

We will dive into the details of the Phi 1.5 language model in this article.
Since their inception, the Phi series of LLMs by Microsoft has been really impressive. Mostly because they perform well above their parameter threshold. For example, with just 1.3B parameters Phi 1.5 either matches or beats LLama2 7B in many benchmarks. In fact, almost all Phi models outperform larger models in their time frame, as we will see in later articles.

From this article, we will start our discussion with Phi 1.5 (skipping Phi 1) and slowly move up the ladder in future ones.
We will cover the following topics in this article:
- We will start with a general introduction to the Phi 1.5 model. This will also include a brief of the Phi 1 model.
- Next, we will cover the datasets used to train the Phi 1.5 model and its different versions.
- This will lead to the discussion of the benchmarks and results.
- Following this, we will talk about some important areas where Phi 1.5 wins:
- Managing toxicity and bias.
- How does the textbook training data of Phi 1.5 reduce toxicity?
- The default instruction following capability of Phi 1.5.
- Simple reasoning capability of the model.
- Finally, we will check how to use the Phi 1.5 model with Hugging Face Transformers. Here, we will also talk about the tokenizer used.
A Brief Introduction to Phi 1.5
The Phi 1.5 SLM (Small Language Model) is the successor to the Phi 1 model by researchers from Microsoft. The Phi 1 model was created for coding. Contrary to the common norm of scraping all the code from the internet, it was trained on a textbook-quality code dataset. This gave it a distinctive advantage over other models.
The first model was introduced in the paper – Textbooks are All You Need. And Phi 1.5 was introduced in the paper – Textbooks Are All You Need II: phi-1.5 technical report.
Phi 1.5 follows the same path, albeit with small changes to the dataset curation and size. Phi 1.5 is a 1.3 billion parameter model (just like Phi 1). The architecture remains almost the same. Most of the changes happen to the dataset (more on this later).
The primary objective of creating Phi 1.5 and training it on textbook-quality data (mainly coding) was to showcase that with properly curated data, smaller models can beat 4x-5x larger models in the same timeline. Of course, as months progress, the larger models with newer versions will beat the smaller models. To reiterate, Phi 1.5 competes with or beats Llama 2 on many benchmarks.

Furthermore, the dataset and training technique of Phi 1.5 allows it to follow simple instructions and carry out simple logical tasks without further fine tuning (commonly known as instruction tuning). We will get into the details of all these in their respective sections.
One of the most interesting aspects of Phi1.5 is that it uses a code specific tokenizer, i.e. CodeGenTokenizer. On top of that, the vocabulary size is 51200, which was larger than the common 32000 vocabulary size for the timeline. All of these provide a distinctive advantage for coding as well as when fine-tuning for non-coding downstream tasks.
Overall, Phi 1.5 tries to prove that with a properly curated dataset, even much smaller models can beat larger models on the same pretraining benchmarks and even on downstream tasks.
Phi 1.5 Models and Datasets
There are three different versions of models and datasets for Phi 1.5:
- Phi 1.5 (the open-source model)
- Phi 1.5 Web
- Phi 1.5 Web-only
We will get into the details of each here. Before that, it is worthwhile to mention that only the Phi 1.5 model (neither Web nor Web-only) is the open-source model. We will talk extensively about its dataset and touch base on the other two.
Phi 1.5 Open Source Model
The Phi 1.5 with 1.3B parameters is the primary open source model introduced in the paper. Needless to say, it is a Transformer architecture language model. It contains:
- 24 Transformer Layers
- 32 Heads with 64 dimensions each
- It uses rotary embeddings
- It has been trained on a context length of 2048
The training data for Phi 1.5 consists of around 30B tokens. Out of that:
- 7B tokens are from Phi 1’s training data
- 20B new tokens consisting of text-book like synthetic data. These include information about science, daily activities, etc. to teach the model common sense reasoning.
- Out of Phi 1’s 7B tokens, around 6B tokens contain coding data which makes the coding ability of the model stronger than other models of the same and even larger scale.
The dataset was properly filtered and cleaned for the purpose of training Phi 1.5 without noise. Especially, the coding dataset has been carefully curated so that the functions and examples contain complete solutions most of the time. This is unlike most of the web-scraped data like Stackoverflow which can contain incomplete solutions. This process teaches the model how to answer a question properly and with completeness. You may read the Phi 1 paper to get more detail on this.
Phi 1.5 Web and Web-Only Models
The Phi 1.5 Web Only model was trained on a filtered web dataset. The authors collected a dataset of 95B tokens. After applying filtering techniques, the dataset contained around 88B tokens. The model trained on this gave rise to the Phi 1.5 Web Only model.
Furthermore, the authors trained another model on a mixture of datasets collected from the above filtered web data, Phi 1’s code data, and synthetic NLP data. This gave rise to the Phi 1.5 Web model.
From the above, it is obvious that synthetic data was a major part of Phi 1.5. Most probably, using synthetic data from larger models’ output helps as the smaller model learns how to answer like the larger model.
Benchmarks and Results
Let’s jump into discussing the benchmarks and results of the Phi 1.5 model.
The first benchmark that we have is the common sense reasoning benchmark.
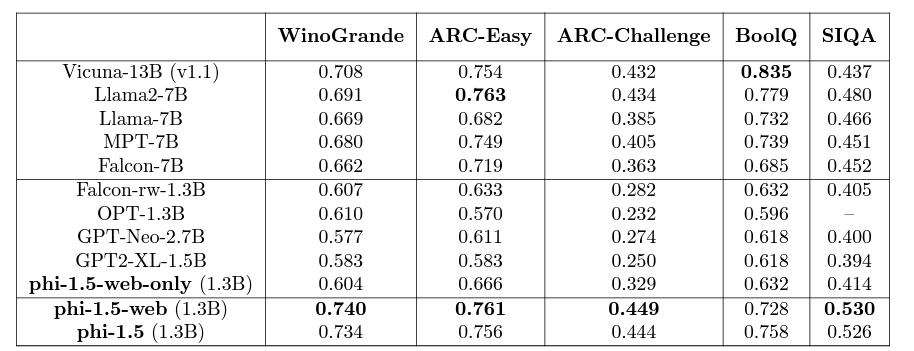
The results are very interesting here. The Phi 1.5 Web model (trained on the most amount of dataset) either beats or is very close to other 5x larger models, including Llama2-7B and even Vicuna-13B. The Phi 1.5 (the open source model) follows closely behind. Remember that this model was trained on textbook-quality data after a lot of filtering.
The most interesting aspect is that out of the three Phi 1.5 models, Phi 1.5 Web Only (trained on filtered web data) performs the worst. This model was not trained on synthetic data as well. However, Phi 1.5 Web contained filtered web data from above, synthetic data, and code data as well. This shows how much synthetic data can boost the performance of smaller models.
The next benchmark is for language understanding.
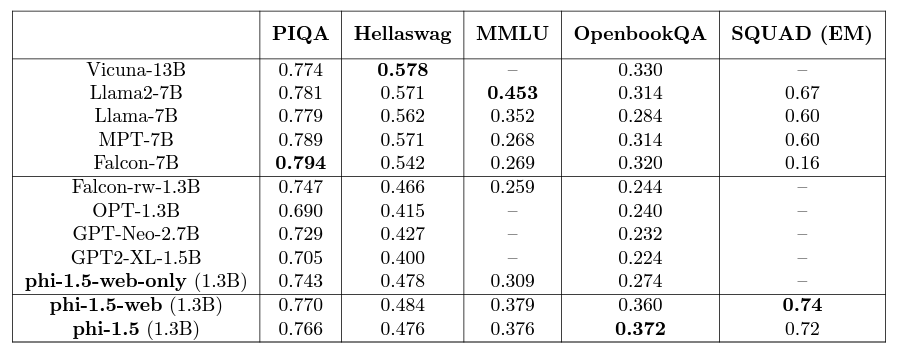
Here, some of the larger models beat the smaller Phi 1.5 models, but the numbers are close. In fact, considering the scale difference in parameters, the results from Phi 1.5 are really good.
The final benchmark is for multi-step reasoning.
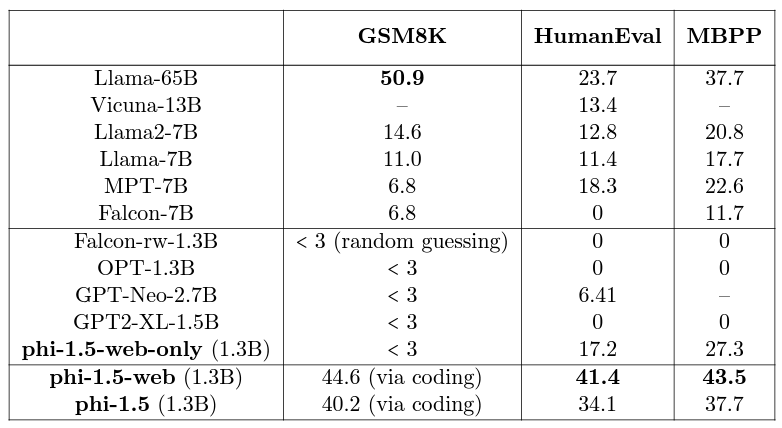
Here we have a mixture of elementary school math (GSM8K) and simple Python coding benchmarks (HumanEval and MBPP). Only Llama-65B beats the Phi 1.5 models in GSM8K. And of course, as Phi 1.5 was trained on coding data, it beats the larger models by a large margin in the respective benchmarks.
I highly recommend going through the benchmark section of the paper to get more details.
Winning Points for Phi 1.5
From the above, it is clear that the Phi 1.5’s performance is impressive. However, there are obvious categories where it proves its worth. In this section, we will focus on Phi 1.5’s ability to manage toxicity in its generation, its instruction following capability, and its reasoning capability.
Toxicity and Bias Management by Phi 1.5
Thanks to its textbook-quality dataset, Phi 1.5 mitigates the generation of toxic and biased content much better than its larger counterparts. The filtered synthetic data helps in this aspect. Other larger models, like Llama2-7B were trained on internet scale data. This leads to more toxic outputs when not fine-tuned for human-alignment or using RLHF. However, Phi 1.5 addresses this issue without any alightment or RLHF training.
Here is a benchmark result on the ToxiGen dataset.
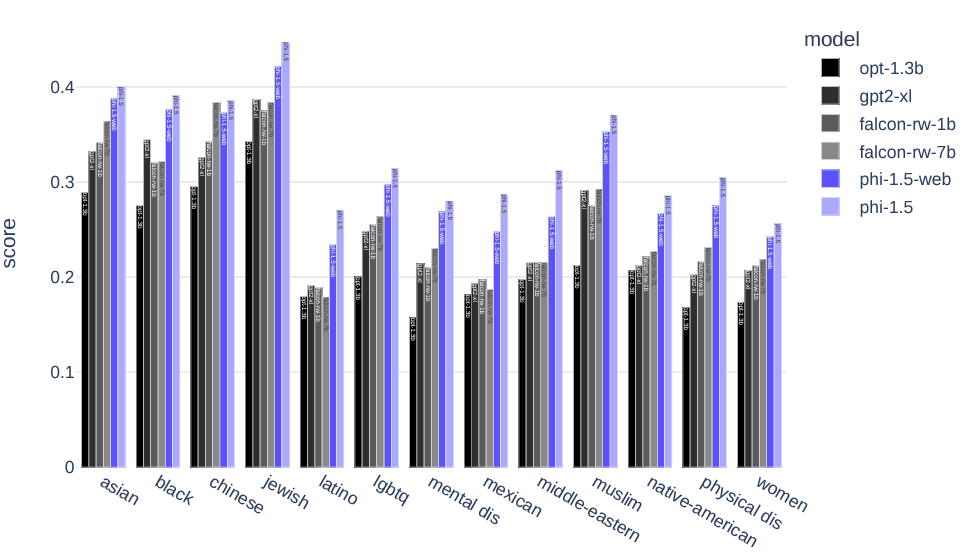
Phi 1.5 is the clear winner here. And it seems like the dataset filtration compared to Phi 1.5 Web model really helps in reducing toxicity.
Instruction Following and Simple Reasoning Capability of Phi 1.5
Even without instruction tuning, Phi 1.5 can follow simple instructions out of the box. Here is an example from the paper.

Phi 1.5 can complete many Python coding tasks when provided with a docstring. Here are some examples.

This shows that fine-tuning Phi 1.5 for downstream tasks, e.g. Question-Answering, Chat, and Coding will just enhance its ability to produce better output.
Where Can We Find the Phi 1.5 Model?
The best way to use Phi 1.5 is through Hugging Face Transformers. As only the Phi 1.5 model is open soruce, you can find the official page here. This contains all the steps to initialize and run the model.
Furthermore, you may to take a look at the tokenizer and model configuration under the Files and versions tab. It reveals a lot of details about the model’s vocabulary and the underlying tokenizer class. If you wish to fine-tune Phi 1.5 for instruction tuning and creating a Jupyter Notebook chat interface, be sure to give the following articles a read:
Summary and Conclusion
In this article, we dived into the Phi 1.5 model. Starting from its inception, the model, the datasets, to the results and benchmarks, we discussed a lot of topics. This exploration revealed that when training smaller language models, the quality of the dataset is crucial, which ultimately decides its final performance. In future article, we will discuss the newer versions of the Phi model including many downstream tasks. I hope that this article was worth your time.
If you have any questions, doubts, or suggestions, please leave them in the comment section.
You can contact me using the Contact section. You can also find me on LinkedIn, and Twitter.
References
