

In recent years, decoder only Large Language Models (LLMs) have shown great potential for numerous NLP tasks. However, for text-to-text tasks, like text summarization, encoder-decoder models are the de facto. It’s true that frontier models like ChatGPT can summarize text in a one-shot manner. But what about smaller models, like Phi 1.5? Can we fine-tune such models for text summarization and gain an advantage over encoder-decoder models? Let’s unravel that in this article. Here, we will be fine-tuning a Phi 1.5 model for text summarization.

This is going to be an interesting article. Instead of an encoder-decoder architecture, we will use a decoder-only Causal Language Model for text summarization. This will reveal the benefits (if any) and the pitfalls of the approach.
We will cover the following topics in the article
- We will start with a short introduction to the dataset that we are using in the article.
- Next, we will move to the dataset preparation part. This will involve the necessary preprocessing for fine-tuning Phi 1.5 for text summarization.
- Then we will load the tokenizer and the Phi 1.5 model.
- The next part involves training the model.
- Finally, we will run inference using the trained model and discuss the advantages and the disadvantages.
Note: We will be directly fine-tuning the Phi 1.5 base model for text summarization here. This model will not go through supervised fine-tuning initially.
Also, before moving further, I highly recommend going through the following articles to get familiar with Phi 1.5 and fine-tuning it with QLoRA.
The BBC News Summary Dataset
We will use the BBC news summary dataset from Hugging Face to fine-tune the Phi 1.5 for summarization. This is an extractive summarization dataset. This means that the summary has been created by extracting short sentences from the original article. The summary sentences are not new restructured sentences.
It is a small dataset with only around 2200 samples. We will later split it into a training and a validation set.
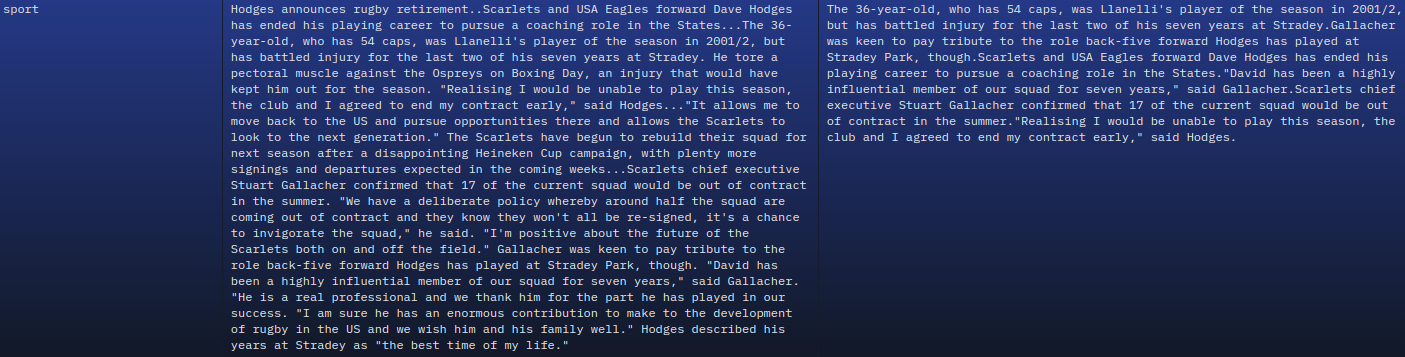
As we can see, there are three columns:
- File_Path: This indicates which category the summary belongs to. There are 5 categories: business, sport, politics, tech, and entertainment.
- Articles: This contains the entire article which the model needs to learn to summarize.
- Summaries: These are the summaries of the articles.
We need not download the dataset manually as we can do so using the Hugging Face datasets library later.
Directory Structure
Following is the directory structure for the project.
├── inference_data │ └── sample_1.txt ├── outputs │ └── phi_1_5_summarization ├── inference.ipynb ├── phi_1_5_summarization.ipynb └── requirements.txt
- There are two Jupyter Notebooks. The
phi_1_5_summarization.ipynbis for training the text summarizer and theinference.ipynbis for running inference. - The
inference_datadirectory contains a few text samples (mini articles) that we will summarize during inference. - The
outputsdirectory contains the trained models. - Finally, the
requirements.txtfile contains all the required libraries.
Download Code
Installing the Necessary Dependencies
We are using the PyTorch as the framework for this project. Be sure to install/update the framework first from the official site.
Following that, you can install the rest of the requirements after downloading and extracting the zip file available with the article.
!pip install -r requirements.txt
All the Jupyter Notebooks and trained weights are available via the download section.
Training Phi 1.5 for Text Summarization
Now, let’s jump into the coding part of the article.
We will start with all the necessary imports.
import os
import torch
from datasets import load_dataset
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
TrainingArguments,
pipeline,
logging,
BitsAndBytesConfig
)
from trl import SFTTrainer
from peft import LoraConfig
Along with the imports to load the data, model, and tokenizer, we are also importing modules for the Supervised Fine-Tuning Trainer pipeline, LoRA, and BitsAndBytes. We will train the model using the QLoRA technique. As we will not go in-depth into the QLoRA training technique and describing the PEFT (Parameter Efficient Fine-Tuning) parameters, be sure to give this article a read.
Defining the Training and Dataset Configuration
The following are all the dataset and training related configurations that we will use throughout the notebook.
batch_size = 1 num_workers = os.cpu_count() epochs = 5 bf16 = True fp16 = False gradient_accumulation_steps = 8 context_length = 1024 learning_rate = 0.0002 model_name = 'microsoft/phi-1_5' out_dir = 'outputs/phi_1_5_summarization' seed = 42
The entire training happens on an RTX 3080 GPU with 10GB VRAM. As we need longer sequence lengths for text summarization training for accommodating the entire article, we use a batch size of 1 with a context length of 1024.
Along with that, we define whether we want to use FP16 or BF16 data type. For older GPUs (P100, T4), we need to choose the FP16 mode. However, for RTX GPUs, we can select BF16. Furthermore, we also define the number of epochs we want to train for, the output directory, and the Hugging Face model tag.
Loading and Preparing the Dataset
The next step is to load the dataset and prepare it in the appropriate format.
dataset = load_dataset('gopalkalpande/bbc-news-summary', split='train')
full_dataset = dataset.train_test_split(test_size=0.2, shuffle=True, seed=seed)
dataset_train = full_dataset['train']
dataset_valid = full_dataset['test']
After loading the dataset, we reserve 20% of the samples for validation. This brings us to 1779 training samples and 445 validation samples.
Here is an example of one of the truncated training samples.
{'File_path': 'entertainment', 'Articles': 'Angels \'favourite funeral song\'..
Angels by Robbie Williams...', 'Summaries': "Queen's Who Wants to Live Forever
... has suggested."}
We also need to preprocess the dataset so that we can feed it to the training pipeline in the required format. The following function does that for us.
def preprocess_function(example):
output_text = []
for i in range(len(example['Articles'])):
text = f"### Instruction:\nSummarize the following article.\n\n### Input:\n{example['Articles'][i]}\n\n### Response:\n{example['Summaries'][i]}<|endoftext|>\n"
output_text.append(text)
return output_text
We format the dataset by taking inspiration from the Alpaca Instruction Following dataset. After going through the above preprocessing step, the dataset will contain an ### Instruction tag, an ### Input tag, and a ### Response tag. Here is an example of a sample.
### Instruction: Summarize the following article. ### Input: Marsh executive in guilty plea..An executive at US insurance firm Marsh & McLennan has pleaded guilty to criminal charges in connection with an ongoing fraud and bid-rigging probe...New York Attorney General Elliot Spitzer said senior vice president Robert Stearns had pleaded guilty to scheming to defraud. The offence carries a sentence of 16 months to four years in state prison. Mr Spitzer's office added Mr Stearns had also agreed to testify in future cases during the industry inquiry. "We are saddened by the development," Marsh said in a statement. The company added it would continue to co-operate in the case, adding it was "committed to resolving the company's legal issues and to serving our clients with the highest standards of transparency and ethics"...According to a statement from Mr Spitzer's office, the Marsh executive admitted he instructed insurance companies to submit non-competitive bids for insurance business between 2002 and 2004. Those bids were then "conveyed to Marsh clients under false and fraudulent pretences". Through the practice, Marsh was allowed to determine which insurers won business from clients, and so control the insurance market, Mr Spitzer's office added. It also protected incumbent insurers when their business was up for renewal and helped Marsh to maximise its fees, a statement said. In one case, an email showed Mr Stearns had instructed a colleague to solicit a non-competitive - or "B" - quote from AIG that was "higher in premium and more restrictive in coverage" and so fixed the bids in a way that would support the present provider Chubb. The company is also still being examined by US stock market regulator the Securities and Exchange Commission (SEC). Late last month the SEC asked for information about transactions involving holders of 5% or more of the firm's shares. ### Response: According to a statement from Mr Spitzer's office, the Marsh executive admitted he instructed insurance companies to submit non-competitive bids for insurance business between 2002 and 2004.Through the practice, Marsh was allowed to determine which insurers won business from clients, and so control the insurance market, Mr Spitzer's office added.It also protected incumbent insurers when their business was up for renewal and helped Marsh to maximise its fees, a statement said.Mr Spitzer's office added Mr Stearns had also agreed to testify in future cases during the industry inquiry."We are saddened by the development," Marsh said in a statement.An executive at US insurance firm Marsh & McLennan has pleaded guilty to criminal charges in connection with an ongoing fraud and bid-rigging probe.<|endoftext|>
You can find a detailed explanation of the Alpaca dataset format here.
Loading the Phi 1.5 Model
The rest of the process for loading the Phi 1.5 model for text summarization is similar to any other supervised fine-tuning pipeline. The next step includes loading the model in INT4 quantized format along with the tokenizer.
# Quantization configuration.
if bf16:
compute_dtype = getattr(torch, 'bfloat16')
else: # FP16
compute_dtype = getattr(torch, 'float16')
quant_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type='nf4',
bnb_4bit_compute_dtype=compute_dtype,
bnb_4bit_use_double_quant=True
)
model = AutoModelForCausalLM.from_pretrained(
model_name,
quantization_config=quant_config
)
Similarly, we load the tokenizer and assign the pad token as the end of sequence token.
tokenizer = AutoTokenizer.from_pretrained(
model_name,
trust_remote_code=True,
use_fast=False
)
tokenizer.pad_token = tokenizer.eos_token
Defining the LoRA Configuration and the Training Arguments
As we are going to carry out LoRA training here, we also need to define the LoRA configuration.
peft_params = LoraConfig(
lora_alpha=16,
lora_dropout=0.1,
r=16,
bias='none',
task_type='CAUSAL_LM',
target_modules = [
'q_proj', 'k_proj', 'v_proj', 'o_proj',
'gate_proj', 'up_proj', 'down_proj',
]
)
Both, LoRA Rank and LoRA Alpha are set to 16. We are fine-tuning all the attention linear layers defined through the target_modules argument.
The following block contains the training arguments.
training_args = TrainingArguments(
output_dir=f"{out_dir}/logs",
evaluation_strategy='epoch',
weight_decay=0.01,
load_best_model_at_end=True,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
logging_strategy='epoch',
save_strategy='epoch',
save_total_limit=2,
bf16=bf16,
fp16=fp16,
report_to='tensorboard',
num_train_epochs=epochs,
dataloader_num_workers=num_workers,
gradient_accumulation_steps=gradient_accumulation_steps,
learning_rate=learning_rate,
lr_scheduler_type='constant',
seed=seed
)
This is standard to any other Hugging Face language model training and most of the arguments are used from the configurations that we defined earlier.
Next is initializing the SFTTrainer pipeline.
trainer = SFTTrainer(
model=model,
train_dataset=dataset_train,
eval_dataset=dataset_valid,
max_seq_length=context_length,
tokenizer=tokenizer,
args=training_args,
peft_config=peft_params,
formatting_func=preprocess_function
)
There are a few important arguments here:
peft_config: The LoRA config that we define above.formatting_func: We also have a preprocessing function to format the data into the Alpaca format. The process is completed when initializing the training pipeline.
At this moment, all the LoRA configurations have been applied to the Phi 1.5 model. Let’s check the final number of trainable parameters now.
print(model)
# Total parameters and trainable parameters.
total_params = sum(p.numel() for p in model.parameters())
print(f"{total_params:,} total parameters.")
total_trainable_params = sum(
p.numel() for p in model.parameters() if p.requires_grad)
print(f"{total_trainable_params:,} training parameters.")
This brings the final trainable parameters to ~4.7M.
Start the Training and Save the Best Model
We just need to call the train method to start the training. Along with that, we also save the best model to disk.
history = trainer.train()
trainer.model.save_pretrained(f"{out_dir}/best_model")
trainer.tokenizer.save_pretrained(f"{out_dir}/best_model")
Here are the training logs and the loss graphs.
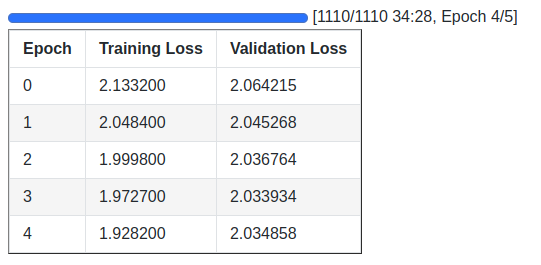
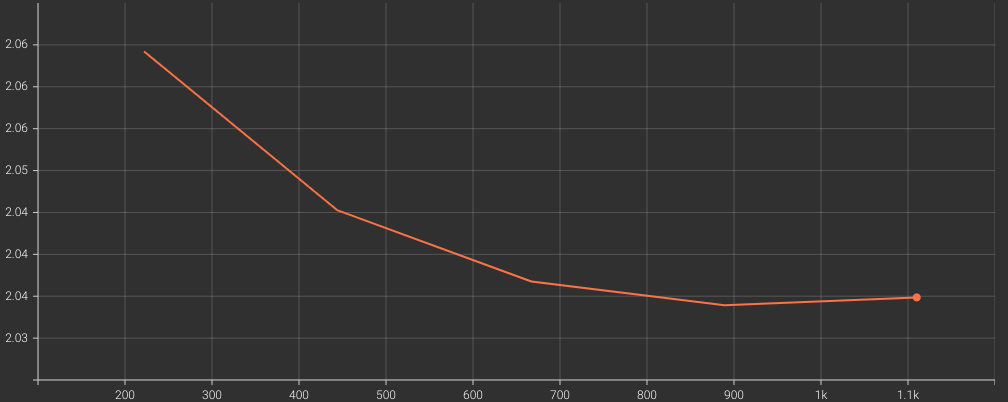
The loss was decreasing till 4 epochs which gives us the best model that we will use for inference.
Inference – Using Phi 1.5 for Text Summarization
The inference code is present in the inference.ipynb notebook. We will summarize the article present in the outputs/sample_1.txt. It contains a news snippet about one of the recent F1 races.
Let’s import all the modules, set the seed, and load the model & the tokenizer.
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline, set_seed import torch set_seed(42)
model = AutoModelForCausalLM.from_pretrained(
'outputs/phi_1_5_summarization/best_model/',
quantization_config= {'load_in_4bit': True}
)
tokenizer = AutoTokenizer.from_pretrained('outputs/phi_1_5_summarization/best_model/')
We are loading the model in INT4 quantized format as it uses substantially less memory.
Next, we need to define the prompt template similar to the training dataset format.
template = '### Instruction:\nSummarize the following article.\n\n### Input:\n{text}\n\n### Response:'
During inference, we replace the {text} with the article which we want to summarize.
Now, let’s read a text file and format the template.
file = open('inference_data/sample_1.txt', 'r')
text = file.read()
prompt = template.format(text=text)
print(prompt)
The final prompt is in the same format as the dataset was during training. Here is the truncated text.
### Instruction: Summarize the following article. ### Input: Just over five months on from a frantic – ... interest continues to be boosted by having celebrity attendees on site. ### Response:
We leave the prompt at ### Response: so that the model knows how to start summarizing the content.
The next step is to tokenize the prompt.
prompt_tokenized = tokenizer(
prompt,
return_tensors='pt',
return_attention_mask=True
).to('cuda')
And finally, pass it through the model to generate the summary.
output_tokenized = model.generate(
**prompt_tokenized,
eos_token_id=tokenizer.eos_token_id,
max_length=len(prompt_tokenized['input_ids'][0])+120,
repetition_penalty=1.1,
temperature=0.8,
top_k=40,
top_p=0.1,
do_sample=True,
num_beams=5
)
answer = tokenizer.decode(token_ids=output_tokenized[0][len(prompt_tokenized[0]):]).strip()
print(answer)
We have passed quite a few generation arguments to the generate method above. Do give the article linked at the beginning of the post to learn more about these arguments.
Here is the output that we get.
When asked by an American journalist if he thought Miami's race had been diminished by the arrival of Vegas, seven-time world champion Lewis Hamilton replied: "Diminished? No, I think the sport's got bigger here.Hard Rock Stadium president and CEO Tom Garfinkel, who is the managing partner of the Formula 1 event and the boss of the Miami Dolphins NFL team, explained to selected media including Motorsport.com that he felt his event is proving out F1's continued growth in the States.As well as a packed house, celebs like Ed Sheeran, Kendall Jenner
The summary looks fine, however, we can observe that the model does not stop correctly. It abruptly ended the generation process in spite of us having provided the end of sequence tokenizer and even properly formatting the training data.
For now, let’s put all of the above generation code into a function and summarize another file containing F1 news.
def summarize(file_path, tokenizer, model, template):
file = open(file_path, 'r')
text = file.read()
prompt = template.format(text=text)
prompt_tokenized = tokenizer(
prompt,
return_tensors='pt',
return_attention_mask=True
).to('cuda')
output_tokenized = model.generate(
**prompt_tokenized,
eos_token_id=tokenizer.eos_token_id,
max_length=len(prompt_tokenized['input_ids'][0])+120,
repetition_penalty=1.1,
temperature=0.8,
top_k=40,
top_p=0.1,
do_sample=True,
num_beams=5
)
answer = tokenizer.decode(token_ids=output_tokenized[0][len(prompt_tokenized[0]):]).strip()
print(answer)
summarize('inference_data/sample_2.txt', tokenizer, model, template)
Following is the output that we get.
Aged 18, early in 2018, Norris was team-mate to Alonso at the Daytona 24 Hours sportscar race.It was hardly the point of their appearance, but Norris set himself a private target of leaving the event with a faster lap time than Alonso - and did it.Norris came close to a win in Russia in 2021, when he put the McLaren on pole and led most of the race confidently before mistakenly choosing to stay out on dry-weather slicks when it rained late on.Heading into the Miami weekend, he held the all-time record for podium finishes
Looking closely, we can see that it is not much of a summary, but rather a compilation of phrases from the original document which do not start correctly. Although it is an inherent issue with extractive summarization, the Phi 1.5 model is also to blame here.
Issues with Using Decoder-Only Small Language Models for Text Summarization
As we have seen above, the process of training decoder-only small language models for text summarization does not produce compelling results. This is the case when at least we start directly from the base model. Here are a few notes and observations:
- Issue 1: We cannot control the length of target IDs like we can in encoder-decoder models. They merge into a single prompt.
- Issue 2: Training for text summarization directly does not teach the model to know where to stop exactly, despite the EOS token.
- Maybe first, instruction fine-tuning and then fine-tuning for summarization using the same instruction format will produce better results.
The third point above is of course experimental. We will try to cover that in one of the future articles. Other than that, we will also try covering:
- Larger abstractive summarization dataset training
- Comparing metrics and performance of decoder-only text summarization technique with encoder-decoder models.
Summary and Conclusion
In this article, we fine-tuned the Phi 1.5 model for text summarization. Along the way, we figured out that directly fine-tuning a base decoder-only model for extractive text summarization on a small dataset does not produce good results. We also discussed what could be done to rectify the issues. I hope that this article was worth your time.
If you have any doubts, thoughts, or suggestions, please leave them in the comment section. I will surely address them.
You can contact me using the Contact section. You can also find me on LinkedIn, and X.

3 thoughts on “Fine-Tuning Phi 1.5 for Text Summarization”