In this article, we cover the architecture of ViTPose and ViTPose++ and run inference on images & videos using ViTPose. ...
ViTPose – Human Pose Estimation with Vision Transformer


Machine Learning and Deep Learning
In this article, we cover the architecture of ViTPose and ViTPose++ and run inference on images & videos using ViTPose. ...
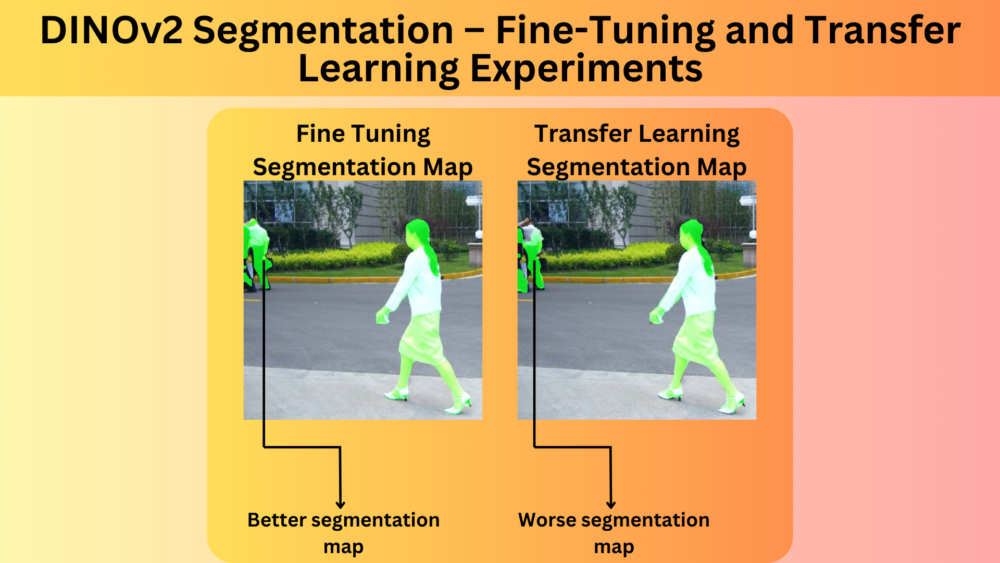
In this article, we simply the semantic segmentation (pixel classification) head of the DINOv2 model and carry out experiments comparing fine-tuning and transfer learning. ...

In this article, we modify the DINOv2 model for semantic segmentation, freeze the backbone, and train the model on the Penn-Fudan Pedestrian segmentation dataset. ...

In this article, we create a custom Vision Transformer based object detection model using NVIDIA's FasterViT backbone and the Single Shot Detection head. ...

In this article, we train the FasterViT on the Pascal VOC semantic segmentation dataset using the PyTorch Deep Learning framework. ...
Business WordPress Theme copyright 2025