
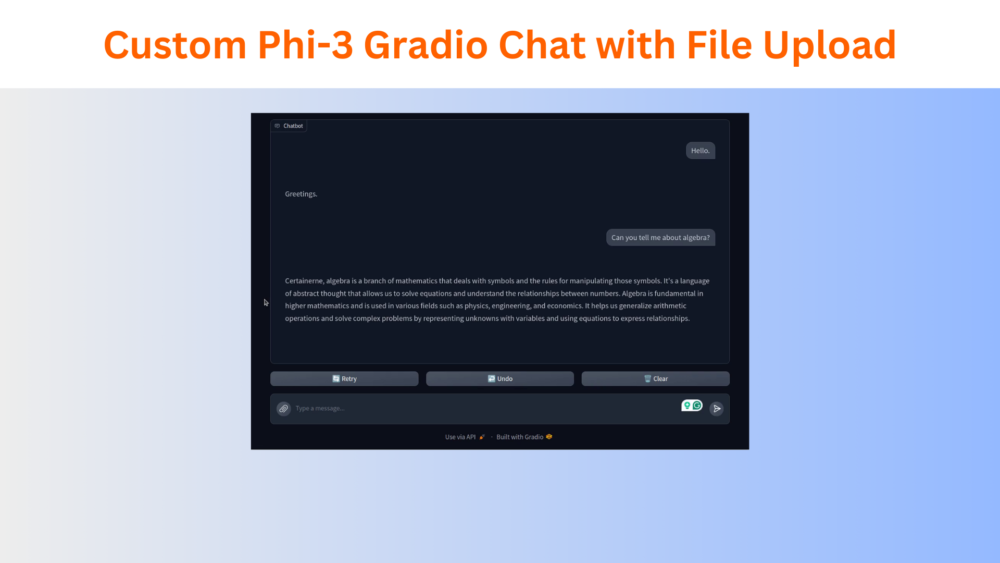
In this article, we will create a custom Phi-3 Gradio chat interface along with the ability to upload and query files.
Since the birth of LLMs (Large Language Models) and SLMs (Small Language Models), online chat interfaces are the primary sources of interaction with them. Although the user interfaces are intuitive and simple to use, a lot happens in the background. Here, the question arises “Can we create a minimalistic version of an LLM chat interface?” Yes, we can.
Here, we will use the Phi-3 model for creating a Gradio chat interface. The Phi-3 Mini instruct model comes in several variants and we will choose one of them. After going through this article, you may create your version of a local LLM chat interface.
We will cover the following topics while creating the custom Phi-3 Gradio chat interface
- Proper loading of the model and tokenizer. We will use the Phi-3-mini-4k-instruct from Hugging Face.
- Initializing the prompt template with proper tokens.
- Managing history so that the model remembers what we are chatting about.
- Uploading a file and querying the model about the it.
Note: We will not go into the details of the Phi-3 model here. We will cover that in a separate article.
Considerations When Implementing a Local LLM Gradio Chat
There are a few points that we need to consider (even if simplified) to create a local LLM chat using Gradio.
Proper Prompt Template
Every chat model has a chat template. If using a Hugging Face model, we can easily find the chat template from the tokenizer configuration. Even if we do not use prebuilt functions used to load the chat template, it is still a better idea to load it at least once and check the templatized string.
Here is an example of a templatized prompt string for Phi-3.
<|system|> You are a helpful assistant.<|end|> <|user|> Question?<|end|> <|assistant|>
This has to continue in a loop when chatting with the model.
Managing Chat History
The above brings us to managing chat history. Each chat history will contain the previous user query and the model response. We need to again append them properly as per the chat template criteria before the next user query begins to manage history. That’s how the model remembers the chat.
Memory Management
Furthermore, as the chat history starts to increase, the GPU memory usage also increases. Along with that, we need to handle the model’s context length as well. Later in the article, we will see how to handle this case.
File Upload and Query
This is not a mandatory use case, although it is nice to have. Uploading a file and querying the model regarding the file can be useful when trying to extract information from large files. However, this also adds to the GPU memory usage and context length when implemented naively. Spoiler: We do a naive implementation here, for the most basic use case.
Libraries and Dependencies
We need three primary libraries for creating the custom Phi-3 Gradio chat. They are
- Transformers:
pip install transformers - BitsAndBytes:
pip install bitsandbytes - Gradio:
pip install gradio
Download Code
We have just one Python script for this project and all the code is contained in that.
The Python script is downloadable via the download section.
Other Phi Language Model Articles You May Be Interested In
- Fine-Tuning Phi 1.5 for Text Summarization
- Phi 1.5 – Introduction and Analysis
- Instruction Following Notebook Interface using Phi 1.5
Custom Phi-3 Gradio Chat
Let’s jump into the code now. All the code is available in the gradio_phi3_chat.py file.
Note: All the experiments shown here were run on a 10 GB RTX 3080 GPU.
Let’s start with the import statements, initializing the Phi-3 model & optimizer, and defining a few constants.
import gradio as gr
import threading
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
TextIteratorStreamer,
BitsAndBytesConfig
)
device = 'cuda'
quant_config = BitsAndBytesConfig(
load_in_4bit=True
)
tokenizer = AutoTokenizer.from_pretrained('microsoft/Phi-3-mini-4k-instruct')
model = AutoModelForCausalLM.from_pretrained(
'microsoft/Phi-3-mini-4k-instruct',
quantization_config=quant_config,
device_map=device
)
streamer = TextIteratorStreamer(
tokenizer, skip_prompt=True, skip_special_tokens=True
)
# Context length of 3800 uses around 9.9GB of GPU memory when highest
# context length is reached. It can be increased to a higher number for
# GPUs with more VRAM. However, we need to consider the model's context
# length as well.
CONTEXT_LENGTH = 3800
We import all the necessary modules from the transformers library, the computation device, and the quantization configuration as well. When loading the model in INT4 data type, the initial memory usage is around 2.4 GB of VRAM.
We also initialize the TextIteratorStreamer class which will be necessary later to stream the output to the Gradio output box in real-time when the inference is going on.
Additionally, we set a context length of 3800 tokens. We are using the Phi-3-mini-4k-instruct model. This model has a max context length of 4096 tokens. This means that the model will not be able to keep any chat in memory properly after accumulation of 4096 tokens. However, for 10GB VRAM, the memory gets full around 3900 tokens. So, we will start clearing tokens after the context gets filled till 3800 tokens.
Managing File Content
We have a very simple approach to managing files here. We can upload small text files to chat with them. For that we have a simple helper function that will read the file content and return it. In future we can add more functionalities.
def file_state_management(file_path):
"""
Function to load file content into the chat history
when a file is uploaded.
:param file_path: File path from the gradio chat input.
"""
file_content = open(file_path).read()
return file_content
Managing History and Generating Tokens
The larger part of all the inference and history management is going to happen in the generate_next_tokens function.
def generate_next_tokens(user_input, history):
print(f"User Input: ", user_input)
print('History: ', history)
print('*' * 50)
# The way we are managing uploaded file and history here:
# When the user first uploads the file, the entire content gets
# loaded into the prompt for that particular chat turn.
# When the next turn comes, right now, we are using the `history`
# list from Gradio to load the history again, however, that only contains
# the file path. So, we cannot exactly get the content of the file in the
# next turn. However, the model may remember the context from its own
# reply and user's query. This approach saves a lot of memory as well.
if len(user_input['files']) == 0:
final_input = user_input['text']
else:
file_content = file_state_management(user_input['files'][0])
user_text = user_input['text']
final_input = file_content
final_input += user_text
chat = [
{'role': 'user', 'content': 'Hi'},
{'role': 'assistant', 'content': 'Hello.'},
{'role': 'user', 'content': final_input},
]
template = tokenizer.apply_chat_template(
chat,
tokenize=False,
add_generation_prompt=True
)
# Loading from Gradio's `history` list. If a file was uploaded in the
# previous turn, only the file path remains in the history and not the
# content. Good for saving memory (context) but bad for detailed querying.
if len(history) == 0:
prompt = '<s>' + template
else:
prompt = '<s>'
for history_list in history:
prompt += f"<|user|>\n{history_list[0]}<|end|>\n<|assistant|>\n{history_list[1]}<|end|>\n"
prompt += f"<|user|>\n{final_input}<|end|>\n<|assistant|>\n"
print('Prompt: ', prompt)
print('*' * 50)
inputs = tokenizer(prompt, return_tensors='pt').to(device)
input_ids, attention_mask = inputs.input_ids, inputs.attention_mask
# A way to manage context length + memory for best results.
print('Global context length till now: ', input_ids.shape[1])
if input_ids.shape[1] > CONTEXT_LENGTH:
input_ids = input_ids[:, -CONTEXT_LENGTH:]
attention_mask = attention_mask[:, -CONTEXT_LENGTH:]
print('-' * 100)
generate_kwargs = dict(
{'input_ids': input_ids.to(device), 'attention_mask': attention_mask.to(device)},
streamer=streamer,
max_new_tokens=1024,
)
thread = threading.Thread(
target=model.generate,
kwargs=generate_kwargs
)
thread.start()
outputs = []
for new_token in streamer:
outputs.append(new_token)
final_output = ''.join(outputs)
yield final_output
We will be using Gradio’s ChatInterface class to create the chat interface. This accepts two implicit positional arguments, which we can see in the above code block, user_input, and history (their names can be different). The bottom line is that the first argument stores the user input from the chat box, and the second argument keeps the chat history in a list.
For every chat, we print the prompt and history on the terminal (not mandatory), primarily for debugging purposes.
We have a few large inline comments as well explaining what is happening behind the scenes.
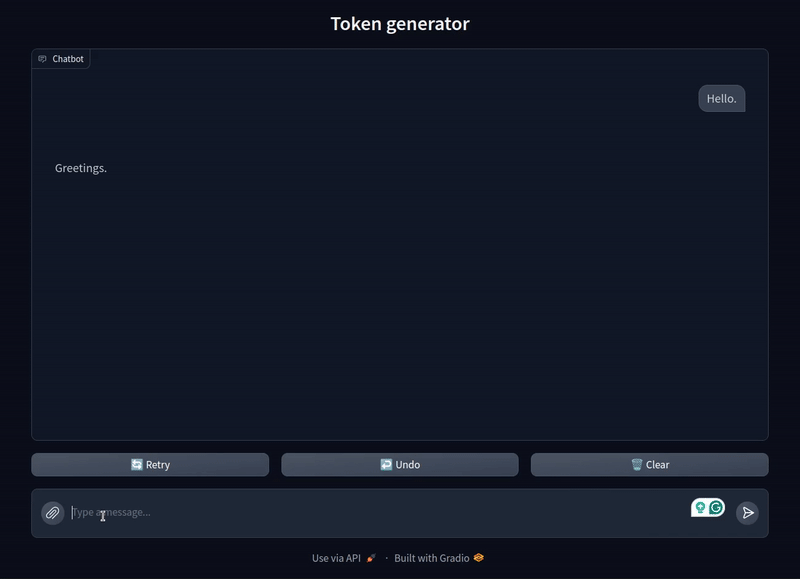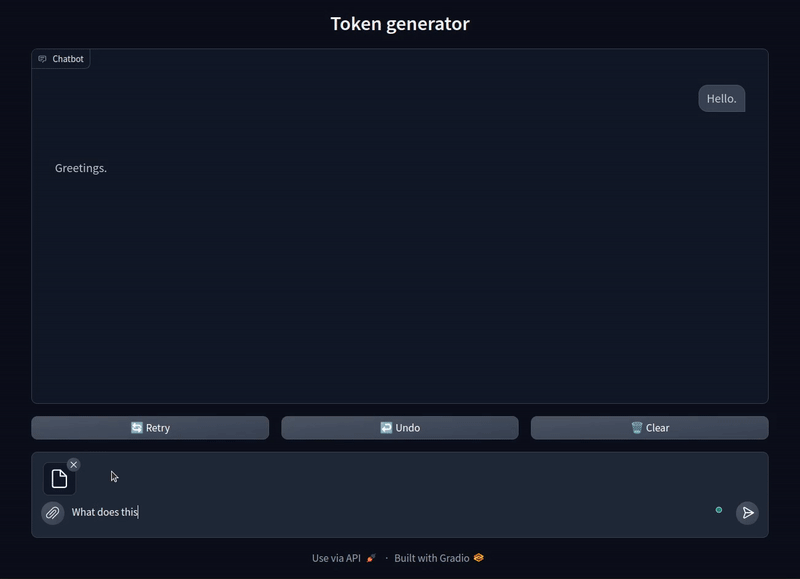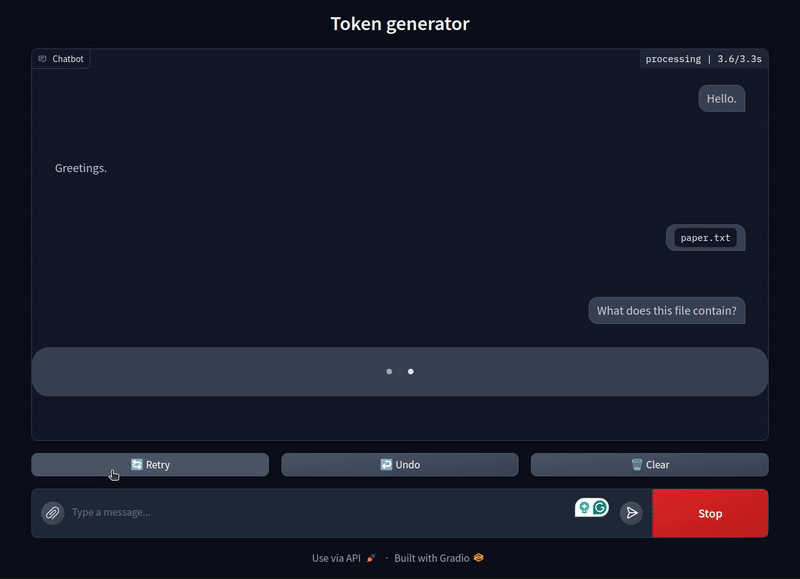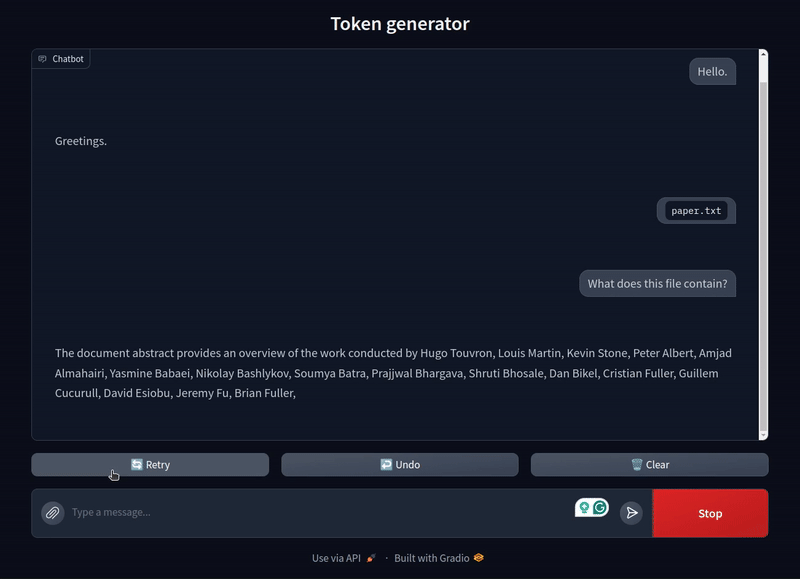
This is how the chat list looks like when a file is uploaded.
{'text': 'Hello.', 'files': ['/tmp/gradio/c4d01ceb5fd35cf7cb0aec486feb5ec1700a497f/file_5166.txt']}
The above is the prompt list that Gradio generates automatically when we upload a file and type Hello in the chat box.
When the user first uploads a file, we read it and directly add it to the prompt. However, this does not become part of the user_input, so, it will not be available in the next turn. To keep things simple, let’s assume that the user will upload a file and ask one question about it (highly unlikely in real-life use cases).
Next, is the chat template and chat history (lines 65 to 86).
Initially, we define a simple chat template and use the tokenizer’s apply_chat_template function. In fact, this should be done with every model and just print the templatized token string to check it once. This is the structure for the Phi-3 Mini model.
<s><|user|> Hi<|end|> <|assistant|> Hello.<|end|>
This structure will be repeated each turn along with that chat history. According to the official model repository, the <s> at the beginning of the prompt is quite important for good results.
Next is the chat history. The history variable stores the chat in the following format.
[['Who are you?', 'I am Phi, an AI developed by Microsoft.']]
It is a 2D list where the first element is the user input and the second is the model’s response. If the history length is not zero, we keep on appending the user input and model response with correct formatting before the current prompt. Here, we need to take care of each white space and new line, otherwise, the model response gets completely messed up.
Then we have the input tokens, attention masks, and managing the context (lines 91 to 98). Here, whenever the length of input of tokens becomes greater than the context length, 3800 in our case, we just truncate the input tokens and attention masks till the context length. You can keep a higher context length when running on a GPU with more VRAM.
Finally, we define the generation keyword arguments and start a thread so that we can output the tokens to the Gradio text box without any interruption.
Initializing the Chat Interface
Now, we just need to initialize the chat interface.
iface = gr.ChatInterface(
fn=generate_next_tokens,
multimodal=True,
title='Token generator'
)
iface.launch()
That’s all the code to create a custom Phi-3 chat with Gradio. To launch it, execute the following in the terminal and open the local host when the link appears.
python gradio_phi3_chat.py
Chatting with Phi-3 using Custom Gradio Interface
As we are using the pretrained Phi-3 model, we will not analyze the model too much in terms of the quality of the results.
However, we will surely try out a few experiments to analyze the UI and how well the file uploading and querying works.
Following is a clip showing some general chatting capabilities of the model with the interface that we created.
The above video is a simple “vibe check” to see whether our chat interface and prompts are working correctly or not.
Following is another video trying to analyze whether our chat history management is working properly or not.
Needless to say, the model can remember the conversation it is having with the user.
For our final test, we will upload a text file that contains the abstract and introduction from the Llama 2 paper. The file is named paper.txt so that we can be sure that the model does not pick anything up from the file name, rather it has to analyze the content.
The model is able to analyze the text file perfectly. It answers all the questions correctly.
Takeaways and Limitations
Although the above method seems good, there are a few points that we need to discuss.
- Chat history management: There are better ways to manage chat history rather than storing everything in memory. Although it is difficult to say how companies like OpenAI and Anthropic handle that, maybe we can just summarize the chat and store them out of GPU memory and RAG them when needed.
- File management: Right now, we are just reading the file and dumping it before the prompt. It is bound to break; Out Of Memory and context length issues will be common for larger files. Instead of reading the entire file and adding them to the prompt, we can use a RAG method.
We can tackle the above issues in a future post.
Summary and Conclusion
In this article, we created a simple custom Phi-3 Gradio chat with file upload and querying capability. We analyzed the results and also discussed some of the limitations. We will try to take this project further in the future. I hope this article was worth your time.
If you have any doubts, thoughts, or suggestions, please leave them in the comment section. I will surely address them.
You can contact me using the Contact section. You can also find me on LinkedIn, and X.
References

4 thoughts on “Custom Phi-3 Gradio Chat with File Upload”