

OCR (Optical Character Recognition) is the basis for understanding digital documents. As we experience the growth of digitized documents, the demand and use case for OCR will grow substantially. Recently, we have experienced rapid growth in the use of VLMs (Vision Language Models) for OCR. However, not all VLM models are capable of handling every type of document OCR out of the box. One such use case is receipt OCR, which follows a specific structure. Smaller VLMs like SmolVLM, although memory and compute optimized, do not perform well on them unless fine-tuned. In this article, we will tackle this exact problem. We will be fine-tuning the SmolVLM model for receipt OCR.

The SmolVLM-256M requires just about 2GB of VRAM for inference. Although it is good at general image understanding, it falters at complex OCR tasks. Fine-tuning it on specific OCR tasks will lead to better results. We will uncover all the techniques here.
What will we cover while fine-tuning SmolVLM for Receipt OCR
- Why is receipt OCR challenging for smaller VLMs?
- The SROIE v2 dataset.
- How to create the ground truth annotations for the receipt OCR?
- How to fine-tune SmolVLM for receipt OCR?
- Using the fine-tuned SmolVLM for inference.
Why is Receipt OCR challenging for Smaller VLMs?
Larger VLMs like Gemini 2.0 Flash, ChatGPT, and the like can easily carry out receipt OCR. However, we know that using a multi-hundred billion parameter VLM for this task is overkill. Because receipt OCR has been tackled for years with text detection models combined with a simple OCR model (think SSD for text detection + TrOCR for cropped text OCR). So, we just need to switch to smaller VLMs to reduce the compute cost and make it a single shot process.
But what about smaller VLMs like 256 million parameters to 2 billion parameter range? They struggle a lot. For example, the following is an output of receipt OCR using the pretrained SmolVLM-256M model.

There are several factors determining such results. Some pertain to the model itself, and some pertain to the scenario:
- Smaller models, although good at simple tasks such as image description, are bad at structured data understanding and extraction.
- Most of the receipt images are taken by users using their smartphones. This leads to extreme variations in background, lighting, sharpness, and image quality.
The most straightforward solution here is to collect several thousand images of receipts in various scenarios and train a smaller VLM model on that.
In this article, we will tackle some of the aspects of this challenge.
The SROIE v2 Dataset
The SROIE (Scanned Receipts OCR and Information Extraction) contains images of scanned receipts.
This dataset is a part of the ICDAR 2019 Robust Reading Challenge. Here, we will use version 2 of the dataset available on Kaggle.
The dataset is already divided into 626 training and 347 test samples. Following is the directory structure of the dataset after downloading and extracting it.
sroie_v2/
└── SROIE2019
├── test
│ ├── box [347 entries exceeds filelimit, not opening dir]
│ ├── entities [347 entries exceeds filelimit, not opening dir]
│ └── img [347 entries exceeds filelimit, not opening dir]
└── train
├── box [626 entries exceeds filelimit, not opening dir]
├── entities [626 entries exceeds filelimit, not opening dir]
└── img [626 entries exceeds filelimit, not opening dir]
- After downloading, we have renamed the parent directory to
sroie_v2for easier access. - The
trainandtestfolders containbox,entities, andimgsubfolders.
The img folder contains the images in JPG format. The following are a few samples from the training set.

The entities folder contains the important information in a text file for each image. The box directory contains the polygonal bounding box information for each information and the corresponding text. For example, the following is an image, its entity information, and its box information.
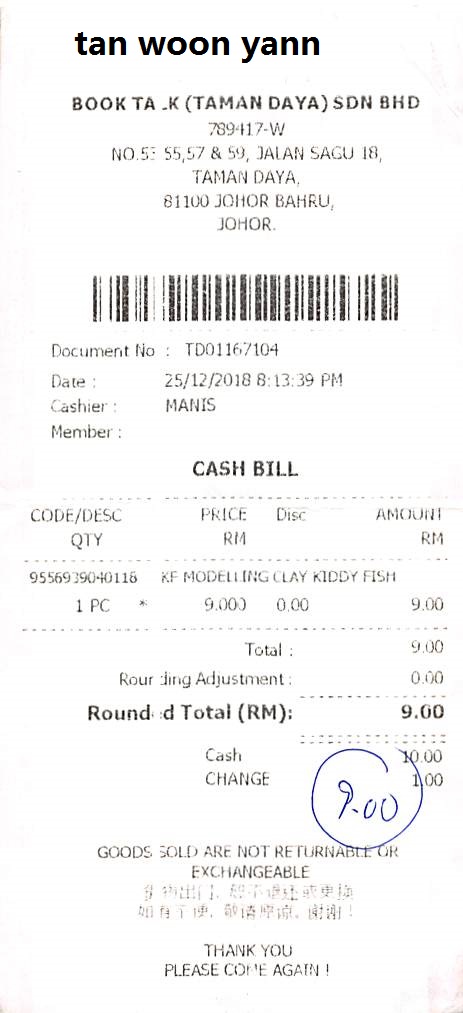
The following block contains its entity information.
{
"company": "BOOK TA .K (TAMAN DAYA) SDN BHD",
"date": "25/12/2018",
"address": "NO.53 55,57 & 59, JALAN SAGU 18, TAMAN DAYA, 81100 JOHOR BAHRU, JOHOR.",
"total": "9.00"
}
The next block contains the box information.
72,25,326,25,326,64,72,64,TAN WOON YANN 50,82,440,82,440,121,50,121,BOOK TA .K(TAMAN DAYA) SDN BND 205,121,285,121,285,139,205,139,789417-W 110,144,383,144,383,163,110,163,NO.53 55,57 & 59, JALAN SAGU 18, 192,169,299,169,299,187,192,187,TAMAN DAYA, 162,193,334,193,334,211,162,211,81100 JOHOR BAHRU, 217,216,275,216,275,233,217,233,JOHOR. 50,342,279,342,279,359,50,359,DOCUMENT NO : TD01167104 50,372,96,372,96,390,50,390,DATE: 165,372,342,372,342,389,165,389,25/12/2018 8:13:39 PM 48,396,117,396,117,415,48,415,CASHIER: 164,397,215,397,215,413,164,413,MANIS 49,423,122,423,122,440,49,440,MEMBER: 191,460,298,460,298,476,191,476,CASH BILL 30,508,121,508,121,523,30,523,CODE/DESC 200,507,247,507,247,521,200,521,PRICE 276,506,306,506,306,522,276,522,DISC 374,507,441,507,441,521,374,521,AMOUNT 69,531,102,531,102,550,69,550,QTY 221,531,247,531,247,545,221,545,RM 420,529,443,529,443,547,420,547,RM 27,570,137,570,137,583,27,583,9556939040116 159,570,396,570,396,584,159,584,KF MODELLING CLAY KIDDY FISH 77,598,113,598,113,613,77,613,1 PC 138,597,148,597,148,607,138,607,* 202,597,245,597,245,612,202,612,9.000 275,598,309,598,309,612,275,612,0.00 411,596,443,596,443,613,411,613,9.00 245,639,293,639,293,658,245,658,TOTAL: 118,671,291,671,291,687,118,687,ROUR DING ADJUSTMENT: 408,669,443,669,443,684,408,684,0.00 86,704,292,704,292,723,86,723,ROUND D TOTAL (RM): 401,703,443,703,443,719,401,719,9.00 205,744,243,744,243,765,205,765,CASH 402,748,441,748,441,763,402,763,10.00 205,770,271,770,271,788,205,788,CHANGE 412,772,443,772,443,786,412,786,1.00 97,845,401,845,401,860,97,860,GOODS SOLD ARE NOT RETURNABLE OR 190,864,309,864,309,880,190,880,EXCHANGEABLE 142,883,353,883,353,901,142,901,*** 137,903,351,903,351,920,137,920,*** 202,942,292,942,292,959,202,959,THANK YOU 163,962,330,962,330,977,163,977,PLEASE COME AGAIN ! 412,639,442,639,442,654,412,654,9.00
For now, we can safely ignore the entity information. Furthermore, we will not use the text annotation from the box folder. This is because the texts are not case sensitive, which can be a primary necessity in receipt OCR. So, we will generate our own annotations later in the article. For now, you can download the dataset from Kaggle.
Project Directory Structure
I am working on this project actively and you can find the GitHub project here.
To ensure that future updates to the project do not break the code in this article, I am providing the download link to a specific commit of the project.
All the code notebooks, trained adapters, QwenVL annotations, and inference code is available for download via the download section.
The following is the directory structure of the project.
├── assets │ └── receipt_ocr_800x800.png ├── input │ ├── sroie_v2 │ │ └── SROIE2019 │ │ ├── test │ │ │ ├── box [347 entries exceeds filelimit, not opening dir] │ │ │ ├── entities [347 entries exceeds filelimit, not opening dir] │ │ │ └── img [347 entries exceeds filelimit, not opening dir] │ │ └── train │ │ ├── box [626 entries exceeds filelimit, not opening dir] │ │ ├── entities [626 entries exceeds filelimit, not opening dir] │ │ └── img [626 entries exceeds filelimit, not opening dir] │ └── input.txt ├── notebooks │ ├── inference_data │ │ ├── image_1_cropped.jpeg │ │ ├── image_1.jpeg │ │ ├── IMG-20241119-WA0001_cropped.jpg │ │ └── IMG-20241119-WA0001.jpg │ ├── trained_adapters │ │ └── smolvlm_receipt_qwengt_ft [12 entries exceeds filelimit, not opening dir] │ ├── gemini_ocr.ipynb │ ├── qwen2_vl_ocr.ipynb │ ├── smolvlm_inference_ft.ipynb │ ├── smolvlm_inference_pretrained.ipynb │ ├── smolvlm_pretrained_inference.py │ └── smol_vlm_sft_sroie.ipynb ├── LICENSE.txt ├── README.md └── requirements.txt
Here are some of the important files and directories that we will deal with:
- The
inputdirectory contains the SROIE v2 dataset that we discussed earlier. - We have all the Jupyter Notebooks in the
notebooksdirectory. Later, we will see all the notebooks that we will work with. In addition, we have the inference data in theinference_datasubdirectory and the trained adapter weights in thetrained_adapterssubdirectory.
Download Code
Installing the Requirements
You can install all the necessary libraries using the requirements file.
pip install -r requirements.txt
All the code files by default use Flash-Attention 2 for training and inference. This requires an NVIDIA GPU with Ampere architecture and above, that is, starting from 30 series consumer GPUs. T4, P100, V100 do not support Flash-Attention. If you get an error during the installation of Flash-Attention, ensure that you install PyTorch and CUDA (system-wide) first and then install Flash Attention 2 again. It should install without errors.
Creating Ground Truth Annotations for Receipt OCR
There are a few ways that we can create the ground truth annotations for the dataset. One of the approaches to get the highest quality results is using the Gemini 2.0 Flash model via API call. In fact, the code for that is already available in the notebooks/gemini_ocr.ipynb file.
However, the API call was returning empty responses in a lot of cases, which is not ideal. For this reason, we will stick with a local approach, using the Qwen2-VL model with batched inference.
The code for that is available in the qwen2_vl_ocr.ipynb Jupyter Notebook inside the notebooks directory.
Let’s take a look at the code that we use for creating the ground truth annotations for the SROIE v2 OCR dataset. This section will include minimal explanation of the code as it is more about the approach rather than logic.
Imports
Following are the imports that we need.
from transformers import Qwen2VLForConditionalGeneration, AutoTokenizer, AutoProcessor from qwen_vl_utils import process_vision_info from transformers import BitsAndBytesConfig from tqdm.auto import tqdm import torch import glob import os
Loading the Qwen2-VL 2B Model
We are using the smallest, 2B Qwen2-VL model here in full precision to get the highest quality results possible.
# flash_attention_2 for better acceleration and memory saving. Great for batched inference.
model = Qwen2VLForConditionalGeneration.from_pretrained(
"Qwen/Qwen2-VL-2B-Instruct",
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
device_map="auto"
)
# Load processor
processor = AutoProcessor.from_pretrained("Qwen/Qwen2-VL-2B-Instruct")
Defining the Dataset Paths
The following block defines the paths to either the training or test images.
# all_images = glob.glob('../input/sroie_v2/SROIE2019/test/img/*.jpg')
all_images = glob.glob('../input/sroie_v2/SROIE2019/train/img/*.jpg')
# out_dir = '../input/qwen2_vl_2b_sroiev2_test_annots'
out_dir = '../input/qwen2_vl_2b_sroiev2_train_annots'
os.makedirs(out_dir, exist_ok=True)
Batched Inference
To reduce inference time, we will use batched inference that is natively supported by Qwen2-VL models.
def batch_infer(messages):
# Preparation for inference
texts = [
processor.apply_chat_template(
msg, tokenize=False, add_generation_prompt=True
)
for msg in messages
]
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=texts,
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt"
)
inputs = inputs.to("cuda")
# Inference: Generation of the output
generated_ids = model.generate(**inputs, max_new_tokens=1024)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
# print(output_text)
return output_text
Creating Data Loaders and Carrying Out Batched Forward Pass
Let’s create a PyTorch data loader with a batch size of 16 and carry out batched forward pass.
batch_size = 16
class BatchedDataset(Dataset):
def __init__(self, all_images):
self.all_images = all_images
def __len__(self):
return len(self.all_images)
def __getitem__(self, idx):
return self.all_images[idx]
custom_dataset = BatchedDataset(all_images)
batch_dl = DataLoader(custom_dataset, batch_size=batch_size, shuffle=False)
for batch in tqdm(batch_dl, total=len(batch_dl)):
messages = []
for image_path in batch:
message = [
{
"role": "user",
"content": [
{
"type": "image",
"image": image_path,
"resized_height": 768,
"resized_width": 512,
},
{"type": "text", "text": "Give the OCR text from this image and nothing else."},
],
}
]
messages.append(message)
texts = batch_infer(messages)
for text, image_path in zip(texts, batch):
# print(text)
with open(os.path.join(out_dir, image_path.split(os.path.sep)[-1].split('.jpg')[0]+'.txt'), 'w') as f:
f.write(text)
As we are using Flash-Attention, the GPU memory usage is reduced substantially. Even with a batch size of 16, the GPU memory usage remained below 10GB during the entire forward pass. The above was carried out on a 10GB RTX 3080 GPU, and it took around 25 minutes to complete the entire process. Of course, reducing the image resolution to 768×512 resolution helped in reducing GPU memory consumption.
At the moment, we need to run the code twice, once for the training directory and again for the test directory. It will be cleaned up in the near future.
In the future, the code will be updated to use the native resolution of the OCR images for the highest quality annotations. Also, I will be publishing the error Character Error Rates (CER) between the provided box annotation and Qwen annotations on the project website soon.
Fine-Tuning SmolVLM for Receipt OCR
We will be fine-tuning the SmolVLM-256M model for receipt OCR here. It is the smallest of the SmolVLM family, so the GPU requirements with LoRA training remain substantially low.
The fine-tuning was done on a system with 10GB RTX 3080 GPU, i7 10the generation CPU, and 32 GB of RAM.
The code for this is available in the smol_vlm_sft_sroie.ipynb Jupyter Notebook inside the notebooks directory.
The code that we discuss here has been adapted from this Hugging Face blog post.
Let’s start with the coding part without further delay. We will discuss only the important parts of the codebase here.
Import Statements
The following code block imports all the necessary libraries and modules that we need for training.
import glob import pandas as pd import os import torch import gc import time from sklearn.model_selection import train_test_split from datasets import Dataset from PIL import Image from transformers import AutoModelForVision2Seq, AutoProcessor from transformers import BitsAndBytesConfig from peft import LoraConfig, get_peft_model from trl import SFTConfig, SFTTrainer
We need gc for clearing up GPU memory when necessary.
Loading and Formatting the SROIE v2 Dataset
We need to load the data and create a formatting function that will read the images and load the annotations.
system_message = """You are a vision language model expert at creating at OCR of receipts, invoices, and forms."""
def format_data(sample):
image = Image.open(sample["image_paths"]).convert("RGB")
query = "OCR this image accurately."
label = sample["text_paths"]
return [
{
"role": "system",
"content": [
{
"type": "text",
"text": system_message
}
],
},
{
"role": "user",
"content": [
{
"type": "image",
"image": image,
},
{
"type": "text",
"text": query,
}
],
},
{
"role": "assistant",
"content": [
{
"type": "text",
"text": label
}
],
},
]
The above code block sets an appropriate system prompt for the model. Along with that, we also define a format_data sample. This function reads each image and its corresponding text file for annotations and finally returns the message prompt.
The next code block reads all the text files for training and test dataset from the directory and loads the associated images.
train_text_files = glob.glob("../input/qwen2_vl_2b_sroiev2_train_annots/*.txt")
test_text_files = glob.glob("../input/qwen2_vl_2b_sroiev2_test_annots/*.txt")
train_text_files.sort()
test_text_files.sort()
def prepare_img_txt_list(text_files, split="train"):
all_images, all_texts = [], []
for text_file in text_files:
text = open(text_file).read()
if len(text) > 200:
text_file_name = text_file.split(os.path.sep)[-1].split(".txt")[0]
image_file_name = os.path.join(f"../input/sroie_v2/SROIE2019/{split}/img/", text_file_name+".jpg")
all_images.append(image_file_name)
all_texts.append(text)
return all_images, all_texts
all_train_images, all_train_texts = prepare_img_txt_list(train_text_files, split="train")
all_test_images, all_test_texts = prepare_img_txt_list(test_text_files, split="test")
train_df = pd.DataFrame(
{
"image_paths": all_train_images,
"text_paths": all_train_texts
}
)
test_df = pd.DataFrame(
{
"image_paths": all_test_images,
"text_paths": all_test_texts
}
)
train_dataset = Dataset.from_pandas(train_df)
test_dataset = Dataset.from_pandas(test_df)
train_dataset = [format_data(sample) for sample in train_dataset]
test_dataset = [format_data(sample) for sample in test_dataset]
We only choose those images whose annotation files contain more than 200 characters. This is necessary because sometimes the Qwen2-VL model may not be able to OCR the images properly. This leads to incomplete annotation files. It is better to avoid such files rather than include them which can lead to poor training.
Next, we convert the data frames to Hugging Face dataset format and create the training and test sets. This process leads to the training set containing 501 samples and test set containing 270 samples.
Printing a sample gives the following result that we can use for a sanity check of our format.
[{'role': 'system',
'content': [{'type': 'text',
'text': 'You are a vision language model expert at creating at OCR of receipts, invoices, and forms.'}]},
{'role': 'user',
'content': [{'type': 'image',
'image': <PIL.Image.Image image mode=RGB size=748x1574>},
{'type': 'text', 'text': 'OCR this image accurately.'}]},
{'role': 'assistant',
'content': [{'type': 'text',
'text': 'MEI LET RESTAURANT\nNO 2, JALAN BULAN BM U5/BM, SEKSYEN U5,\n40150 SHAH ALAM, SELANGOR\nNO GST: 0010 9273 4976\nTAX INVOICE\n\nTABLE : 08\nBILL NO: 00015047 / 10P01\nCASHIER: ADMINISTRATOR\nBILL DT: 22/01/2017 09:09:16 PM\nRM\n1 TALAPIA - DEEP FRIED WITH SWEET & 40.00 SR\nC14\n1 BRAISED PORK BELLY WITH BITTER GO 18.00 SR\nL17\n3 WATER / TEA #0.50 SR\n3 RICE (1) #1.50\n6 SUB TOTAL 64.00\n6 GST 6% 3.84\nROUNDING ADJ 0.01\nNET TOTAL 67.85\nCash 100.00\nCHANGE 32.15\n\nTax Summary\nAmount Tax\n64.00\n3.84\nSR GST 6%'}]}]
Loading the Model
We will load the SmolVLM-256M in INT4 format using BitsAndBytes, and apply LoRA for PEFT (Parameter Efficient Fine-Tuning).
model_id = "HuggingFaceTB/SmolVLM-256M-Instruct"
# BitsAndBytesConfig int-4 config
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
# Load model and tokenizer
model = AutoModelForVision2Seq.from_pretrained(
model_id,
device_map="auto",
torch_dtype=torch.bfloat16,
quantization_config=bnb_config,
_attn_implementation="flash_attention_2", # Use `flash_attention_2` on Ampere GPUs and above and `eager` on older GPUs.
# _attn_implementation="eager", # Use `flash_attention_2` on Ampere GPUs and above and `eager` on older GPUs.
)
processor = AutoProcessor.from_pretrained(model_id)
# Configure LoRA
peft_config = LoraConfig(
r=8,
lora_alpha=16,
lora_dropout=0.1,
target_modules=['down_proj','o_proj','k_proj','q_proj','gate_proj','up_proj','v_proj'],
use_dora=True,
init_lora_weights="gaussian"
)
# Apply PEFT model adaptation
peft_model = get_peft_model(model, peft_config)
# Print trainable parameters
peft_model.print_trainable_parameters()
We are using a rank of 8 and alpha of 16 for the fine-tuning process. The usage of Flash Attention will lead to lower GPU usage and faster training.
Starting the Fine-Tuning Process
Finally, let’s write the code to start the fine-tuning process of SmolVLM for receipt OCR.
output_dir = "trained_adapters/smolvlm_receipt_qwengt_ft"
# Configure training arguments using SFTConfig
training_args = SFTConfig(
output_dir=output_dir,
num_train_epochs=5,
per_device_train_batch_size=2,
per_device_eval_batch_size=2,
gradient_accumulation_steps=4,
warmup_steps=50,
learning_rate=1e-4,
weight_decay=0.01,
logging_steps=100,
eval_steps=100,
eval_strategy="steps",
save_strategy="steps",
save_steps=100,
save_total_limit=1,
optim="adamw_torch_fused",
bf16=True,
report_to="tensorboard",
remove_unused_columns=False,
gradient_checkpointing=True,
dataset_text_field="",
dataset_kwargs={"skip_prepare_dataset": True},
)
image_token_id = processor.tokenizer.additional_special_tokens_ids[
processor.tokenizer.additional_special_tokens.index("<image>")]
def collate_fn(examples):
texts = [processor.apply_chat_template(example, tokenize=False) for example in examples]
image_inputs = []
for example in examples:
image = example[1]['content'][0]['image']
if image.mode != 'RGB':
image = image.convert('RGB')
image_inputs.append([image])
batch = processor(text=texts, images=image_inputs, return_tensors="pt", padding=True)
labels = batch["input_ids"].clone()
labels[labels == processor.tokenizer.pad_token_id] = -100 # Mask padding tokens in labels
labels[labels == image_token_id] = -100 # Mask image token IDs in labels
batch["labels"] = labels
return batch
trainer = SFTTrainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=test_dataset,
data_collator=collate_fn,
peft_config=peft_config,
tokenizer=processor.tokenizer,
)
trainer.train()
trainer.save_model(training_args.output_dir)
We are training for 5 epochs with a batch of 2 and gradient accumulation steps of 4. This makes our effective batch size 8. Following is the training log.
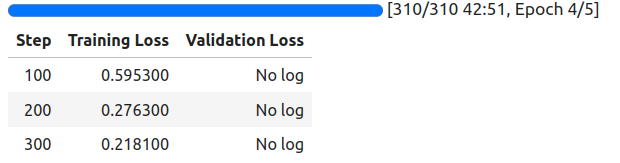
These are very preliminary results, and we can improve much more in the near future. However, let’s take the model from here and try out inference.
Inference using Trained Model
Let’s use the trained model for inference. The code for this is present in the smolvlm_inference_ft.ipynb Jupyter Notebook inside the notebooks folder.
The following are the import statements.
from transformers import AutoModelForVision2Seq, AutoProcessor from PIL import Image import torch import matplotlib.pyplot as plt
Now, loading the trained and the trained adapters.
model_id = "HuggingFaceTB/SmolVLM-256M-Instruct"
model = AutoModelForVision2Seq.from_pretrained(
model_id,
device_map="auto",
torch_dtype=torch.bfloat16,
_attn_implementation="flash_attention_2" # Use `flash_attention_2` on Ampere GPUs and above and `eager` on older GPUs.
# _attn_implementation="eager", # Use `flash_attention_2` on Ampere GPUs and above and `eager` on older GPUs.
)
processor = AutoProcessor.from_pretrained(model_id)
adapter_path = "trained_adapters/smolvlm_receipt_qwengt_ft/"
model.load_adapter(adapter_path)
We will use the following image of the receipt that we ran OCR on initially, which the pretrained model was unable to predict correctly.

Let’s read the image and pass through the model.
test_image = Image.open("inference_data/image_1_cropped.jpeg").convert("RGB")
def test(model, processor, image, max_new_tokens=1024, device="cuda"):
messages = [
{
"role": "user",
"content": [
{"type": "image"},
{"type": "text", "text": "OCR this image accurately"}
]
},
]
# Prepare the text input by applying the chat template
text_input = processor.apply_chat_template(
messages, # Use the sample without the system message
add_generation_prompt=True
)
image_inputs = []
if image.mode != 'RGB':
image = image.convert('RGB')
image_inputs.append([image])
# Prepare the inputs for the model
model_inputs = processor(
#text=[text_input],
text=text_input,
images=image_inputs,
return_tensors="pt",
).to(device) # Move inputs to the specified device
# Generate text with the model
generated_ids = model.generate(**model_inputs, max_new_tokens=max_new_tokens)
# Trim the generated ids to remove the input ids
trimmed_generated_ids = [
out_ids[len(in_ids):] for in_ids, out_ids in zip(model_inputs.input_ids, generated_ids)
]
# Decode the output text
output_text = processor.batch_decode(
trimmed_generated_ids,
skip_special_tokens=True,
clean_up_tokenization_spaces=False
)
return output_text[0] # Return the first decoded output text
output = test(model, processor, test_image)
print(output)
Following is the result that we get.
Main Street Restaurant 6332 Business Drive Suite 528 Palo Alto California 94301 575-1628095 Fri 04/07/2017 11:36 AM Merchant ID: 9qjxvu4fdr Terminal ID: 11111 Transaction ID: #e6d598ef Type: PURCHASE Number: XXXXXXXXXXX0041 Entry Mode: Swiped Card Type: DISCOVER Response: APPROVED Approval Code: 819543 Sub Total: USD$ 25.23 Tip: 3.78 Total: USD$ 29.01
Other than the text at the bottom of the receipt, we get almost perfect results.
You can try with more such images.
Current Limitation
There are a few limitations that we need to take care of soon.
- The dataset is not varied enough, we need to gather more data in varied conditions. Almost all the images in the dataset show cropped receipts only.
- This leads to the model learning only good OCR techniques on cropped receipts. At the moment, it does not perform well on receipts with varied backgrounds.
- Augmentations and gathering more data will help.
Summary and Conclusion
In this article, we covered fine-tuning SmolVLM for receipt OCR. We discussed the dataset collection, annotation techniques, training, and inference steps for this project. We also covered the current limitations of our model which we further want to mitigate. I hope this article was worth your time.
If you have any questions, thoughts, or suggestions, please leave them in the comment section. I will surely address them.
You can contact me using the Contact section. You can also find me on LinkedIn, and X.

2 thoughts on “Fine-Tuning SmolVLM for Receipt OCR”