ll also briefly touch upon inference and discuss the improvements over the previous generation Qwen2-VL model.
What We Will Cover:
- Qwen2.5-VL Architecture: An in-depth look at the model’s components, including the LLM, vision encoder, and fusion mechanisms, as well as dynamic FPS sampling. We will also compare it with the architecture of Qwen2 VL to assess the key differences.
- Data Preparation: An overview of the data sources, cleaning strategies, and augmentation techniques used to train Qwen2.5-VL, leading to superior understanding and reasoning.
- Benchmark Performance: A summary of Qwen2.5-VL’s performance on key vision-language benchmarks, comparing it to other state-of-the-art models.
- Qwen2.5 VL Inference: We will carry out inference for image captioning, video description, and object detection using Qwen2.5 VL.
The Qwen2.5-VL Model: Technical Deep Dive
The Qwen2.5-VL model builds upon the foundation laid by the Qwen series. The model has three components:
- Large Language Model
- Vision Encoder
- MLP-based Vision Language Merger
Architecture
Large Language Model (LLM: The LLM backbone of Qwen2.5-VL is initialized with pre-trained weights from Qwen2.5 LLM. The 1D ROPE is replaced with Multimodal Rotary Position Embedding Aligned to Absolute Time.
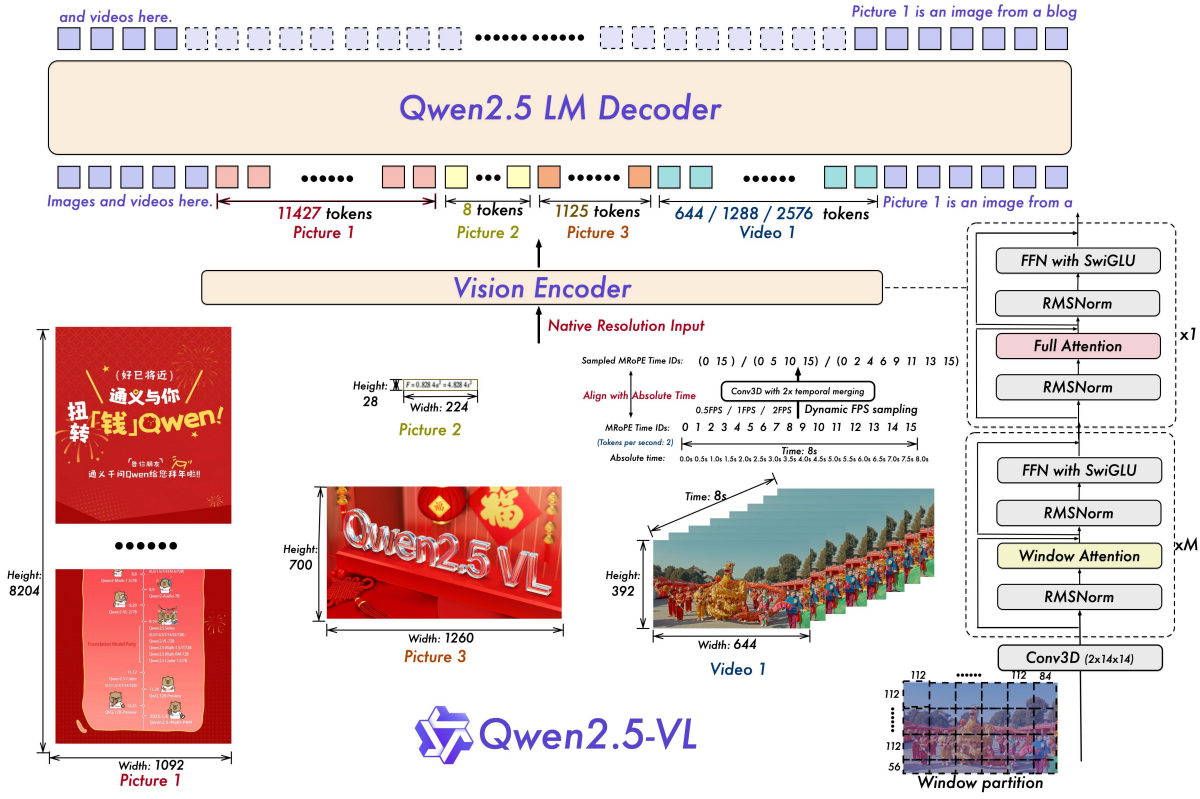
Vision Encoder: The vision encoder in Qwen2.5-VL is a significantly redesigned Vision Transformer (ViT) architecture, incorporating 2D-RoPE and window attention to natively support variable input resolutions and improve computational efficiency. During the training and inference the height and width of the images are resized to multiples of 28, and the image patches are generated with a stride of 14.
MLP-based Vision-Language Merger: Qwen2.5-VL employs a simple yet effective MLP-based vision-language merger to address the efficiency challenges posed by long image feature sequences. This merger compresses the feature sequences before feeding them into the LLM by grouping spatially adjacent sets of patch features, concatenating them, and projecting them into a dimension aligned with the LLM’s text embeddings using a two-layer MLP.
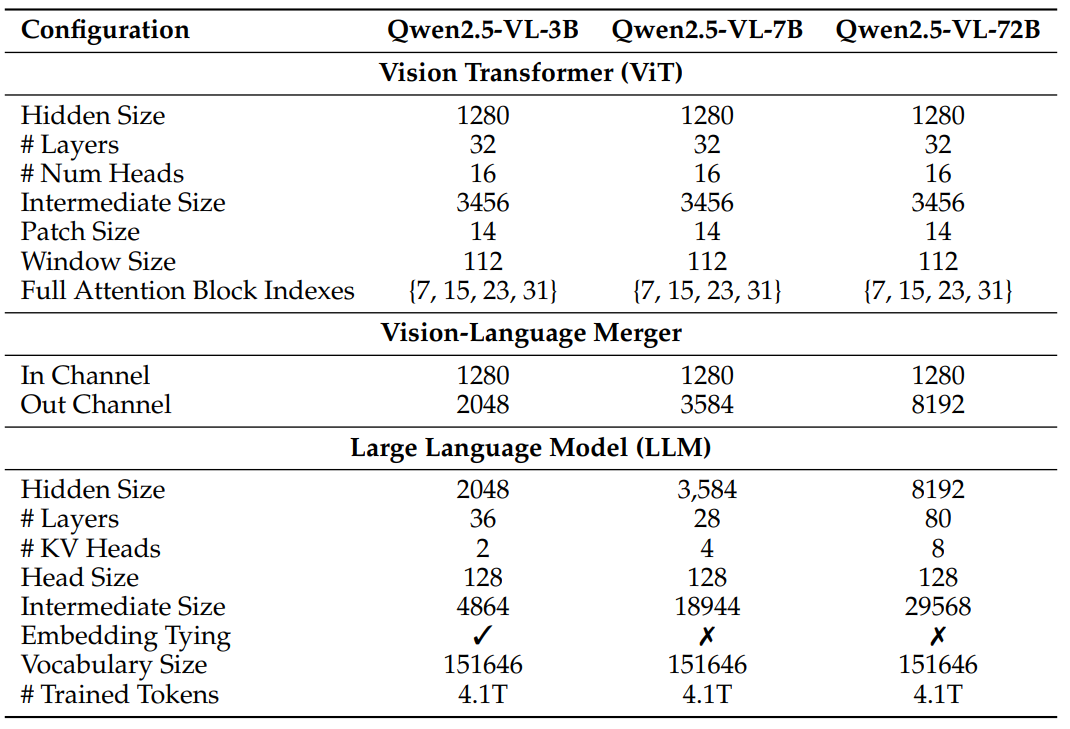
Similar to Qwen2 VL, Qwen2.5 VL also comes in three sizes: 3B, 7B, and 72B, addressing a wide array of uses, from edge AI to high-performance computing. However, the details of their parameters are different. Please refer to the following for details.
Architectural Innovations: Improvements over Qwen2-VL
Qwen2.5-VL introduces several key architectural innovations compared to its predecessor, Qwen2-VL, enhancing its capabilities and efficiency.
Window Attention: A primary enhancement is the implementation of window attention in the visual encoder, optimizing inference efficiency by linearly scaling computational costs with the number of patches rather than quadratically. While Qwen2 VL used full attention, Qwen2.5-VL uses a combination of full attention and window attention, leading to better performance and efficiency.
Dynamic FPS Sampling: Qwen2.5-VL extends dynamic resolution to the temporal dimension with dynamic FPS sampling. This enables comprehensive video understanding across varying sampling rates by aligning MROPE IDs directly with timestamps, thus understanding temporal dynamics without additional computational overhead. The former model lacked dynamic FPS sampling and did not handle videos as efficiently.
Multimodal Rotary Position Embedding (MROPE) Alignment: The multimodal rotary position embedding (MROPE) is also aligned to the absolute time with the help of a novel strategy that allows the model to better comprehend temporal dynamics without additional computational overhead.
These architectural advancements collectively contribute to Qwen2.5-VL’s enhanced performance, efficiency, and versatility in handling diverse multimodal tasks.
Data Preparation
Qwen2.5-VL leverages a meticulously curated and expanded pre-training dataset, growing from 1.2 trillion tokens in Qwen2-VL to approximately 4.1 trillion tokens. This dataset incorporates a diverse range of multimodal data, including:
- Interleaved Image-Text Data: High-quality, relevant interleaved data is ensured through a scoring and cleaning pipeline, improving the model’s reasoning and content generation abilities.
- Grounding Data with Absolute Position Coordinates: Qwen2.5-VL uses coordinate values based on the actual dimensions of the input images during training, allowing the model to capture the real-world scale and spatial relationships of objects, improving performance in tasks such as object detection and localization.
- Document Omni-Parsing Data: A large corpus of document data is synthesized with diverse elements such as tables, charts, equations, images, music sheets, and chemical formulas uniformly formatted in HTML, enabling comprehensive parsing, understanding, and conversion of document formats.
- OCR Data: The OCR performance was enhanced by gathering and curating data from different sources. The model was trained to support languages such as French, German, Italian, Spanish, Portuguese, Arabic, Russian, Japanese, Korean and Vietnamese.
- Video Data: Sampling of FPS was done dynamically during training to enhance robustness. Targeted pipelines were used to generate long-video captions, and timestamps were formulated in second-based and hour-minute-second-frame formats to ensure the model can understand and output time accurately in various formats.
- Agent Data: The model’s perception and decision-making abilities were enhanced by collecting screenshots on mobile, web, and desktop platforms.
The composition and proportions of these data types are carefully adjusted during training to optimize learning outcomes.
Qwen2.5 VL Benchmarks
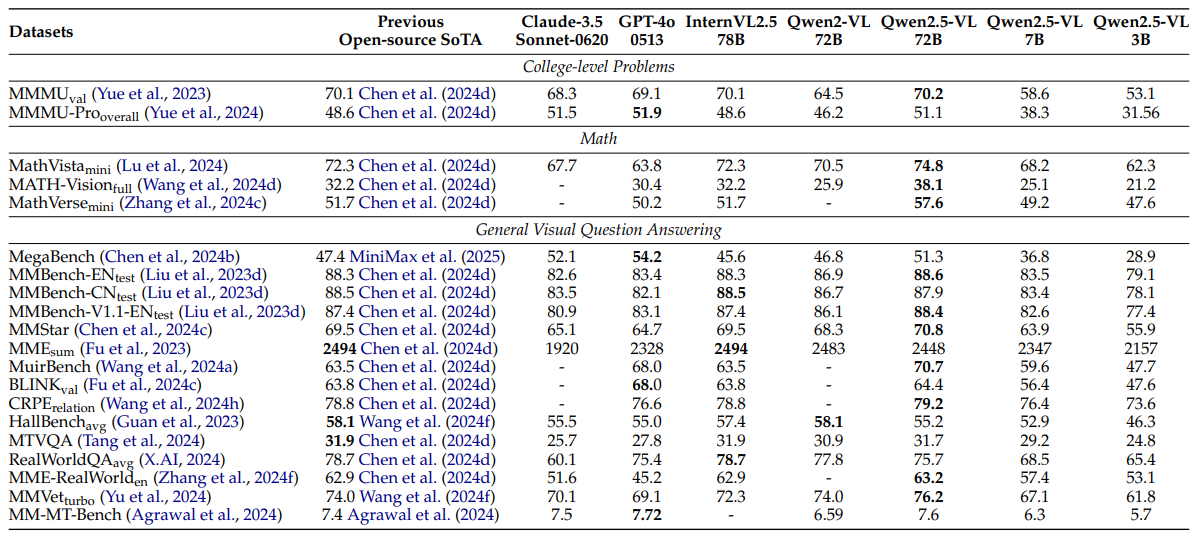
Qwen2.5-VL’s performance is rigorously evaluated against state-of-the-art models on a diverse set of benchmarks, demonstrating its superior capabilities.
Some key highlights include:
- College-Level Problems: Qwen2.5-VL-72B achieves a score of 70.2 on MMMU, surpassing previous open-source models and achieving performance comparable to GPT-4o.
- Math-Related Tasks: Qwen2.5-VL-72B achieves a score of 74.8 on MathVista, outperforming previous open-source models.
- General Visual Question Answering: The 72B excels on various benchmarks, achieving a score of 88.6 on MMBench-EN, slightly surpassing the previous best score.
- OCR-Related Benchmarks: On composite OCR-related understanding benchmarks such as OCRBench, InfoVQA, and SEED-Bench-2-Plus, Qwen2.5-VL-72B achieves remarkable results.
These results underscore Qwen2.5-VL’s robust performance and versatility across a wide range of tasks and datasets.
Directory Structure
Let’s take a look at the directory structure for the inference section.
├── input │ ├── demo.jpeg │ └── video_1.mp4 ├── qwen2_5_3b_awq_image.py ├── qwen2_5_3b_awq_od.py ├── qwen2_5_3b_awq_od_video.py ├── qwen2_5_3b_awq_video.py └── requirements.txt
- The
inputdirectory contains the images and videos that we will use for inference. - There are four Python scripts that we will cover further in the article in their respective subsections.
- The
requirements.txtfile contains all the major requirements for running the code.
All the Python files, inference data and the requirements file are available via the download section.
Download Code
Installing Dependencies
The code requires PyTorch as the base framework that you can install from here.
After that, install the rest of the libraries including the latest version of Transformers using the requirements file.
pip install -r requirements.txt
That’s all we need for the set up.
Qwen2.5-VL – Inference for Image Description, Video Description, and Object Detection
Let’s jump into the coding section and get started with some interesting inference examples of Qwen2.5-VL.
For all the inference examples, we will use the Qwen2.5-VL 3B model quantized with AWQ. The quantized model contains 1.35B parameters.
All the inference experiments shown here were run on an RTX 3080 10GB GPU.
Inference for Image Description using Qwen2.5-VL
We will start with the simplest example – describing an image.
The code for this is present in the qwen2_5_3b_awq_image.py file.
Imports and Defining Argument Parser
Let’s start with importing all the necessary modules and defining the argument parser.
from transformers import (
Qwen2_5_VLForConditionalGeneration, AutoProcessor
)
from qwen_vl_utils import process_vision_info
import argparse
parser = argparse.ArgumentParser()
parser.add_argument(
'--input',
default='input/demo.jpeg',
help='path to the input image(s)'
)
parser.add_argument(
'--prompt',
default='Describe this image.',
help='user prompt on what the model should do with the input'
)
args = parser.parse_args()
We import the classes to load the model and the processor. Along with that, we import the process_vision_info function from the qwen_vl_utils modules. We installed this module from the requirements file and it is provided by the Qwen Team for optimized processing of images.
Loading the Model and the Processor
Next, we load the Qwen2.5-VL 3B Instruct model and it processor.
# Load model.
model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
'Qwen/Qwen2.5-VL-3B-Instruct-AWQ',
torch_dtype='auto',
device_map='auto',
attn_implementation='flash_attention_2' # Comment this if you have GPUs older than Ampere.
)
# Load processor.
processor = AutoProcessor.from_pretrained(
'Qwen/Qwen2.5-VL-3B-Instruct-AWQ',
# min_pixels=256*8*8,
# max_pixels=1280*28*28
)
As the experiments were run on an RTX GPU, we have passed attn_implementation='flash_attention_2'. This leads to faster inference and less GPU VRAM consumption. If you are running on Kaggle or Colab with T4 or P100 GPUs, you need to comment this out as Flash Attention is supported only on GPUs starting from the Ampere architecture.
During the loading of the processor, we have commented out two arguments, min_pixels and max_pixels. Qwen2.5-VL models process images in native resolution. However, this can lead to OOM (Out of Memory) errors when dealing with high resolution images. So, the processor contains the above two arguments where we can control the minimum and maximum number of pixels for resizing. The above commented values are good defaults and should run without issues on an 8GB VRAM GPU.
Define the Message, Apply Chat Template, and Carry Out Forward Pass
Now, we need to define the message list, process the image, and carry out the forward pass.
messages = [
{
'role': 'user',
'content': [
{
'type': 'image',
'image': args.input,
},
{'type': 'text', 'text': args.prompt},
],
}
]
# Preparation for inference.
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors='pt',
)
inputs = inputs.to('cuda')
# Inference: Generation of the output.
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed,
skip_special_tokens=True,
clean_up_tokenization_spaces=False
)
print(output_text)
The messages list contains a content key which in turn is a list containing the type and image keys. The former defines the type of input, which is image in our case, and the latter, the input image path. We can also pass the URL to a downloadable image or a base64 encoded string as well instead of the image path. The second dictionary in the content list contains the user prompt, which is of type text. We by default use the following prompt: “Describe this image”.
Next, we apply the chat template and also pass the messages list through the process_vision_info function. This returns the image inputs and video inputs (whichever data is available) that we pass through the processor. Finally, we do a forward pass through the model and print the decoded string on the terminal.
Let’s execute the code.
python qwen2_5_3b_awq_image.py --input input/image_1.jpg
The description shown below is for the following image.

Here is the output.
['The image depicts a serene tropical beach scene. There are palm trees with lush green leaves and fronds, casting shadows on the sandy beach. The sky is clear with a few scattered clouds, and the ocean is calm with gentle waves approaching the shore. The overall atmosphere is peaceful and idyllic, typical of a tropical paradise.']
The description is quite apt and detailed.
Inference for Video Description using Qwen2.5-VL
We will apply the same process as above for video description now. There will be a few minor changes to the process. The code for this is contained within the qwen2_5_3b_awq_video.py file.
Imports, Loading the Model, and the Processor
The code till loading the model and processor essentially remains the same.
from transformers import (
Qwen2_5_VLForConditionalGeneration, AutoProcessor
)
from qwen_vl_utils import process_vision_info
import argparse
parser = argparse.ArgumentParser()
parser.add_argument(
'--input',
default='input/video_1.mp4',
help='path to the input video'
)
parser.add_argument(
'--prompt',
default='Describe this video.',
help='user prompt on what the model should do with the input'
)
args = parser.parse_args()
# Load model.
model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
'Qwen/Qwen2.5-VL-3B-Instruct-AWQ',
torch_dtype='auto',
device_map='auto',
attn_implementation='flash_attention_2' # Comment this if you have GPUs older than Ampere.
)
# Load processor.
processor = AutoProcessor.from_pretrained(
'Qwen/Qwen2.5-VL-3B-Instruct-AWQ',
# min_pixels=256*8*8,
# max_pixels=1280*28*28
)
In the above code block, the --input command line argument accepts the path to a video.
Creating the Message List and Forward Pass
Let’s create the message list, process the video, and carry out the forward pass through the model.
messages = [
{
'role': 'user',
'content': [
{
'type': 'video',
'video': args.input,
},
{'type': 'text', 'text': args.prompt},
],
}
]
# Preparation for inference.
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs, video_kwargs = process_vision_info(
messages,
return_video_kwargs=True # Additional argument as we are processing videos here.
)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors='pt',
**video_kwargs
)
inputs = inputs.to('cuda')
# Inference: Generation of the output.
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed,
skip_special_tokens=True,
clean_up_tokenization_spaces=False
)
print(output_text)
This time, the content type in the messages list is video instead of an image.
Furthermore, during the processing of the video using the process_vision_info function, we ask the function to return additional video information using return_video_kwargs argument. As Qwen2.5-VL uses dynamic FPS sampling, passing the above argument will extract a certain number of frames per second. Printing the value of video_kwargs gives the following output in our case.
{'fps': [1.9900497512437811]}
So, the model extracts around 2 frames per second from our video.
Let’s execute the code for video inference.
python qwen2_5_3b_awq_video.py
We are using the following video.
And we get the following output.
['A young woman is walking on a road with Table Mountain in the background. She is wearing a white tank top, red pants, and a black backpack. The sun is setting, casting a warm glow over the scene.']
The model describes the video quite succinctly and to the point.
Object Detection using Qwen2.5-VL
Our final experiment involves object detection using Qwen2.5-VL. This is one of the most interesting aspects of the model. It can detect objects in images solely based on textual prompts.
Let’s see how it works. The code is present in the qwen2_5_3b_awq_od.py file.
Importing the Necessary Modules, Defining the Argument Parser, and Loading the Model
The first few lines of code contain the import statements, the argument parser, and the loading of the model & the processor.
from transformers import (
Qwen2_5_VLForConditionalGeneration, AutoProcessor
)
from qwen_vl_utils import process_vision_info
import argparse
import ast
import cv2
parser = argparse.ArgumentParser()
parser.add_argument(
'--input',
default='input/demo.jpeg',
nargs='+',
help='path to the input image(s)'
)
parser.add_argument(
'--prompt',
default='Detect all objects in the image and give the coordinates. The format of output should be like {"bbox_2d": [x1, y1, x2, y2], "label": label',
help='user prompt on what the model should do with the input'
)
args = parser.parse_args()
# Load model.
model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
'Qwen/Qwen2.5-VL-3B-Instruct-AWQ',
torch_dtype='auto',
device_map='auto',
attn_implementation='flash_attention_2' # Comment this if you have GPUs older than Ampere.
)
# Load processor.
processor = AutoProcessor.from_pretrained(
'Qwen/Qwen2.5-VL-3B-Instruct-AWQ',
# min_pixels=256*8*8,
# max_pixels=1280*28*28
)
We have a few more imports here:
cv2: For handling annotations.ast: To convert stringified lists to lists.
We already have a default prompt in the argument parser with the following format:
'Detect all objects in the image and give the coordinates. The format
of output should be like {"bbox_2d": [x1, y1, x2, y2], "label": label'
Formatting the prompt like the above always directs the model to output the bounding boxes in [xmin, ymin, xmax, ymax] format and the label in a JSON format. However, the output is always going to be a string. We will later see how to handle that.
Creating the Message List and Carrying Out Forward Pass
As we are essentially dealing with an image here, the messages list does not change. The forward pass process also remains the same.
messages = [
{
'role': 'user',
'content': [
{
'type': 'image',
'image': args.input,
},
{'type': 'text', 'text': args.prompt},
],
}
]
# Preparation for inference.
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors='pt',
)
inputs = inputs.to('cuda')
# Inference: Generation of the output.
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed,
skip_special_tokens=True,
clean_up_tokenization_spaces=False
)
print(f"Raw output at index 0:\n {output_text[0]}")
string_list = output_text[0][8:-3:]
print(f"Raw output after removing JSON strings:\n {string_list}")
final_output = ast.literal_eval(string_list)
print(final_output)
print(f"Box info after converting to list: {final_output[0]['bbox_2d']}")
print(f"Box info after converting to list: {final_output[1]['bbox_2d']}")
We have quite a few print statements for understanding the output format here. As the JSON output is within a list, so we print the 0-index element of the output. The following block shows the output that gets printed in the terminal.
Raw output at index 0:
```json
[
{"bbox_2d": [456, 587, 1183, 1214], "label": "dog"},
{"bbox_2d": [920, 525, 1490, 1088], "label": "person"}
]
```
Raw output after removing JSON strings:
[
{"bbox_2d": [456, 587, 1183, 1214], "label": "dog"},
{"bbox_2d": [920, 525, 1490, 1088], "label": "person"}
]
[{'bbox_2d': [456, 587, 1183, 1214], 'label': 'dog'}, {'bbox_2d': [920, 525, 1490, 1088], 'label': 'person'}]
Box info after converting to list: [456, 587, 1183, 1214]
Box info after converting to list: [920, 525, 1490, 1088]
The issue with the above JSON output is that it is a string entirely. So, we remove the first 7 elements which include the string ```json and the last three elements, which include the last three back ticks. This gives us a stringified list that we convert to a list using ast.literal_eval. This lets us easily access the values within it.
Helper Function for Object Detection Annotation
The final code block contains a small helper function for annotating the detected objects with the bounding boxes and the labels. Then we visualize the output on screen.
def annotate_image(image, output):
for i, output in enumerate(final_output):
cv2.rectangle(
image,
pt1=(output['bbox_2d'][0], output['bbox_2d'][1]),
pt2=(output['bbox_2d'][2], output['bbox_2d'][3]),
color=(0, 0, 255),
thickness=2,
lineType=cv2.LINE_AA
)
cv2.putText(
image,
text=output['label'],
org=(output['bbox_2d'][0], output['bbox_2d'][1]-5),
fontFace=cv2.FONT_HERSHEY_SIMPLEX,
fontScale=2,
color=(0, 0, 255),
thickness=2,
lineType=cv2.LINE_AA
)
return image
image = cv2.imread(args.input)
image = annotate_image(image, final_output)
cv2.imshow('Image', image)
cv2.waitKey(0)
We can execute the code with the default prompt with the following command.
python qwen2_5_3b_awq_od.py
This gives us the following output.

We can see that the bounding boxes are quite accurate and the labels are also correct. This shows how much further we have come in vision language models since their inception.
Summary and Conclusion
In this article, we covered the Qwen2.5-VL model. We started with a brief discussion about its architecture and benchmarks. Then we moved on to hands-on coding and carried out inference for image & video description, and object detection in images. There are many advanced use cases that we can carry out which we may cover in future articles. I hope this article proves a good starting point for you.
If you have any questions, thoughts, or suggestions, please leave them in the comment section. I will surely address them.
You can contact me using the Contact section. You can also find me on LinkedIn, and Twitter.
References

1 thought on “Qwen2.5-VL: Architecture, Benchmarks and Inference”