

Gemma 3 is the third iteration in the Gemma family of models. Created by Google (DeepMind), Gemma models push the boundaries of small and medium sized language models. With Gemma 3, they bring the power of multimodal AI with Vision-Language capabilities.
Gemma 3 family of models contains small language models (SLMs) and vision language models (VLMs) in the range of 1B to 27B parameters. They are also equipped with 128K context length, better architecture, and pre-training and post-training strategies. In this article, we will explore the Gemma 3 model with sample inference code using Hugging Face.
We will cover the following topics with Gemma 3
- Why Gemma 3?
- How has the architecture of Gemma 3 evolved?
- How does Gemma 3 stack up against other models?
- Inference with Gemma 3 using Hugging Face.
Why Gemma 3?
Gemma 3 was developed by Google DeepMind to address the following limitations of the previous versions of Gemma model:
- Multimodality: The previous Gemma models (Gemma 1 and Gemma 2), while excellent at chatting, did not have multimodality. They could not deal with images. Gemma 3 has multimodality built in. This means we can chat with the models just via text or even with images.
- Accessible Model Sizes: The previous Gemma version had a 9B and a 27B version. Although small, however, it is not particularly mobile friendly. Gemma 3 contains 4 different model sizes: 1B, 4B, 12B, and 27B. Starting from the smallest of models for mobile devices to running on a powerful desktop, we have all the options.

Gemma 3 Architecture
As is the norm, Gemma 3 is built on top of a general decoder-only transformer architecture. It comes in 4 different sizes.
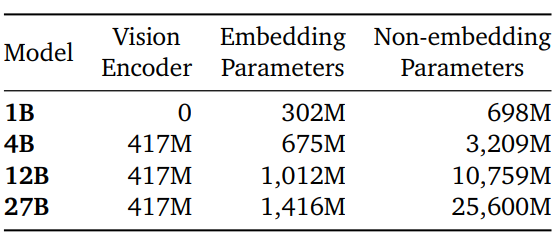
The 1B model only supports text modality. All other models are multimodal with both text and vision support.
There are a few major improvements compared to the previous Gemma versions:
- Long context: Gemma 3 models support a context length of up to 128K tokens. However, the 1B model supports up to 32K context length. With longer context, the KV cache tends to explode. The authors of Gemma 3 mitigate this by increasing the ratio of local to global attention layers.
- 5:1 interleaving of local/global layers: As global self-attention layers tend to use more memory, the authors interleave 5 local self-attention layers per global self-attention layer. These local layers attend to only 1024 tokens.
This design significantly reduces the memory footprint, as only the less frequent global layers need to store the KV cache for the entire long context.
Vision Modality in Gemma 3
Gemma 3 uses a 400M SigLip vision encoder that accepts an input size of 896×896. It is pretrained and shared between the 4B, 12B, and 27B models while keeping it frozen during training.
Another interesting fact is that the image embeddings of each model are pre-computed for the vision encoder. During joint training, the pre-computed image embeddings are used to reduce training cost.
There are several other details regarding the architecture and training strategy, including pre-training, quantization aware training, compute infrastructure, and post-training. I highly recommend giving the technical report a read.
Benchmark and Evaluations of Gemma 3
On LMSYS, Gemma 3 competes closely with other much larger and closed-sourced models.
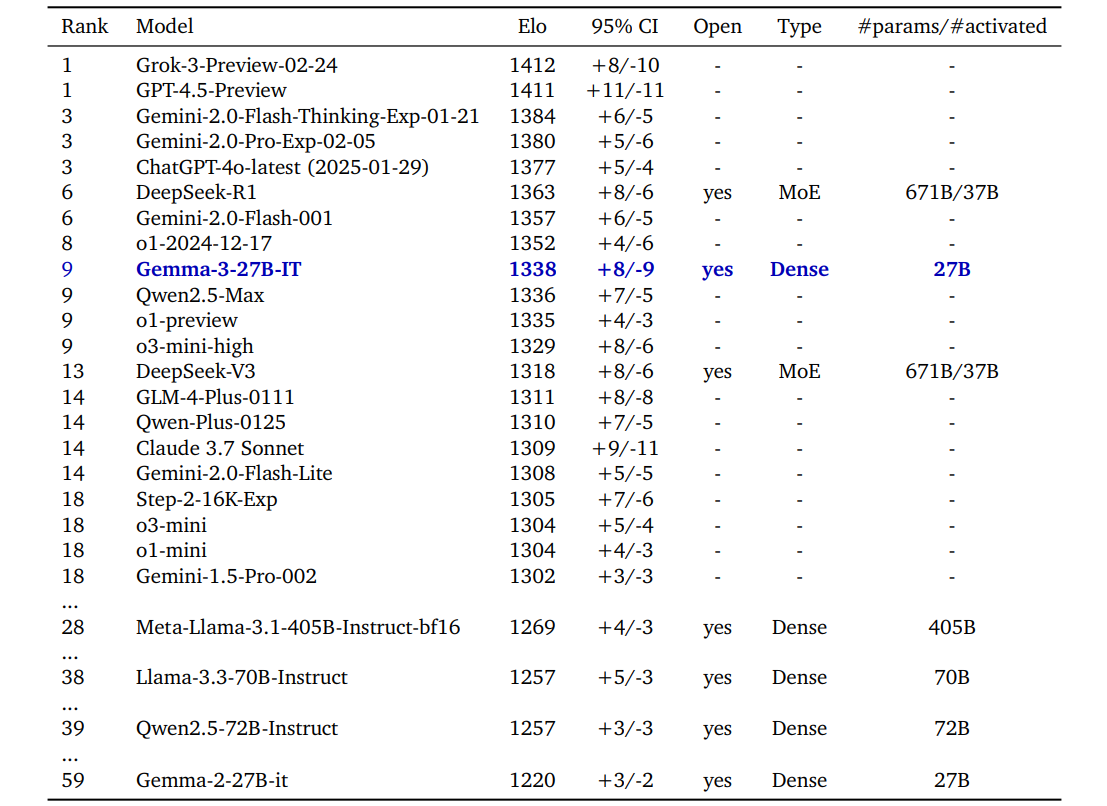
The 27B model is better than much larger DeepSeek-V3, OpenAI o1 models, and also, Meta Llama 405B models.
Compared with DeepMind’s own models, Gemma 3 27B performs close to the versions of the Gemini models.
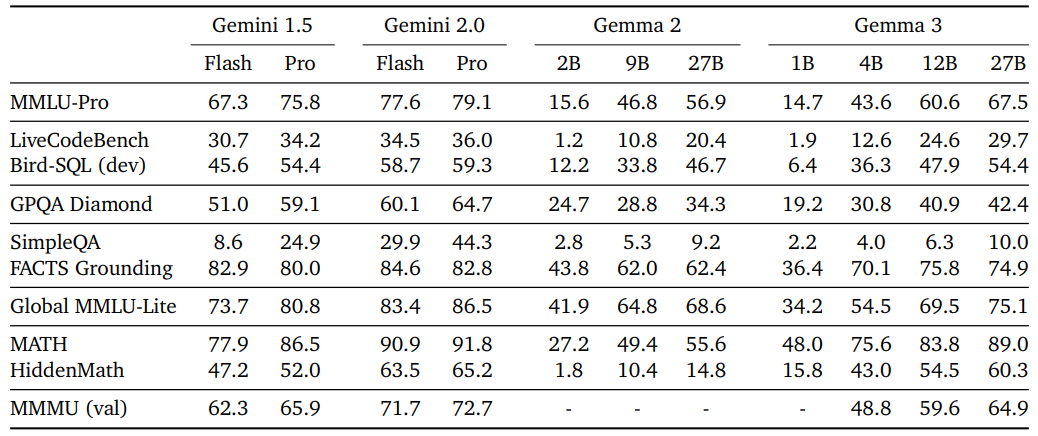
And of course, the recent models are much better than the Gemma 2 models.
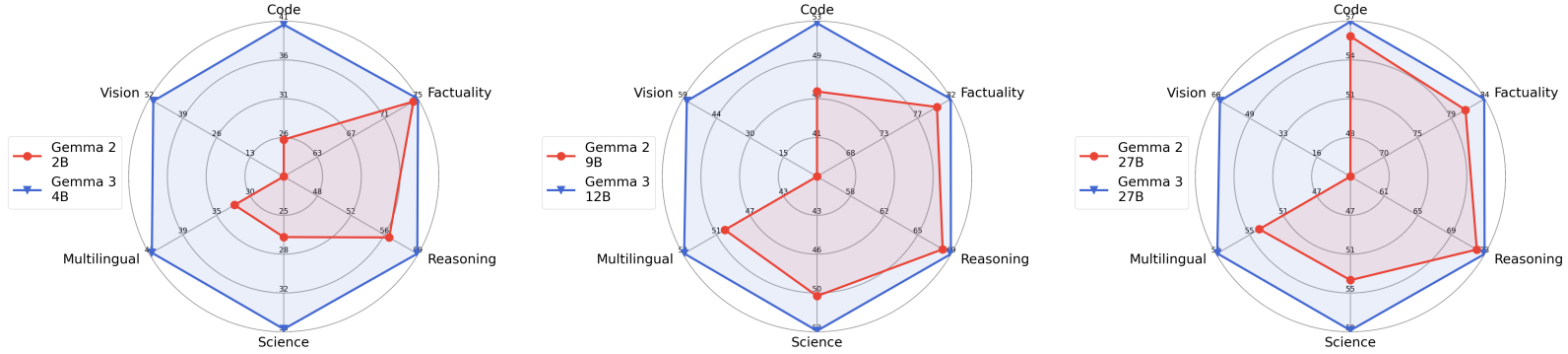
The technical report also contains details about specific benchmarks like code, science, and maths.
Directory Structure
Before we get into the inference part, let’s take a look at the directory structure.
├── input │ ├── image_1.jpg │ ├── image_2.jpg │ └── receipt.jpg ├── gemma3_inference.py ├── README.md └── requirements.txt
- The
inputdirectory contains the images that we will use for Gemma 3 multimodal inference. - We have a single Python script for inference.
- The
requirements.txtfile contains the major libraries that we need to install.
Download Code
Installing Dependencies
You can install all the dependencies using the requirements file.
pip install -r requirements.txt
We are done with the setup, let’s move to the inference part.
Getting Started with Gemma 3 Inference using Hugging Face
Let’s start with the inference code without any further delay.
All the code is present in gemma3_inference.py file. The following block contains the entire code.
import torch
import argparse
import os
from transformers import (
AutoProcessor,
Gemma3ForConditionalGeneration,
TextStreamer,
AutoTokenizer,
BitsAndBytesConfig
)
from PIL import Image
def load_model_and_processor(model_id="google/gemma-3-4b-it"):
"""Loads the Gemma 3 model and processor"""
print(f"Loading model: {model_id}...")
try:
bnb_config = BitsAndBytesConfig(load_in_8bit=True)
model = Gemma3ForConditionalGeneration.from_pretrained(
model_id,
device_map="auto",
torch_dtype=torch.bfloat16,
quantization_config=bnb_config
).eval()
processor = AutoProcessor.from_pretrained(model_id)
tokenizer = AutoTokenizer.from_pretrained(model_id)
print("Model and Processor loaded successfully.")
return model, processor, tokenizer
except Exception as e:
print(f"Error loading model or processor: {e}")
print("Please ensure you have the necessary libraries installed and are logged into Hugging Face if required.")
exit(1)
def perform_inference(
model, processor, tokenizer, prompt, image_path=None, max_new_tokens=250
):
"""
Performs text-only or multimodal inference based on provided arguments.
"""
messages = []
is_multimodal = False
# Prepare messages based on input.
if image_path:
print(f"Performing multimodal inference with image: {image_path}")
if not os.path.exists(image_path):
print(f"Error: Image path not found: {image_path}")
return
try:
image = Image.open(image_path).convert("RGB")
is_multimodal = True
messages = [
{
"role": "system",
"content": [{
"type": "text",
"text": "You are an expert image analyst assistant."
}]
},
{
"role": "user",
"content": [
{"type": "image", "image": image},
{"type": "text", "text": prompt}
]
}
]
except Exception as e:
print(f"Error opening or processing image: {e}")
return
else:
print("Performing text-only chat inference.")
messages = [
{
"role": "system",
"content": [{
"type": "text",
"text": "You are a friendly and helpful AI assistant."
}]
},
{
"role": "user",
"content": [
{"type": "text", "text": prompt}
]
}
]
# Tokenize and Prepare Inputs.
try:
inputs = processor.apply_chat_template(
messages,
add_generation_prompt=True,
tokenize=True,
return_dict=True,
return_tensors="pt"
).to(model.device, dtype=torch.bfloat16)
except Exception as e:
print(f"Error processing inputs with chat template: {e}")
return
text_streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
# Generation.
print("Generating response...")
# Adjust generation parameters based on task.
gen_kwargs = {
"max_new_tokens": max_new_tokens,
"do_sample": not is_multimodal, # Use sampling for chat, greedy for image analysis
"temperature": 0.7 if not is_multimodal else 1.0, # Lower temp for chat
"top_k": 50 if not is_multimodal else None,
"top_p": 0.95 if not is_multimodal else None,
"streamer": text_streamer
}
with torch.inference_mode():
try:
model.generate(**inputs, **gen_kwargs)
except Exception as e:
print(f"Error during model generation: {e}")
return
def main():
parser = argparse.ArgumentParser(
description="Gemma 3 inference for text chat or image understanding."
)
parser.add_argument(
"-p", "--prompt",
type=str,
required=True,
help="The text prompt for the model."
)
parser.add_argument(
"-i", "--image",
type=str,
default=None,
help="Optional path to an image file for multimodal inference."
)
parser.add_argument(
"-m", "--model-id",
dest="model_id",
type=str,
default="google/gemma-3-4b-it",
help="The Hugging Face model ID to use (e.g., google/gemma-3-4b-it)."
)
parser.add_argument(
"--max-new-tokens",
dest="max_new_tokens",
type=int,
default=256,
help="Maximum number of new tokens to generate."
)
args = parser.parse_args()
# Load the model and processor
model, processor, tokenizer = load_model_and_processor(args.model_id)
# Perform inference
perform_inference(
model,
processor,
tokenizer,
args.prompt,
args.image,
args.max_new_tokens
)
if __name__ == "__main__":
main()
The code is quite straightforward.
- We load the Gemma 3 model, the processror, and tokenizer in the
load_model_and_processorfunction. At the time of writing this, 4-bit BitsAndBytes configuration was throwing CUDA error. So, we are loading the model in 8-bit quantization. - The
perform_inferencefunction accepts the model, the processor, tokenizer, prompt, and an optional image path as parameters. We process the message differently when passing only the text prompt and when passing both text prompt and image. The text streamer streams the output into the CLI as the model predicts each token. - The
mainfunction combines everything along with command line arguments for the text prompt, the image path, the model tag from Hugging Face, and the total number of new tokens that we want to predict.
Gemma 3 Text Inference
Let’s start with a simple text only inference where we ask the Gemma 3 4B model about the Transformer architecture.
python gemma3_inference.py --prompt "Describe the Transformer architecture in 200 words"
Following is the response by the model.
Okay, let’s break down the Transformer architecture – it’s a revolutionary design that powers many of today’s AI models, like ChatGPT! At its core, the Transformer ditches the traditional sequential processing of Recurrent Neural Networks (RNNs). Instead, it uses something called **attention mechanisms**. Think of it like this: when reading a sentence, you don't just process each word in order; you relate it to *all* the other words to understand its meaning. That’s what attention does! **Here’s the gist:** * **Encoder & Decoder:** The Transformer has an encoder that processes the input and a decoder that generates the output. * **Self-Attention:** This is the magic! It allows each word to “attend” to every other word in the input, figuring out their relationships. * **Feed-Forward Networks:** After attention, these networks process the information further. * **Positional Encoding:** Since it doesn’t process sequentially, positional encoding adds information about word order. Essentially, the Transformer excels at parallel processing and capturing long-range dependencies in data, making it incredibly effective for tasks like translation, text generation, and more. Would you like me to delve into a specific aspect
The answer is quite concise and to the point.
Gemma 3 Image Description
Next, we will ask the Gemma 3 model to describe a complex image. Following is the image that we will be dealing with.

Let’s prompt the model with the text and the image now.
python gemma3_inference.py --prompt "Describe the image concisely" --image input/image_1.jpg
Following is the output of the model.
Okay, here's a concise analysis of the image: **The image is a stark, high-contrast black and white photograph featuring a lone paraglider suspended in the sky above a densely forested mountain range.** **Key elements:** * **Composition:** The image is framed by dark, textured clouds on either side, drawing the eye to the central subject. * **Subject:** A single paraglider is the focal point, appearing small and isolated against the vastness of the sky. * **Setting:** The scene depicts a mountainous landscape shrouded in mist or low-hanging clouds, suggesting a remote and possibly dramatic location. Do you want me to delve deeper into any specific aspect of the image, such as the lighting, composition, or potential mood it evokes?
The output is pretty good. It is able to infer the tone and color of the image and interpret them properly.
Gemma 3 OCR Capability
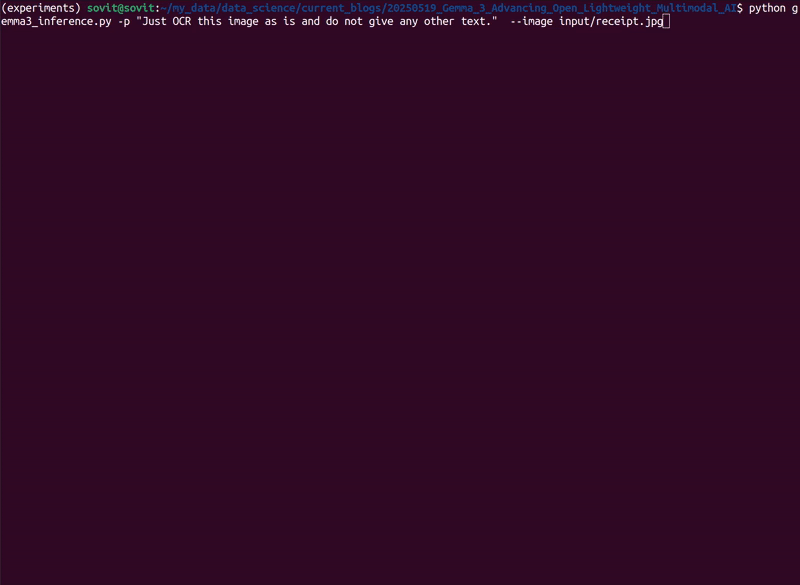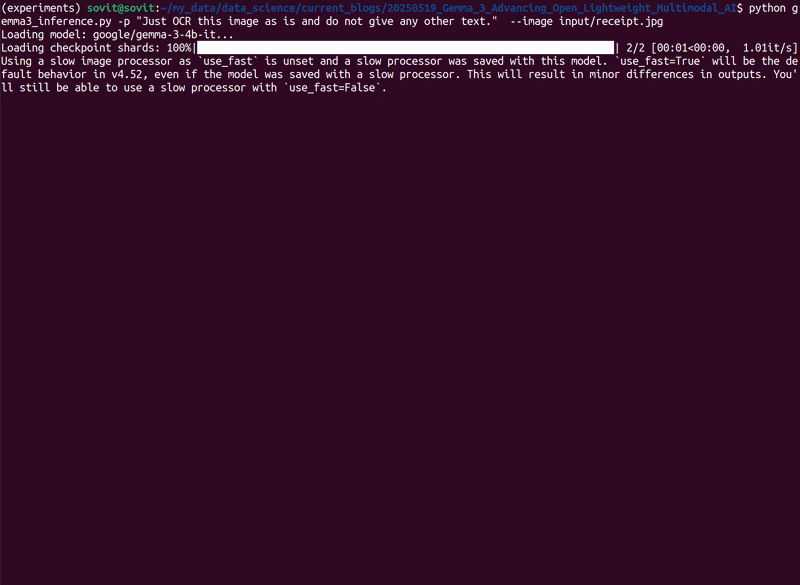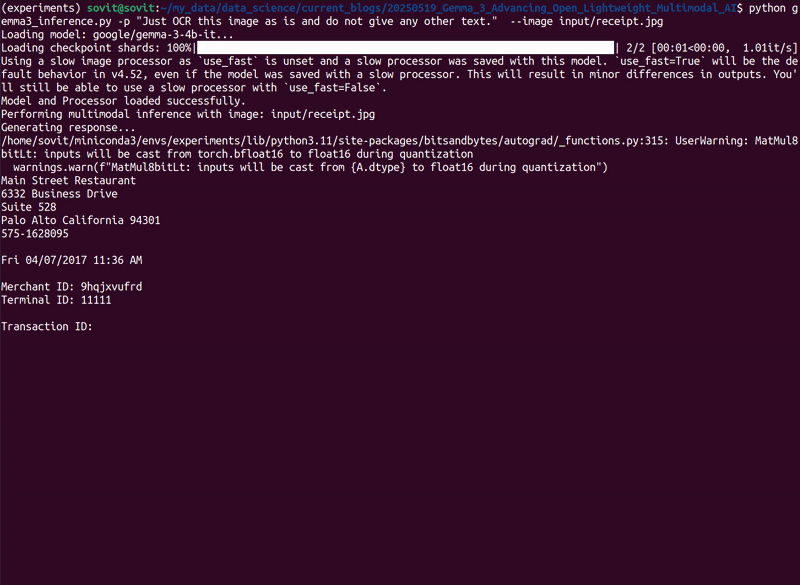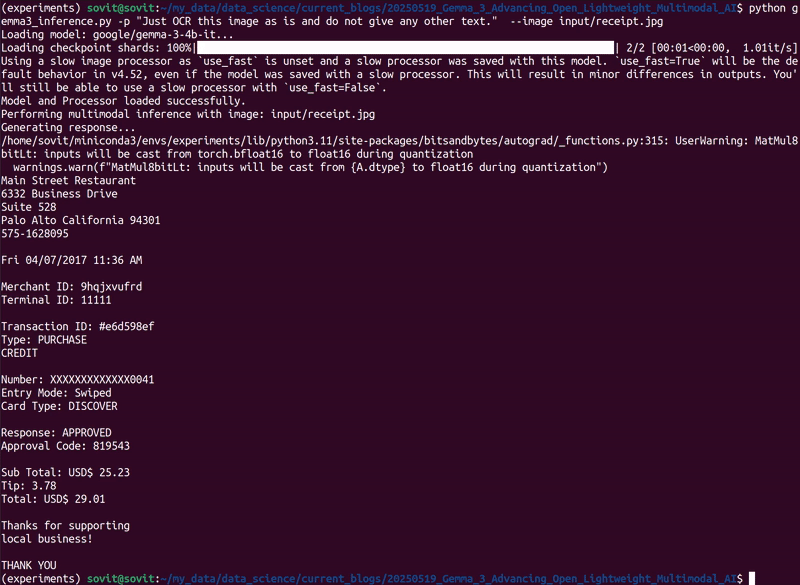
Here, we will check the OCR capability of the Gemma 3 4B model. Note that this is the smallest multimodal model in the Gemma 3 family. We will provide the following receipt image as input for OCR to the model.

python gemma3_inference.py -p "Just OCR this image as is and do not give any other text." --image input/receipt.jpg
The model gave the following OCR output.
Main Street Restaurant 6332 Business Drive Suite 528 Palo Alto California 94301 575-1628095 Fri 04/07/2017 11:36 AM Merchant ID: 9hqjxvufrd Terminal ID: 11111 Transaction ID: #e6d598ef Type: PURCHASE CREDIT Number: XXXXXXXXXXXXX0041 Entry Mode: Swiped Card Type: DISCOVER Response: APPROVED Approval Code: 819543 Sub Total: USD$ 25.23 Tip: 3.78 Total: USD$ 29.01 Thanks for supporting local business! THANK YOU
The output is entirely correct. It is interesting given that we are dealing with a 4B model here.
Gemma 3 Counting Capability
Finally, we will check the counting capability of the Gemma 3 model. We will ask the model to count the number of zebras in the following image.

python gemma3_inference.py -p "How many zebras" --image input/image_2.jpg
Following was the response of the model.
Based on my assessment, I can identify **five** zebras in the image. Here's a breakdown of how I counted them: * There are four zebras standing in a line in the foreground. * One zebra is grazing to the right of the group. Do you want me to analyze any other specific details within the image, such as the landscape, lighting, or composition?
The count is correct, and the model also gave additional context.
It seems that the multimodal capabilities of even the smallest Gemma 3 model are strong. Fine-tuning the model for specific use cases will result in an even better understanding.
Summary and Conclusion
In this article, we covered the new Gemma 3 model by Google DeepMind. We started with the need for Gemma 3, covered its architecture, and also ran inference for both text and image understanding. I hope this article was worth your time.
If you have any questions, thoughts, or suggestions, please leave them in the comment section. I will surely address them.
You can contact me using the Contact section. You can also find me on LinkedIn, and X.
References
