

Multimodal models like Gemini can interact with several modalities, such as text, image, video, and audio. However, it is closed source, so we cannot play around with local inference. Qwen2.5-Omni solves this problem. It is an open source, Apache 2.0 licensed multimodal model that can accept text, audio, video, and image as inputs. Additionally, along with text, it can also produce audio outputs. In this article, we are going to briefly introduce Qwen2.5-Omni while carrying out a simple inference experiment.
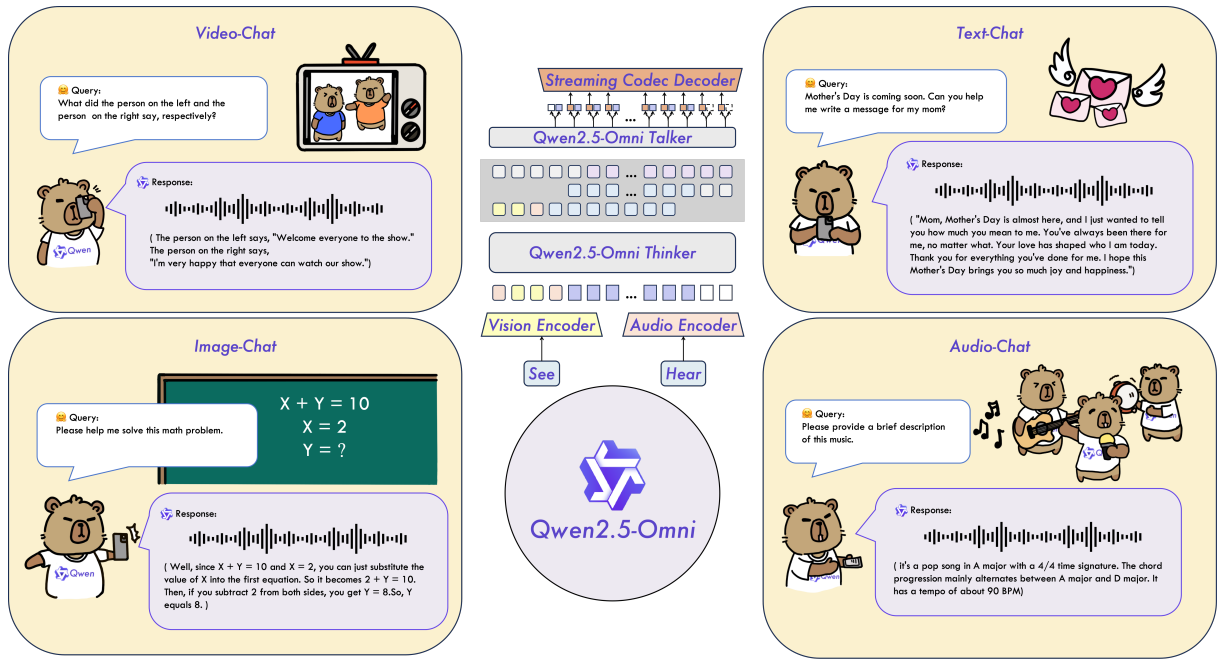
Qwen2.5-Omni was introduced by the QwenLM team in an official technical report. It is a unified model that can process all modalities simultaneously while generating text and natural speech as output. We will specifically cover the architecture of the Qwen2.5-Omni model and discuss what it takes to build such a model in the 7B parameter scale.
We will cover the following topics while discussing Qwen2.5-Omni
- What is the architecture of Qwen2.5-Omni 7B?
- What different components are necessary to build such a multimodal model?
- How to carry inference using Hugging Face Transformers with Qwen2.5-Omni 7B?
The Qwen2.5-Omni 7B Architecture
The Qwen2.5-Omni model consists of the following components:
- A text encoder to process input text.
- A vision encoder from Qwen2.5 VL to process images and video frames.
- Audio encoder from Qwen2-Audio for processing audio.
- A text decoder (Thinker model) for outputting text.
- A causal audio decoder (Talker model) for real-time speech streaming.
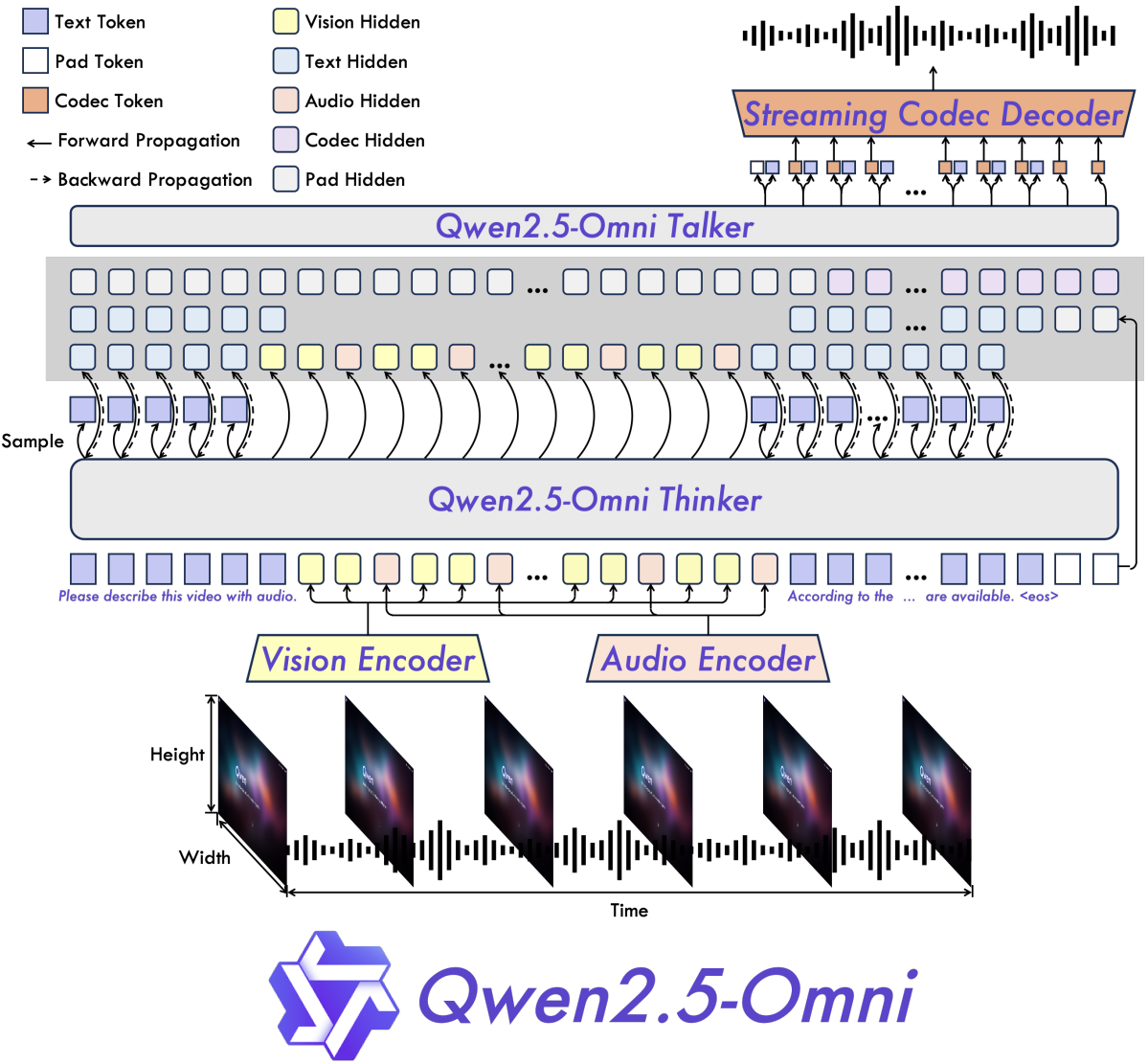
Encoding Text, Audio, Image, and Video
The Thinker is used to process text, image, and video inputs. The thinker does not process the audio inputs.
For encoding text, the model uses the Qwen tokenizer. The image and video input processing is done by the Qwen2.5-VL encoder. To process audio tracks and audio from videos, the model uses the audio encoder from Qwen2-Audio model. The authors resample all the audio to a frequency of 16 kHz while transforming the raw waveform into a 128-channel mel-spectrogram.
Encoding Video and Video + Audio with TMRoPE
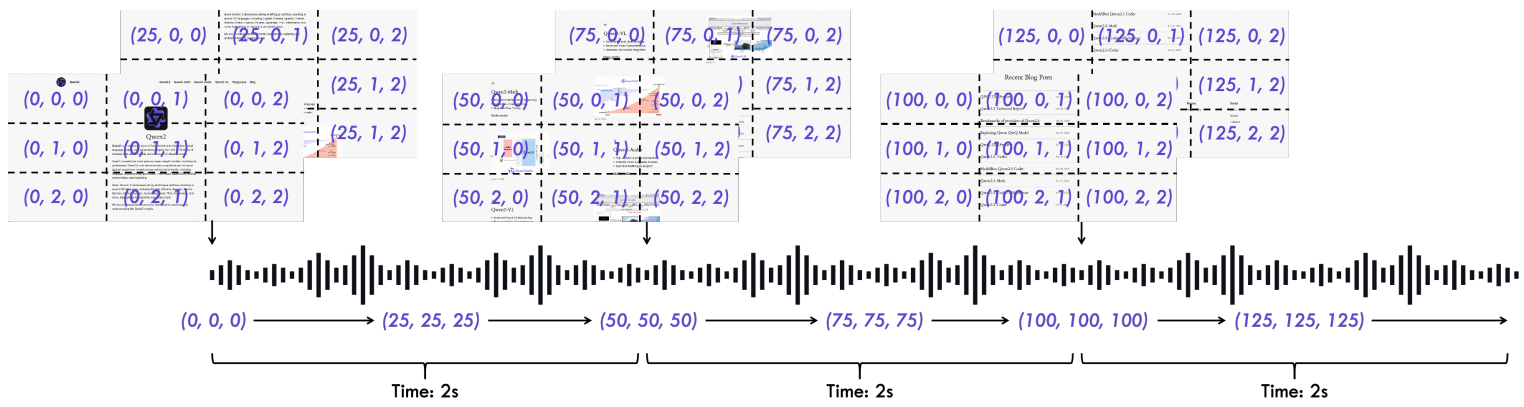
TMRoPE (Time-Aligned Multimodal RoPE) is a time-interleaving algorithm for processing audio and video. This uses a novel positional encoding for multimodal inputs.
The time-interleaving method segments video with audio into 2-second chunks, as shown in the above figure. The audio for such scenarios is encoded with identical position IDs for every 40ms per frame. As for the video frames, the algorithm treats them as a series of images with temporal ID increments for each frame.
Generating Text and Speech
The Thinker generates text. It uses a similar autoregressive approach to other LLMs.
However, speech is generated by the Talker. For this, the Talker receives the embeddings of text tokens and the high-level representations from the Thinker. The high-level information is necessary to incorporate and adhere to the tone and attitude of the situation while streaming the audio.
The Talker essentially uses a TTS (Text-to-Speech) architecture. For Qwen2.5-Omni, the authors create an efficient speech codec, qwen-tts-tokenizer. It represents the key information from the audio tokens, and they are then decoded to speech in a streaming manner using a causal audio decoder.
There are other details in the technical report that lay out the information for prefilling during inference, streaming code generation, and using Flow-Matching to transform input code into mel-spectrogram. I highly recommend going through the paper to understand these in detail.
Qwen2.5-Omni 7B Benchmarks
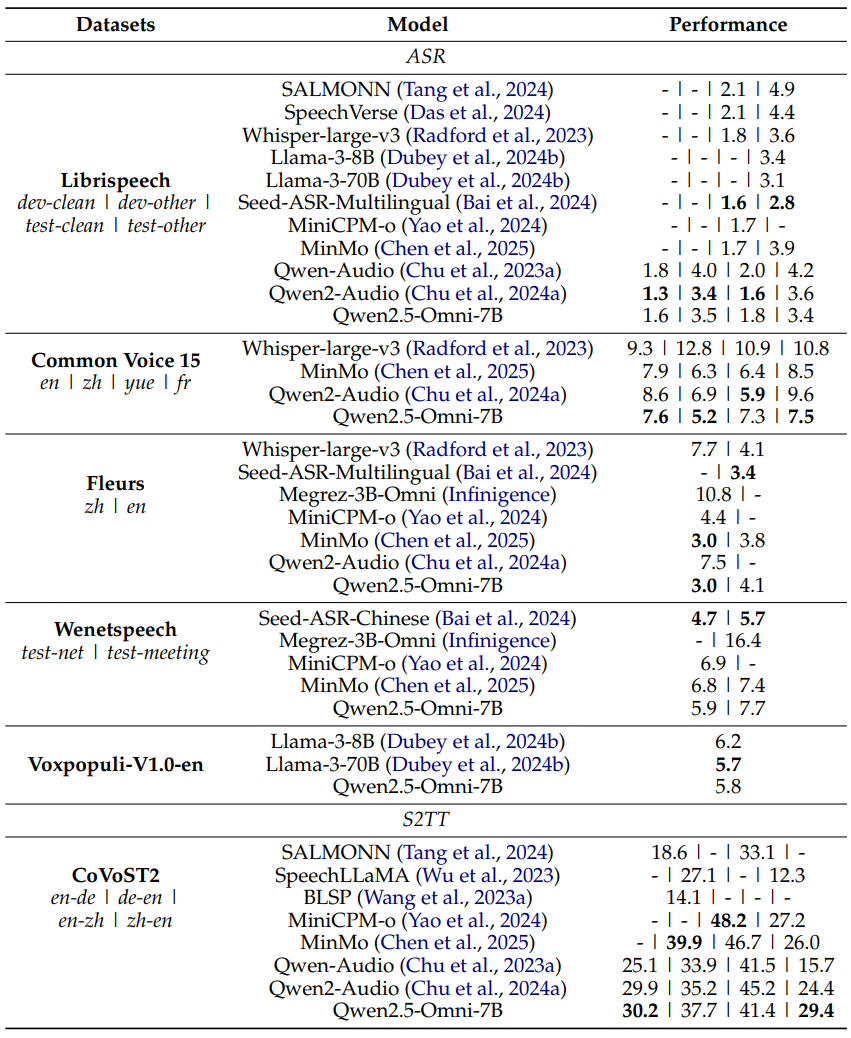
While Qwen2.5-Omni is not the best model out there in the 7B parameter range for text generation, it is one of the best multimodal models, incorporating almost all the modalities. The following are the benchmark results for text-to-text.
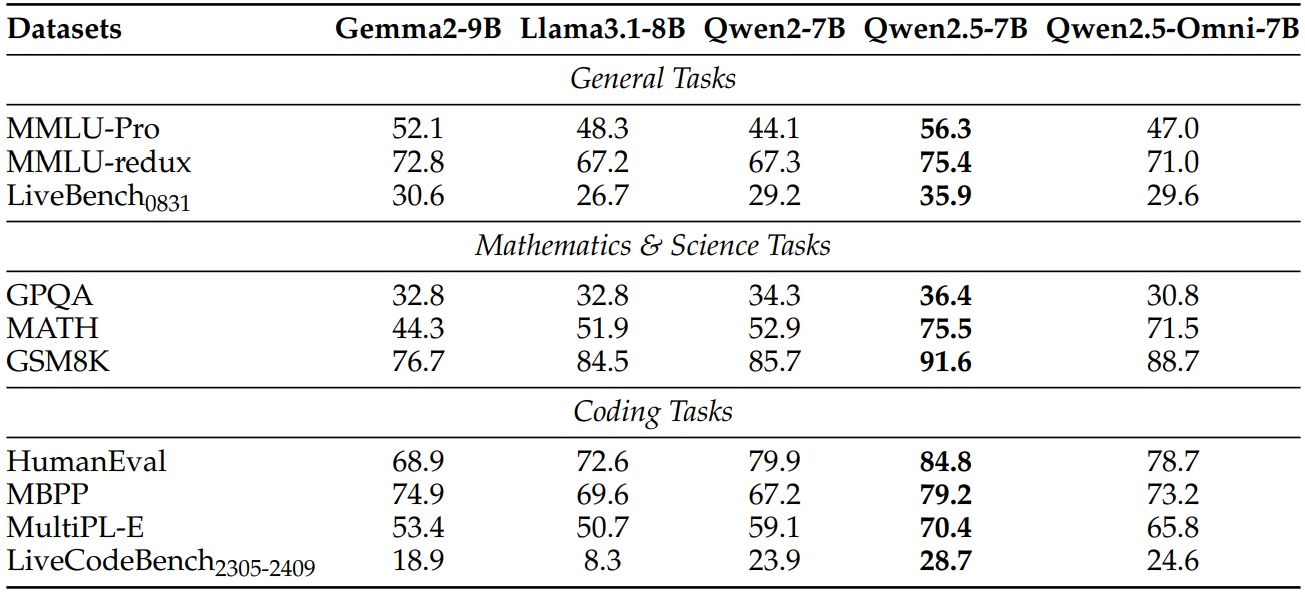
The performance falls between Qwen2-7B and Qwen2.5-7B. It may be because of interleaving all the modalities. Dealing with four modalities is certainly more difficult than training just a text-to-text model.
For audio-to-text, Qwen2.5-Omni has mixed results. However, it is important to remember that we are comparing it with other models that carry out TTS only.
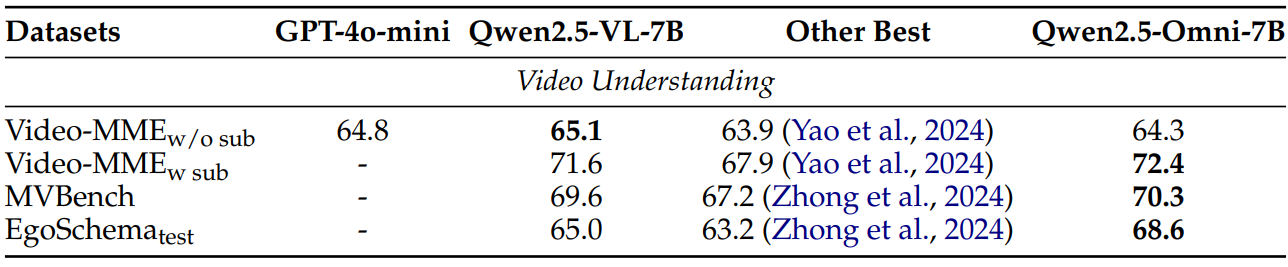
In image-to-text, the model stands out. It outperforms GPT-4o-Mini in almost all cases.

In video understanding, the Qwen2.5-Omni model falls behind Qwen2.5-VL-7B in just one benchmark.
The authors also benchmark the model on OmniBench, which is a multimodality-to-text dataset.

As we can see, it beats much larger models like Gemini-1.5-Pro and other models in the same parameter scale.
This brings us to the end of the technical report discussion. I recommend going through the report once on your own as well to get more detailed insights. We will jump into the inference part next.
Directory Structure
Let’s check out the directory structure of the inference files that we are maintaining here.
├── input │ ├── bird-1.wav │ ├── video_1.mp4 │ └── video_1_trimmed.mp4 └── qwen2_5_omni.py
- We have an
inputdirectory that contains all the files that we will use for inference. These include a video and an audio file. - The
qwen2_5_omni.pyPython file contains the code for Qwen2.5-Omni inference.
All the inference data and the Python script are available to download via the download section.
Download Code
Installing Dependencies
Running Qwen2.5-Omni 7B at the time of the writing requires a specific version of Transformers that is not merged with the main branch at the moment.
First, uninstall the current version of Transformers that you have.
pip uninstall transformers
Install the version of Transformers that supports Qwen2.5-Omni.
pip install git+https://github.com/BakerBunker/transformers@21dbefaa54e5bf180464696aa70af0bfc7a61d53
Install Accelerate.
pip install accelerate
Finally, install Qwen Omni utilities for faster video loading.
pip install qwen-omni-utils[decord] -U
Inference using Qwen2.5-Omni 7B
Let’s jump into the inference code of Qwen2.5-Omni 7B.
All the code is available in a single Python script, qwen2_5_omni.py.
The inference was run on a system with 10GB RTX 3080 GPU, 32GB RAM, and i7 10th generation CPU.
The following block contains the inference code.
from transformers import Qwen2_5OmniForConditionalGeneration, Qwen2_5OmniProcessor
from qwen_omni_utils import process_mm_info
import soundfile as sf
model = Qwen2_5OmniForConditionalGeneration.from_pretrained(
"Qwen/Qwen2.5-Omni-7B",
torch_dtype="auto",
device_map="auto",
attn_implementation="flash_attention_2",
)
processor = Qwen2_5OmniProcessor.from_pretrained("Qwen/Qwen2.5-Omni-7B")
conversation = [
{
"role": "system",
"content": "You are Qwen, a virtual human developed by the Qwen Team, Alibaba Group, capable of perceiving auditory and visual inputs, as well as generating text and speech.",
},
{
"role": "user",
"content": [
{"type": "video", "video": "input/video_1_trimmed.mp4"},
{"type": "audio", "audio": "input/bird-1.wav"},
{"type": "text", "text": "Hi. What are the above elements?"},
]
}
]
# set use audio in video
USE_AUDIO_IN_VIDEO = False
# Preparation for inference
text = processor.apply_chat_template(
conversation,
add_generation_prompt=True,
tokenize=False
)
audios, images, videos = process_mm_info(
conversation, use_audio_in_video=USE_AUDIO_IN_VIDEO
)
inputs = processor(
text=text,
audio=audios,
images=None,
videos=videos,
return_tensors="pt",
padding=True,
use_audio_in_video=USE_AUDIO_IN_VIDEO
)
inputs = inputs.to(model.device).to(model.dtype)
# Inference: Generation of the output text and audio
text_ids = model.generate(
**inputs,
return_audio=False,
use_audio_in_video=USE_AUDIO_IN_VIDEO
)
# Trim the generated ids to remove the input ids
trimmed_generated_ids = [
out_ids[len(in_ids):] for in_ids, out_ids in zip(inputs.input_ids, text_ids)
]
text = processor.batch_decode(
text_ids,
skip_special_tokens=True,
clean_up_tokenization_spaces=False
)
print(text)
# sf.write(
# "output.wav",
# audio.reshape(-1).detach().cpu().numpy(),
# samplerate=24000,
# )
- We start with importing the necessary libraries and classes.
- Next, we load the Qwen2.5-Omni model with Flash Attention 2. This is necessary to run the model within 10GB of VRAM. Else, ~12GB of VRAM is necessary when using eager attention.
- We create a
conversationlist that contains system prompt and paths to an audio and a video file. In the end, we ask the model to summarize all the content that we have passed to it. - We define
USE_AUDIO_IN_VIDEOand set it toFalseto let the model know to not use audio in the video and focus only on the frames. - Next, we apply the chat template, process the conversation, and get the processed audio, images, and video, if present.
- In the next step, we pass these through the
processor, to get the input IDs. - Finally, we call the
generatemethod of the model and decode the tokens.
Executing the Qwen2.5-Omni 7B Inference Script
Let’s execute the script and check the output.
python qwen2_5_omni.py
Following is the output that we get.
["Well, the above elements are a person standing on a rocky cliff overlooking a vast ocean. The sky is clear and blue, and there are some birds chirping in the background. It's a really peaceful and beautiful scene. What do you think about it?"]
The model captured the combined essence of all the files quite well. It was able to understand the video we are dealing with and combine that with the bird sounds from the audio file.
I recommend playing around with the model more and getting hands-on with different types of images, videos, and audio files.
Summary and Conclusion
In this article, we covered the Qwen2.5-Omni model briefly. We started with a short discussion of the architecture, the tokenizer, and the novel positional embedding technique. Then, we carried out a small inference experiment. I hope that this article was worth your time.
If you have any questions, thoughts, or suggestions, please leave them in the comment section. I will surely address them.
You can contact me using the Contact section. You can also find me on LinkedIn, and Twitter.
References
