

The Llama 3 (and 3.1) family of models, introduced in The Llama 3 Herd of Models technical report by Meta AI engineers, are some of the top-performing and largest open-weight models at the moment. Ranging from 8B to 405B parameters, Llama 3 models offer something for every use case and scale. The released technical paper details topics covering the overall architecture of Llama 3, pretraining, and fine-tuning tactics & datasets among many others. In this article, we will cover the most important components of the Llama 3 technical report concisely.

What are we going to cover in the Llama 3 technical report overview?
- The overall architecture of Llama 3.
- Pretraining and fine-tuning dataset and strategy.
- Infrastructure and compute used.
- Balancing helpfulness and safety.
- Its multimodal capabilities.
Long Form tl;dr of Llama 3
Quick Facts
- Developed by: Meta’s AI team
- Largest model: 405 billion parameters
- Context window: Up to 128,000 tokens
- Training data: Over 15 trillion multilingual tokens
What’s New?
- Llama 3 is multilingual
- Advanced coding skills
- Improved reasoning abilities
- Better tool usage
The Llama 3 Family
- Model sizes: 8B, 70B, and 405B parameters
- Each size offers different capabilities for various needs and budgets
Performance
- Rivals top models like GPT-4 in benchmark tests
- Balances helpfulness with safety to minimize harmful content
Training Data
- 50% general knowledge
- 25% math and reasoning
- 17% coding
- 8% multilingual content
Architecture Highlights
- Based on dense Transformer model
- Uses Grouped Query Attention (GQA) for faster inference
- 128,000-token vocabulary for better language support
Training Infrastructure
- Used Meta’s Grand Teton AI servers with H100 GPUs
- Employed 4D parallelism for efficient training across 16,000 GPUs
- Leveraged Tectonic distributed file system for massive data handling
Fine-Tuning Process
- Supervised Fine-Tuning (SFT) with human-annotated prompts
- Direct Preference Optimization (DPO) for aligning with human preferences
Multimodal Capabilities
- Can process text, images, video, and audio
- Uses separate encoders for each modality
- Enables tasks like image captioning, video summarization, and speech recognition
Real-World Applications
- Education: Interactive, multi-media learning experiences
- Healthcare: Analyzing medical images alongside patient records
- Entertainment: Smart content creation and voice-controlled interactions
Llama 3: Meta’s Best Open-Weight Dense Language Models
Meta’s AI team recently released their next generation of dense Transformer models (LLMs), Llama 3. These models are designed to excel at tasks that require understanding multiple languages, writing code, solving complex problems, and using various tools. What sets Llama 3 apart is its impressive scale – the largest model boasts a whopping 405 billion parameters. To cater to all types of tasks and inference load, we also have Llama-8B and Llama-70B from Meta.
One of Llama 3’s standout features is its ability to handle really long pieces of text – up to 128,000 tokens, which is roughly equivalent to a small book. This means it can understand just as well as the best close-source AI models out there.
The Llama Family Tree

Llama 3 builds on the success of its older siblings, Llama 1 and Llama 2. After several iterations for updates in training data, model architecture, pre-training, and post-training strategy, Meta released Llama 3.
The Llama 3 family comes in different sizes to suit various needs:
- 8 billion parameter model: For simple everyday tasks like chatting, writing an email, or helping you prep your meal.
- 70 billion parameter model: For slightly advanced tasks like logical reasoning, curating ideas for your next article, or even helping you with your homework
- 405 billion parameter model: For complex reasoning, coding, and mathematical questions.
Each size has its own strengths, allowing users to choose the right model for their specific needs and budget.
How Does Llama 3 Stack Up?
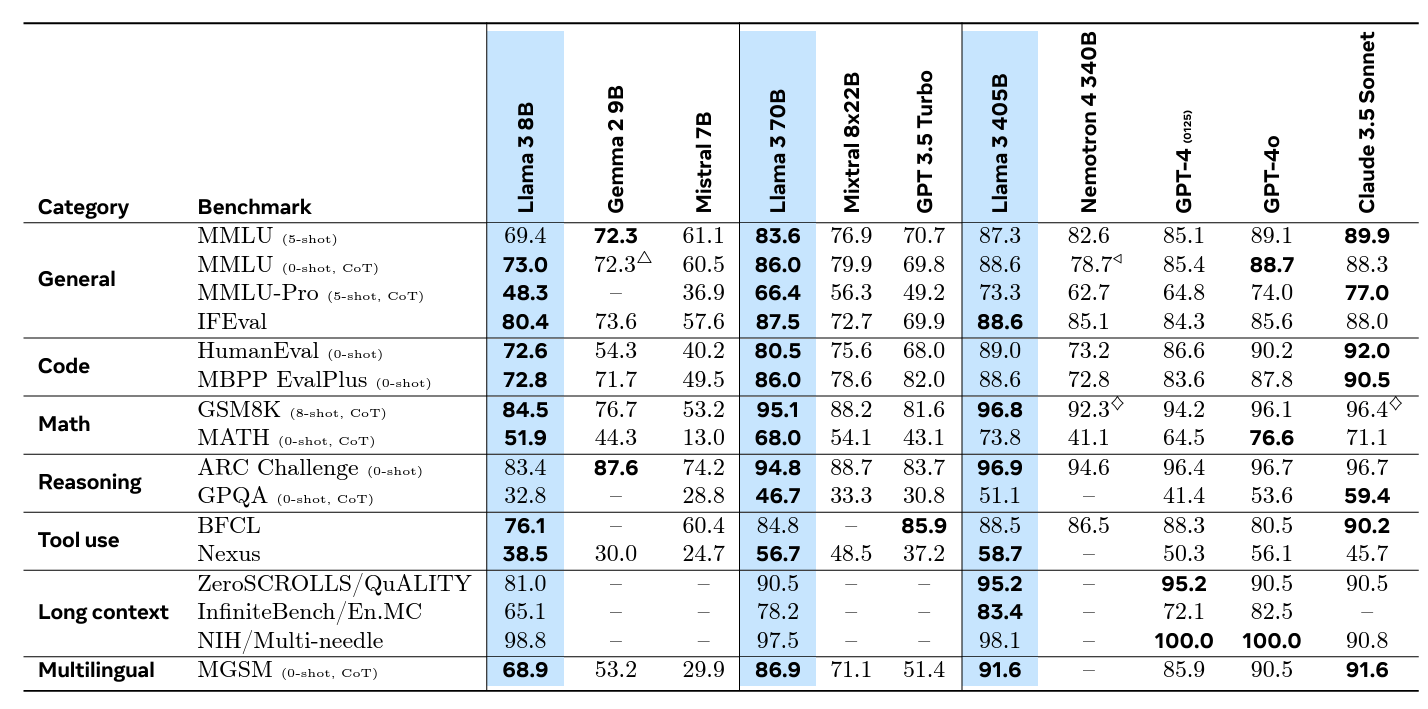
When it comes to performance, Llama 3 is comparable with other top-tier closed AI models like GPT-4 on various benchmark tests. What’s particularly impressive is how the Llama 3 team has managed to strike a balance between being super helpful and avoiding potentially harmful or biased content. They’ve achieved this by carefully selecting the data used to train the model and employing advanced techniques to ensure the AI behaves in line with human values.
Training Data
The Llama 3 models have been fed a massive amount of text – over 15 trillion words in multiple languages. This data consists of everything that we may need an LLM of this scale to deal with.
The team at Meta AI spent enormous effort and time to curate this huge dataset to include:
- 50% general knowledge: A bit of everything to give the AI a well-rounded education
- 25% math and reasoning data: To sharpen its problem-solving skills
- 17% coding information: Teaching the AI to speak the language of computers
- 8% content in various languages: Helping Llama 3 become multilingual
The team also went to great lengths to ensure the quality of this data. They removed duplicate content, filtered out inappropriate material, and made sure to protect people’s privacy by excluding personal information.
Llama 3’s Architecture

Llama 3 is built on an enhanced version of the Transformer architecture. The largest model in the series, with 405 billion parameters, consists of 126 layers of neural networks, 16,384 dimensions, and 128 attention heads.
One notable point in Llama 3 is Grouped Query Attention (GQA), which helps the model handle information more quickly and efficiently, particularly when generating longer pieces of text during inference.
Additionally, Llama 3 has a significantly expanded vocabulary of 128,000 words and symbols, with 28,000 new tokens specifically added for non-English languages. This broader vocabulary allows the model to better understand and generate text across a wide range of languages.
Compute Infrastructure
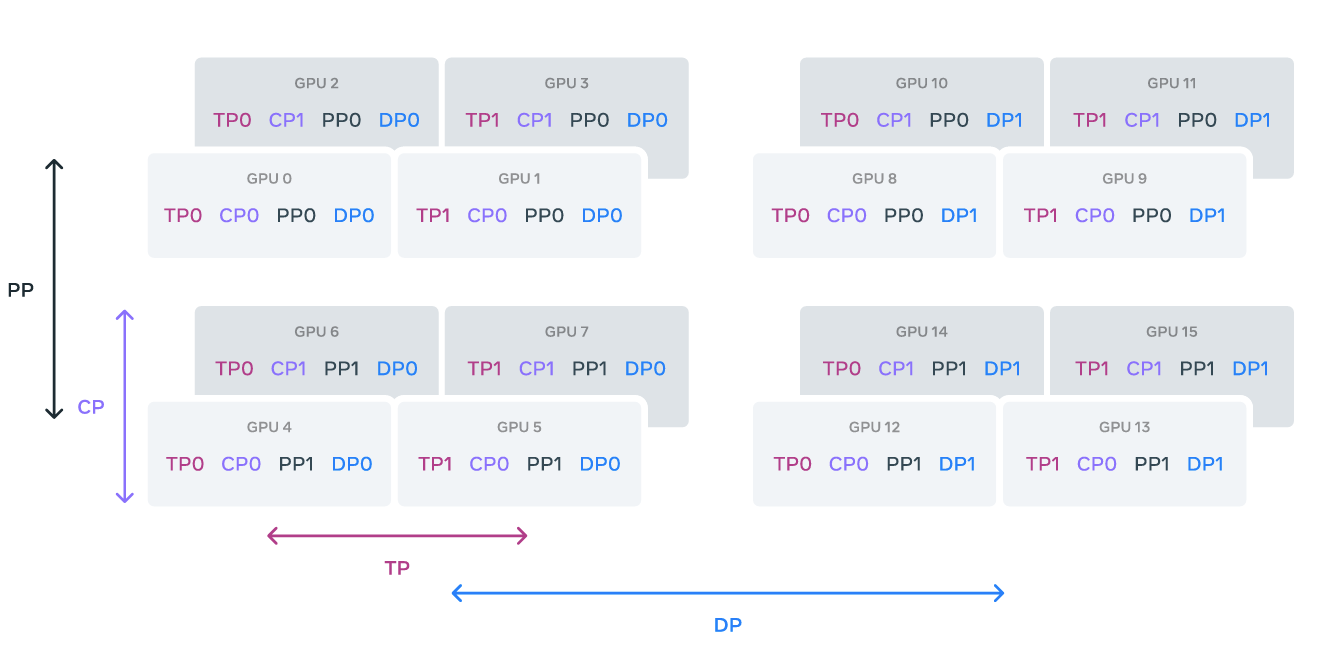
To efficiently train a model as large as Llama 3, Meta used 4D parallelism, which combines four different types of parallelism: tensor, pipeline, context, and data parallelism.
- Tensor parallelism splits the model’s weights into smaller chunks across different devices.
- Pipeline parallelism breaks the model into stages so that different layers can be processed in parallel.
- Context parallelism divides long input sequences into manageable segments to reduce memory load.
- Data parallelism processes data in parallel across multiple GPUs, synchronizing the results after each training step.
This combination allows the training workload to be split efficiently across thousands of GPUs, preventing memory bottlenecks and ensuring that each GPU can handle its part of the task. It also addresses issues like imbalances in memory and computation, making training more efficient at scale.
Teaching Llama 3 to Be Helpful and Safe
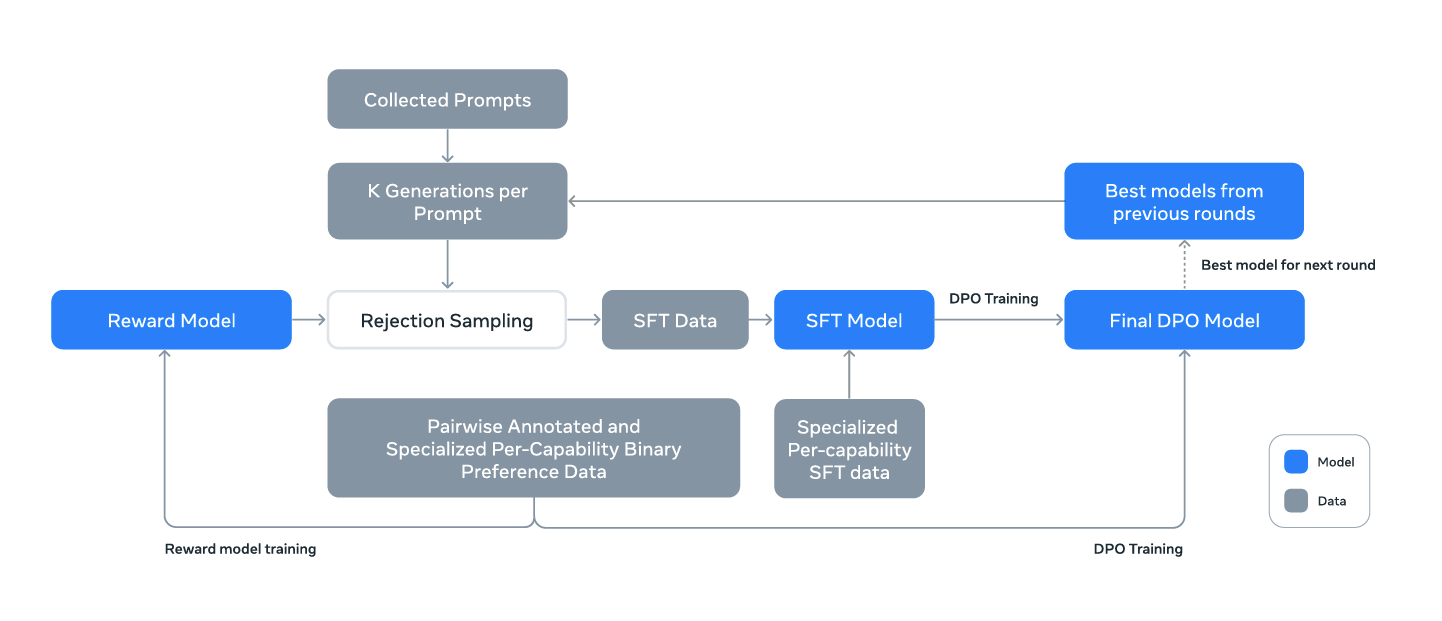
After the initial training, Llama 3 went through two important fine-tuning steps:
- Supervised Fine-Tuning (SFT): SFT of LLMs helps in personalizing the model according to the needs, using carefully selected examples to teach it how to follow instructions and generate high-quality responses.
- Direct Preference Optimization (DPO): Training language models with DPO align the model’s behavior with human preferences.
These steps help ensure that Llama 3 not only performs well but also behaves in a way that’s helpful and safe for users.
Llama 3 Multimodality: Understanding Images, Video, and Audio
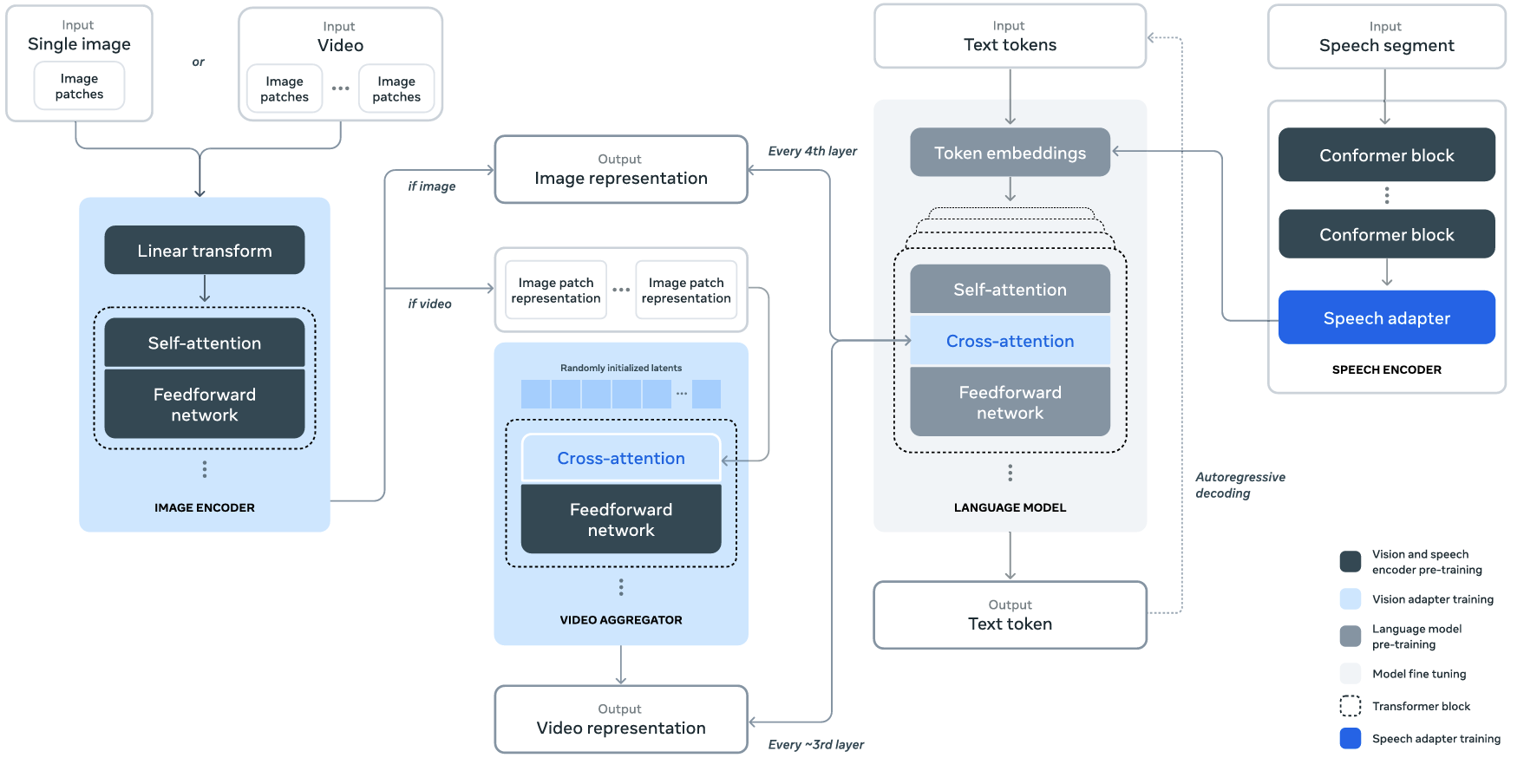
One of the most exciting features of Llama 3 is its ability to understand not just text, but also images, videos, and audio.
But how does this work? The team added special “encoders” for each type of media:
- An image encoder that helps it understand pictures
- A video encoder that can make sense of moving images
- An audio encoder that processes speech and other sounds
These encoders work together with the main language model, allowing Llama 3 to perform tasks like describing images, summarizing videos, or transcribing speech. It’s like giving the AI eyes and ears in addition to its language skills.
However, the process is more complex in practice. I would highly recommend going through sections 7 and 8 of the technical article to understand it better.
Real-World Applications of Llama 3
The potential applications (not at all exhaustive) for Llama 3 are vast and exciting:
- In education, it could create interactive learning experiences that combine text, images, and videos.
- In healthcare, it might help doctors by analyzing medical images alongside patient records.
- In entertainment, it could help in content creation, enabling new ways to interact with media through voice commands and visual inputs.
What Does the Future Hold for Such Open-Weight Models?
While some of Llama 3’s more advanced features are still being refined, the model series represents a significant leap forward in AI technology. Its ability to handle multiple types of data – text, images, video, and audio – opens up a world of possibilities for more natural and versatile AI applications.
As research continues and these models are further developed, we can expect to see Llama 3 and its successors playing increasingly important roles across various industries, potentially transforming the way we interact with technology in our daily lives. Llama 3 is not the last of the open-weight 405B model. In fact, we will very soon see completely open-source LLMs of similar scale which will give both AI engineers and developers much more freedom to do things that were incomprehensible a few years back.
Summary and Conclusion
In this article, we boiled down the most important parts of the Llama 3 technical article into quickly digestible points. The original technical report holds a myriad of information about LLM training, scaling, and inference. I highly recommend anyone interested in LLMs to go through it at least once. I hope this article was worth your time.
If you have any doubts, thoughts, or suggestions, please leave them in the comment section. I will surely address them.
You can contact me using the Contact section. You can also find me on LinkedIn, and X.
Reference

1 thought on “Meta Llama 3 – An Overview”